基于HDFS异构机制的列簇功能详解
千亿数据规模下,数据查询系统的性能与储存成本成正比,要达到满意的查询性能需要昂贵的存储设备来存储海量的数据,反之廉价的存储设备会降低查询速度,所以需要一种兼顾性能与成本的分级存储方法。
目前主流存储设备按照读取速度从快到慢的顺序,有内存、SSD固态硬盘、SAS机械硬盘、SATA机械硬盘,其价格也与之成正比。从稳定可靠的性能看,正好反之,速度越慢的设备越不容易损坏,内存最容易丢失数据,在断电的情况下就会丢失数据。
除了存储设备分级外,数据也是分级的,数据可以根据保存时间分级、可以根据重要程度分级、可以根据即时性分级,并且这些级别会随着时间的变化而变化。
现有方案
虽然目前业界采用一定的方式解决了数据分级的问题,但功能很受限。不能从根本上降低存储成本。并且在性能上也存在很多硬伤。
首先存储方式上,一张数据表,只能存储在同一种类的存储设备中,这种方式对本地磁盘要求比较高,一旦磁盘损坏,则该表无法使用,服务会受到影响。另外一种情况是如果数据由多备份或副本组成,其中一份副本所对应的磁盘故障,或当前正在进行大IO操作等因素导致这块磁盘读的速度很慢,系统不会自动识别切换到另外一块磁盘上进行读写,从而拖累整体的查询速度。
其次业界采用的这种方式只能作用到具体某张表上,不能细化到具体的某个数据列上面,这不够灵活,存储也不够精细化。因此对于同一张数据表的不同数据列之间有诸多限制。比如:
① 同一张表的数据列必须是相同的生命周期,保存的天数必须相同。
② 同一张表的数据列必须存储在同一个存储设备上,不能按列分数据级别后分别存储在不同的存储设备上。
③ 同一张表的数据列不会随着时间的改变变换存储级别,从而变换存储设备。
④ 同一张表的数据列只能存储在同一台计算机上,不能将不同的数据列分散存储在不同的计算机上。不同的列之间不可以通过存储设备的不同,做到列和列之间的资源隔离。在同一台计算机上读取时会相互影响。比如读取A列数据,B列数据也要一起随同读取进来,但是并不需要B列,故而浪费了磁盘IO资源,和用于解压的CPU资源。尤其在A列是小体积数据而B列是大体积数据的时候,比如图片文件之类的,更会严重影响性能。
列簇存储
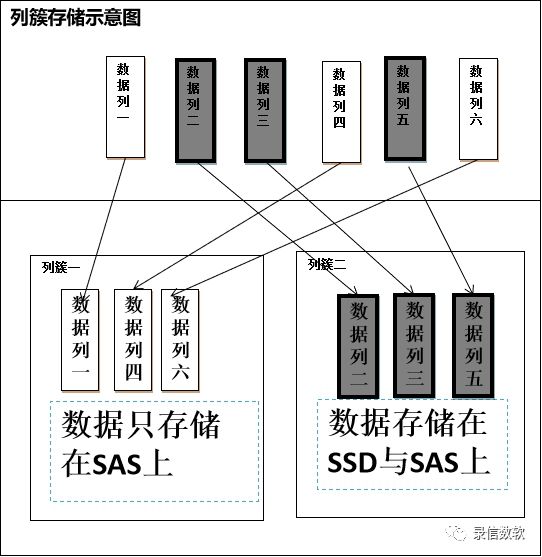
列簇功能是一个较典型的存储需求。从名字中就可以看出其作用——将一张表中的不同的列的存储隔离开来,不同的列拥有不同的存储目录。在开源方案中列簇并不少见,常见的支持列簇的存储产品有HBase、RocksDB(columnfamily)等,列簇功能其实也成为了大数据存储组件的一个典型功能。
录信数据库LSQL的列簇功能用于管理不同列保存不同的周期。列簇存储适合只是追加,并不需要修改的数据,如:日志数据。列簇存储是将行存数据直接存储在HDFS上,通过减少了索引合并,从而提升创建索引的效率。不同的列簇可以设置不同的生命周期,不同的存储介质,具体原理如下图所示:
列簇特点
-
不同列簇可以存储到不同磁盘, 具备混合使用不同磁盘的能力。
-
列簇可以根据时间变更存储设备,自动迁移。
-
不同列簇可以有不同的存储生命周期。
-
同一个数据列能综合使用多种存储设备。
-
不同列簇不同存储格式,不同压缩算法。支持行存,列存,混合存,多值列,汇聚存储均支持。
对于一张宽表可以有多种数据融合方案,如下所示:
假设一张宽表共300个列:
-
前100个列,都是图片,文件存储,比较大,保存10天,存储在SATA盘上;
-
中间100列,都是文本内容,经常全文检索,保存30天,一份副本存SSD,其他副本存储SATA;
-
后100个列,都是轨迹与关系数据,占存储空间相对较少,但需要进行统计分析,故存储90天,最近7天一份副本存在内存里,7天外存储在SSD,另外一份副本存储在SATA做备份。
LSQL将一张数据表按照分为不同的列簇,可以是每列一个列簇,也可以是多列一个列簇。每个列簇根据其数据等级的特点选择最适合的存储设备,提升性能的同时,最高可以节省90%存储成本。HDFS的异构存储在一定程度上降低了成本,但是使用上列簇存储则可将硬件的性价比发挥到极致。
列簇使用
基本使用
1. 两种列簇存储方式
-
启用行存数据-索引外的-列簇存储='store@true'
-
启用索引内-索引数据-列簇存储='index@true'
2. 列簇使用语法
(1)旧版创建方式
create columnfamily physical_table_name (
default at 'index@true' 'store@true' 'ssdindex@tim,doc' 'ssdindex2@fdt,fdx' 'cleanday@200,yyyyMMdd',
cf_name_01 at 'fields@col_001,col_002' index@false' 'cleanday@150,yyyyMMdd',
cf_name_02 at 'fields@col_003,col_004,col_005' 'store@false' 'cleanday@100,yyyyMMdd',
cf_name_03 at 'fields@col_006,col_007,col_008' 'cleanday@60,yyyyMMdd'
);-
create columnfamily:语法关键字。
-
physical_table_name: 物理表名称,可变。
-
cf_name_0*:列簇名称,可变。
-
default:默认列簇管理策略。
-
fields:字段列表,物理表中的字段;不能对MAPPING对象(映射表)做列簇管理。
-
index:索引列簇,true代表需要索引列簇管理,false代表不需要索引列簇管理;不写默认为true。
-
store:数据列簇(行存储列簇),true代表需要数据列簇管理,false代表不需要数据列簇管理;不写默认为true。store只对行存数据起作用,列存数据不可用。
-
ssdindex、ssdindex2、ssdindex3:异构特性设置,参考Hadoop异构存储介绍。
-
cleanday:列簇保存周期,用作数据清理淘汰。
注:后面的属性由于含有逗号,而逗号是sql的关键字,需要用单引号括起。如果需要修改列簇的保存周期,只需根据原有的脚本修改天数,重复执行创建即可。
(2)新版创建方式
LSQL新增在创建表时直接指定列簇信息(具体内容参照旧版),建立列簇表,格式如下:
create table lsql_column(col1 y_string_is,col2 y_string_is,col3 y_string_is,col4 y_string_is)tableproperties(
columnfamily='default at index@true store@true ssdindex@tim,doc ssdindex2@fdt,fdx cleanday@200,yyyyMMdd'
,columnfamily='cf1 at fields@col1 index@false cleanday@150,yyyyMMdd'
,columnfamily='cf2 at fields@col2,col3 store@false cleanday@100,yyyyMMdd'
,columnfamily='cf3 at fields@col4 cleanday@60,yyyyMMdd');同时兼容旧版列簇创建方式。
3. 创建实例
(1)创建物理表
进入LSQL所在节点:
# cd /opt/software/lsql/bin
# ./beeline.sh创建物理表“physical_table_test”:
create table physical_table_test(
col_001 y_string_id,
col_002 y_string_id,
col_003 y_string_id,
col_004 y_string_id,
col_005 y_string_id,
col_006 y_string_id,
col_007 y_string_id,
col_008 y_string_id,
col_009 y_string_id,
col_010 y_string_id
);物理表详情如下图所示:

(2)创建物理表“physical_table_test”的列簇
create columnfamily physical_table_test (
default at 'index@false' 'store@false' 'ssdindex@tim,doc' 'ssdindex2@fdt,fdx' 'cleanday@200,yyyyMMdd',
cf1_2 at 'fields@col_001,col_002' 'ssdindex@tim,tip' 'ssdindex2@doc' 'cleanday@150,yyyyMMdd',
cf3_5 at 'fields@col_003,col_004,col_005' 'index@false' 'cleanday@100,yyyyMMdd',
cf6_8 at 'fields@col_006,col_007,col_008' 'store@false' 'cleanday@60,yyyyMMdd',
cf9_10 at 'fields@col_009,col_010' 'cleanday@20,yyyyMMdd'
);根据上面的代码我们可以获取到的信息为:
-
列簇cf1_2:“col_001,col_002”字段做一个列簇,其中索引的“tim,tip,doc”做异构存储;列簇存储周期为150天。
-
列簇cf3_5:“col_003,col_004,col_005”字段做一个列簇,数据进行列簇,索引不做列簇管理;列簇存储周期为100天。
-
列簇cf6_8:“col_006,col_007,col_008”字段做一个列簇,数据不做列簇管理,索引进行列簇管理;列簇存储周期为60天。
-
列簇cf9_10:“col_009,col_010”字段做一个列簇;数据存储周期为60天。
-
列簇default:数据不做列簇,索引不做列簇,其中索引的“tim,doc,fdt,fdx”做异构存储;列簇存储周期为200天。
注:如果只对个别列进行列簇定期清理数据处理,那只对个别列进行设置即可,其他列的存储策略走默认default路线存储 ,数据永久存储时:'cleanday@200,yyyyMMdd'不设置即可。
创建列簇详情如下图所示:

更多使用
1. 设置行存储是否启用压缩
可以在default属性上设置compress@false,禁止进行压缩,默认不设置则索引内存储采用lz4压缩,索引外列簇采用zip。
具体使用方法如下:
--启用索引列簇存储,行存储不启用压缩:
create columnfamily common_performance (
default at 'index@true' 'store@false' 'compress@false'
);
--启用索引列簇存储、行存储列簇存储,行存储不启用压缩:
create columnfamily common_performance (
default at 'index@true' 'store@true' 'compress@false'
);2. 列簇名更换后如何使用
可以采用 'cf_old_site@oldcf' 'cf_old@newcf 用于兼容 更换列簇的情形。
(1)第一种情形-先在配置文件配置列簇(这个方式已经被废弃,没有按照表进行区分),更改为通过create columnfamily方式
cl.column.family.store=true
cl.rowstore.column.family=cf
cl.rowstore.column.family.alltable.s_mod_10=hl
cl.rowstore.column.family.alltable.s_mod_100=hl
--变更为create方式后就读不到列簇的值了
create columnfamily common_performance (
default at 'index@true' 'store@true'
,sss at 'fields@s_mod_10,s_mod_100' 'index@true' 'store@true'
)
--添加 'cf_old_site@cf'就可以读到之前在配置文件中配置的的列簇的值了
create columnfamily common_performance (
default at 'index@true' 'store@true' 'cf_old_site@cf'
,sss at 'fields@s_mod_10,s_mod_100' 'index@true' 'store@true' 'cf_old_site@hl'
)(2)第二种方式,通过create columnfamily的方式,但后期由于某种需要更改了列簇的名字
--原先是 sss列簇:
create columnfamily common_performance (
default at 'index@true' 'store@true'
,sss at 'fields@s_mod_10,s_mod_100' 'index@true' 'store@true'
);
--sss列簇变更为mmm列簇,无法再读取到之前sss列簇的值:
create columnfamily common_performance (
default at 'index@true' 'store@true'
,mmm at 'fields@s_mod_10,s_mod_100' 'index@true' 'store@true'
);
--添加 'cf_old@sss',可以继续读取之前设置过的 sss 列簇,即兼容旧列簇的数据:
create columnfamily common_performance (
default at 'index@true' 'store@true'
,mmm at 'fields@s_mod_10,s_mod_100' 'index@true' 'store@true' 'cf_old@sss'
);3. 其他用法
--用来查看系统中的列簇:
show columnfamilys;
--用来查看系统中的列簇:
drop columnfamily XXX;
--用来查看创建列簇的语句(取消show create columnfamily语法支持):
show create table XXX;LSQL的列簇功能将一张数据表按照分为不同的列簇,可以是每列一个列簇,也可以是多列一个列簇。每个列簇根据其数据等级的特点选择最适合的存储设备。从而达到性能与成本的最佳性价比,增强系统的灵活性,并显著提升系统的整体性能。现在登陆LSQL官网:www.lucene.xin,还可以免费试用喔~
关注录信数软官方公众号,录信团队欢迎优秀的你!
