【转载】MilkV Duo使用TPU推理pytorch模型
MilkV Duo的TPU推理Pytorch模型部署
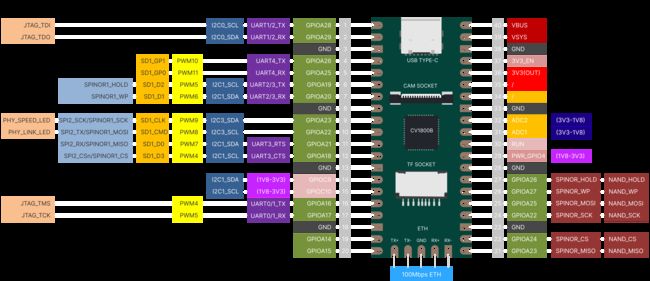
1.MilkV Duo开发板
最近在朋友的推荐下,购入了一块国产RISC-V架构的MilkV Duo开发板,首先这个开发板价格很便宜才35块,并且支持TPU模型推理,视频硬件编码,支持MIPI 2M的摄像头,这个性能确实震惊到我了,因此来看MilkV这个产品应该是和RP2040的开发板对标的。
开发板实物图:

首先来看看开发板的参数:
| Milk-V Duo | Specification |
|---|---|
| Processor | CVITEK CV1800B (C906@1Ghz + C906@700MHz) |
| Memory | DDR2 64MB |
| Storage | 1x Mirco SD slot,1x SD NAND solder pad |
| USB | 1x Type-C for data and Power,1x USB2 solder pad |
| Camera | 1x 16P FPC connector (MIPI CSI 2-lane) |
| Audio | 1x2P MicroPhone |
| GPIO | up to 26 Pins available for general purpose I/O(GPIO) |
| Size | 21mm*51mm |
2.部署docker镜像
1.安装docker命令:
MilkV Duo的开发板的模型转换环境需要在docker中运行,这样可以避免无意中篡改了主机的系统环境变量,我们以Ubuntu22.04的系统为例子:
(ps:需要注意的是从22.04后的Ubuntu系统的apt无法正确安装docker镜像,需要snap安装docker镜像;wsl子系统的用户请自行查找其他docker的安装教程)
sudo snap install docker
- 1
2.在github拉取项目:
git clone https://github.com/aceraoc/MilkV-Duo_TPU.git
- 1
(ps:下拉项目后进入项目文件夹中)
3.导入本地的docker镜像
下载镜像会比较久请耐心等待
./getdocker.sh
tar -zxvf cvitek_tpu_sdk_cv180x_musl_riscv64_rvv.tar.gz
tar -zxvf cvimodel_samples_cv180x.tar.gz
tar -zxvf cvitek_mlir_ubuntu-18.04_v1.5.0-883-gee0cbe9e3.tar.gz
sudo docker load -i docker_cvitek_dev_1.9-ubuntu-18.04.tar
- 1
- 2
- 3
- 4
- 5
4.运行docker镜像
(ps:如果是第一次进入需要这个步骤,如果不是第一次请移步下一步骤)
sudo docker run -itd -v $PWD:/work --name cvitek cvitek/cvitek_dev:1.9-ubuntu-18.04
sudo docker exec -it cvitek bash
- 1
- 2
5.关机或结束终端后重启docker:
(ps:第一次进入docker的bash操作页面可以忽略此步骤)
sudo docker start cvitek -i
- 1
3.编译移植Pytorch
如下步骤均在docker环境中执行
1.导入mlir的环境变量
source cvitek_mlir/cvitek_envs.sh
- 1
2.获取模型文件
(ps:考虑到有些网友网速比较差所以我把模型已经下下来放到github项目里去了,如果想把我的过程重走一遍的朋友可以试试执行getonnx.py这个python脚本)
mkdir -p /work/model_resnet18/workspace && cd model_resnet18
touch getonnx.py
python3 getonnx.py
- 1
- 2
- 3
getonnx.py的内容
# python
import torch
import torchvision.models as models
# Use an existing modelfrom Torchvision, note it
# will download this ifnot already on your computer (might take time)
model = models.resnet18(pretrained=True)
# Create some sampleinput in the shape this model expects
dummy_input = torch.randn(1, 3, 224, 224)
# Use the exporter from torch to convert to onnx
torch.onnx.export(model, \
dummy_input, \
'resnet18.onnx', \
export_params=True, \
opset_version=13, \
verbose=True, \
input_names=['input'])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
进入workspace文件夹内复制必要的官方训练集
cd workspace
cp $MLIR_PATH/tpuc/regression/data/cat.jpg .
cp -rf $MLIR_PATH/tpuc/regression/data/images .
ln -s /work/cvitek_mlir/tpuc/python/cvi_toolkit/tool/model_transform.py model_transform.py
ln -s /work/cvitek_mlir/tpuc/python/cvi_toolkit/tool/run_calibration.py run_calibration.py
- 1
- 2
- 3
- 4
- 5
3.onnx转换为mlir
官方对于转换脚本model_transform.py的解释如下
| 参数名称 | 描述 |
|---|---|
| –model_type |
源模型的框架类型, 支持caffe, onnx等框架(pytorch,tensorflow需要先转为onnx) |
| –model_name |
模型的名字 |
| –model_def |
模型文件(*.prototxt, *.onnx等) |
| –model_data |
caffe模型权重文件(*.caffemodel) |
| –image_resize_dims |
输入图片resize后的h和w, 如"256,256", 可选;–image_resize_dims如果设置的image_resize_dims和net_input_dims不相等, |
| –keep_aspect_ratio |
resize时是否保持原始高宽比不变,值为1或者0, 默认值为0; |
| –net_input_dims |
模型的input shape的h与w: 如 “224,224” |
| –model_channel_order |
通道顺序,如"bgr" 或 “rgb", 默认值为"bgr" |
| –raw_scale <255.0> | raw_scale 默认值为255 |
| –mean <0.0, 0.0, 0.0> | mean 通道均值,默认值为"0.0 ,0.0 ,0.0", 值的顺序要和model_channel_order一致 |
| –input_scale <1.0> | input_scale,默认值为1.0 |
| –std <1.0 ,1.0 ,1.0> | std, 通道标准差,默认值为"1.0 ,1.0 ,1.0", 值的顺序要和model_channel_order一致 |
| –batch_size |
指定生成模型的的batch num,默认用模型本身的batch |
| –gray |
是否输入的图片为灰度图,默认值为false |
| –image |
指定输入文件用于验证,可以是图片或npz、npy(w-major order);如果不指定,则不会做相似度验证 |
| –tolerance<0.99,0.99,0.98> | mlir单精度模型与源模型逐层精度对比时所能接受的最小相似度,相似度包括三项:余弦相似度、相关相似度、欧式距离相似度. 默认值为"0.99,0.99,0.98" |
| –excepts <“-”> | 逐层对比时跳过某些层, 多个层可以用逗号隔开, 如:“layer1,layer2”,默认值为"-",即对比所有层 |
| –mlir |
输出mlir单精度模型 |
预处理过程用公式表达如下(x代表输入):
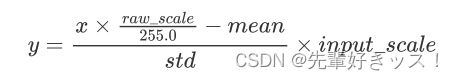
执行shell命令:
model_transform.py \
--model_type onnx \
--model_name resnet18 \
--model_def ../resnet18.onnx \
--image ./cat.jpg \
--image_resize_dims 256,256 \
--keep_aspect_ratio false \
--net_input_dims 224,224 \
--raw_scale 1.0 \
--mean 0.485,0.456,0.406 \
--std 0.229,0.224,0.225 \
--input_scale 1.0 \
--model_channel_order "rgb" \
--tolerance 0.99,0.99,0.99 \
--mlir resnet18_fp32.mlir
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
(ps:请将目录挂在到/work/model_resnet18/workspace下再执行)
4.生成全bf16量化cvimodel
执行下面的shell命令:
model_deploy.py \
--model_name resnet18 \
--mlir resnet18_fp32.mlir \
--quantize BF16 \
--chip cv180x \
--image cat.jpg \
--tolerance 0.99,0.99,0.86 \
--correctness 0.99,0.99,0.93 \
--cvimodel resnet18_bf16.cvimodel
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
5.生成全int8量化cvimodel
先做Calibration,需要先准备校正图片集,图片的数量根据情况准备100~1000张左右,这里用官方的。
执行下面的shell命令:
run_calibration.py \
resnet18_fp32.mlir \
--dataset=./images \
--input_num=100 \
-o resnet18_calibration_table
- 1
- 2
- 3
- 4
- 5
run_calibration.py 相关参数说明如下:
| 参数名称 | 描述 |
|---|---|
| –dataset | 指定校准图片集的路径 |
| –image_list | 指定样本列表,与dataset二选一 |
| –input_num | 指定校准图片数量 |
| –histogram_bin_num | 直方图bin数量, 默认为2048 |
| –tune_num | 指定微调使用的图片数量,增大此值可能会提升精度 |
| –tune_thread_num | 指定微调使用的线程数量,默认为4,增大此值可以减少运行时间,但是内存使用量也会增大 |
| –forward_thread_num | 指定模型推理使用的线程数量,默认为4,增大此值可以减少运行时间,但是内存使用量也会增大 |
| –buffer_size | 指定activations tensor缓存大小,默认为4G;如果缓存小于所有图片的activation tensor,则增大此值会减少运行时间,若相反,则增大此值无效果 |
| -o |
输出calibration table文件 |
执行下面的shell命令:
model_deploy.py \
--model_name resnet18 \
--mlir resnet18_fp32.mlir \
--calibration_table resnet18_calibration_table \
--chip cv180x \
--image cat.jpg \
--quantize INT8 \
--tolerance 0.98,0.98,0.84 \
--correctness 0.99,0.99,0.99 \
--cvimodel resnet18_int8.cvimodel
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
model_deploy.py的相关参数说明如下:
| 参数名称 | 描述 |
|---|---|
| –model_name |
指定模型名 |
| –mlir |
指定mlir单精度模型文件 |
| –calibration_table |
输入calibration table, 可选, 量化为int8模型 |
| –mix_precision_table |
输入mix precision table, 可选, 配合calib_table量化为混精度模型 |
| –quantize |
指定默认量化方式,BF16/MIX_BF16/INT8 |
| –tolerance |
量化模型和单精度模型精度对比所能接受的最小相似度,相似度包括三项:余弦相似度、相关相似度、欧式距离相似度. |
| –excepts <“-”> | 逐层对比时跳过某些层, 多个层可以用逗号隔开, 如:“layer1,layer2”, 默认值为"-",即对比所有层 |
| –correctness |
cvimodel在仿真上运行的结果与量化模型推理的结果对比时所能接受的最小相似度,默认值为:“0.99,0.99,0.98” |
| –chip |
cvimodel被部署的目标平台名, 值为"cv183x"或"cv182x"或"cv181x"或"cv180x" |
| –fuse_preprocess |
是否在模型内部使用tpu做前处理(mean/scale/channel_swap等) |
| –pixel_format |
cvimodel所接受的图片输入格式, 详见下文 |
| –aligned_input |
cvimodel所接受的输入图片是否为vpss对齐格式, 默认值为false;如果设置为true,必须先设置fuse_process为true才能生效 |
| –inputs_type |
指定输入类型(AUTO/FP32/INT8/BF16/SAME),如果是AUTO,当第一层是INT8时用INT8,BF16时用FP32 |
| –outputs_type |
指定输出类型(AUTO/FP32/INT8/BF16/SAME),如果是AUTO,当最后层是INT8时用INT8,BF16时用FP32 |
| –merge_weight |
与同一个工作目前中生成的模型共享权重,用于后续合并同一个模型依据不同batch或分辨率生成的cvimodel |
| –model_version |
支持选择模型的版本,默认为latest; 如果runtime比较老,比如1.2,则指定为1.2 |
| –image |
用于测试相似度的输入文件,可以是图片、npz、npy(w-majororder);如果有多个输入,用,隔开 |
| –save_input_files |
保存model_deploy的指令及输入文件,文件名为${model_name}_deploy_files.tar.gz。解压后得到的__deploy.sh保存了当前model_deploy的指令。 |
| –dump_neuron <“-”> | 调试选项,指定哪些层可以在调用model_runner -i input.npz -m xxx.cvimodel --dump-all-tenors时,可以dump下来,多个层可以用逗号隔开, |
| –keep_output_name |
保持输出节点名字与原始模型相同,默认为false |
| –cvimodel |
输出的cvimodel名 |
其中 pixel_format 用于指定外部输入的数据格式,有这几种格式:
| pixel_format | 说明 |
|---|---|
| RGB_PLANAR | rgb顺序,按照nchw摆放 |
| RGB_PACKED | rgb顺序,按照nhwc摆放 |
| BGR_PLANAR | bgr顺序,按照nchw摆放 |
| BGR_PACKED | bgr顺序,按照nhwc摆放 |
| GRAYSCALE | 仅有一个灰色通道,按nchw摆放 |
| YUV420_PLANAR | yuv420 planner格式,来自vpss的输入 |
| YUV_NV21 | yuv420的NV21格式,来自vpss的输入 |
| YUV_NV12 | yuv420的NV12格式,来自vpss的输入 |
| RGBA_PLANAR | rgba格式,按照nchw摆放 |
4.部署cvimodel模型
1.用ssh命令连接上Duo
如果你更改了IP或者用户名的话请自行修改命令
ssh [email protected]
- 1
操作Duo的bash
创建文件夹
cd / && mkdir -p /home/milkv/model_resnet18
- 1
2.上传模型和指定架构的sdk到开发板
(ps:这里在你的主机端docker bash下进行操作)
上传自己转换的模型:
(ps:这里挂在到我们docker镜像的/work/model_resnet18/workspace目录下)
scp *.cvimodel [email protected]:/home/milkv
- 1
这里也可以把官方制作好的模型上传:
(ps:需要挂载到docker镜像的/work目录下)
scp -r cvimodel_samples [email protected]:/home/milkv
- 1
上传sdk:
(ps:注意这里上传的是目录而不是文件)
scp -r cvitek_tpu_sdk [email protected]:/home/milkv
- 1
3.EVB运行Samples程序
(ps:这里在你的duo bash下进行操作)
执行如下命令,此命令配置一些环境变量
cd /home/milkv
export MODEL_PATH=$PWD/cvimodel_samples #这里是tpu官方的cvimodel
export MY_MODEL_PATH=$PWD/model_resnet18 #这里是你自己上传的cvimodel
export TPU_ROOT=$PWD/cvitek_tpu_sdk
export TPU_ENABLE_PMU=1 #
source cvitek_tpu_sdk/envs_tpu_sdk.sh
- 1
- 2
- 3
- 4
- 5
- 6
进入samples的目录
cd /home/milkv/cvitek_tpu_sdk/samples
- 1
运行sample实例
(ps:$MODEL_PATH的官方模型的环境变量可以替换成$MY_MODEL_PATH自己训练模型的环境变量)
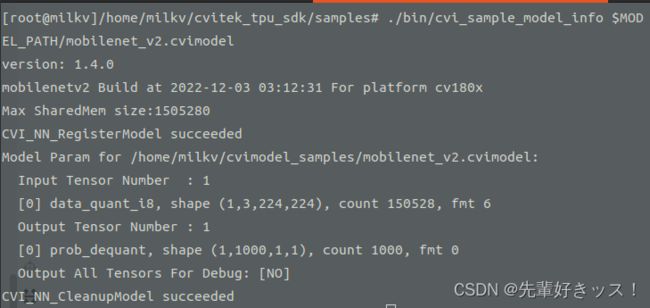
./bin/cvi_sample_model_info $MODEL_PATH/mobilenet_v2.cvimodel
- 1
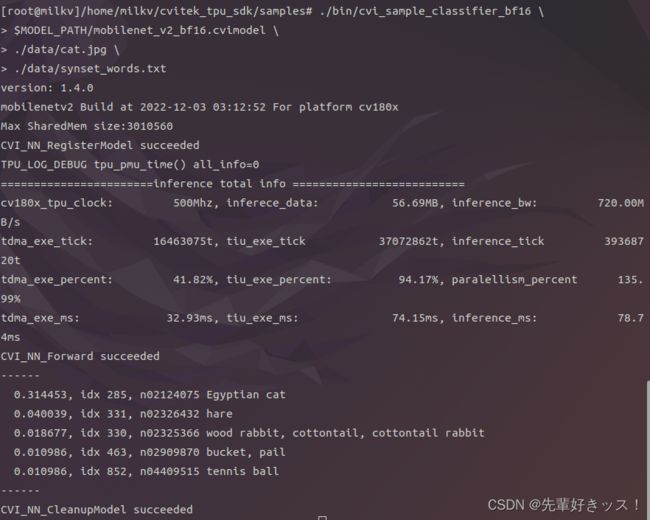
./bin/cvi_sample_classifier \
$MODEL_PATH/mobilenet_v2.cvimodel \
./data/cat.jpg \
./data/synset_words.txt
- 1
- 2
- 3
- 4

./bin/cvi_sample_classifier_bf16 \
$MODEL_PATH/mobilenet_v2_bf16.cvimodel \
./data/cat.jpg \
./data/synset_words.txt
- 1
- 2
- 3
- 4
./bin/cvi_sample_classifier_fused_preprocess \
$MODEL_PATH/mobilenet_v2_fused_preprocess.cvimodel \
./data/cat.jpg \
./data/synset_words.txt
- 1
- 2
- 3
- 4
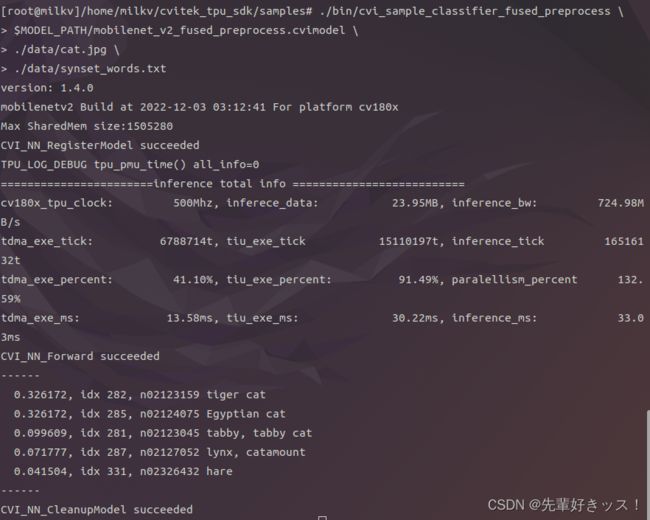
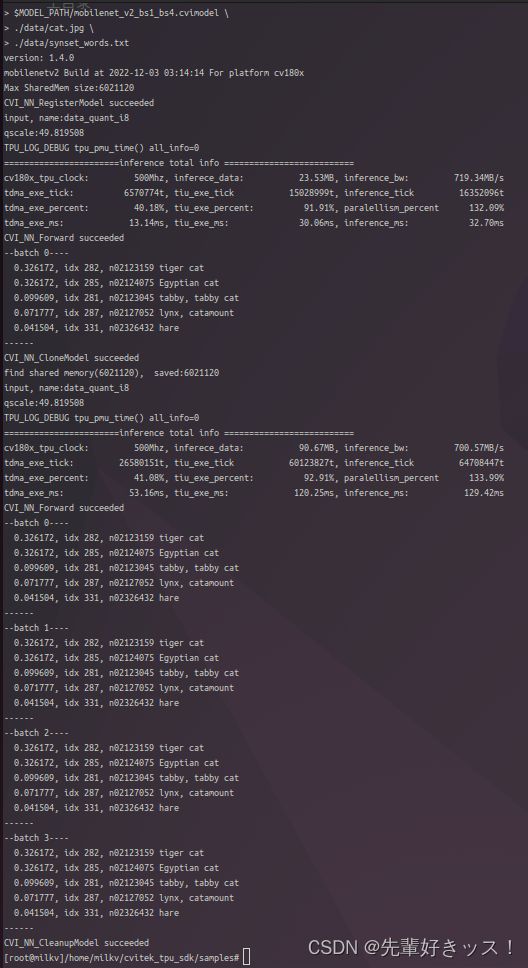
./bin/cvi_sample_classifier_multi_batch \
$MODEL_PATH/mobilenet_v2_bs1_bs4.cvimodel \
./data/cat.jpg \
./data/synset_words.txt
- 1
- 2
- 3
- 4
5.在CV180X使用TPU注意事项
我在官方的cv180x模型例子里面没有看到对yolo系列模型的直接支持,但是官方例子里面却有yolo系列的二进制例程文件,而且在cv180x班子上也能跑得通,也希望TPU官方能把对yolo系列的例子补全。