【Hive实战】Hive的压缩池与锁
文章目录
-
- Hive的压缩池
-
- 池的分配策略
-
- 自动分配
- 手动分配
- 隐式分配
- 池的等待超时
- Labeled worker pools 标记的工作线程(自定义线程池)
- Default pool 默认池
- Worker allocation 工作线程的分配
- 锁
- Turn Off Concurrency
- Debugging
- Configuration
-
-
-
- hive.support.concurrency
- hive.lock.manager
- hive.lock.mapred.only.operation
- hive.lock.query.string.max.length
- hive.lock.numretries
- hive.unlock.numretries
- hive.lock.sleep.between.retries
- hive.zookeeper.quorum
- hive.zookeeper.client.port
- hive.zookeeper.session.timeout
- hive.zookeeper.namespace
- hive.zookeeper.clean.extra.nodes
- hive.lockmgr.zookeeper.default.partition.name
-
-
Hive的压缩池
Compaction pooling
可以将压缩请求和工作线程分配到池中。 分配给特定池的工作线程将仅处理该池中的压缩请求。 没有分配池的工作线程和压缩请求隐式属于默认池。 池概念允许对处理压缩请求进行微调。 例如,可以创建一个名称为“高优先级压缩”的池,为其分配一些经常修改的表,并将一组工作线程专用于该池。 因此,即使默认队列中还有其他几个压缩请求(之前排队),这些表的压缩请求也将立即由专用工作线程获取。
池的分配策略
可以通过三种不同的方式将压缩请求分配给池。
自动分配
可以通过配置数据库、表和分区的属性的方式分配到压缩池:
hive.compactor.worker.pool={pool_name}
数据库/表属性。 如果该属性是在数据库级别设置的,则它适用于所有表和分区。 池也可以在表/分区级别上分配,在这种情况下,它会覆盖数据库级别值(如果设置)。
CREATE TABLE table_name (
id int,
name string
)
CLUSTERED BY (id) INTO 2 BUCKETS STORED AS ORC
TBLPROPERTIES ("transactional"="true",
);
如果设置了上述任何一项,则发起者在创建压缩请求期间将使用它。
手动分配
ALTER TABLE COMPACT table_name POOL 'pool_name';
还可以使用 ALTER TABLE COMPACT 命令将压缩请求分配给池(例如手动压缩)。 如果提供,该值将覆盖任何级别的 hive.compactor.worker.pool 值。
隐式分配
没有指定池名称的表、分区和手动压缩请求将隐式分配给默认池。
池的等待超时
如果压缩请求在预定义的时间内没有被任何标记池处理,它将回退到默认池。 超时时间可以通过设置
hive.compactor.worker.pool.timeout
配置属性。 该方法涵盖以下场景:
- 请求被意外分配给不存在的池。 (例如:发出 ALTER TABLE COMPACT 命令时池名称中的拼写错误。
- 发起者用来创建压缩请求的数据库或表属性中的拼写错误。
- HS2(HiveServer2) 实例由于缩减或计划而停止,并且仍应处理其挂起的压缩请求。
可以通过将配置属性设置为 0 来禁用超时。
Labeled worker pools 标记的工作线程(自定义线程池)
标记的工作池可以通过以下方式定义
hive.compactor.worker.{poolname}.threads={thread_count}
配置设置
Default pool 默认池
默认池负责处理未标记和超时的压缩请求。 在集群范围内,至少一个节点上的至少 1 个工作线程应分配给默认池,否则可能永远不会处理压缩请求。
Worker allocation 工作线程的分配
已经存在的 hive.compactor.worker.threads 配置值保存最大工作线程数。 工作线程分配如下:
- 标记池以随机顺序按顺序初始化。
- 每个池都会根据自己的工作线程数量减少可用工作线程的数量。
- 如果可分配的worker数量少于配置的数量,则池大小将被调整(换句话说:如果请求的池大小为5,但只剩下3个worker,则池大小将减少到3)。
- 如果可分配的worker数量为0,则池不会被初始化。
- 标记池中未用完的所有剩余工作人员将分配给默认池。
可以为每个 HS2 实例配置工作线程分配。
锁
Locking
并发支持(http://issues.apache.org/jira/browse/HIVE-1293)是数据库中必须的,并且它们的用例很好理解。 至少,我们希望尽可能支持并发读取器和写入器。 添加一种机制来发现当前已获取的锁将很有用。 不需要立即添加 API 来显式获取任何锁,因此所有锁都将隐式获取。
hive 中将定义以下锁定模式(注意不需要意向锁)。
- Shared (S)
- Exclusive (X)
As the name suggests, multiple shared locks can be acquired at the same time, whereas X lock blocks all other locks.
The compatibility matrix is as follows:
顾名思义,可以同时获取多个共享锁,而 X 锁会阻塞所有其他锁。
兼容性矩阵如下:
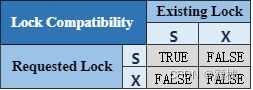
对于某些操作,锁本质上是分层的——例如,对于某些分区操作,表也被锁定(以确保在创建新分区时不能删除表)。
获取锁模式背后的原理如下:
对于非分区表,锁定模式非常直观。 读取表时,会获取 S 锁,而所有其他操作(插入表、更改任何类型的表等)都会获取 X 锁。
对于分区表来说,思路如下:
执行读取时,会获取表和相关分区上的“S”锁。 对于所有其他操作,都会在分区上获取“X”锁。 但是,如果更改仅适用于较新的分区,则在表上获取“S”锁,而如果更改适用于所有分区,则在表上获取“X”锁。 因此,可以读取和写入较旧的分区,同时将较新的分区转换为 RCFile。 每当一个分区被锁定在任何模式下时,其所有父分区都会被锁定在“S”模式下。
基于此,一个操作获取的锁如下:
| Hive Command | Locks Acquired |
|---|---|
| select … T1 partition P1 | S on T1, T1.P1 |
| insert into T2(partition P2) select … T1 partition P1 | S on T2, T1, T1.P1 and X on T2.P2 |
| insert into T2(partition P.Q) select … T1 partition P1 | S on T2, T2.P, T1, T1.P1 and X on T2.P.Q |
| alter table T1 rename T2 | X on T1 |
| alter table T1 add cols | X on T1 |
| alter table T1 replace cols | X on T1 |
| alter table T1 change cols | X on T1 |
| alter table T1 *concatenate* | X on T1 |
| alter table T1 add partition P1 | S on T1, X on T1.P1 |
| alter table T1 drop partition P1 | S on T1, X on T1.P1 |
| alter table T1 touch partition P1 | S on T1, X on T1.P1 |
| alter table T1 set serdeproperties | S on T1 |
| alter table T1 set serializer | S on T1 |
| alter table T1 set file format | S on T1 |
| alter table T1 set tblproperties | X on T1 |
| alter table T1 partition P1 concatenate | X on T1.P1 |
| drop table T1 | X on T1 |
为了避免死锁,这里提出了一个非常简单的方案。 将所有需要锁定的对象按字典顺序排序,并获取所需的模式锁。 请注意,在某些情况下,对象列表可能未知 - 例如,在动态分区的情况下,正在修改的分区列表在编译时未知 - 因此,该列表是保守生成的。 由于分区数量可能未知,因此应该在表或已知的前缀上采用独占锁(但目前不是由于 HIVE-3509 bug)。
将添加两个新的可配置参数来决定锁定的重试次数以及每次重试之间的等待时间。 如果重试次数非常高,可能会导致活锁。 查看 ZooKeeper recipes 以了解如何使用 Zookeeper api 实现读/写锁。 请注意,锁定请求将被拒绝,而不是等待。 现有的锁将被释放,并且在重试间隔后将全部重试。
由于锁的分层性质,上面列出的方法将无法按指定方式工作。
表 T 的“S”锁指定如下:
- 调用create()创建一个路径名为“/warehouse/T/read-”的节点。 这是协议后面使用的锁定节点。 确保设置序列和临时标志。
- 在锁定节点上调用 getChildren( ) 而不设置监视标志。
- 如果有一个子进程的路径名以“write-”开头且序列号比所获得的序列号低,则无法获取锁。 删除第一步创建的节点并返回。
- 否则授予锁定。
表 T 的“X”锁指定如下:
- 调用create()创建一个路径名为“/warehouse/T/write-”的节点。 这是协议后面使用的锁定节点。 确保设置序列和临时标志。
- 在锁定节点上调用 getChildren( ) 而不设置监视标志。
- 如果存在一个路径名以“read-”或“write-”开头且序列号低于所获取序列号的子进程,则无法获取锁。 删除第一步创建的节点并返回。
- 否则授予锁定。
这种模式的写入器或因为读取陷入饥饿状态。如果读取的时间太长,那么写入会陷入饥饿状态。
默认的 Hive 行为不会改变,并且不支持并发。
Turn Off Concurrency
您可以通过将以下变量设置为 false 来关闭并发:hive.support.concurrency。
Debugging
您可以通过发出以下命令来查看表上的锁:
- SHOW LOCKS
; - SHOW LOCKS
EXTENDED; - SHOW LOCKS
PARTITION ( ); - SHOW LOCKS
PARTITION ( ) EXTENDED;
EXPLAIN LOCKS
这对于了解系统将获取哪些锁来运行指定的查询很有用。
EXPLAIN LOCKS UPDATE target SET b = 1 WHERE p IN (SELECT t.q1 FROM source t WHERE t.a1=5)
可以支持JSON输出
EXPLAIN FORMATTED LOCKS <sql>
Configuration
锁的相关配置数据属性 Locking.
hive.support.concurrency
- Default Value:
false - Added In: Hive 0.7.0 with HIVE-1293
Hive 是否支持并发。 ZooKeeper 实例必须启动并运行,默认 Hive 锁管理器才能支持读写锁。
设置为true以支持INSERT … VALUES、UPDATE 和 DELETE 事务(Hive 0.14.0 及更高版本)。 有关打开 Hive 事务所需的参数的完整列表,请参阅 hive.txn.manager。
hive.lock.manager
- Default Value:
org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager - Added In: Hive 0.7.0 with HIVE-1293
当 hive.support.concurrency 设置为true时使用的锁管理器。
hive.lock.mapred.only.operation
- Default Value:
false - Added In: Hive 0.8.0
此配置属性用于控制是否仅对需要执行至少一个 Mapred 作业的查询进行锁定
hive.lock.query.string.max.length
- Default Value: 1000000
- Added In: Hive 3.0.0
要存储在锁中的查询字符串的最大长度。 默认值为 1000000,因为 znode 的数据限制为 1MB。
hive.lock.numretries
- Default Value:
100 - Added In: Hive 0.7.0 with HIVE-1293
您想要尝试获取所有锁的总次数。
hive.unlock.numretries
- Default Value:
10 - Added In: Hive 0.8.1
您想要进行一次解锁的总次数。
hive.lock.sleep.between.retries
- Default Value:
60 - Added In: Hive 0.7.0 with HIVE-1293
各种重试之间的睡眠时间(以秒为单位)。
hive.zookeeper.quorum
- Default Value: (empty)
- Added In: Hive 0.7.0 with HIVE-1293
要与之通信的 ZooKeeper 服务器列表。 仅读/写锁需要此操作。
hive.zookeeper.client.port
- Default Value:
- Hive 0.7.0: (empty)
- Hive 0.8.0 and later:
2181(HIVE-2196)
- Added In: Hive 0.7.0 with HIVE-1293
要与之通信的 ZooKeeper 服务器的端口。 仅读/写锁需要此操作。
hive.zookeeper.session.timeout
- Default Value:
- Hive 0.7.0 to 1.1.x:
600000ms - Hive 1.2.0 and later:
1200000ms(HIVE-8890)``
- Hive 0.7.0 to 1.1.x:
- Added In: Hive 0.7.0 with HIVE-1293
ZooKeeper 客户端的会话超时(以毫秒为单位)。 如果在超时时间内未发送心跳,则客户端将断开连接,并且所有锁都会被释放。
hive.zookeeper.namespace
- Default Value:
hive_zookeeper_namespace - Added In: Hive 0.7.0
所有 ZooKeeper 节点均在其下创建的父节点。
hive.zookeeper.clean.extra.nodes
- Default Value:
false - Added In: Hive 0.7.0
在会话结束时清理多余的节点。
hive.lockmgr.zookeeper.default.partition.name
- Default Value:
__HIVE_DEFAULT_ZOOKEEPER_PARTITION__ - Added In: Hive 0.7.0 with HIVE-1293
ZooKeeperHiveLockManager 为 hive 锁管理器 时的默认分区名称。