Linux三剑客与正则
目录
正则表达式
text测试文件
正则符号分类
基础正则符号
正则表达式的贪婪性
扩展正则符号
linux三剑客
三剑客特点及应用场景
grep
sed
sed命令执行过程
sed查找script
sed删除script
sed增加script
具体功能
具体script
sed替换script
后向引用
awk
awk执行过程
awk的行与列
awk的内置变量
取行script
取列script
awk取行取列
BEGIN{}与END{}
awk数组
作用
使用案例
批量输出数组内容
awk的for循环
awk的if判断
正则表达式
text测试文件
[root@CentOS7-1 ~]# cat test
hello : orange : bird : cat : 21
Apple : cow : cup : desk : 12
deep : dog : app : country : 11
computer : phone : bag : paper : 8含义:用于匹配有规律的东西的表达式
正则符号分类

基础正则符号
^:以……开头的行
test文件执行命令:grep '^deep' test
[root@CentOS7-1 ~]# grep '^deep' test
deep : dog : app : country : 11$:以……结尾的行
test文件执行命令:grep '11$' test
[root@CentOS7-1 ~]# grep '11$' test
deep : dog : app : country : 11注意:^$表示空行(这一行中没有任何东西)
.(点):表示任意一个字符
注意:点不匹配空行
test文件执行命令:grep '.' test

\:转义字符
需求:匹配出文件中以点结尾的行
对于app文件
[root@CentOS7-1 ~]# cat app
i am a dog.
no no no
I said this without thinking about it.执行:grep '\.$' app
[root@CentOS7-1 ~]# grep '\.$' app
i am a dog.
I said this without thinking about it.*:前一个字符出现了0次或以上
注意:所有内容都会显示出来——因为可以当作出现0次
test文件执行命令:grep 'a*' test

注意:
- .*表示所有内容
- .*表示所有,或*连续出现时,表现出尽可能的贪婪(匹配的更多)
正则表达式的贪婪性
对于test文件执行:grep '^.*o' test

结论:由此观之,总是直接匹配到最后一个o,贪婪
[]:匹配任何一个字符(只能算一个)
如:[a,b,c]相当于a或b或c
注意:
- [a-z]:匹配小写字母任意一个
- [0-9]:匹配数字任意一个
- [a-Z]:匹配大小写字母任意一个([a-zA-Z]也可)
- [a-z | A-Z | 0-9]:匹配字母和数字和|([]里的内容去掉特殊含义)
- [^abc]:匹配除了a,b,c之外的任意一个字符(^在中括号里表示取反)
对于test文件执行:grep '[a,b]' test

扩展正则符号
前言:grep只支持基础正则,扩展正则使用egrep或-E
+:前一个字符出现了一次或多次以上
注意:[0-9]+:匹配连续出现的数字(一次或多次)
对于test文件执行:egrep 'p+' test

|:或者
对于test文件执行:egrep 'a|b' test

[]与|的区别
- []一次匹配一个字符
- |匹配一个或多个字符
():被括起来的内容表示一个整体
需求:我要选择oldboy或oldbey
对于person文件
[root@CentOS7-1 ~]# cat person
haha oldboy hello
beautiful oldbey hi
in the park执行:egrep '(oldboy|oldbey)' person
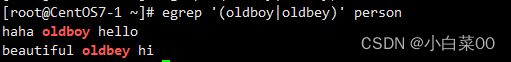
{}:表示连续出现
理解:
- o{n,m}表示o至少出现了n次,至多出现m次
- o{n}表示o连续出现n次(超过也可)
- o{n,}表示o至少出现n次,多了不限
- o{,m}表示o最多出现m次,少了不管
对于test文件执行:egrep 'p{2,3}' test

?:表示字符出现了0次或1次
对于test文件执行:egrep 'de?s?' test

linux三剑客
三剑客特点及应用场景
| 命令 | 特点 | 场景 |
| grep | 过滤 | grep命令过滤速度最快 |
| sed | 替换,修改文件内容,取行 | 替换/修改文件内容,取出某个范围内的内容 |
| awk | 取列,统计计算 | 取列,对比,比较,统计,计算 |
grep
作用:对文本进行搜索
语法:grep [options] 搜索内容 具体路径的文件名1 具体路径的文件名2
options
- -n:显示行号
- -w:精确匹配(匹配正正好好的数据)
- -v:显示不匹配的行
- -i:忽略大小写
- -o:显示匹配过程
- -c:统计匹配好的出现了多少行
- -E:使用扩展正则表达式匹配(相当于egrep)
- -A n:匹配你要的内容显示接下来的n行
- -B n:匹配你要的内容显示上面的n行
- -C n:匹配你想要的内容显示上下n行
注意:可以同时搜索多个文件
对于test文件执行:grep -ni app test
[root@CentOS7-1 ~]# grep -ni app test
2:Apple : cow : cup : desk : 12
3:deep : dog : app : country : 11app文件内(验证精确匹配)
[root@CentOS7-1 ~]# cat app
i am a dog.
no no not
I said this without thinking about it.执行:egrep -w 'no' app
![]()
sed
特点:stream editor流编辑器,sed把处理的内容(文件)当作是水,源源不断的进行处理,直到文件末尾
理解:sed是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓
冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理
完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件
内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化
对文件的反复操作
sed功能:增删改查
语法:sed [options] script 文件名
options
- -n:不输出现有的内容到屏幕,即不自动打印
- -r:支持使用扩展正则表达式
- -i:直接修改文本文件(若不加该参数不会修改文件)
sed命令执行过程
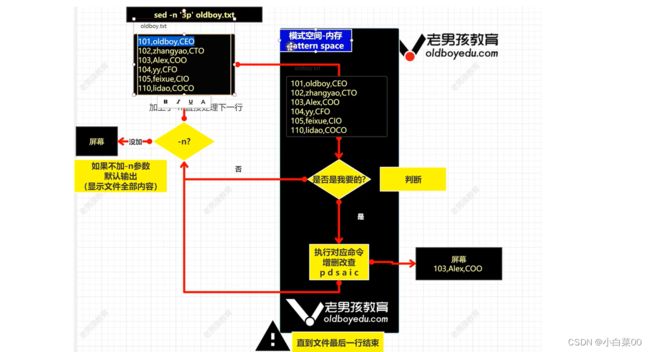
命令含义:显示文件的第三行
过程:首先在sed执行时会把文件的内容的第一行读取到内存空间,然后看该行是否是我想要的,若是自己想要的,则直接将他打印到屏幕,若不是则看看有没有-n参数,若有则不将其打印到屏幕上,没有则将其打印到屏幕上。继续处理下一行以此类推,直到结束。
sed查找script
| 查找格式 | 含义 |
| 'np' | 查找第n行 |
| 'n,mp' | 查找第n-m行 |
| '/hello/p' | 类似grep过滤(查找hello所在行),//里面可以写正则 |
| '/10:00/,/11:00/p' | 查找10点开始到11点结束这段时间内的日志 |
| 'n,/hello/p' | 混合查找(查找第n行到有hello的行) |
test文件
[root@CentOS7-1 ~]# cat test
hello : orange : bird : cat : 21
Apple : cow : cup : desk : 12
deep : dog : app : country : 11
computer : phone : bag : paper : 8执行:sed -n /cou/p test
[root@CentOS7-1 ~]# sed -n /cou/p test
deep : dog : app : country : 11sed删除script
| 删除格式 | 含义 |
| 'nd' | 删除第n行 |
| 'n,md' | 删除第n-m行 |
| '/hello/d' | 类似grep过滤(删除hello所在行),//里面可以写正则 |
| '/10:00/,/11:00/d' | 删除10点开始到11点结束这段时间内的日志 |
| 'n,/hello/d' | 混合删除(删除第n行到有hello的行) |
test文件
[root@CentOS7-1 ~]# cat test
hello : orange : bird : cat : 21
Apple : cow : cup : desk : 12
deep : dog : app : country : 11
computer : phone : bag : paper : 8执行:sed /app/d test
[root@CentOS7-1 ~]# sed /app/d test
hello : orange : bird : cat : 21
Apple : cow : cup : desk : 12
computer : phone : bag : paper : 8sed增加script
具体功能
| 功能 | 含义 |
| c | replace替代这行的内容 |
| a | append追加,向指定行或某一行后面追加内容 |
| i | insert插入,向指定行或每一行前面插入内容 |
具体script
| 命令 | 含义 |
| 'na 要加的内容' | 在n行后面添加要添加的内容(添加行) |
| 'ni 要加的内容' | 在n行前面添加要添加的内容(添加行) |
| 'nc 要替换的内容' | 将n行内容删除后换上新内容 |
| 'n,ma hello' | 在n行到m行之后均添加hello这一行 |
| '/hello/a hi' | 在hello行的后面添加hi这一行 |
| 'n,/hello/a hello' | 在n行和有hello的行之后添加hello这一行 |
注意:格式也支持上述格式
对于test文件
[root@CentOS7-1 ~]# cat test
hello : orange : bird : cat : 21
Apple : cow : cup : desk : 12
deep : dog : app : country : 11
computer : phone : bag : paper : 8执行:sed '2,4i hello' test
[root@CentOS7-1 ~]# sed '2,4i hello' test
hello : orange : bird : cat : 21
hello
Apple : cow : cup : desk : 12
hello
deep : dog : app : country : 11
hello
computer : phone : bag : paper : 8sed替换script
| 命令 | 含义 |
| 's/数据1/数据2/g' | 全局将数据1替换成数据2 |
| 's/数据1/数据2/' | 将每行的第一个数据1替换成数据2 |
注意:g为global全局替换,sed默认只替换每行第一个匹配的内容
test文件
[root@CentOS7-1 ~]# cat test
hello : orange : bird : cat : 21
Apple : cow : cup : desk : 12
deep : dog : app : country : 11
computer : phone : bag : paper : 8
cup app cup puc执行:sed s/cup/haha/g test
[root@CentOS7-1 ~]# sed s/cup/haha/g test
hello : orange : bird : cat : 21
Apple : cow : haha : desk : 12
deep : dog : app : country : 11
computer : phone : bag : paper : 8
haha app haha puc后向引用
使用方法:先保护,再引用
需求:将oldboy_lidao改成lidao_oldboy
执行:echo oldboy_lidao | sed -r 's/(^.*)_(.*$)/\2_\1/g'
[root@CentOS7-1 ~]# echo oldboy_lidao | sed -r 's/(^.*)_(.*$)/\2_\1/g'
lidao_oldboy解释:先将要用的内容用小括号保护起来,后面的\n就为前面第n个小括号内的引用。
awk
前言:awk是一门语言,主要用来统计、过滤和计算
awk执行过程
案例:awk -F, 'BEGIN{print "name"}{print $2}END{print "end of file"}' oldboy.txt

理解:awk读取文件之前,先看看命令行里有什么参数并处理begin{}的代码,awk读取文件时先从文件读取一行放到内存中,看该行是否满足条件,满足条件则执行对应的动作,不满足条件看是不是最后一行,若是直接就执行end{}里的代码,不是则从文件中取出另外一行依此类推直到文件结束后执行end{}的代码
注意:awk读取文件之前就可以执行命令行的参数或者begin{}
语法:awk [options] script 文件名
options
- -F 分隔符:指定分隔符,指定每一列结束标记(默认空格/制表符)
- -v val=val:在执行处理过程之前,设置一个变量var,并给其设备的初始值为val。
awk的行与列
| 名词 | awk中的叫法 | 一些说明 |
| 行 | 记录(record) | 每一行默认通过回车分割的 |
| 列 | 字段(field) | 每一行默认通过空格分割的 |
awk的内置变量
| 内置变量 | 说明 |
| NR | Number of Record(记录号,行号) |
| NF | Number of Field(每行有多少字段,$NF为最后一列) |
| FS | Field Separator字段分隔符,每个字段的结束标记 |
| OFS | Output Field Separator,输出字段分隔符(awk显示每列的时候,每列之间用什么分割,默认空格) |
取行script
| 命令 | 说明 |
| ’NR==1'(这里的符号是灵活的) | 取出第一行 |
| 'NR>=1&&NR<=5' | 取出1到5行 |
| '/hello/' | 取出hello所在的行 |
| '/2/,/4/' | 取出2行到4行 |
符号:>,<,>=,<=,==,!=
test文件
[root@CentOS7-1 ~]# cat test
hello : orange : bird : cat : 21
Apple : cow : haha : desk : 12
deep : dog : app : country : 11
computer : phone : bag : paper : 8执行:awk NR==1 test
[root@CentOS7-1 ~]# awk NR==1 test
hello : orange : bird : cat : 21执行:awk /cow/ test
[root@CentOS7-1 ~]# awk /cow/ test
Apple : cow : haha : desk : 12取列script
| 命令 | 说明 |
| '{print $n}' | 取出第n列 |
| '{print $n,$m}' | 取出第n列和第m列 |
| '{print $NF}' | 取出最后一列 |
| '{print $n"cjc"$m}' | 取出第n列和第m列,并在之间写上cjc |
| '$2~/g/' | 确定第二列中包含g的行 |
注意:
- 在awk中"$n"代表取出第n列
- 通常情况下,取列与-F参数一同使用
- 正则表达式中~表示包含,!~表示不包含
test文件
[root@CentOS7-1 ~]# cat test
hello : orange : bird : cat : 21
Apple : cow : haha : desk : 12
deep : dog : app : country : 11
computer : phone : bag : paper : 8执行:awk -F : '{print $2,$5}' test
[root@CentOS7-1 ~]# awk -F : '{print $2,$5}' test
orange 21
cow 12
dog 11
phone 8(OFS相关)执行:awk -F: -v OFS=? '{print $2,$4}' test
[root@CentOS7-1 ~]# awk -F: -v OFS=? '{print $2,$4}' test
orange ? cat
cow ? desk
dog ? country
phone ? paper awk取行取列
test文件取3行2列:awk -F: 'NR==3{print $2}' test
[root@CentOS7-1 ~]# awk -F: 'NR==3{print $2}' test
dog BEGIN{}与END{}
| 模式 | 含义 | 应用场景 |
| BEGIN{} | 里面的内容会在awk读取文件之前进行 | 1进行简单统计,不涉及读取文件 2用于在处理文件之前添加个表头 3用于定于awk变量 |
| END{} | 里面的内容会在awk读取文件之后进行 | 1awk进行统计,一般过程:先进行计算,最后在END里面输出结果 2awk使用数组,用来输出数组的结果 |
需求:计算从1加到100
执行:seq 100 | awk 'BEGIN{print "start"}{sum=sum+$1}END{print sum}'
[root@CentOS7-1 ~]# seq 100 | awk 'BEGIN{print "start"}{sum=sum+$1}END{print sum}'
start
5050awk数组
作用
- 统计次数:类似于统计每个ip出现次数、统计每种状态码出现的次数、统计系统中每个用户被攻击的次数,统计攻击者ip出现的次数
- 累计求和:统计每个ip消耗的流量
使用案例
执行:awk 'BEGIN{a[0]=12306;a[1]="hello"; print a[0],a[1]}'
[root@CentOS7-1 ~]# awk 'BEGIN{a[0]=12306;a[1]="hello"; print a[0],a[1]}'
12306 hello注意:awk字母会被识别为变量,若只想使用字符串,则需要将该字母引起来
批量输出数组内容
语法:for(i in array) print array[i]
执行:awk 'BEGIN{a[0]=12306;a[1]="hello"; for(i in a) print i,a[i]}'
[root@CentOS7-1 ~]# awk 'BEGIN{a[0]=12306;a[1]="hello"; for(i in a) print i,a[i]}'
0 12306
1 helloawk的for循环
前言:awk的for循环一般用来循环每个字段的
for(i=1;i<=10;i++)
print iawk的if判断
if(条件)
print("success")
else
print("fail")案例:统计这段语句中,单词字符数小于6的单词,并显示出来
语句:echo I am oldboy teacher welcome to oldboy training class.
执行:echo I am oldboy teacher welcome to oldboy training class.|awk -F"[ .]" '{for(i=1;i<=NF;i++) if(length($i)<6) print $i}'
[root@CentOS7-1 ~]# echo I am oldboy teacher welcome to oldboy training class.|awk -F"[ .]" '{for(i=1;i<=NF;i++) if(length($i)<6) print $i}'
I
am
to
class