动态内存管理学习分享
动态内存管理学习分享
- 1. 为什么存在动态内存分配
- 2. 动态内存函数的介绍
-
- 2.1 [malloc](https://legacy.cplusplus.com/reference/cstdlib/malloc/?kw=malloc)和[free](https://legacy.cplusplus.com/reference/cstdlib/free/?kw=free)
-
- 2.1.1 实例
- 2.2 [calloc](https://legacy.cplusplus.com/reference/cstdlib/calloc/?kw=calloc)
-
- 2.2.1 实例
- 2.3 [realloc](https://legacy.cplusplus.com/reference/cstdlib/realloc/?kw=realloc)
- 3. 常见的动态内存错误
-
- 3.1 对NULL指针的解引用操作
- 3.2 对动态开辟空间的越界访问
- 3.3 对非动态开辟内存使用free释放
- 3.4 使用free释放一块动态开辟内存的一部分
- 3.5 对一块动态内存进行多次释放
- 3.6 开辟动态内存忘记释放([内存泄漏](http://t.csdn.cn/x2vbA))
- 4 C/C++程序的内存开辟
- 5 柔性数组
-
- 5.1 柔性数组的特点
- 5.2 柔性数组的使用
- 5.3 柔性数组的优势
- 6. 结尾

1. 为什么存在动态内存分配
我们常见的内存开辟方式有:
int val = 20;///在栈上开辟4个字节空间
char arr[10] = { 0 };//在栈上开辟连续10个字节的连续空间
但上述开辟空间的方式有两个特点:
- 开辟的空间大小是固定的。
- 数组在申明的时候,必须指定数组的长度,它所需的内存在编译时分配。
但是对于空间的需求,不仅仅是上述的情况。有时我们需要的空间大小在运行时才能知道。
那数组在编译时开辟空间的方式就不能满足需求了!!
这时就只能试试动态内存开辟了。
2. 动态内存函数的介绍
2.1 malloc和free
C语言提供了一个动态内存开辟的函数:
void* malloc (size_t size);
这个函数可以向内存申请一块连续可用的空间,并返回指向这块空间的指针。
-
如果开辟成功,则返回一个指向开辟好空间的指针。
-
如果开辟失败,则返回一个NULL指针,因此malloc的返回值一定要做检查。
-
返回值的类型是void*,所以malloc函数并不知道开辟内存空间的类型,具体在使用的时候使用者自己来决定。
-
如果参数size为0,malloc的行为是标准未定义的,取决于编译器。
C语言提供了另一个函数free,专门是用来做动态内存的释放和回收的,函数原型如下:
void free (void* ptr);
1. 如果参数ptr指向的空间不是内存开辟的,那么free函数的行为是未定义的。
2. 如果参数ptr是NULL指针,则函数什么事都不做。
malloc和free都声明在stdlib.h头文件中。
Tips:
- malloc函数申请到空间后,直接返回这块空间的起始地址,并不会初始化空间的内容。
- malloc函数申请的内存空间,当程序退出时会还给操作系统。但当程序没有退出时,动态申请的空间不会主动释放。需要使用free函数来释放。
2.1.1 实例
#include 运行结果:
![]()
2.2 calloc
C语言还提供了一个叫calloc,calloc函数也用来动态内存分配。原型如下:
void* calloc (size_t num, size_t size);
- 函数的功能是为num个大小为=ize的元素开辟一块空间,并且把空间的每一个字节初始化为0。
- 与函数malloc的区别只在于calloc在返回地址之前会将申请到的空间的每个字节初始化为0。
2.2.1 实例
int main()
{
int* p = (int*)calloc(10, sizeof(int));
if (p == NULL)
{
perror("calloc");
return 1;
}
for (int i = 0; i < 10; i++)
{
printf("%d:%p\n", p[i],&p[i]);
}
return 0;
}
结果:

2.3 realloc
realloc函数的出现让动态内存管理更加灵活。
过去有时我们会发现申请的空间太小了,有时候我们又会觉得申请的空间太大了,那为了开辟合理内存,我们一定会对内存的大小做灵活的调整。那么realloc函数就可以做到对动态开辟内存的大小进行调整。
函数原型如下:
void* realloc (void* ptr, size_t size);
- ptr是要调整的内存地址,size为调整后的新大小。
- 返回值为调整之后的内存起始位置。
- realloc在调整内存空间时会存在两种情况:
。在原有空间之后有足够大小的空间:要扩展内存之后直接追加空间,原来空间的数据不发生变化。
。原有空间之后没有足够大的空间:在栈空间上另找一个合适大小的连续空间重新开辟一块内存空间,并将旧空间中的数据拷贝到新的空间,并释放旧空间,返回新空间的起始位置。
3. 常见的动态内存错误
3.1 对NULL指针的解引用操作
int main()
{
int* p = (int*)malloc(40);
//没有进行判断是否开辟成功
//若开辟失败,则p为空指针。
//对空指针进行解引用操作是非法的
*p = 20;
free(p);
return 0;
}
3.2 对动态开辟空间的越界访问
int main()
{
int* p = (int*)malloc(40);//开辟10字节空间
if (p == NULL)
{
perror("malloc");
return 1;
}
for (int i = 0; i <= 10; i++)//越界访问
{
*(p + i) = i + 1;
}
free(p);
p = NULL;
return 0;
}
3.3 对非动态开辟内存使用free释放
int main()
{
int a = 10;
int* p = &a;
free(p);//err
return 0;
}
后果:
对非动态开辟内存释放会导致内存泄漏,如果内存泄漏发生在长时间运行的程序中,可能会导致系统资源耗尽,使整个系统变得不稳定。
3.4 使用free释放一块动态开辟内存的一部分
int main()//err
{
int* p = (int*)malloc(40);
if (p == NULL)
{
perror("malloc");
return 1;
}
for (int i = 0; i < 10; i++)
{
*p = i + 1;
p++;//p在不断向后移动
}
//释放
free(p);//释放时,只是放了一小部分
p = NULL;
return 0;
}
后果:
释放部分内存可能会导致内存损坏,因为该内存可能被后续的内存分配操作重叠使用。这可能导致程序崩溃、数据损坏或其他不可预测的行为。
3.5 对一块动态内存进行多次释放
int main()
{
int* p = (int*)malloc(40);
if (p == NULL)
{
perror("malloc");
return 1;
}
//释放
free(p);
p = NULL;
free(p);//err,多次释放
return 0;
}
后果:
1.数据损坏:重复释放内存可能导致未定义的行为,包括数据损坏。当重复释放内存后,其他变量可能会被覆盖或改变,导致程序出现逻辑错误或不可预测的行为。
2.安全漏洞:重复释放内存可能导致安全漏洞。恶意攻击者可以利用重复释放内存的漏洞来执行代码注入、缓冲区溢出等攻击。
3.6 开辟动态内存忘记释放(内存泄漏)
在前面已经多次提及这个问题,在此就不再过多介绍了。
4 C/C++程序的内存开辟
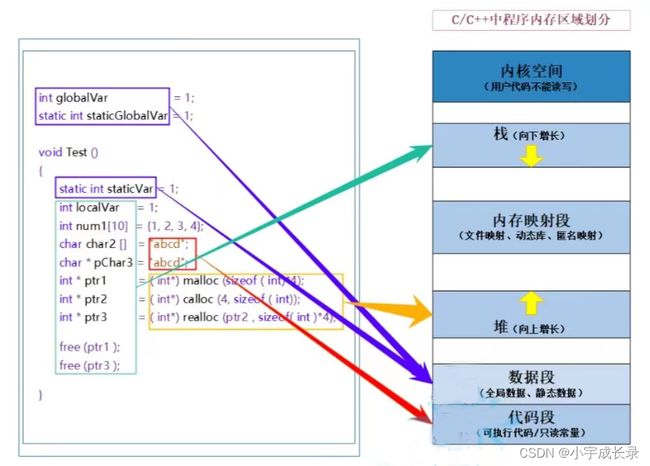
C/C++程序内存分配的几个区域:
①:栈区(stack):在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元会自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。栈区主要存放运算函数而分配的局部变量、函数参数、返回数据、返回地址等。
②:堆区(heap):一般有程序员分配释放,若程序员不释放,程序结束时可能由QS回收。分配方式类似于链表。
③:数据段(静态区)(stack)存放全局变量、静态数据。程序结束后由系统释放。
④:代码段:存放函数体(类成员函数和全局变量)的二进制代码。
同时也能解释为什么static修饰局部变量导致其生命周期变长。
实际上普通的局部变量是在栈区分配空间的,栈区的特点是上面创建的变量出作用于后销毁。
但是被static修饰的局部变量存放在数据段(静态区),数据段上的特点是在上面创建的变量,直到按程序结束才销毁。
所以生命周期变长。
5 柔性数组
也许你没听过柔性数组(flexible array) 数组这个概念,但它是的确存在的。
C99中,结构中的最后一个元素允许是未知大小的数组,这就叫做 【柔性数组] 的成员。
例如:
//在C语言中,柔性数组有两种声明形式,具体具体取决与编译器:
//第一种声明方式
struct S
{
int i;
int arr[];//柔性数组,前面至少有一个成员
};
//第二种声明方式
struct S
{
int i;
int arr[0];//柔性数组
};
5.1 柔性数组的特点
- 结构中的柔性数组成员前面必须至少有一个成员。
- sizeof返回的这种结构大小不包括柔性数组的内存。
- 包含柔性数组成员的结构用malloc函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小。
例如:
typedef struct S
{
int i;
int arr[];
}type_s;
sizeof("%d\n", sizeof(type_s));//输出的是4
5.2 柔性数组的使用
typedef struct S
{
int i;
int arr[];
}type_s;
int main()
{
int i = 0;
type_s* p = (type_s*)malloc(sizeof(type_s) + 100 * sizeof(int));
if (p == NULL)
{
perror("malloc->type_s");
return 1;
}
//业务处理
p->i = 100;
for (i = 0; i < 100; i++)
{
p->arr[i] = i + 1;
}
free(p);
p = NULL;
return 0;
}
这样的柔性数组成员a,相当于获得了100个整形元素的连续空间。
5.3 柔性数组的优势
上述的type_s结构也可以设计为:
typedef struct S
{
int i;
int* p_a;
}type_s;
int main()
{
type_s* p = (type_s*)malloc(sizeof(type_s));
if (p == NULL)
{
perror("malloc->type_s");
return 1;
}
p->i = 100;
int* ptr = realloc(p->p_a, 4 * sizeof(int));
if (ptr == NULL)
{
perror("malloc->p_s");
return 1;
}
else
{
p->p_a = ptr;
}
//业务处理
for (int i = 0; i < 100; i++)
{
p->p_a[i] = i + 1;
}
//释放
free(p->p_a);
p->p_a = NULL;
free(p);
p = NULL;
return 0;
}
上述两种代码可以完成完全相同的功能,但是第一种实现有两个好处:
第一个好处:方便内存释放
如果我们的代码是在一个给别人的函数中,你在里面做了二次内存分配,并把整个结构体返回给用户。用户调用free可以释放结构体,但是用户并不知道这个结构体的成员也需要free,所以你不能指望用户来发现这个事。所以,我们把结构体的内存以及其成员要的内存一次性分配好了,并返回给用户一个结构体指针,用户做一次free就可以把所有的内存都释放掉。
第二个好处:有利于访问速度
连续的内存有益于提高访问速度,有利于减少内存碎片。(但其实这个因素产生的结果也高不了多少,反正你跑不了用偏移量的加法来寻址)。
拓展阅读:
C语言结构体的数组和指针
6. 结尾
本篇博客到此就结束了,如果对你有帮助记得三连哦。感谢您的支持!!