Golang速成
目录
- Golang 语言特性
-
- Golang的优势
- Golang 的应用场景
- Golang 的不足
- 基础语法
-
- 变量的声明
- 常量与 iota
- string
-
- 字符串遍历
- strings 包
- bytes 包
- strconv 包
- unicode 包
- 循环语句
-
- range
- 函数
-
- 多返回值
- init 函数
- 闭包
- import 导包
- 匿名函数
- 指针
- defer
- 切片 slice
-
- 数组
- slice
- slice 操作
- …
- map
-
- map 的声明
- map 的使用
- error
- 面向对象编程
-
- type
- 方法
- struct
- 封装
- 继承
- 多态
-
- 不同接收者实现接口
- 通用万能类型
- 反射
-
- 变量内置 Pair 结构
- reflect
-
- 结构体标签
- 并发知识
-
- 基础知识
- 早期调度器的处理
- GMP模型
- 调度器的设计策略
- 并发编程
-
- goroutine
- channel
- 无缓冲的 channel
- 有缓冲的 channel
- 关闭 channel
- channel 与 range
- channel 与 select
- Go Modules
-
- go mod 命令
- go mod 环境变量
-
- GO111MODULE
- GOPROXY
- GOSUMDB
- GOPRIVATE
- 初始化项目
- 修改项目版本依赖关系
- Golang 生态拓展
-
- Web 框架
- 微服务框架
- 容器编排
- 服务发现
- 存储引擎
- 静态建站
- 中间件
- 爬虫框架
Golang 语言特性
Golang的优势
静态类型语言:编译的时候检查出来隐藏的大多数问题
语言层面的并发:
- 天生的基因支持
- 充分的利用多核
强大的标准库:
- runtime系统调度机制
- 高效的GC垃圾回收
- 丰富的标准库
简单易学:
- 25个关键字
- C语言简洁基因,内嵌C语法支持
- 面向对象特征(继承、多态、封装)
- 跨平台
Golang 的应用场景
1、云计算基础设施领域:
代表项目:docker、kubernetes、etcd、consul、cloud flare CDN、七牛云存储 等。
2、基础后端软件:
代表项目:tidb、influxdb、 cockroach 等。
3、微服务
代表项目:go-kit、 micro、 monzo bank 的 typhon、bilibili 等。
4、互联网基础设施
代表项目:以太坊、hyperledger 等。
Golang 的不足
1、包管理,大部分包都托管在 Github 上。
托管在 Github 上的代码容易被作者个人操作影响到使用该项目的工程
2、无泛化类型。
后面版本可能会有
3、所有 Exception 都用 Error 来处理(有争议)。
4、对 C 的降级处理,并非无缝,没有 C 降级到 asm 那么完美。(序列化问题)
基础语法
package main
// 导多个包
import (
"fmt"
"time"
)
// Golang 有无 ; 都可,建议不加
func main() { // 函数的 { 必须和函数名同行, 否则编译报错
fmt.Println("Hello Go!")
time.Sleep(1 * time.Second)
}
变量的声明
输出变量类型的方法:
var a int
fmt.Printf("type of a = %T\n", a)
// type of a = int
局部变量的声明:
// 方法一:声明一个变量 默认的值是0
var a int
// 方法二:声明一个变量,初始化一个值
var b int = 100
// 方法三:初始化的时候, 省去数据类型,通过值自动匹配当前的变量的数据类型
var c = 100
// 方法四:(常用) 省去var关键字,直接自动匹配
d := 100
全局变量的声明:以上只有方法四不支持(编译会报错)
多变量的声明:
// 单行写法
var xx, yy int = 100, 200
var kk, ll = 100, "Aceld"
// 多行写法
var (
vv int = 100
jj bool = true
)
常量与 iota
使用 const 定义常量,常量是只读的,不允许修改
const a int = 10
const (
a = 10
b = 20
)
const 可以用来定义枚举:
const {
BEIJING = 0
SHANGHAI = 1
SHENZHEN = 3
}
const 可以和 iota 一起使用来定义有规则的枚举:
const (
// 可以在const() 添加一个关键字 iota, 每行的iota都会累加1, 第一行的iota的默认值是0
BEIJING = iota // iota = 0
SHANGHAI // iota = 1
SHENZHEN // iota = 2
)
const (
a, b = iota+1, iota+2 // iota = 0, a = iota + 1, b = iota + 2, a = 1, b = 2
c, d // iota = 1, c = iota + 1, d = iota + 2, c = 2, d = 3
e, f // iota = 2, e = iota + 1, f = iota + 2, e = 3, f = 4
g, h = iota * 2, iota *3 // iota = 3, g = iota * 2, h = iota * 3, g = 6, h = 9
i, k // iota = 4, i = iota * 2, k = iota * 3 , i = 8, k = 12
)
string
对于字符串操作的 4 个包:bytes、strings、strconv、unicode
- bytes 包操作 []byte。因为字符串是只读的,因此逐步构创建字符串会导致很多分配和复制,使用bytes.Buffer 类型会更高。
- strings 包提供 切割、索引、前缀、查找、替换 等功能。
- strconv 包提供 布尔型、整型数、浮点数 和对应字符串的相互转换,还提供了双引号转义相关的转换。
- unicode 包提供了 IsDigit、IsLetter、IsUpper、IsLower 等类似功能,用于给字符分类。
如果 string 中包含汉字,要注意:
- UTF-8 编码中,一个汉字需要 3 个字节,通过
len()获取的是字符串占据的字节数。
str1 := "hello 世界"
fmt.Println(len(str1)) // 12
- 如果想要得到字符串本身的长度,可以将 string 转为 rune 数组再计算:
str2 := "hello 世界"
fmt.Println(len([]rune(str2))) // 8
字符串遍历
byte 是 uint8 的别名
rune 是 int32 的别名,相当于 Go 里面的 char
如果包含汉字,以下遍历方式会出现乱码:
str := "你好世界!"
for i := 0; i < len(str); i++ {
fmt.Printf("%c", str[i])
}
// ä½ å¥½ä¸çï¼%
- 解决方案1:转成 rune 切片再遍历
str := "你好世界!"
newStr := []rune(str)
for i := 0; i < len(newStr); i++ {
fmt.Printf("%c", newStr[i])
}
// 你好世界!
- 解决方案2:使用 range 来遍历
range 按照字符遍历,前面的 for 按照字节遍历
str := "你好世界123"
for index, value := range str {
fmt.Printf("index = %d value = %c\n", index, value)
}
/*
index = 0 value = 你
index = 3 value = 好
index = 6 value = 世
index = 9 value = 界
index = 12 value = 1
index = 13 value = 2
index = 14 value = 3
*/
strings 包
字符串比较:使用 strings.Compare 比较两个字符串的字典序
strings.Compare("aaa", "bbb") // -1
strings.Compare("baa", "abb") // 1
strings.Compare("aaa", "aaa") // 0
查找函数:使用 strings.Index 查找字符串中子串的位置(第 1 个),不存在返回 -1
strings.Index("hello world", "o") // 4
类似的,使用 strings.LastIndex 查找字符串子串出现的最后一个位置,不存在返回 -1
strings.Index("hello world", "o") // 4
Count、Repeat:
使用 strings.Count 统计子串在整体中出现的次数:
strings.Count("abc abc abab abc", "abc") // 3
使用 strings.Repeat 将字符串重复指定次数:
strings.Repeat("abc", 3) // abcabcabc
Replace、Split、Join:
strings.Replace 实现字符串替换
str := "acaacccc"
// 局部替换 param3: 替换次数,< 0 则全部替换
strings.Replace(str, "a", "b", 2) // bcbacccc
strings.Replace(str, "a", "b", -1) // bcbbcccc
// 全部替换
strings.ReplaceAll(str, "a", "b") // bcbbcccc
strings.Split 实现字符串切割
str := "abc,bbc,bbd"
slice := strings.Split(str, ",")
fmt.Println(slice) // [abc bbc bbd]
strings.Join 实现字符串拼接
slice := []string{"aab", "aba", "baa"}
str := strings.Join(slice, ",")
fmt.Println(str // aab,aba,baa
bytes 包
Buffer 是 bytes 包中定义的 type Buffer struct {...},Bufer 是一个变长的可读可写的缓冲区。
创建缓冲器:bytes.NewBufferString、bytes.NewBuffer
func main() {
buf1 := bytes.NewBufferString("hello")
buf2 := bytes.NewBuffer([]byte("hello"))
buf3 := bytes.NewBuffer([]byte{'h', 'e', 'l', 'l', 'o'})
fmt.Printf("%v,%v,%v\n", buf1, buf2, buf3)
fmt.Printf("%v,%v,%v\n", buf1.Bytes(), buf2.Bytes(), buf3.Bytes())
buf4 := bytes.NewBufferString("")
buf5 := bytes.NewBuffer([]byte{})
fmt.Println(buf4.Bytes(), buf5.Bytes())
}
/*
hello,hello,hello
[104 101 108 108 111],[104 101 108 108 111],[104 101 108 108 111]
[] []
*/
写入缓冲器:Write、WriteString、WriteByte、WriteRune、WriteTo
func main() {
buf := bytes.NewBufferString("a")
fmt.Printf("%v, %v\n", buf.String(), buf.Bytes())
// a, [97]
buf.Write([]byte("b")) // Write
buf.WriteString("c") // WriteString
buf.WriteByte('d') // WriteByte
buf.WriteRune('e') // WriteRune
fmt.Printf("%v, %v\n", buf.String(), buf.Bytes())
// abcde, [97 98 99 100 101]
}
缓冲区原理介绍:Go 字节缓冲区底层以字节切片做存储,切片存在长度 len 与容量 cap
- 缓冲区从长度 len 的位置开始写,当 len > cap 时,会自动扩容
- 缓冲区从内置标记 off 位置开始读(off 始终记录读的起始位置)
- 当 off == len 时,表明缓冲区已读完,读完就重置缓冲区 len = off = 0
func main() {
byteSlice := make([]byte, 20)
byteSlice[0] = 1 // 将缓冲区第一个字节置1
byteBuffer := bytes.NewBuffer(byteSlice) // 创建20字节缓冲区 len = 20 off = 0
c, _ := byteBuffer.ReadByte() // off+=1
fmt.Printf("len:%d, c=%d\n", byteBuffer.Len(), c) // len = 20 off =1 打印c=1
byteBuffer.Reset() // len = 0 off = 0
fmt.Printf("len:%d\n", byteBuffer.Len()) // 打印len=0
byteBuffer.Write([]byte("hello byte buffer")) // 写缓冲区 len+=17
fmt.Printf("len:%d\n", byteBuffer.Len()) // 打印len=17
byteBuffer.Next(4) // 跳过4个字节 off+=4
c, _ = byteBuffer.ReadByte() // 读第5个字节 off+=1
fmt.Printf("第5个字节:%d\n", c) // 打印:111(对应字母o) len=17 off=5
byteBuffer.Truncate(3) // 将未字节数置为3 len=off+3=8 off=5
fmt.Printf("len:%d\n", byteBuffer.Len()) // 打印len=3为未读字节数 上面len=8是底层切片长度
byteBuffer.WriteByte(96) // len+=1=9 将y改成A
byteBuffer.Next(3) // len=9 off+=3=8
c, _ = byteBuffer.ReadByte() // off+=1=9 c=96
fmt.Printf("第9个字节:%d\n", c) // 打印:96
}
缓冲区:
func main() {
buf := &bytes.Buffer{}
// 写缓冲区
buf.WriteString("abc?def")
// 从缓冲区读(分隔符为 ?)
str, _ := buf.ReadString('?')
fmt.Println("str = ", str)
fmt.Println("buff = ", buf.String())
}
/*
str = abc?
buff = def
*/
缓冲区读数据:Read、ReadByte、ReadByes、ReadString、ReadRune、ReadFrom
func main() {
log.SetFlags(log.Lshortfile)
buff := bytes.NewBufferString("123456789")
log.Println("buff = ", buff.String()) // buff = 123456789
// 从缓冲区读取4个字节
s := make([]byte, 4)
n, _ := buff.Read(s)
log.Println("buff = ", buff.String()) // buff = 56789
log.Println("s = ", string(s)) // s = 1234
log.Println("n = ", n) // n = 4
// 从缓冲区读取4个字节
n, _ = buff.Read(s)
log.Println("buff = ", buff.String()) // buff = 9
log.Println("s = ", string(s)) // s = 5678
log.Println("n = ", n) // n = 4
n, _ = buff.Read(s)
log.Println("buff = ", buff.String()) // buff =
log.Println("s = ", string(s)) // s = 9678
log.Println("n = ", n) // n = 1
buff.Reset()
buff.WriteString("abcdefg")
log.Println("buff = ", buff.String()) // buff = abcdefg
b, _ := buff.ReadByte()
log.Println("b = ", string(b)) // b = a
log.Println("buff = ", buff.String()) // buff = bcdefg
b, _ = buff.ReadByte()
log.Println("b = ", string(b)) // b = b
log.Println("buff = ", buff.String()) // buff = cdefg
bs, _ := buff.ReadBytes('e')
log.Println("bs = ", string(bs)) // bs = cde
log.Println("buff = ", buff.String()) // buff = fg
buff.Reset()
buff.WriteString("编译输出GO")
r, l, _ := buff.ReadRune()
log.Println("r = ", r, ", l = ", l, ", string(r) = ", string(r))
// r = 32534 , l = 3 , string(r) = 编
buff.Reset()
buff.WriteString("qwer")
str, _ := buff.ReadString('?')
log.Println("str = ", str) // str = qwer
log.Println("buff = ", buff.String()) // buff =
buff.WriteString("qwer")
str, _ = buff.ReadString('w')
log.Println("str = ", str) // str = qw
log.Println("buff = ", buff.String()) // buff = er
file, _ := os.Open("doc.go")
buff.Reset()
buff.ReadFrom(file)
log.Println("doc.go = ", buff.String()) // doc.go = 123
buff.Reset()
buff.WriteString("中国人")
cbyte := buff.Bytes()
log.Println("cbyte = ", cbyte) // cbyte = [228 184 173 229 155 189 228 186 186]
}
strconv 包
字符串转 [ ]byte:
sum := []byte("hello")
字符串 ——> 整数:使用 strconv.Atoi 或 strconv.ParseInt
// 按照 10进制 转换,返回 int 类型
i, _ := strconv.Atoi("33234")
fmt.Printf("%T\n", i) // int
// param1:要转化的字符串
// param2:转换的进制,如 2,8,16,32
// param3:返回bit的大小(注意,字面量显示还是 int64)
i2, _ := strconv.ParseInt("33234", 10, 0)
fmt.Printf("%T\n", i2) // int64
字符串 ——> 浮点数:使用 strconv.ParseFloat
// 参数类似 ParseInt
val, _ := strconv.ParseFloat("33.33", 32)
fmt.Printf("type: %T\n", val) // type: float64
val2, _ := strconv.ParseFloat("33.33", 64)
fmt.Printf("type: %T\n", val2) // type: float64
整数 —> 字符串:使用 strconv.Iota 或 strconv.FormatInt
num := 180
// 默认按照10进制转换
f1 := strconv.Itoa(num)
// param1: 要转换的数字(必须是int64类型)
// param2: 转换的进制
f2 := strconv.FormatInt(int64(num), 10)
浮点数 —> 整数:使用 strconv.FormatFloat
num := 23423134.323422
fmt.Println(strconv.FormatFloat(float64(num), 'f', -1, 64)) // 普通模式
fmt.Println(strconv.FormatFloat(float64(num), 'b', -1, 64)) // 二进制模式
fmt.Println(strconv.FormatFloat(float64(num), 'e', -1, 64)) // 科学记数法
fmt.Println(strconv.FormatFloat(float64(num), 'E', -1, 64)) // 同上,显示为E
fmt.Println(strconv.FormatFloat(float64(num), 'g', -1, 64)) // 指数大时用科学记数,否则普通模式
fmt.Println(strconv.FormatFloat(float64(num), 'G', -1, 64)) // 同上,显示为E
/*
23423134.323422
6287599743057036p-28
2.3423134323422e+07
2.3423134323422E+07
2.3423134323422e+07
2.3423134323422E+07
*/
字符串 和 bool 类型转换:
// string --> bool
flagBool, _ := strconv.ParseBool("true")
// It accepts 1, t, T, TRUE, true, True, 0, f, F, FALSE, false, False.
// Any other value returns an error.
// bool --> string
flagStr := strconv.FormatBool(true)
unicode 包
/src/unicode/letter.go:
// 判断字符 r 是否为大写格式
func IsUpper(r rune) bool
// 判断字符 r 是否为小写格式
func IsLower(r rune) bool
// 判断字符 r 是否为 Unicode 规定的 Title 字符
// 大部分字符的 Title 格式就是其大写格式
// 只有少数字符的 Title 格式是特殊字符
// 这里判断的就是特殊字符
func IsTitle(r rune) bool
// ToUpper 将字符 r 转换为大写格式
func ToUpper(r rune) rune
// ToLower 将字符 r 转换为小写格式
func ToLower(r rune) rune
// ToTitle 将字符 r 转换为 Title 格式
// 大部分字符的 Title 格式就是其大写格式
// 只有少数字符的 Title 格式是特殊字符
func ToTitle(r rune) rune
// To 将字符 r 转换为指定的格式
// _case 取值:UpperCase、LowerCase、TitleCase
func To(_case int, r rune) rune
/src/unicode/digit.go:
// IsDigit 判断 r 是否为一个十进制的数字字符
func IsDigit(r rune) bool
/src/unicode/graphic.go:
// IsNumber 判断 r 是否为一个数字字符 (类别 N)
func IsNumber(r rune) bool
// IsLetter 判断 r 是否为一个字母字符 (类别 L)
// 汉字也是一个字母字符
func IsLetter(r rune) bool
// IsSpace 判断 r 是否为一个空白字符
// 在 Latin-1 字符集中,空白字符为:\t, \n, \v, \f, \r,
// 空格, U+0085 (NEL), U+00A0 (NBSP)
// 其它空白字符的定义有“类别 Z”和“Pattern_White_Space 属性”
func IsSpace(r rune) bool
// IsControl 判断 r 是否为一个控制字符
// Unicode 类别 C 包含更多字符,比如代理字符
// 使用 Is(C, r) 来测试它们
func IsControl(r rune) bool
// IsGraphic 判断字符 r 是否为一个“图形字符”
// “图形字符”包括字母、标记、数字、标点、符号、空格
// 他们分别对应于 L、M、N、P、S、Zs 类别
// 这些类别是 RangeTable 类型,存储了相应类别的字符范围
func IsGraphic(r rune) bool
// IsPrint 判断字符 r 是否为 Go 所定义的“可打印字符”
// “可打印字符”包括字母、标记、数字、标点、符号和 ASCII 空格
// 他们分别对应于 L, M, N, P, S 类别和 ASCII 空格
// “可打印字符”和“图形字符”基本是相同的,不同之处在于
// “可打印字符”只包含 Zs 类别中的 ASCII 空格(U+0020)
func IsPrint(r rune) bool
// IsPunct 判断 r 是否为一个标点字符 (类别 P)
func IsPunct(r rune) bool
// IsSymbol 判断 r 是否为一个符号字符
func IsSymbol(r rune) bool
// IsMark 判断 r 是否为一个 mark 字符 (类别 M)
func IsMark(r rune) bool
// IsOneOf 判断 r 是否在 set 范围内
func IsOneOf(set []*RangeTable, r rune) bool
循环语句
go 语言中的 for 循环有 3 种形式:
for init; condition; post { }
for condition { }
for { }
func main() {
numbers := [6]int{1, 2, 3, 5}
for i := 0; i < len(numbers); i++ {
fmt.Println(numbers[i])
}
i := 0
for i < len(numbers) {
fmt.Println(numbers[i])
i++
}
for i, x := range numbers {
fmt.Printf("index: %d, value: %d\n", i, x)
}
// 无限循环
for {
fmt.Println("endless...")
}
}
range
func main() {
numbers := []int{1, 2, 3, 4, 5, 6}
// 忽略value, 只取index, 支持 string/array/slice/map
for i := range numbers {
fmt.Println(numbers[i])
}
// 忽略 index
for _, n := range numbers {
fmt.Println(n)
}
// 忽略全部返回值,仅迭代
for range numbers {
}
m := map[string]int{"a": 1, "b": 2}
for k, v := range m {
fmt.Println(k, v)
}
}
函数
多返回值
单返回值的函数:
func foo1(a string, b int) int {
return 100
}
多返回值的函数:
// 返回多个返回值,匿名的
func foo2(a string, b int) (int, int) {
return 666, 777
}
// 返回多个返回值,有形参名称的
func foo3(a string, b int) (r1 int, r2 int) {
// r1 r2 属于foo3的形参,初始化默认的值是0
// r1 r2 作用域空间 是foo3 整个函数体的{}空间
fmt.Println("r1 = ", r1) // 0
fmt.Println("r2 = ", r2) // 0
// 给有名称的返回值变量赋值
r1 = 1000
r2 = 2000
return
}
func foo4(a string, b int) (r1, r2 int) {
// 给有名称的返回值变量赋值
r1 = 1000
r2 = 2000
return
}
init 函数
每个 go 程序都会在一开始执行 init() 函数,可以用来做一些初始化操作:
package main
import "fmt"
func init() {
fmt.Println("init...")
}
func main() {
fmt.Println("hello world!")
}
init...
hello world!
如果一个程序依赖了多个包,它的执行流程如下图:
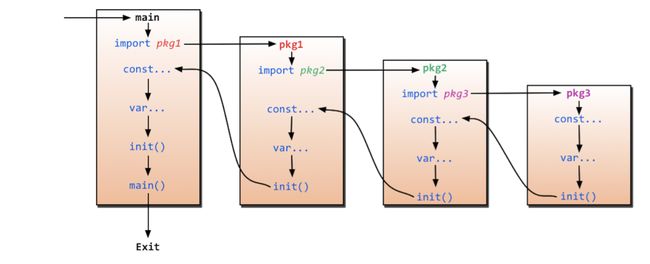
制作包的时候,项目路径如下:
$GOPATH/GolangStudy/5-init/
├── lib1/
│ └── lib1.go
├── lib2/
│ └── lib2.go
└── main.go
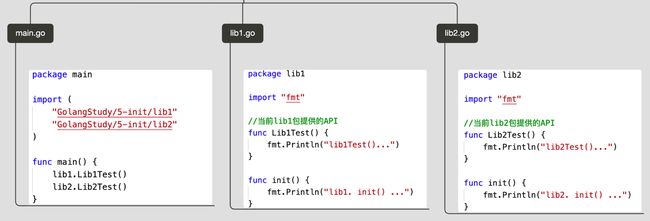
lib1 .init() ...
lib2 .init() ...
lib1Test()
lib2Test()
闭包
func a() func() int {
i := 0
b := func() int {
i++
fmt.Println(i)
return i
}
return b
}
func main() {
c := a()
c() // 1
c() // 2
c() // 3
a() // 无输出
}
import 导包
-
import _ "fmt"给 fmt 包一个匿名, ⽆法使用该包的⽅法,但是会执行该包内部的 init() 方法
-
import aa "fmt"给 fmt 包起一个别名 aa,可以用别名直接调用:
aa.Println() -
import . "fmt"将 fmt 包中的全部方法,导入到当前包的作用域中,全部方法可以直接调用,无需
fmt.API的形式
匿名函数
匿名函数的使用:
func main() {
res := func(n1 int, n2 int) int {
return n1 * n2
}(10, 20)
fmt.Printf("res: %v\n", res)
}
将匿名函数赋值给变量,通过变量调用:
func main() {
ret := func(n1 int, n2 int) int {
return n1 + n2
}
// 变量调用
sum := ret(100, 20)
fmt.Printf("sum: %v\n", sum)
// 多次调用
sum2 := ret(1000, 30)
fmt.Printf("sum2: %v\n", sum2)
}
指针


经典:在函数中交换两数的值
func swap(pa *int, pb *int) {
var temp int
temp = *pa
*pa = *pb
*pb = temp
}
func main() {
var a, b int = 10, 20
swap(&a, &b) // 传地址
fmt.Println("a = ", a, " b = ", b)
}
defer
defer 声明的语句会在当前函数执行完之后调用:
func main() {
defer fmt.Println("main end")
fmt.Println("main::hello go ")
}
/*
main::hello go
main end
*/
如果有多个 defer,依次入栈,函数返回后依次出栈执行:
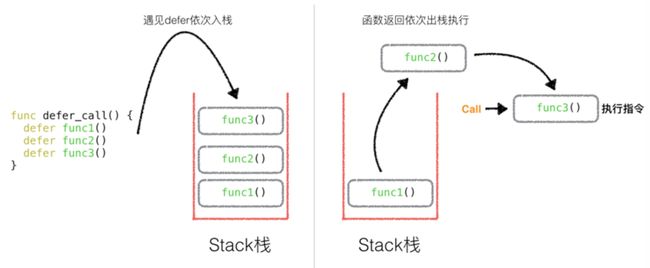
上图执行顺序:func3() -> func2() -> func1()
关于 defer 和 return 谁先谁后:
func deferFunc() int {
fmt.Println("defer func called...")
return 0
}
func returnFunc() int {
fmt.Println("return func called...")
return 0
}
func returnAndDefer() int {
defer deferFunc()
return returnFunc()
}
func main() {
returnAndDefer()
}
return func called...
defer func called...
结论:return 之后的语句先执⾏,defer 后的语句后执⾏。
切片 slice
Golang 默认都是采用值传递,有些值天生就是指针:slice、map、channel。
注意:固定长度数组是值传递,slice 是指针传递。
数组
声明数组的方式:(固定长度的数组)
var array1 [10]int
array2 := [10]int{1,2,3,4}
array3 := [4]int{1,2,3,4}
数组的长度是固定的,并且在传参的时候,严格匹配数组类型
// 传入参数的数组长度为4,则只能传递长度为4的数组
func printArray(myArray [4]int) {
fmt.Println(myArray) // [1 2 3 4]
myArray[0] = 666 // 数组是值传递
}
func main() {
myArray := [4]int{1, 2, 3, 4}
printArray(myArray)
fmt.Println(myArray) // [1 2 3 4]
}
myArray := [...]int{1, 2, 3, 4}是自动计算数组长度,但并不是引用传递。
声明动态数组和声明数组一样,只是不用写长度。
// 不指定长度则是动态数组
func printArray(myArray []int) {
fmt.Println(myArray) // [1 2 3 4]
myArray[0] = 10 // 动态数组是引用传递
}
func main() {
myArray := []int{1, 2, 3, 4}
printArray(myArray)
fmt.Println(myArray) // [10 2 3 4]
}
slice
slice 的声明方式:通过 make 关键字
// 1 声明一个切片,并且初始化,默认值是1,2,3,长度是3
slice1 := []int{1, 2, 3} // [1 2 3]
// 2 声明一个切片,但是没有给它分配空间
var slice2 []int // slice2 == nil
// 开辟3个空间,默认值是0
slice2 = make([]int, 3) // [0 0 0]
// 3 声明一个切片,同时给slice分配3个空间,默认值是0
var slice3 []int = make([]int, 3) // [0 0 0]
// 4 声明一个切片,同时给slice分配3个空间,默认值是0,通过:=推导出slice是一个切片
slice4 := make([]int, 3) // [0 0 0]
len() 和 cap() 函数:
- len:长度,表示左指针⾄右指针之间的距离。
- cap:容量,表示指针至底层数组末尾的距离。
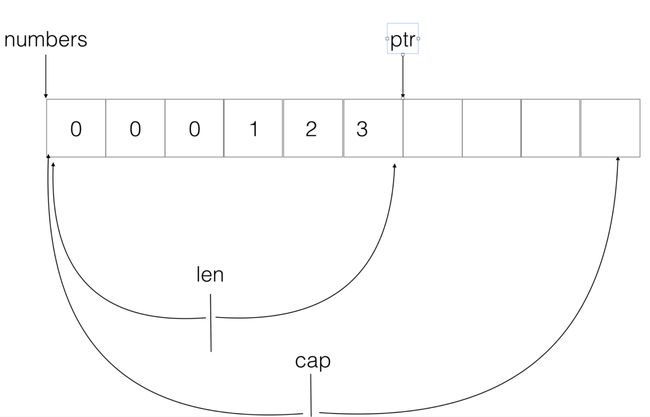
切⽚的扩容机制,append 的时候,如果长度增加后超过容量,则将容量增加 2 倍。
var numbers = make([]int, 3, 5)
fmt.Printf("len = %d, cap = %d, slice = %v\n", len(numbers), cap(numbers), numbers)
// 向numbers切片追加一个元素1, len = 4, [0,0,0,1], cap = 5
numbers = append(numbers, 1)
fmt.Printf("len = %d, cap = %d, slice = %v\n", len(numbers), cap(numbers), numbers)
// 向numbers切片追加一个元素2, len = 5, [0,0,0,1,2], cap = 5
numbers = append(numbers, 2)
fmt.Printf("len = %d, cap = %d, slice = %v\n", len(numbers), cap(numbers), numbers)
// 向一个容量cap已经满的slice 追加元素, len = 6, cap = 10
numbers = append(numbers, 3)
fmt.Printf("len = %d, cap = %d, slice = %v\n", len(numbers), cap(numbers), numbers)
len = 3, cap = 5, slice = [0 0 0]
len = 4, cap = 5, slice = [0 0 0 1]
len = 5, cap = 5, slice = [0 0 0 1 2]
len = 6, cap = 10, slice = [0 0 0 1 2 3]
slice 操作
slice 截取是浅拷贝,若想深拷贝需要使用 copy
可以通过设置下限以及上限设置截取切片 [lower-bound: upper-bound],实例:
func main() {
/* 创建切片 */
numbers := []int{0, 1, 2, 3, 4, 5, 6, 7, 8}
fmt.Println(numbers)
/* 打印原始切片 */
fmt.Println("number ==", numbers)
/* 打印子切片从索引1(包含)到索引4(不包含) */
fmt.Println("numbers[1:4] ==", numbers[1:4])
/* 默认下限为 0 */
fmt.Println("numbers[:3] ==", numbers[:3])
/* 默认上限为 len(s) */
fmt.Println("numbers[4:] ==", numbers[4:])
numbers1 := make([]int, 0, 5)
fmt.Println(numbers1)
/* 打印子切片从索引 0(包含) 到索引 2(不包含) */
numbers2 := numbers[:2]
fmt.Println(numbers2)
/* 打印子切片从索引 2(包含) 到索引 5(不包含) */
numbers3 := numbers[2:5]
fmt.Println(numbers3)
}
[0 1 2 3 4 5 6 7 8]
number == [0 1 2 3 4 5 6 7 8]
numbers[1:4] == [1 2 3]
numbers[:3] == [0 1 2]
numbers[4:] == [4 5 6 7 8]
[]
[0 1]
[2 3 4]
利用 copy 函数拷贝切片,是深拷贝。
slice1 := []int{1, 2, 3}
slice2 := make([]int, 3)
copy(slice2, slice1)
slice2[0] = 10
fmt.Println(slice1) // [1 2 3]
直接赋值切片,是浅拷贝。
slice1 := []int{1, 2, 3}
slice2 := slice1
slice2[0] = 10
fmt.Println(slice1) // [10 2 3]
…
... 是 Go 的一种语法糖。
- 用法 1:函数可以用来接受多个不确定数量的参数。
- 用法 2:slice 可以被打散进行传递。
func test(args ...string) {
for _, v := range args {
fmt.Println(v)
}
}
func main() {
var ss = []string{
"abc",
"efg",
"hij",
"123",
}
test(ss...)
}
map
slice、map、channel 都是引用类型,声明后还需要初始化分配内存,即 make
map 的声明
map 的第一种声明方式:
// 声明myMap1是一种map类型 key是string,value是string
var myMap1 map[string]string
fmt.Println(myMap1 == nil) // true
// 使用map前,需要先用make给map分配数据空间
myMap1 = make(map[string]string, 10)
myMap1["one"] = "java"
myMap1["two"] = "c++"
myMap1["three"] = "python"
fmt.Println(myMap1)
// map[one:java three:python two:c++]
map 的第二种声明方式:
myMap2 := make(map[int]string)
myMap2[1] = "java"
myMap2[2] = "c++"
myMap2[3] = "python"
fmt.Println(myMap2)
// map[1:java 2:c++ 3:python]
map 的第三种声明方式:
myMap3 := map[string]string {
"one": "php",
"two": "c++",
"three": "python",
}
fmt.Println(myMap3)
// map[one:java three:python two:c++]
map 的使用
func printMap(cityMap map[string]string) {
for key, value := range cityMap {
fmt.Println("key = ", key+", value = ", value)
}
}
func AddValue(cityMap map[string]string) {
// map 是引用传递
cityMap["England"] = "London"
}
func main() {
cityMap := make(map[string]string)
// 添加
cityMap["China"] = "Beijing"
cityMap["Japan"] = "Tokyo"
cityMap["USA"] = "NewYork"
// 删除
delete(cityMap, "China")
// 遍历
printMap(cityMap)
fmt.Println("-------")
// 修改
cityMap["USA"] = "DC"
// 利用函数添加 - map 是引用传递
AddValue(cityMap)
// 遍历
printMap(cityMap)
}
key = Japan, value = Tokyo
key = USA, value = NewYork
-------
key = England, value = London
key = Japan, value = Tokyo
key = USA, value = DC
判断 map 中 key 值是否存在:直接取值,返回有两个返回值,通过第 2 个返回值判断。
m := make(map[string]interface{})
m["a"] = "AAA"
if _, ok := m["ba"]; ok {
fmt.Println("存在")
} else {
fmt.Println("不存在")
}
error
捕获系统抛出异常:
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println("捕获:", err)
}
}()
nums := []int{1, 2, 3}
fmt.Println(nums[4]) // 系统抛出异常
// 捕获: runtime error: index out of range [4] with length 3
}
手动抛出异常并捕获:
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println("捕获:", err)
}
}()
panic("出现异常!") // 手动抛出异常
// 捕获: 出现异常!
}
返回异常:
func getCircleArea(radius float32) (area float32, err error) {
if radius < 0 {
// 构建个异常对象
err = errors.New("半径不能为负")
return
}
area = 3.14 * radius * radius
return
}
func main() {
area, err := getCircleArea(-5)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(area)
}
}
自定义异常:
type PathError struct {
path string
op string
createTime string
message string
}
func (p *PathError) Error() string {
return fmt.Sprintf("path=%s \nop=%s \ncreateTime=%s \nmessage=%s",
p.path, p.op, p.createTime, p.message)
}
func Open(filename string) error {
file, err := os.Open(filename)
if err != nil {
return &PathError{
path: filename,
op: "read",
message: err.Error(),
createTime: fmt.Sprintf("%v", time.Now()),
}
}
defer file.Close()
return nil
}
func main() {
err := Open("test.txt")
switch v := err.(type) {
case *PathError:
fmt.Println("get path error,", v)
default:
}
}
面向对象编程
type
利用 type 可以声明某个类型的别名(理解为声明一种新的数据类型)
type myint int
func main() {
var a myint = 10
fmt.Println("a = ", a)
fmt.Printf("type of a = %T\n", a)
}
a = 10
type of a = main.myint
方法
方法:包含了接受者的函数,接受者可以是命名类型或结构体类型的值或者指针。
方法和普通函数的区别:
- 对于普通函数,参数为值类型时,不能将指针类型的数据直接传递,反之亦然。
- 对于方法,接收者为值类型时,可以直接用指针类型的变量调用方法(反过来也可以)。
// 1.普通函数
// 接收值类型参数的函数
func valueIntTest(a int) int {
return a + 10
}
// 接收指针类型参数的函数
func pointerIntTest(a *int) int {
return *a + 10
}
func structTestValue() {
a := 2
fmt.Println("valueIntTest:", valueIntTest(a))
// 函数的参数为值类型,则不能直接将指针作为参数传递
// fmt.Println("valueIntTest:", valueIntTest(&a))
// compile error: cannot use &a (type *int) as type int in function argument
b := 5
fmt.Println("pointerIntTest:", pointerIntTest(&b))
// 同样,当函数的参数为指针类型时,也不能直接将值类型作为参数传递
// fmt.Println("pointerIntTest:", pointerIntTest(b))
// compile error:cannot use b (type int) as type *int in function argument
}
// 2.方法
type PersonD struct {
id int
name string
}
//接收者为值类型
func (p PersonD) valueShowName() {
fmt.Println(p.name)
}
//接收者为指针类型
func (p *PersonD) pointShowName() {
fmt.Println(p.name)
}
func structTestFunc() {
// 与普通函数不同,接收者为指针类型和值类型的方法,指针类型和值类型的变量均可相互调用
// 值类型调用方法
personValue := PersonD{101, "hello world"}
personValue.valueShowName()
personValue.pointShowName()
// 指针类型调用方法
personPointer := &PersonD{102, "hello golang"}
personPointer.valueShowName()
personPointer.pointShowName()
}
struct
type Book struct {
title string
price string
}
func changeBook(book Book) {
// 传递一个book的副本
book.price = "666"
}
func changeBook2(book *Book) {
// 指针传递
book.price = "777"
}
func main() {
var book Book
book.title = "Golang"
book.price = "111"
fmt.Printf("%v\n", book) // {Golang 111}
changeBook(book)
fmt.Printf("%v\n", book) // {Golang 111}
changeBook2(&book)
fmt.Printf("%v\n", book) // {Golang 777}
}
一道 struct 与指针面试题:
type student struct {
name string
age int
}
func main() {
m := make(map[string]*student)
stus := []student{
{name: "aaa", age: 18},
{name: "bbb", age: 23},
{name: "ccc", age: 28},
}
for _, stu := range stus {
m[stu.name] = &stu
}
for k, v := range m {
fmt.Println(k, "=>", v.name)
}
}
aaa => ccc
bbb => ccc
ccc => ccc
解决方法 1:
for _, stu := range stus {
// 方法1
temp := stu
m[stu.name] = &temp
}
解决方法 2:
for i, stu := range stus {
// 方法2
m[stu.name] = &stus[i]
}
封装
Golang 中,类名、属性名、⽅法名 首字⺟大写 表示对外(其他包)可以访问,否则只能够在本包内访问。
// 如果类名首字母大写,表示其他包也能够访问
type Hero struct {
// 如果类的属性首字母大写, 表示该属性是对外能够访问的,否则的话只能够类的内部访问
Name string
Ad int
level int // 只能本包访问
}
func (h *Hero) Show() {
fmt.Println("Name = ", h.Name)
fmt.Println("Ad = ", h.Ad)
fmt.Println("Level = ", h.level)
fmt.Println("---------")
}
func (h *Hero) GetName() string {
return h.Name
}
// 不用指针则传递的是副本,无法赋值
func (h *Hero) SetName(newName string) {
h.Name = newName
}
func main() {
hero := Hero{Name: "zhang3", Ad: 100}
hero.Show()
hero.SetName("li4")
hero.Show()
}
Name = zhang3
Ad = 100
Level = 0
---------
Name = li4
Ad = 100
Level = 0
---------
继承
Golang 通过匿名字段实现继承的效果:
// 父类
type Human struct {
name string
sex string
}
func (h *Human) Eat() {
fmt.Println("Human.Eat()...")
}
func (h *Human) Walk() {
fmt.Println("Human.Walk()...")
}
// 子类
type SuperMan struct {
Human // SuperMan类继承了Human类的方法
level int
}
// 重定义父类的方法Eat()
func (s *SuperMan) Eat() {
fmt.Println("SuperMan.Eat()...")
}
// 子类的新方法
func (s *SuperMan) Fly() {
fmt.Println("SuperMan.Fly()...")
}
func main() {
// 定义一个子类对象
// s := SuperMan{Human{"li4", "female"}, 88}
var s SuperMan
s.name = "li4"
s.sex = "male"
s.level = 88
s.Walk() // 父类的方法
s.Eat() // 子类的方法
s.Fly() // 子类的方法
}
Human.Walk()...
SuperMan.Eat()...
SuperMan.Fly()...
多态
Go 中接口相关文章:理解Duck Typing(鸭子模型)
- 如何理解Golang中的接口? - 波罗学的回答 - 知乎
Golang 中多态的基本要素:
- 有一个父类(有接口)
// 本质是一个指针
type AnimalIF interface {
Sleep()
GetColor() string // 获取动物的颜色
GetType() string // 获取动物的种类
}
- 有子类(实现了父类的全部接口)
// 具体的类
type Cat struct {
color string // 猫的颜色
}
func (c *Cat) Sleep() {
fmt.Println("Cat is Sleep")
}
func (c *Cat) GetColor() string {
return c.color
}
func (c *Cat) GetType() string {
return "Cat"
}
- 父类类型的变量(指针)指向(引用)子类的具体数据变量
// 接口的数据类型,父类指针
var animal AnimalIF
animal = &Cat{"Green"}
animal.Sleep() // 调用的就是Cat的Sleep()方法, 多态
不同接收者实现接口
type Mover interface {
move()
}
type dog struct {
name string
}
值类型接收者实现接口:可以同时接收 值类型 和 指针类型。
Go 语言中有对指针类型变量求值的语法糖,dog 指针
dog2内部会自动求值*dog2
// 可以同时接收 值类型 和 指针类型
func (d dog) move() {
fmt.Println(d.name, "is moving")
}
func main() {
var m Mover
var dog1 = dog{"dog1"}
m = dog1 // 可以接收值类型
m.move()
var dog2 = &dog{"dog2"}
m = dog2 // 可以接收指针类型
m.move()
}
指针类型接收者实现接口:只能接收指针类型。
// 只能接收指针类型
func (d *dog) move() {
fmt.Println(d.name, "is moving")
}
func main() {
var m Mover
// 无法接收指针类型
// var dog1 = dog{"dog1"}
// m = dog1
//m.move()
var dog2 = &dog{"dog2"}
m = dog2
m.move()
}
一道面试题:以下代码能否通过编译?
type People interface {
Speak(string) string
}
type Student struct{}
func (stu *Student) Speak(think string) (talk string) {
if think == "sb" {
talk = "你是个大帅比"
} else {
talk = "您好"
}
return
}
func main() {
var peo People = Student{}
think := "bitch"
fmt.Println(peo.Speak(think))
}
不能。修改 var peo People = Student{} 为 var peo People = &Student{} 即可。
通用万能类型
interface{} 表示空接口,可以用它引用任意类型的数据类型。
// interface{}是万能数据类型
func myFunc(arg interface{}) {
fmt.Println(arg)
}
type Book struct {
auth string
}
func main() {
book := Book{"Golang"}
myFunc(book)
myFunc(100)
myFunc("abc")
myFunc(3.14)
}
Golang 给 interface{} 提供类型断言机制,用来区分此时引用的类型:
注意断言这个操作会有两个返回值
func myFunc(arg interface{}) {
// 类型断言
value, ok := arg.(string)
if !ok {
fmt.Println("arg is not string type")
} else {
fmt.Println("arg is string type, value = ", value)
fmt.Printf("value type is %T\n", value)
}
}
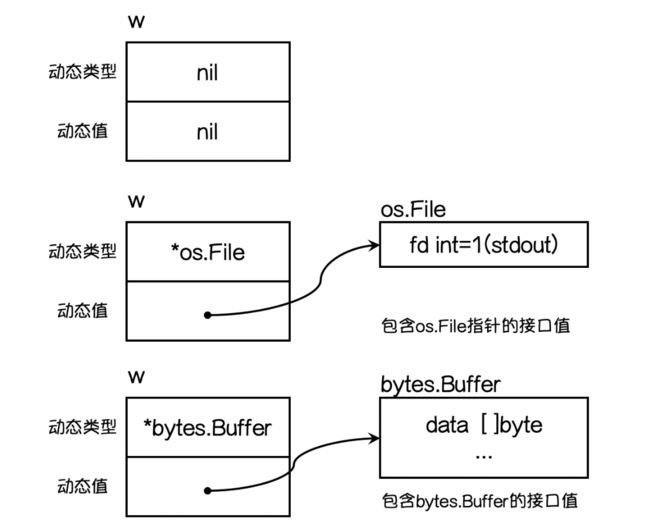
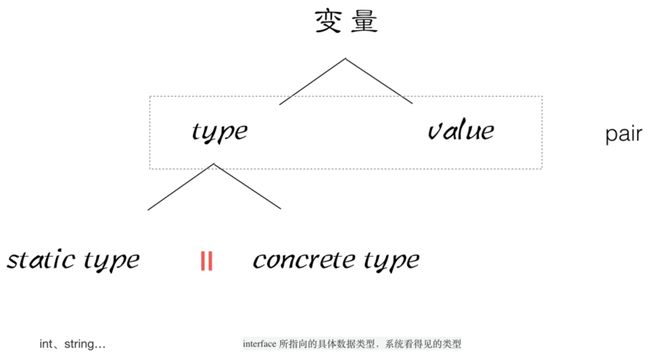
一个接口的值(简称接口值)是由一个 具体类型 和 具体类型的值 两部分组成的。
这两部分分别称为接口的动态类型和动态值。
var w io.Writer
w = os.Stdout
w = new(bytes.Buffer)
w = nil
switch 判断多个断言:
func justifyType(x interface{}) {
switch v := x.(type) {
case string:
fmt.Printf("x is a string,value is %v\n", v)
case int:
fmt.Printf("x is a int is %v\n", v)
case bool:
fmt.Printf("x is a bool is %v\n", v)
default:
fmt.Println("unsupport type!")
}
}
反射
变量内置 Pair 结构
var a string
// pair类型断言其实就是根据 pair 中的 type 获取到 value
// tty: pair仔细分析下面的代码:
- 由于 pair 在传递过程中是不变的,所以不管 r 还是 w,pair 中的 tpye 始终是 Book
- 又因为 Book 实现了 Reader、Wrtier 接口,所以 type 为 Book 可以调用 ReadBook() 和 WriteBook()
type Reader interface {
ReadBook()
}
type Writer interface {
WriteBook()
}
// 具体类型
type Book struct {
}
func (b *Book) ReadBook() {
fmt.Println("Read a Book")
}
func (b *Book) WriteBook() {
fmt.Println("Write a Book")
}
func main() {
// b: pairreflect
reflect 包中的两个重要方法:
// ValueOf returns a new Value initialized to the concrete value
// stored in the interface i. ValueOf(nil) returns the zero Value.
func ValueOf(i interface{}) Value {...}
// ValueOf接口用于获取输入参数接口中的数据的值,如果接口为空则返回0
// TypeOf returns the reflection Type that represents the dynamic type of i.
// If i is a nil interface value, TypeOf returns nil.
func TypeOf(i interface{}) Type {...}
// TypeOf用来动态获取输入参数接口中的值的类型,如果接口为空则返回nil
反射的应用:
- 获取简单变量的类型和值:
func reflectNum(arg interface{}) {
fmt.Println("type : ", reflect.TypeOf(arg))
fmt.Println("value : ", reflect.ValueOf(arg))
}
func main() {
var num float64 = 1.2345
reflectNum(num)
}
type : float64
value : 1.2345
- 获取结构体变量的字段方法:
type User struct {
Id int
Name string
Age int
}
func (u User) Call() {
fmt.Println("user ius called..")
fmt.Printf("%v\n", u)
}
func main() {
user := User{1, "AceId", 18}
DoFieldAndMethod(user)
}
func DoFieldAndMethod(input interface{}) {
// 获取input的type
inputType := reflect.TypeOf(input)
fmt.Println("inputType is :", inputType.Name())
// 获取input的value
inputValue := reflect.ValueOf(input)
fmt.Println("inputValue is :", inputValue)
// 通过type获取里面的字段
// 1.获取interface的reflect.Type,通过Type得到NumField,进行遍历
// 2.得到每个field,数据类型
// 3.通过field有一个Interface()方法,得到对应的value
for i := 0; i < inputType.NumField(); i++ {
field := inputType.Field(i)
value := inputValue.Field(i).Interface()
fmt.Printf("%s: %v = %v\n", field.Name, field.Type, value)
}
// 通过type获取里面的方法,调用
for i := 0; i < inputType.NumMethod(); i++ {
m := inputType.Method(i)
fmt.Printf("%s: %v\n", m.Name, m.Type)
}
}
inputType is : User
inputValue is : {1 AceId 18}
Id: int = 1
Name: string = AceId
Age: int = 18
Call: func(main.User)
结构体标签
结构体标签的定义:
type resume struct {
Name string `info:"name" doc:"我的名字"`
Sex string `info:"sex"`
}
func findTag(str interface{}) {
t := reflect.TypeOf(str).Elem()
for i := 0; i < t.NumField(); i++ {
taginfo := t.Field(i).Tag.Get("info")
tagdoc := t.Field(i).Tag.Get("doc")
fmt.Println("info: ", taginfo, " doc: ", tagdoc)
}
}
func main() {
var re resume
findTag(&re)
}
info: name doc: 我的名字
info: sex doc:
结构体标签的应用:JSON 编码与解码
import (
"encoding/json"
"fmt"
)
type Movie struct {
Title string `json:"title"`
Year int `json:"year"`
Price int `json:"price"`
Actors []string `json:"actors"`
Test string `json:"-"` // 忽略该值,不解析
}
func main() {
movie := Movie{"喜剧之王", 2000, 10, []string{"xingye", "zhangbozhi"}, "hhh"}
// 编码:结构体 -> json
jsonStr, err := json.Marshal(movie)
if err != nil {
fmt.Println("json marshal error", err)
return
}
fmt.Printf("jsonStr = %s\n", jsonStr)
// 解码:jsonstr -> 结构体
myMovie := Movie{}
err = json.Unmarshal(jsonStr, &myMovie)
if err != nil {
fmt.Println("json unmarshal error", err)
return
}
fmt.Printf("%v\n", myMovie)
}
jsonStr = {"title":"喜剧之王","year":2000,"price":10,"actors":["xingye","zhangbozhi"]}
{喜剧之王 2000 10 [xingye zhangbozhi] }
其他应用:orm 映射关系 …
并发知识
基础知识
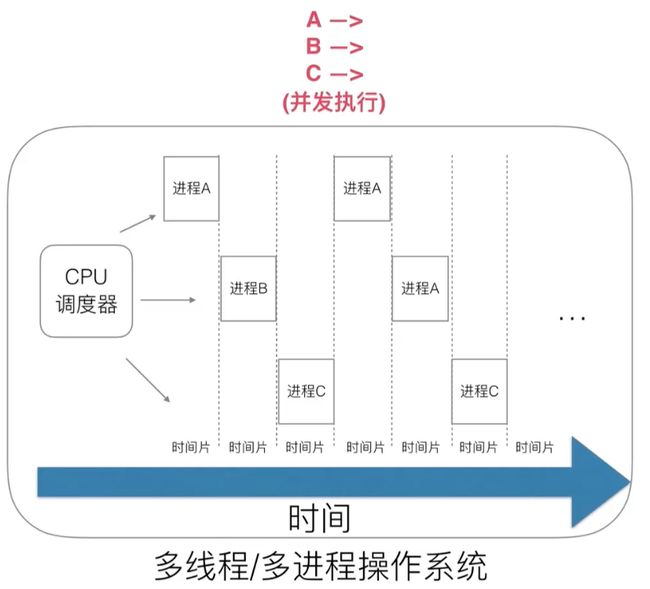
早期的操作系统是单进程的,存在两个问题:
1、单一执行流程、计算机只能一个任务一个任务的处理
2、进程阻塞所带来的 CPU 浪费时间

多线程 / 多进程 解决了阻塞问题:
但是多线程又面临新的问题:上下文切换所耗费的开销很大。
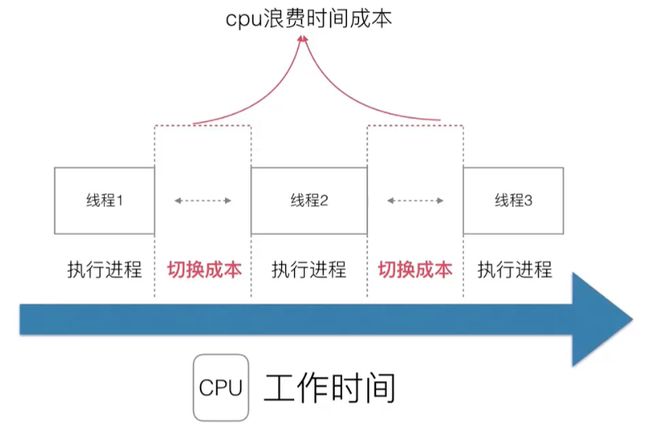
进程 / 线程的数量越多,切换成本就越大,也就越浪费。
有可能 CPU 使用率 100%,其中 60% 在执行程序,40% 在执行切换…
多线程 随着 同步竞争(如 锁、竞争资源冲突等),开发设计变的越来越复杂。
多线程存在 高消耗调度 CPU、高内存占用 的问题:
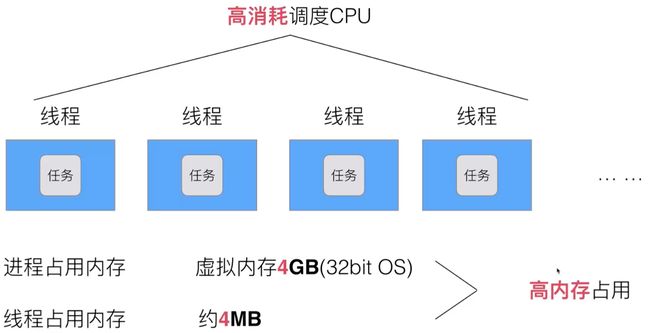
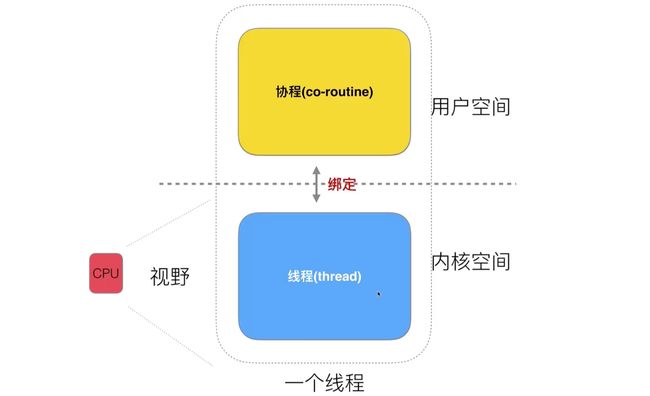
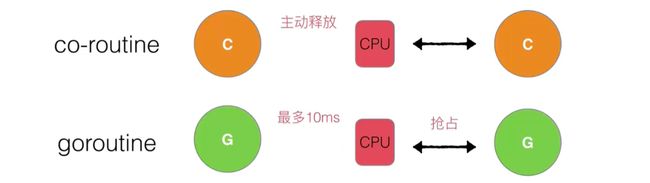
如果将内核空间和用户空间的线程拆开,也就出现了协程(其实就是用户空间的线程)
内核空间的线程由 CPU 调度,协程是由开发者来进行调度。
用户线程,就是协程。内核线程,就是真的线程。
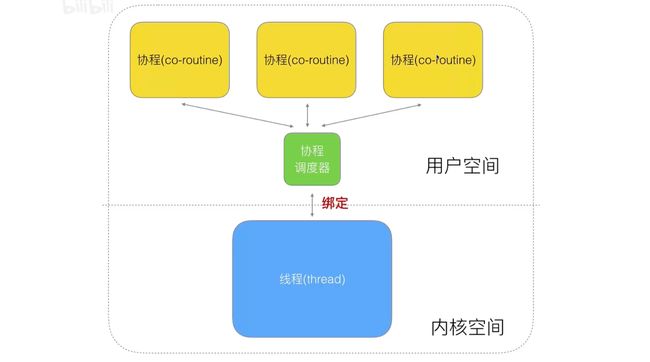
然后在内核线程与协程之间,再加入一个协程调度器:实现线程与协程的一对多模型
- 弊端:如果一个协程阻塞,会影响下一个的调用(轮询的方式)
如果将上面的模型改成一对一的模型,虽然没有阻塞,但是和以前的线程模型没有区别了…
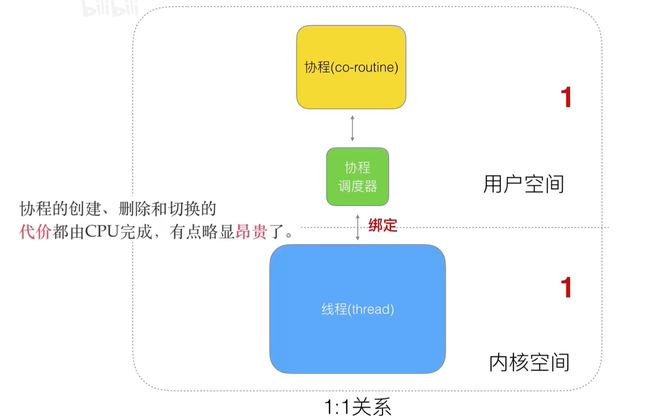
再继续优化成多对多的模型,则将主要精力放在优化协程调度器上:
内核空间是 CPU 地盘,我们无法进行太多优化。
不同的语言想要支持协程的操作,都是在用户空间优化其协程处理器。
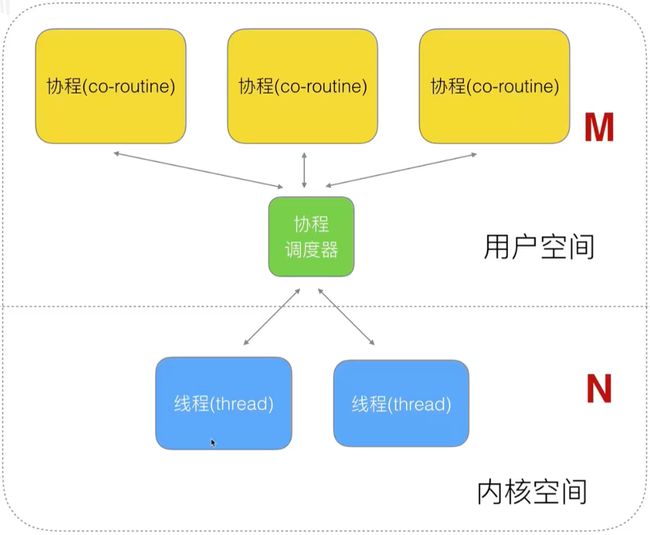
Go 对协程的处理:

早期调度器的处理
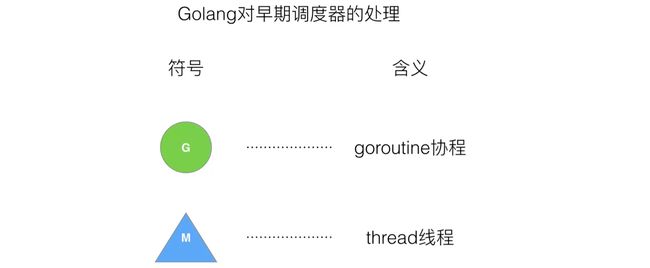
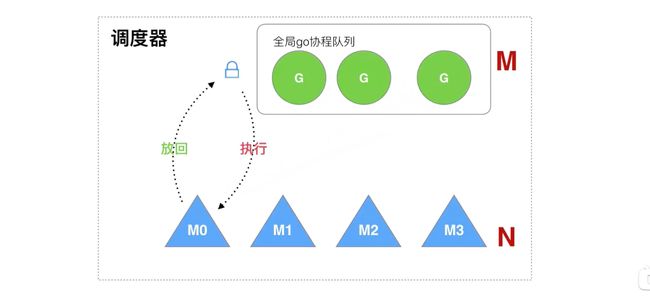
老调度器有几个缺点:
- 创建、销毁、调度 G 都需要每个 M 获取锁,形成了激烈的锁竞争。
- M 转移 G 会造成延迟和额外的系统负载。
- 系统调用(CPU 在 M 之前的切换)导致频繁的线程阻塞和取消阻塞操作,增加了系统开销。
GMP模型
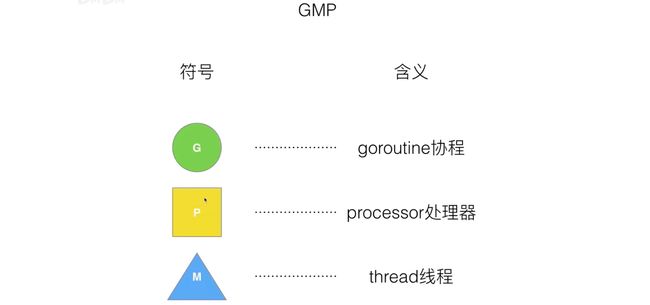
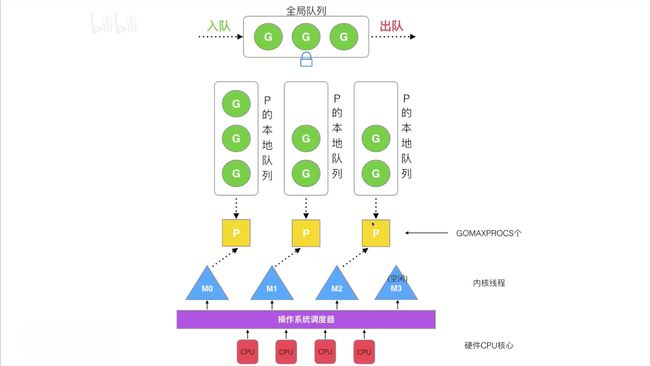
调度器的设计策略
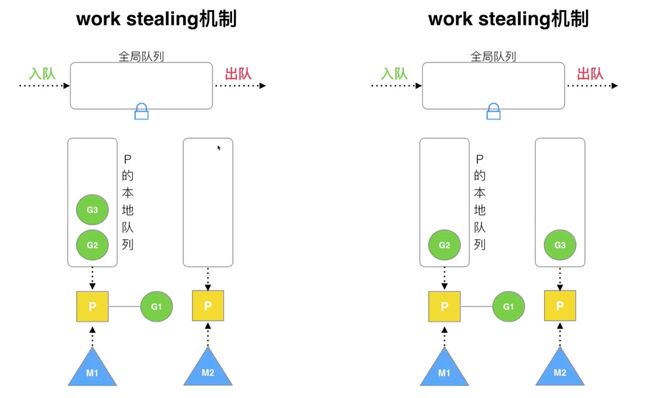
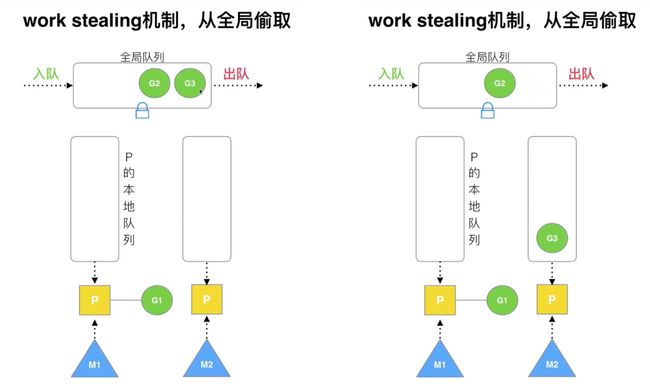
调度器的 4 个设计策略:复用线程、利用并行、抢占、全局G队列
复用线程:work stealing、hand off
- work stealing 机制:某个处理器的本地队列空余,从其他处理器中偷取协程来执行
注意,这里是从某个处理器的本地队列偷取,还有从全局队列中偷取的做法
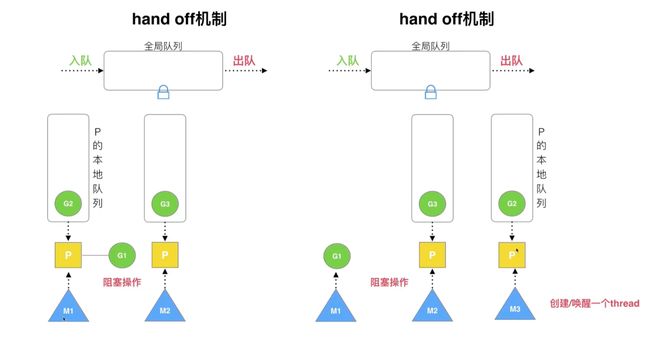
- hand off 机制:如果某个线程阻塞,会将处理器资源让给其他线程。
利用并行:利用 GOMAXPROCS 限定 P 的个数 = CPU 核数 / 2
抢占:
全局G队列:基于 warlk stealing 机制,如果所有处理器的本地队列都没有协程,则从全局获取。
并发编程
goroutine
创建 goroutine:
// 子routine
func newTask() {
i := 0
for {
i++
fmt.Printf("new Goroutie: i = %d\n", i)
time.Sleep(1 * time.Second)
}
}
// 主routine
func main() {
// 创建一个子进程 去执行newTask()流程
go newTask()
i := 0
for {
i++
fmt.Printf("main goroutine: i = %d\n", i)
time.Sleep(1 * time.Second)
}
}
main goroutine: i = 1
new Goroutie: i = 1
new Goroutie: i = 2
main goroutine: i = 2
main goroutine: i = 3
new Goroutie: i = 3
...
退出当前的 goroutine 的方法 runtime.Goexit(),比较以下两段代码:
func main() {
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
fmt.Println("B")
}()
fmt.Println("A")
}()
// 防止程序退出
for {
time.Sleep(1 * time.Second)
}
}
B
B.defer
A
A.defer
执行了退出 goroutine 的方法:
func main() {
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
runtime.Goexit() // 退出当前goroutine
fmt.Println("B")
}()
fmt.Println("A")
}()
// 防止程序退出
for {
time.Sleep(1 * time.Second)
}
}
B.defer
A.defer
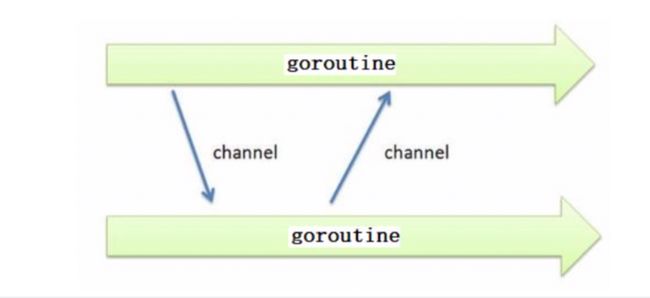
channel
channel 用于在 goroutine 之间进行数据传递:
make(chan Type) // 等价于 make(chan Type, 0)
make(chan Type, capacity)
channel <- value // 发送value到channel
<-channel // 接收并将其丢弃
x := <-channel // 从channel中接收数据,并赋值给x
x, ok := <-channel // 功能同上,同时检查通道是否已关闭或为空
channel 的使用:
func main() {
// 定义一个channel
c := make(chan int)
go func() {
defer fmt.Println("goroutine 结束")
fmt.Println("goroutine 正在运行")
c <- 666 // 将666发送给c
}()
num := <-c // 从c中接受数据, 并赋值给num
fmt.Println("num = ", num)
fmt.Println("main goroutine 结束...")
}
goroutine 正在运行...
goroutine结束
num = 666
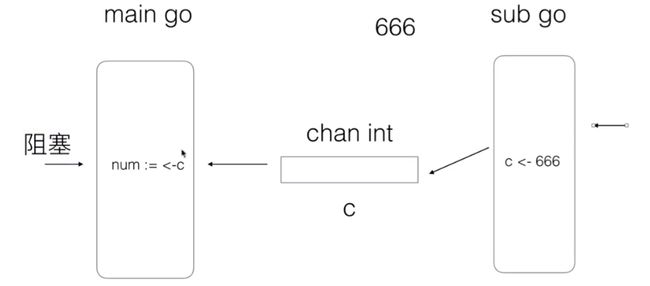
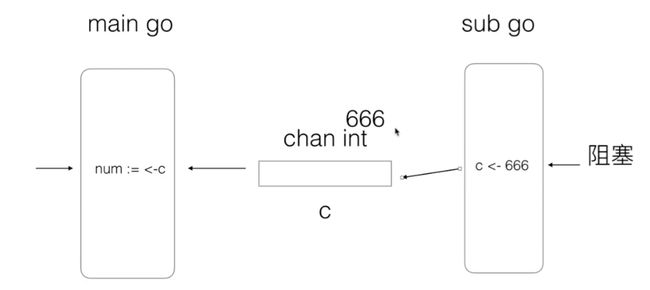
main goroutine 结束...
上面的代码(使用 channel 交换数据),sub goroutine 一定会在 main goroutine 之后运行
- 如果 main goroutine 运行的快,会进入等待,等待 sub goroutine 传递数据过来
- 如果 sub goroutine 运行的快,也会进入等待,等待 main routine 运行到当前,然后再发送数据
无缓冲的 channel
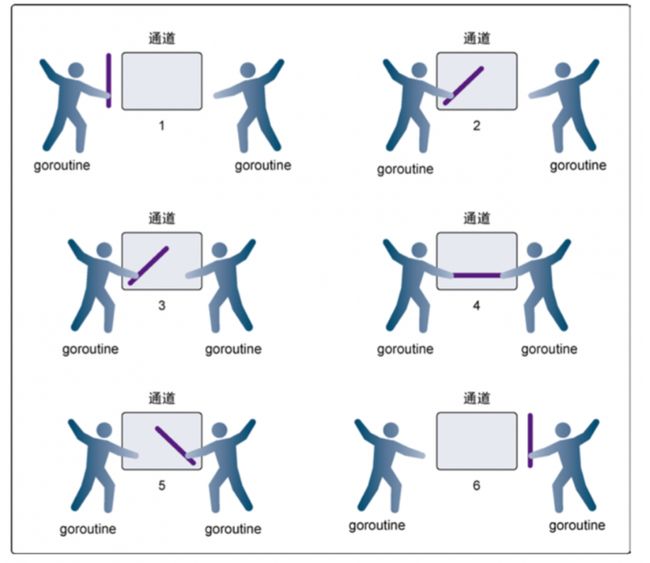
-
第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执⾏发送或者接收。
-
第 2 步,左侧的 goroutine 将它的⼿伸进了通道,这模拟了向通道发送数据的⾏为。
这时,这个 goroutine 会在通道中被锁住,直到交换完成。
-
第 3 步,右侧的 goroutine 将它的手放⼊通道,这模拟了从通道⾥接收数据。
这个 goroutine ⼀样也会在通道中被锁住,直到交换完成。
-
第 4 步和第 5 步,进⾏交换。
-
第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。
两个 goroutine 现在都可以去做其他事情了。
有缓冲的 channel
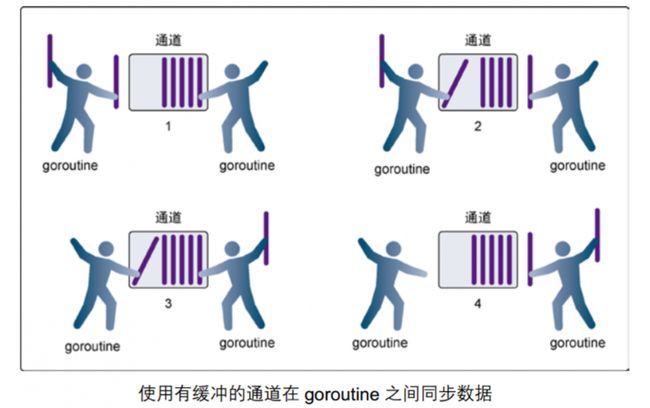
-
第 1 步,右侧的 goroutine 正在从通道接收一个值。
-
第 2 步,右侧的这个 goroutine 独立完成了接收值的动作,左侧的 goroutine 正在发送一个新值到通道里。
-
第 3 步,左侧的 goroutine 还在向通道发送新值,⽽右侧的 goroutine 正在从通道接收另外一个值。
这个步骤⾥的两个操作既不是同步的,也不会互相阻塞。
-
第 4 步,所有的发送和接收都完成,⽽通道里还有⼏个值,也有一些空间可以存更多的值。
特点:
- 当 channel 已经满,再向⾥面写数据,就会阻塞。
- 当 channel 为空,从⾥面取数据也会阻塞。
func main() {
// 带有缓冲的channel
c := make(chan int, 3)
fmt.Println("len(c) = ", len(c), "cap(c) = ", cap(c))
go func() {
defer fmt.Println("子go程结束")
for i := 0; i < 3; i++ {
c <- i
fmt.Println("子go程正在运行,发送的元素 =", i, "len(c) = ", len(c), " cap(c) = ", cap((c)))
}
}()
time.Sleep(2 * time.Second)
for i := 0; i < 3; i++ {
num := <-c // 从c中接收数据,并赋值给num
fmt.Println("num = ", num)
}
fmt.Println("main 结束")
}
len(c) = 0 cap(c) = 3
子go程正在运行,发送的元素 = 0 len(c) = 1 cap(c) = 3
子go程正在运行,发送的元素 = 1 len(c) = 2 cap(c) = 3
子go程正在运行,发送的元素 = 2 len(c) = 3 cap(c) = 3
子go程结束
num = 0
num = 1
num = 2
main 结束
上例中,可以尝试分别改变 2 个 for 的循环次数进行学习。
关闭 channel
func main() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
// close可以关闭一个channel
close(c)
}()
for {
// ok为true表示channel没有关闭,为false表示channel已经关闭
if data, ok := <-c; ok {
fmt.Println(data)
} else {
break
}
}
fmt.Println("Main Finished..")
}
0
1
2
3
4
Main Finished..
channel 不像文件一样需要经常去关闭,只有当确实没有任何发送数据了,或者想显式的结束 range 循环之类的,才去关闭 channel,注意:
- 关闭 channel 后,无法向 channel 再发送数据(引发 panic 错误后导致接收立即返回零值)
- 关闭 channel 后,可以继续从 channel 接收数据
- 对于 nil channel,⽆论收发都会被阻塞
channel 与 range
func main() {
c := make(chan int)
go func() {
defer close(c)
for i := 0; i < 5; i++ {
c <- i
}
}()
// 可以使用range来迭代不断操作channel
for data := range c {
fmt.Println(data)
}
fmt.Println("Main Finished..")
}
channel 与 select
select 可以用来监控多路 channel 的状态:
func fibonacii(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <- x:
// 如果c可写,则进入该case
x, y = y, x+y
case <-quit:
// 如果quit可读,则进入该case
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
// sub go
go func() {
for i := 0; i < 6; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
// main go
fibonacii(c, quit)
}
1
1
2
3
5
8
quit
Go Modules
Go modules 是 Go 语言的依赖解决⽅案。
发布于 Go1.11,成⻓于 Go1.12,丰富于 Go1.13,正式于 Go1.14 推荐在生产上使⽤。
Go modules 集成在Go 的工具链中,只要安装了 Go 就可以使用,它解决了以下几个问题:
- Go 语言长久以来的依赖管理问题。
- “淘汰” 现有的 GOPATH 的使用模式。
- 统一社区中其他的依赖管理工具(提供依赖迁移功能)。
GO PATH 的弊端:
- 无版本控制概念
- 无法同步一致第三方版本号
- 无法指定当前项⽬引用的第三⽅版本号
go mod 命令
| 命令 | 作用 |
|---|---|
| go mod init | 生成 go.mod 文件 |
| go mod download | 下载 go.mod 文件中指明的所有依赖 |
| go mod tidy | 整理现有的依赖 |
| go mod graph | 查看现有的依赖结构 |
| go mod edit | 编辑 go.mod 文件 |
| go mod vendor | 导出项目所有的依赖到 vendor 目录 |
| got mod verify | 检验一个模块是否被篡改过 |
| go mod why | 查看为什么需要依赖某模块 |
go mod 环境变量
通过 go env 命令进行查看:
$ go env
GO111MODULE="auto"
GOPROXY="https://goproxy.cn,direct"
GONOPROXY=""
GOSUMDB="sum.golang.org"
GONOSUMDB=""
GOPRIVATE=""
...
GO111MODULE
GO111MODULE 表示是否开启 Go modules 模式,允许设置以下参数:
- auto:项目包含了 go.mod 文件就启用 Go Modules。
- on:启用 Go modules ,推荐设置。
- off:禁用 Go modules,不推荐。
建议 go v1.11 后,都设置为 on:go env -w GO111MODULE=on
GOPROXY
GOPROXY 用于设置 Go 模块代理,用于使 Go 在拉取版本模块时通过镜像站点来快速拉取。
默认值是:https://proxy.golang.org,国内无法访问
阿里云:阿里云Go Module代理服务 (aliyun.com)
七牛云:七牛云 - Goproxy.cn
建议设置为国内的地址:
go env -w GOPROXY=https://goproxy.cn,direct
direct用于指示 Go 回源到模块版本的源地址去抓取(比如 GitHub 等)
GOSUMDB
GOSUMDB 用于检验拉取的第三方库是否完整。
默认值是 sum.golang.org(国内无法访问),但是如果设置了 GOPROXY 默认就会被代理。
GOPRIVATE
GOPRIVATE 环境变量的值也将作为 GONOPROXY 和 GONOSUMDB 的默认值。
这三个环境变量都是用于公司依赖了私有模块,需要设置,否则会拉取失败。
使用示例:
设置 git.example.com 和 github.com/aceld/zinx 是私有仓库,不会进行 GOPROXY 下载和检验
go env -w GOPRIVATE="git.example.com,github.com/aceld/zinx
设置 example.com 的子域名,比如 git.example.com、hello.example.com,都不进行 GOPROXY 下载和检验
go env -w GOPRIVATE="*.example.com"
初始化项目
使用 go mod 创建项目,不强制要求在
$GOPATH/src目录下进行。
创建 go.mod 文件,同时为当前项目的模块命名:(以后别人通过这个名字导入你的模块)
go mod init github.com/yusael/modules_test
会生成一个 go.mod 文件:
module github.com/yusael/modules_test
go 1.17
在项目中编写源代码,如果依赖了某个库(比如:github.com/aceld/zinx/znet))
可以手动下载
go get github.com/aceld/zinx/znet,也可以自动下载
下载后 go.mod 文件中会添加一行新代码:
- 含义是当前模块依赖
github.com/aceld/zinx - 依赖的版本是
v1.0.1 // indirect表示间接依赖
module github.com/yusael/modules_test
go 1.17
require github.com/aceld/zinx v1.0.1 // indirect
同时项目中会生成 go.sum 文件:
- go.sum 作用:列出当前项目直接或间接依赖的所有模块版本,保证今后项目依赖版本不被篡改。
h1:hash表示对整体项目 zip 文件打开后全部文件的校验和来生成的 hash
不存在则表示依赖的库可能用不上。
xxx/go.mod h1:hashgo.mod 文件做的 hash
github.com/aceld/zinx v1.0.1 h1:WnahGyE7tDJvkJRVK2VI/m57aHEeUjr12EAYpOYW3ng=
github.com/aceld/zinx v1.0.1/go.mod h1:Tth0Fmjjpel0G8YjCz0jHdL0sXlc4p3Km/l/srvqqKo=
github.com/golang/protobuf v1.3.3/go.mod h1:vzj43D7+SQXF/4pzW/hwtAqwc6iTitCiVSaWz5lYuqw=
修改项目版本依赖关系
go mod edit [email protected][email protected]
以上命令将 [email protected] 的依赖修改为 [email protected] 的依赖。
这个一般用不上,用上时请查阅当前的最新资料。
Golang 生态拓展
Web 框架
beego:https://github.com/astaxie/beego
gin:https://github.com/gin-gonic/gin
echo:https://github.com/labstack/echo
lris:https://github.com/kataras/iris
微服务框架
go kit:http://gokit.io/
Istio:https://istio.io/
容器编排
Kubernets:https://github.com/kubernetes/kubernetes
swarm:https://github.com/docker/classicswarm
服务发现
consul:https://github.com/hashicorp/consul
存储引擎
etcd:https://github.com/coreos/etcd
tidb:https://github.com/pingcap/tidb
静态建站
hugo:https://github.com/gohugoio/hugo
中间件
消息队列 nsq:https://github.com/nsqio/nsq
TCP 长连接框架(轻量服务器):https://github.com/aceld/zinx
Leaf(游戏服务器):https://github.com/name5566/leaf
RPC 框架,gRPC:https://grpc.io/
redis 集群:https://github.com/CodisLabs/codis
爬虫框架
go query:https://github.com/PuerkitoBio/goquery