Retrospectives on the Embodied AI Workshop(嵌入式人工智能研讨会回顾) 论文阅读
论文信息
题目:Retrospectives on the Embodied AI Workshop
作者:Matt Deitke, Dhruv Batra, Yonatan Bisk
来源:arXiv
论文地址:https://arxiv.org/pdf/2210.06849
Abstract
我们的分析重点关注 CVPR Embodied AI Workshop 上提出的 13 个挑战。这些挑战分为三个主题:(1) visual navigation
(2) re-arrangement
(3) embodied vision-and language

Introduction
研讨会提出的挑战集中在导航、重新排列以及具体视觉和语言方面的基准进展。
- 导航挑战:包括 Habitat PointNav [1] 和 ObjectNav [17]、使用 iGibson [210] 的交互式和社交导航、RoboTHOR ObjectNav [51]、MultiON [198]、RVSU 语义 SLAM [82] 以及使用 SoundSpaces [38] 的视听导航];
- 重新排列挑战:包括 AI2-THOR 重新排列 [200]、TDW-Transport [67] 和 RVSU 场景变化检测 [82];
- 体现的视觉和语言挑战:包括 RxR-Habitat [102]、ALFRED [177] 和 TEACh [133]。
我们讨论每个挑战的设置及其最先进的性能,分析挑战中获奖作品之间的共同方法,最后讨论该领域有前途的未来方向
Challenge Details
Navigation Challenges
在较高层次上,导航任务包括在模拟 3D 环境(例如家庭)中运行的agent,其目标是移动到某个目标。对于每项任务,agent都可以使用以自我为中心的摄像机,并从第一人称的角度观察环境。智能体必须学会通过视觉观察来导航环境。
挑战主要取决于目标的编码方式(例如 ObjectGoal、PointGoal、AudioGoal)、代理如何与环境交互(例如静态导航、交互式导航、社交导航)、训练和评估场景(例如 3D扫描、视频游戏环境、现实世界)、观察空间(例如 RGB 与 RGBD,是否提供定位信息)和动作空间(例如输出离散的高级动作或连续的关节运动动作)。
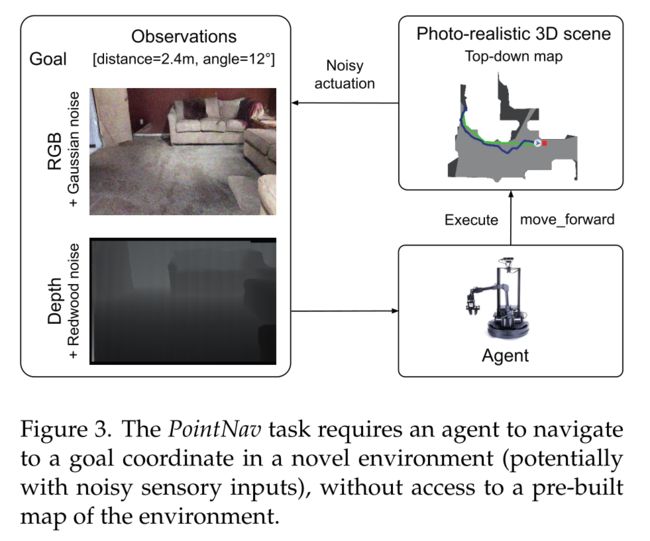
PointNav
在 PointNav 中,代理的目标是导航到新环境中相对于其起始位置的目标坐标(例如,相对于其起始姿势向北导航 5m,向西导航 3m),而无需访问预先构建的环境地图。该代理可以访问以自我为中心的感官输入(RGB 图像、深度图像或两者)和用于定位的自我运动传感器(有时称为 GPS+罗盘传感器)。
机器人的动作空间包括:向前移动 0.25m、向右旋转 30°、向左旋转 30° 和完成。
如果代理在目标 0.2 米范围内且最大步数在 500 步以内发出“完成”命令,则视为成功。使用成功率 (SR) 和“按路径长度加权的成功”(SPL) [9] 指标来评估代理,该指标衡量代理所采取路径的成功和效率。对于训练和评估,挑战参与者使用 Gibson 3D 数据集的训练和验证分割 [223]
2019年,AI Habitat在PointNav上举办了首场挑战赛。获胜作品[31]利用经典方法和基于学习的方法相结合,在RGB-D轨道上取得了0.948的高测试SPL,在RGB轨道上取得了0.805的高测试SPL 。根据 Kadian 等人的研究结果 [92],2020 年和 2021 年,PointNav 挑战赛进行了修改,以强调增加真实性和 sim2real 预测性(根据模拟性能预测真实机器人性能的能力)。具体来说,挑战 (PointNavv2) 引入了 (1) 无 GPS+指南针传感器,(2) 嘈杂的驱动和传感,(3) 碰撞动力学和“滑动”,以及 (4) 对机器人实施例/尺寸、相机分辨率的微小改变,高度以更好地匹配LoCoBot机器人。事实证明,这些变化更具挑战性,2020 年获胜的提交作品[149]实现了 0.21 的 SPL 和 0.28 的 SR。 2021年,取得了重大突破,比2020年的获胜者性能提升了3倍;获胜作品的 SPL 为 0.74,SR 为 0.96 [1]。由于在此 PointNav-v2 设置中具有完美 GPS + 指南针传感器的代理最多只能实现 0.76 SPL 和 0.99 SR,因此 PointNav-v2 挑战被认为已解决,并在未来几年停止。
Interactive and Social PointNav
在交互式和社交导航中,代理需要在包含动态对象(家具、杂物等)或动态代理(行人)的动态环境中达到 PointGoal。尽管机器人导航在仓库等静态结构化环境中取得了显着的成功,但在家庭和办公室等动态环境中它仍然是一个具有挑战性的研究问题。 2020 年和 2021 年,斯坦福大学视觉与学习实验室与 Robotics@Google 合作举办了互动和社交(动态)导航挑战赛2。这些挑战使用了模拟环境 iGibson [105, 175] 和许多真实的室内场景,如图 4 所示。2020 年挑战 3 还采用了 Sim2Real 组件,参与者在 iGibson 模拟环境中训练他们的策略并部署在真实世界。

-
在交互式导航中,我们挑战导航代理要不惜一切代价避免碰撞的观念。我们的观点恰恰相反——在充满杂乱的真实环境中,例如家庭,智能体必须交互并推开物体才能实现有意义的导航。请注意,场景中的所有对象都被分配了真实的物理重量并且可以交互。
就像在现实世界中一样,虽然有些物体很轻并且可以由机器人移动,但其他物体则不然。除了场景中最初的家具对象之外,还添加了来自 Google 扫描对象数据集 [54] 的其他对象(例如鞋子和玩具)以模拟现实世界的混乱。使用一种新颖的交互式导航评分(INS)[210]来评估代理的性能,该分数既可以衡量导航的成功程度,也可以衡量代理沿途对场景造成的干扰程度 -
在社交导航中,智能体在家庭环境中的行走人类中进行导航。场景中的人类向随机采样的位置移动,他们的 2D 轨迹是使用 iGibson [105,140,175] 中集成的最佳相互碰撞避免 (ORCA) [18] 模型进行模拟。
代理应避免碰撞或接近行人超过阈值(距离 <0.3 米),以避免事件终止。它还应与行人保持舒适的距离(距离<0.5米),超过此分数将受到处罚,但事件不会终止。社交导航得分(SNS)是STL(按时间长度衡量的成功)和PSC(个人空间合规性)的平均值,用于评估代理的绩效。
社交导航部分面临的挑战之一是难以模拟人类代理的轨迹,包括代理之间的反应和交互。很多时候,要达到目标就需要对空间进行协商,或者代理需要超过所需的个人空间阈值;或者由于行为模型和空间限制的限制,模拟的人类代理行为不稳定。对于未来的版本,我们将强调具有类人行为的高保真导航模拟的重要性。
对于 2020 年挑战赛的 Sim2Real 组件,由于视觉传感器读数、动力学(例如电机驱动)和 3D 建模(例如软地毯)中的现实差距,在 Sim2Real 传输过程中观察到性能显着下降。
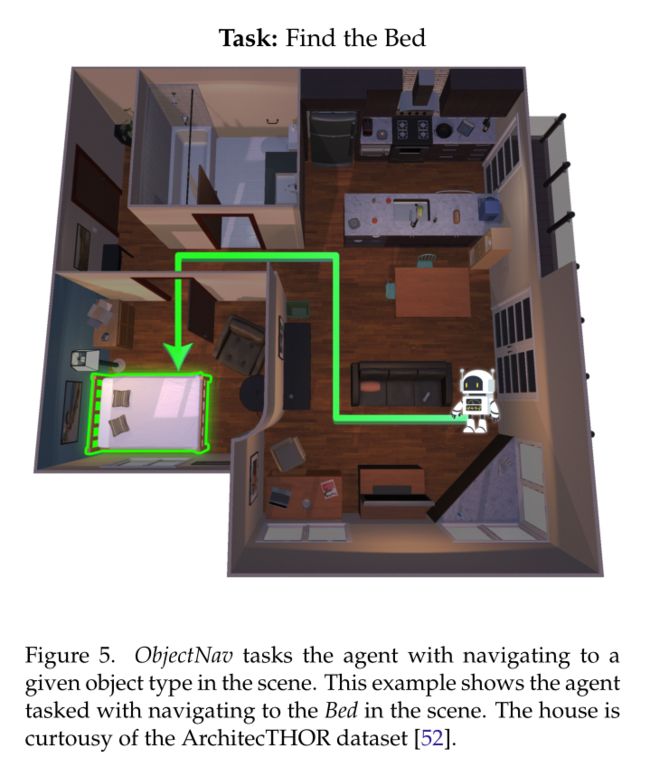
ObjectNav
在 ObjectNav 中,代理的任务是在给定以自我为中心的感官输入的情况下导航到一组目标对象类型中的一个(例如导航到床)。感官输入可以是 RGB 图像、深度图像或两者的组合。在每个时间步骤,代理必须发出以下操作之一:向前移动、向右旋转、向左旋转、向上查找、向下查找和完成。向前移动操作将代理移动 0.25m,旋转和查看操作以 30° 增量执行。
如果
(1) 对象在摄像机画面中可见 ,
(2) 代理与目标对象之间的距离在 1 米以内,
(3) 代理发出“完成”操作,
则被视为成功。
代理的起始位置是场景中的随机位置。
oboTHOR ObjectNav 挑战赛 [51] 和 Habitat ObjectNav 挑战赛 [166, 214]。这两项挑战都使用了上述的动作和观察空间,以及模拟的 LoCoBot 机器人代理。
Multi-ObjectNav
在 Multi-ObjectNav (MultiON) [198] 中,代理在环境中的随机起始位置进行初始化,并要求导航到放置在真实 3D 内部的有序对象序列(图 6a、6b)。代理必须导航到给定序列中的每个目标对象,并调用 Found 操作来表示对象的发现。此任务是 ObjectNav 的通用变体,代理必须导航到一系列对象而不是单个对象。 MultiON 显式测试代理定位先前观察到的目标对象的导航能力,因此是评估基于内存的嵌入式 AI 架构的合适测试平台。
该代理配备了 RGB-D 摄像头和(无噪音)GPS+指南针传感器。 GPS+指南针传感器提供代理相对于其在情节中的初始位置和方向的当前位置和方向。它没有提供环境地图。动作空间包括向前移动 0.25 米、向左旋转 30°、向右旋转 30° 和找到。
MultiON 数据集是通过在 Habitat-Matterport 3D (HM3D) [152] 场景中综合添加对象来创建的。这些物体要么是圆柱形的,要么是看起来自然的(真实的)物体。如图 6a 所示,圆柱体对象具有相同的高度和半径,但颜色不同。然而,这些物体在 Matterport 房屋的室内场景中显得不真实。此外,检测具有不同颜色的同一物体对于代理来说可能很容易学习。这导致我们将房屋中自然出现的逼真物体纳入其中(图 6b)。
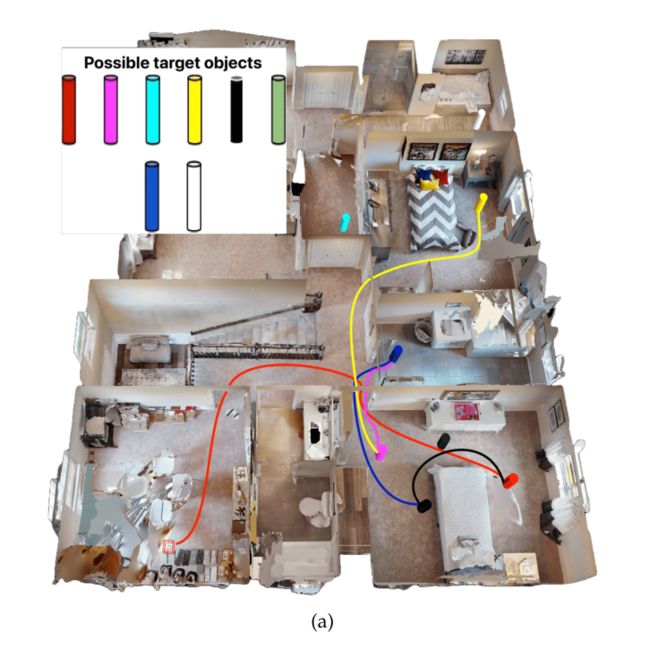

这些物体的大小和形状各不相同,提出了更苛刻的检测挑战。训练部分有 800 个 HM3D 场景和 8M 集,验证部分有 30 个未见过的场景和 1050 个集,测试部分有 70 个未见场景和 1050 个集。这些情节是通过采样随机可导航点作为起始位置和目标位置来生成的,使得这些位置位于同一楼层并且它们之间存在可导航路径。接下来,从一组圆柱体或真实对象中随机采样五个目标对象,将其插入起点和目标之间,保持它们之间的最小成对测地距离以避免混乱。此外,为了使任务更加现实和更具挑战性,每个情节中都会插入三个干扰对象(不是目标)。干扰物的存在将鼓励新智能体区分目标对象和环境中的其他对象。
如果代理能够按指定顺序到达每个目标 1 米范围内并在每个目标对象处生成 FOUND 操作,则事件被视为成功。除了 ObjectNav 中使用的标准评估指标,例如成功率 (SR) 和按路径长度加权的成功 (SPL) [9],我们还使用进度和按路径长度加权的进度 (PPL) 来衡量代理性能。挑战的排行榜基于 PPL 指标。
Navigating to Identify All Objects in a Scene
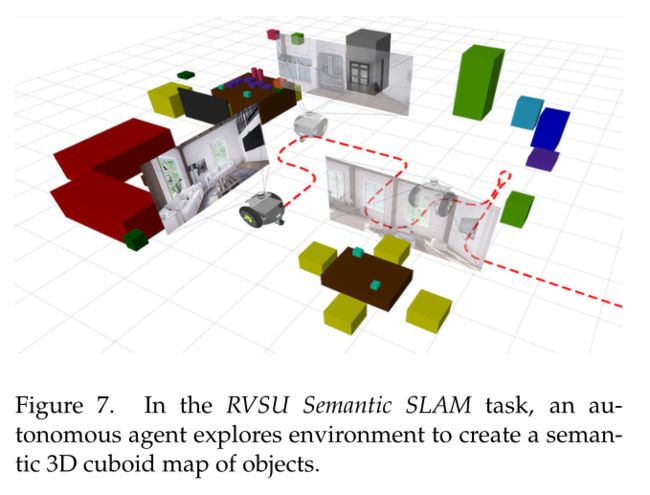
RVSU 语义 SLAM 挑战任务要求参与者探索模拟环境,以绘制其中所有感兴趣的对象。这个挑战向机器人代理提出了一个问题:“什么物体在哪里?”场景内。机器人代理遍历场景,创建该场景内对象的轴对齐 3D 长方体语义图,并根据其地图的准确性进行评估。提供对物体的语义理解可以帮助机器人解释其环境属性的能力,例如知道如何与物体交互以及了解它可能所处的房间类型。这种语义理解通常被视为语义同步定位和地图(SLAM)问题。
语义 SLAM 任务已经使用 KITTI [68]、Sun RGBD [181] 和 SceneNet [115] 等静态数据集进行了大量研究。然而,这些静态数据集忽略了机器人的主动能力,并且放弃在物理动作空间中搜索最能探索和理解环境的动作。为了解决这一限制,RVSU 语义 SLAM 挑战赛 [82] 通过为被动和主动方法的可重复、定量比较提供框架和模拟环境,有助于弥合被动和主动语义 SLAM 系统之间的差距。
Audio-Visual Navigation
虽然当前的导航模型将视觉和移动紧密结合在一起,但它们对周围的世界充耳不闻,在这些因素的推动下,引入了视听导航任务 [38, 66],其中实体代理的任务是导航到发声对象在未知的未映射环境中,具有以自我为中心的视觉和听觉感知(图 8)。这种视听导航任务可以在辅助和移动机器人中找到应用,例如用于搜索和救援操作的机器人以及辅助家庭机器人。除了这项任务之外,还推出了 SoundSpaces 平台,这是第一个同类视听模拟器,实体代理可以在模拟环境中移动,同时看到和听到声音。
Other
其他部分暂时不在研究范围,后续有需要再阅读