pyspark入门---通过协同过滤算法推荐电影
数据集是Movielens官网的ml-100k数据,下载地址
https://grouplens.org/datasets/movielens/
用jupyter实现比较好
from pyspark.sql import SparkSession
user_df=spark.read.text('data/u.user')
user_df.show(10)

##为用户数据添加 schema
from pyspark import Row
user_rdd=user_df.rdd.map(lambda x:x[0].split('|')).map(lambda x:Row(id=x[0],age=x[1],sex=x[2],job=x[3],code=x[4]))
user_rdd.take(5)

#创建用户 dataframe
user_df=spark.createDataFrame(user_rdd)
#注册临时表
user_df.registerTempTable("user")
spark.sql('select id,age,sex,job,code from user').show()

#读取评分数据
rating_df=spark.read.text('data/u.data')
rating_df.show(5)

#为评分数据添加 schema
rating_rdd=rating_df.rdd.map(lambda x:x[0].split()).map(lambda x:Row(user_id=x[0],film_id=x[1],rating=x[2],time=x[3]))
rating_rdd.take(5)

#创建评分 dataframe
rating_df=spark.createDataFrame(rating_rdd)
#注册评分临时表
rating_df.registerTempTable('rating')
spark.sql("select user_id,film_id,rating,time from rating").show()

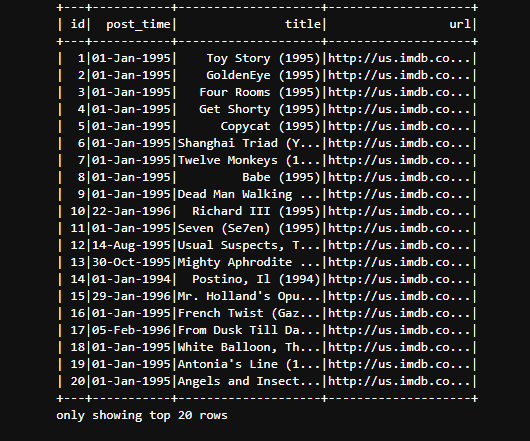
#读取电影信息
film_df=spark.read.text('data/u.item')
film_df.show(5)

#为电影数据添加 schema
film_rdd=film_df.rdd.map(lambda x:x[0].split('|')).map(lambda x:Row(id=x[0],title=x[1],post_time=x[2],url=x[4]))
film_rdd.take(5)

#创建电影 dataframe
film_df=spark.createDataFrame(film_rdd)
#注册电影临时表
film_df.registerTempTable('film')
spark.sql('select * from film').show()
#导入 Spark 机器学习包: 协同过滤算法(需要之前安装好numpy)
from pyspark.mllib.recommendation import ALS
#ALS.trainImplicit 中第一个参数 RDD 是固定格式( 用户编号, 电影编号, 评分值)
rdd=rating_rdd.map(lambda x:(x[3],x[0],x[1]))
rdd.take(5)

#训练模型
model=ALS.train(rdd,10,10,0.01)
#使用模型进行推荐, 参数为用户 id, 推荐个数
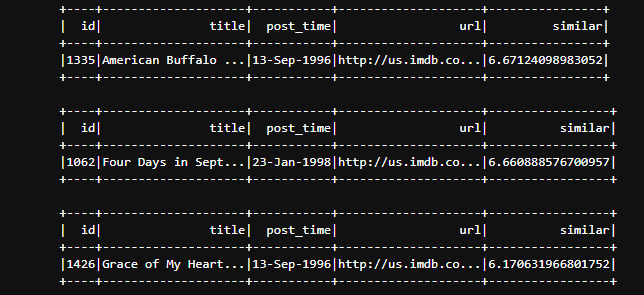
user_film=model.recommendProducts(112,3)
print(user_film)
![]()
#显示推荐电影名称
print(type(user_film))
for film in user_film:
spark.sql("select id ,title,post_time,url , "+str(film[2])+" as similar from film where id="+str(film[1])).show()

#查看用户看过的电影
spark.sql("select a.user_id,b.title from rating a,film b where a.film_id=b.id and a.user_id=112").show()

#保存模型
import os
import shutil
save_path='data/book_model'
if os.path.exists(save_path):
shutil.rmtree(save_path)
model.save(sc,save_path)
print('model saved!')
![]()
#调用模型
from pyspark.mllib.recommendation import MatrixFactorizationModel
model=MatrixFactorizationModel.load(sc,save_path)
result=model.recommendProducts(112,3)
for film in user_film:
spark.sql("select id ,title,post_time,url , "+str(film[2])+" as similar from film where id="+str(film[1])).show()