【AI底层逻辑】——篇章5(下):机器学习算法之聚类&降维&时间序列
续上:
目录
4、聚类
5、降维
6、时间序列
三、无完美算法
往期精彩:
4、聚类
聚类即把相似的东西归在一起,与分类不同的是,聚类要处理的是没有标签的数据集,它根据样本数据的分布特性自动进行归类。
人在认知是事物时倾向于简化,虽然世界上不存在完全相同的个体,但是却不影响对它们进行归类,大脑用抽取共性的方式使得我们快速记忆不同的事物。
聚类是典型的无监督学习算法,基本思路都是利用每个数据样本所表示的向量之间的“距离”或密集程度来进行归类。这与分类算法中的K邻近算法思路相近。典型的“计算距离”的聚类算法有K均值(K-Means)算法,具体步骤如下:
1、任意取k个数据点作为初始中心;
2、依次计算其他点到这些中心的距离;
3、将每个点归类到与它距离最近的中心,每个类别下点下的集合是一个类簇;
4、重新计算各类簇的中心位置(即类簇中所有点的中心——质心;
5、重复上述2、3、4步骤,直到所有数据点都被归类,且类簇的中心位置没有明显变化;此时可认为聚类任务完成,其基本思路就是不断拉拢身边距离相近的样本数据,将它们归为同类。
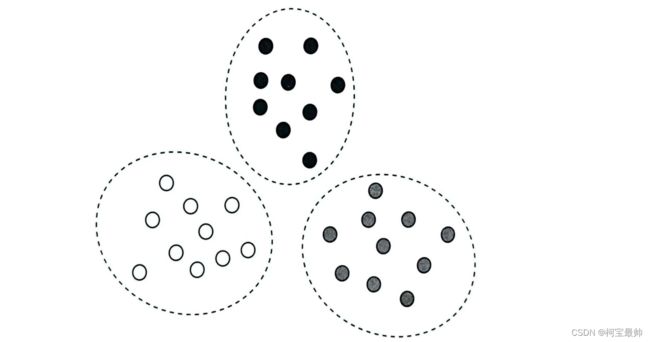
不足:①需要提前指定类簇数量,实际应用时很难知道数据是什么分布,甚至不知道分为几类;②要提前定义初始中心,这个选择通常是随机的(初始中心不同最终结果也可能不同,如果初始中心都在同一类别,会对结果影响很大);③算法需要重复迭代地计算类簇中心,计算开销大;④常用欧式距离划分类簇,但是隐含一个前提假设——数据各个维度变量具有相同的重要性。
“计算距离”只是聚类解题的一种思路,有些情况并不一定数据点之间距离越近就属于一类。因为数据在空间中的分布可能是任意尺寸、任意形状,如曲面。此时可考虑用“计算密度”(即根据数据之间的疏密程度)的方法:

聚类算法应用场景:
①图像分割和特征提取,找到图像中相似的视觉区域;
②从海量论文中找到相似内容和观点的论文;
③异常点检测,如信用卡防欺诈、肿瘤病例筛查、刑侦破案等。
5、降维
大量的数据增加了数据采集和分析的难度,由于许多变量之间存在关联(和、差、积、商或其他运算关系),变量之间的关系不能孤立看待,盲目减少可能损失信息。所以需要一种合理的数据处理方法,在减少变量数量的同时,尽量降低原变量中包含信息的损失程度,如果变量之间存在关联,那么使用更少的综合变量来代替原变量,减少数据维度,理论上可行的——降维。
就如在特征提取时不必提取所有特征,精准抓住足够解决问题的特征即可,这是一个特征选择过程,主成分分析法可帮助我们快速完成特征筛选过程:
主成分分析法(Principal Component Analysis,PCA)在文件压缩、声音降噪等领域有着广泛应用,它是一种把多个变量简化为少数几个主成分的统计方法,这些主成分能反映原变量的绝大部分信息,通常表示为原始变量的线性组合。
PCA数学原理:对数据进行正交线性变换,把原始数据变换到一个新的坐标系中,从而找到新坐标系的主成分,求解过程需要用到矩阵运算和特征分解,关键步骤是如何寻找最大方差的方向。
原变量之间可组成不同的线性组合,PCA尝试找到最佳的特征组合,PCA有两个目标:①尽可能找到最小的特征组合,即去除冗余的特征;②尽可能体现特征的差异,即让不同特征能明显区分——举例来说,随意挑选两个特征构建它们的散点图,如下图所示,图中每个点有两个特征,分别对应X轴和Y轴,在图中画一条直线,将所有点投影到这条线上就可以构建出一个新的特征(新的X轴)——它可以通过两个旧特征的线性组合来表示。
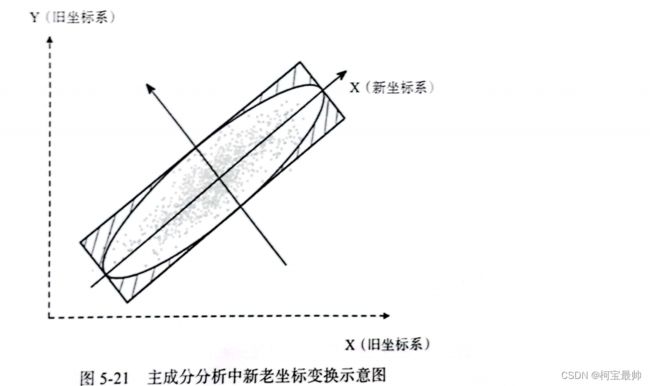
不仅如此,PCA还会根据两种不同的“最佳”标准找到最合适的新坐标系:①让数据投影在新坐标系上的点(新特征)尽量分散,即方差最大化;②让新特征与原来的两个特征的距离偏差最小,即误差最小化。当同时满足上述两点时,新的特征组合就找到了。
PCA去除了冗余信息,保留了最有可能重建原有特征的新特征,这些新特征更有区分度,数学表征上方差更大。所以PCA不仅可以实现降维,也可以作为提取有效特征(特征工程)的一种方法,在分析数据时尤为有用。
6、时间序列
时间序列是一组按照时间顺序记录的有序数据,对时间序列进行观察、研究、找寻变化规律,预测未来趋势,即为时间序列分析。时间序列属于统计学的一个分支,遵循统计学基本原理——利用观察数据估计总体的性质。但时间序列也有其特殊性,由于时间不可回退,也不可重复,使得时间序列分析拥有一套自成体系的分析方法。
常用的时间序列分析方法大致有两种!
第一种采用趋势拟合的方法,比如提取时间序列的各种趋势规律(如ARIMA(差分整合自回归移动平均)算法),或用各种不同的频率和幅度的波形叠加组合(如傅里叶变换、小波分析),还有前面的回归算法。第二种采用特征提取的方法,比如使用统计方法、专家经验提取时间序列特征,将这些特征、原始时序数据、标签等输入人工神经网络进行训练,或使用具有上下文记忆功能的人工神经网络算法。并没有特定分析方案,需要根据实际的数据特点挑选算法,也可以多个算法结合使用。
下面详细展开一种常用方法,这种方法考察时间序列数据的趋势性、周期性、季节性以及剩余不规则变化(随机变动,也叫残差)。
①趋势性可使用线性回归、指数曲线、多项式函数来描述!
②周期性是一种循环的变动,取决于一个系统内部影响因素的周期变化规律,表现为一段时间内数据呈现涨落相同、峰谷交替的循环变动!
③如果一些波动受季节影响,说它是一种季节性变化。许多销售数据或经济活动会收到季节的影响!
④剔除时间序列的趋势性、周期性、季节性,剩余的波动部分通常被归为不规则变化,它包含突然性变动和随机性变动。随机性变动是数据以随机形式呈现出的变动(通常是无法解释的噪声);突然性变动可能由突发事件导致,表现为一些异常值。
模型构建:趋势性、周期性、季节性都可以用时间序列的相关算法构建具体的数学模型,这些模型叠加组合后的总体结果。叠加效果数学上通常有两种处理方法,①各个影响因素相互累加,如信息熵的计算,一个时间的信息熵是每个子事件信息熵之和——加法模型假定多个影响因素之间相互独立,互不影响;②各个影响因素的结果相乘,如概率的计算,事件发生的概率是每个子事件发生的概率之积——乘法模型假定各个因素之间会相互影响。乘法模型较为常用,加法和乘法也可混合使用。
注:时间序列模型在解决实际问题时,序列必须满足特定的数据分布,或者具有平稳的时间序列特性,比如在剔除趋势数据后,时间序列不能与时间有依赖关系,数据波动的频率和幅度不能随时间变化等。如果不能满足检验要求,则无法通过模型求解。
三、无完美算法
没有一个算法可以在任何领域总是表现最佳,不存在普遍适用的最优算法。使用任何算法都必须要有与待解决问题相关的假设,一旦脱离具体问题,空谈算法毫无意义!
一个好的算法不在于它足够复杂,而在于它的逻辑简洁、清晰、设计优雅!你觉得算法复杂是因为所要解决的场景复杂!——算法是简洁和高度抽象的表达,场景才是复杂的!

往期精彩:
【AI底层逻辑】——篇章3(下):信息交换&信息加密解密&信息中的噪声
【AI底层逻辑】——篇章3(上):数据、信息与知识&香农信息论&信息熵
【机器学习】——续上:卷积神经网络(CNN)与参数训练
【AI底层逻辑】——篇章1&2:统计学与概率论&数据“陷阱”
【AI底层逻辑】——篇章5(上):机器学习算法之回归&分类