顺序表和链表 手撕链表深入解析链表实现
目录
线性表
顺序表
动态数组的实现
链表
单链表和其实现
单链表的实现(不带虚拟头结点的版本)
单链表的实现(带虚拟头结点的版本)
双向链表的实现
符如果需要下面代码的完整实现代码,可以去我的码云仓库获取
我的码云仓库 https://gitee.com/song-cheng-liu/java_-package_-code
https://gitee.com/song-cheng-liu/java_-package_-code
线性表
线性表 ( linear list ) 是 n 个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构
- 常见的线性表 顺序表,链表,栈,队列,字符串(因为本质还是字符数组).........
- 线性表就是让多个相同数据类型元素逻辑上呈直线排列,逻辑上连续(逻辑连续就是想象它是连续的,但现实中不一定是要由连续的内存实现),但是物理上不一定连续,这种数据结构就叫做线性表
- 线性表的存储在物理上通常用数组或者链式结构实现
数组结构这种存储方式,在物理上是一个挨着一个,中间没有空隙,在物理上是连续存储的
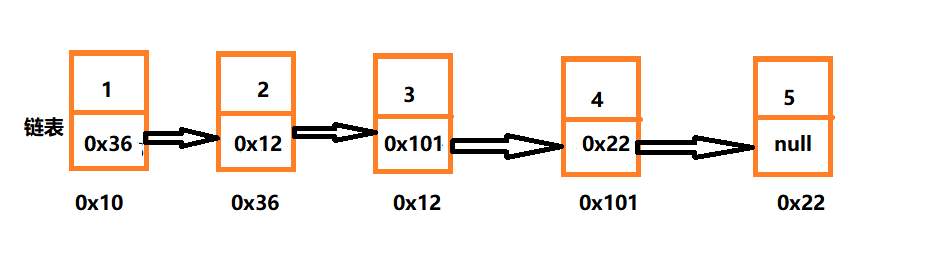
链表结构这种存储方式,在物理上并不是连续存储的,它将一个数据的空间分为两个区域,一个为数据域,存储数据,另一个为指针域,指针域存储下一个逻辑上连续的数据的地址
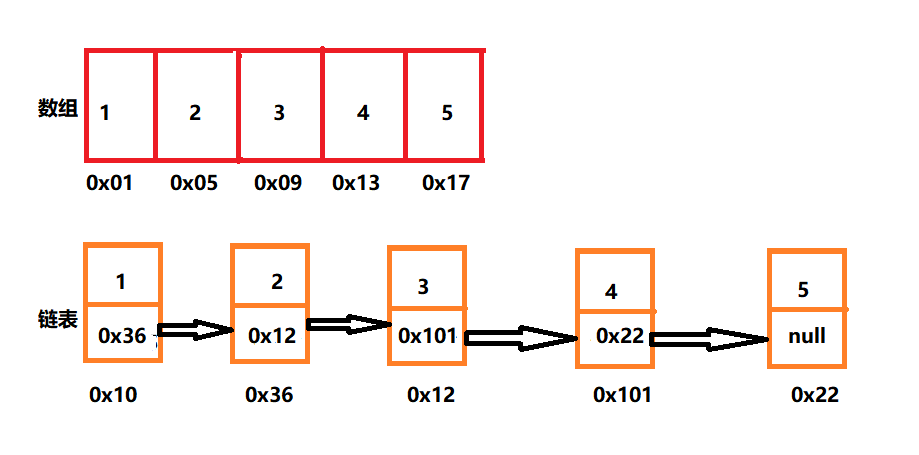
顺序表
顺序表是用一段 物理地址连续 的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改顺序表的分类
- 静态顺序表(用定长数组实现存储)
- 动态顺序表(用动态开辟的数组实现存储)
动态数组的实现
动态数组 就是在普通的数组的基础上,增加一个可以实现元素的动态调整数组大小的功能,我们在使用普通数组时,是不可以改变其长度的,所以需要我们自己定义一个类来实现这些功能
类的成员属性
public class MyArrary { private int[] arr;//先定义出这个动态数组 private int size=0; //这个size是用来表示下一个要存储数据的索引 // 也可以表示这个数组已经有多少个元素了 }构造方法
public MyArrary(){ arr=new int[10]; //不规定数组的大小,则默认大小为10 } public MyArrary(int initCap){ arr=new int[initCap]; //在实例化对象时,指定开辟空间的大小 }无参构造默认代表开辟了 10 个大小的数组空间
有参构造就是开辟 initCap 大小的数组空间
grow 扩容功能方法
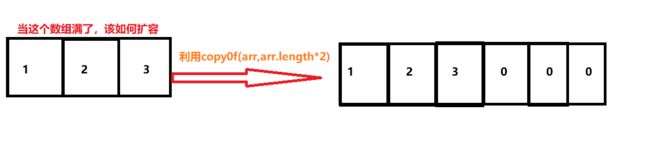
利用Arrays.copyOf来实现扩容功能,当拷贝的长度大于原数组,则用默认值来填充
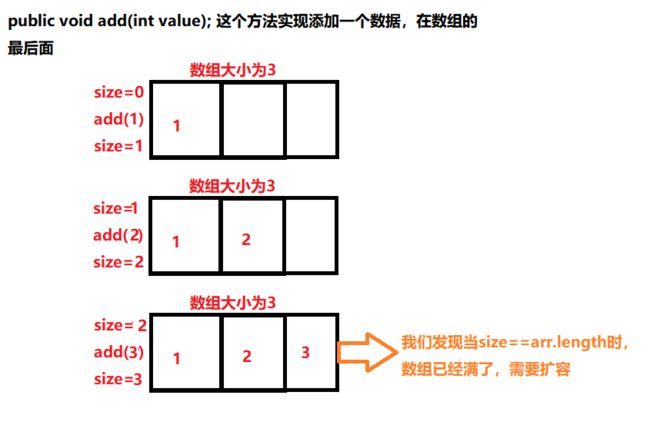
/** * 这份方法应该对外界不可见的, * 你扩容只要能实现用户增加数据的要求,外部不需要知道如何实现 */ private void grow(){ this.arr=Arrays.copyOf(arr,arr.length*2); }add添加元素方法
/** * 实现在动态数组的最后添加一个值为value的元素 * @param value */ public void add(int value){ arr[size]=value; size++; if (size== arr.length){ //此时数组已经满了,扩容当前数组 grow(); } }addIndex 指定索引添加一个值
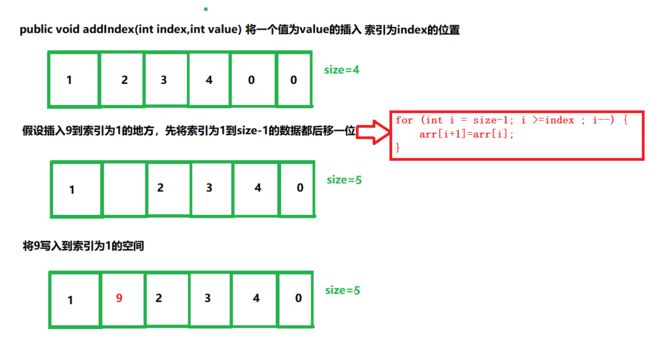
/** * 这个方法用来将值为value插到下标为index的索引下标 * @param index * @param value * @return */ public boolean addIndex(int index,int value){ if (index<0||index>size) { System.out.println("输入的索引值不规范"); return false; } for (int i = size-1; i >=index ; i--) { arr[i+1]=arr[i]; } arr[index]=value; size++; if (size==arr.length){ grow(); } return true; }
- 为什么在后移操作中,我们不需要担心数组是满的,因为如果我们添加数据的时候,如果数组满了,我们都会,将数组直接扩容为原来的两倍,所以不用担心后移时数组满了这个情况
- 为什么在判断索引值的合法性时,是index>size,因为如果当index=size的时候,表示是在数组有效元素后面添加一个元素,因为我们扩容的方式,所以不存在数组满的情况,所以不会发生越界
查询功能
/** * 查找是否存在value这个值,存在就返回true,不存在就返回false * @param value * @return */ public boolean contains(int value){ return getByValue(value)!=1; } /** * 查找数组中是否存在value这个值 * 如果存在返回第一个值为value的索引值 * 不存在就返回-1 * @param value * @return */ public int getByValue(int value){ //利用遍历查找是否存在这个value值的数据 for (int i = 0; i < size; i++) { if (value==arr[i]){ return i; } } return -1; } /** * 查询索引值为index的值 * @param index * @return */ public int get(int index){ if (index<0||index>=size){ System.out.println("你输入的索引值不规范"); return -1; } return arr[index]; }
- 为什么在get中判断索引值要index>=size,因为size表示的是总共有多少个有效元素,所以索引的有效值在0至size-1;
修改功能
/** * 修改索引值为index的值为newVal * 返回oldVal * @param index * @param newVal * @return */ public int set(int index,int newVal){ if (index<0||index>=size){ System.err.println("你输入的索引值不规范"); return -1; } int oldVal=arr[index]; arr[index]=newVal; return oldVal; } /** * 修改第一个值为value的值为newVal * 如果不存在这个为value,则返回false * @param value * @param newVal * @return */ public boolean setByValue(int value,int newVal){ int ret=getByValue(value); if (ret==-1){ System.err.println("不存在该值,修改失败"); return false; } arr[ret]=newVal; return true; }
- 我们要善用我们已经写过的代码,比如我们在setByValue中,利用了getByValue这个方法来查找Value这个值是否存在
删除功能
/** * 将索引为index的值删除 * @param index * @return */ public int removeIndex(int index){ if (index<0||index>=size){ System.err.println("该索引不规范,删除失败"); return -1; } int oldVal=arr[index]; for (int i = index; i
/** * 删除第一个元素 * @return */ public int removeFirst(){ return removeByIndex(0); } /** * 删除最后一个元素 * @return */ public int removrLast(){ return removeByIndex(size-1); }
/** * 删除第一个值为value的值 * 如果没有这个值就返回false * 如果删除成功就返回true * @param value * @return */ public boolean removeByValue(int value){ int index=getByValue(value); if (index==-1){ System.out.println("不存在这个数,删除失败"); return false; } removeByIndex(index); return true; }
public boolean removeAllByValue(int value){ int flag=0; for (int i = 0; i < size; i++) { if (arr[i]==value){ removeByIndex(i); flag=1; i--;//因为删除了一个数,在removeByIndex的作用下, // 所有的索引值都会-1,所以减一才是下个数值的索引 } } if (flag==0){ System.out.println("不存在这个数,删除失败"); return false; } else { return true; } }






链表
- 链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 。
- 表结构这种存储方式,在物理上并不是连续存储的,它将一个数据的空间分为两个区域,一个为数据域,存储数据,另一个为指针域,指针域存储下一个逻辑上连续的数据的地址
单链表和其实现
我们可以将单链表类比成火车
- 火车之间不是连续密封在一起的,是靠着一个个钩子将车厢链接在一起 ,就像我们的单链表,也不是在内存中连续存储的,是靠当前结点存储了下一个结点的地址才将整个链表链接起来(最后一个结点的指针域存储null,表示尾结点,类比火车最后一个车厢的钩子是没有勾任何东西的,就表示为空)
- 每个结点类比为车厢,整个链表就类比为一个火车,我们去买火车票的时候,注重的是我们买的是那班火车,而不是那一节车厢,所以在使用链表的时候,应该去使用链表这个类,而不是结点这个类,我们只要去使用链表,不去关心如何这个链表是如何实现的,就像我们去坐火车,只享受火车提供的便利,而不去关心火车怎么跑起来的,火车怎么把车厢链接起来的
- Node类——>火车车厢 SingleLinkList——>火车 head结点表示SingleLinkList(通常我们生活中用火车头去代表这个火车,类比链表用头结点去代表这个链表)
- 单链表分为两类,一类是不带虚拟头结点的,一类带虚拟结点(不存储数据,只存储第一个实际结点的地址)(不带虚拟头结点就类似于一个火车都是车厢组成,我们把最前面的车厢当成这个火车的代表,所以这个意义上的火车头会随着车厢的增加和减少而变化,带虚拟头结点的就是带有火车头的火车,火车头是给车长的,是不会坐乘客的,而且不管车厢的增加减少,火车头总是在最前面)
- 单向链表的特征:因为我们每个结点都只保存了下一个结点的地址,而我们只能用头结点去代表这个链表类,所以链表的遍历必须从头结点开始,所以这种链表结构被称为单向链表
单链表的实现(不带虚拟头结点的版本)
Node 和 SingleLinkList的数据类型实现
public class Node {//类比火车的车厢 int val;// 存储当前结点的数据 Node next;//引用类型,存储下一个结点的数据 }public class SingleLinkList { private Node head;//头结点,用来表示这个链表,类比于火车头 private int size; //表示当前链表有多少个结点 }链表的打印功能
public String toString(){//打印函数 String ret=""; Node x=head; while (x!=null){ ret+=x.val; ret+="->"; x=x.next; } ret+="NULL"; return ret; }链表的增加结点功能
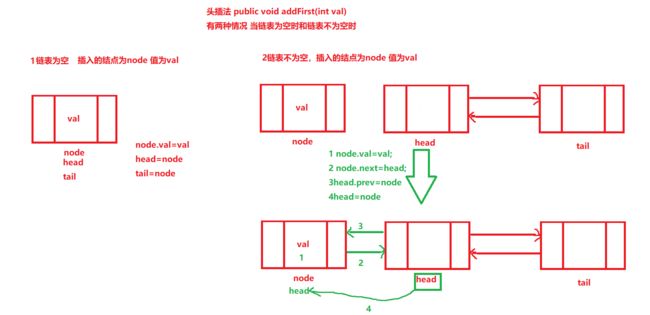
头插法
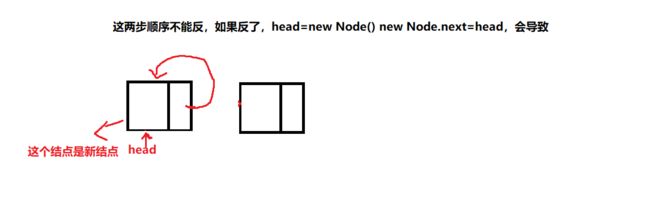
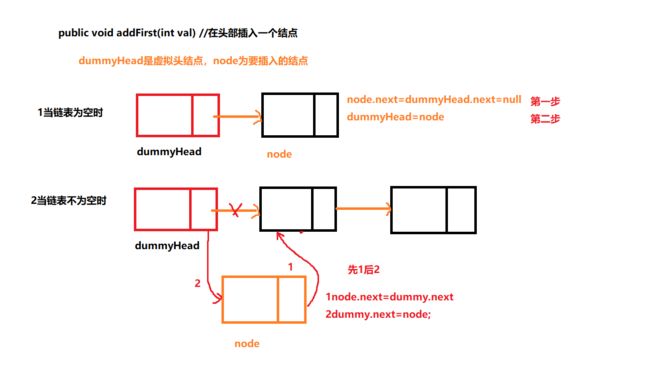
public void addFirst(int val)
public void add(int val){//头插法添加元素 Node newNode=new Node(); newNode.val=val; if (head==null){ //当前是一个空链表 head=newNode; } else { //当前链表不为空 newNode.next=head; } head=newNode; size++; }在任意位置插入结点
public void add(int val,int index)
public void add(int index,int val){ if (index<0&&index>size){ System.out.println("索引值不规范,插入识别"); return; } if (index==0){ addFirst(val); }else { Node newNode=new Node(); newNode.val=val; Node prev=head; for (int i = 0; i < index - 1; i++) { prev=prev.next; } newNode.next=prev.next; prev.next=newNode; size++; } }在结尾插入一个结点
public void addLast(int val)
调用add函数
public void addLast(int val){ add(size,val); }检查索引是否合法的方法
private boolean rangeIndex(int index) { if (index>=0&&index
- 因为只在类的内部用,所以应该封装起来
- 这个方法在修改,查询,删除
查询功能
/** * 找到第一个值为val的结点的索引 * @param val * @return */ public int getByValue(int val){ Node node=head;//定义一个临时变量存储头结点,不然遍历一次,就不能拿head遍历了 int index=0; for (node=head; node!=null; node=node.next) { if (node.val==val){ return index; } index++; } System.out.println("这个值为"+val+"值不存在"); return -1; }
- 从头结点开始遍历,直到找到这个值,如果node==null(表示遍历完整个链表了),还没有找到,说明这个数据链表中不存在
/** * 查找索引为index结点的数据 * @param index * @return */ public int getByIndex(int index){ Node node=head;//定义一个临时变量存储头结点,不然遍历一次头结点改变,就不能拿head遍历了 if (rangeIndex(index)){ for (int i = 0; i < index; i++) { node=node.next; } return node.val; }else { return -1; } }
- 从头结点开始遍历,走index步,就走到了索引值为index的结点,因为头结点的索引值是0
/** * 判断一个是否含有值为val的结点 * @param val * @return */ public boolean contains(int val){ int ret=getByValue(val); return ret!=-1; }
- 调用getByValue方法
修改功能
public int set(int index,int newVal){ if (rangeIndex(index)){ Node node=head; for (int i = 0; i < index; i++) { node=node.next; } int oldVal=node.val; node.val=newVal; return oldVal; }else { return -1; } }删除功能
链表删除最重要的点就是在于找前驱结点
/** * 删除索引为index的结点 * @param index * @return */ public int remove(int index){ if (rangeIndex(index)){ if (index==0){//删除头结点 Node node=head; int oldVal=node.val; head=head.next; node.next=null;//切断原头结点跟后面结点的联系 size--; return oldVal; }else { Node prev= head;//这个结点是前驱结点的定义 //通过这个循环,找到要删除结点的前驱结点 for (int i = 0; i < index-1; i++) { prev=prev.next; } Node node=prev.next;//node是要被删除的结点 int oldVal=node.val; prev.next=node.next; node.next=null;//切断被删除结点跟后面结点的联系 size--; return oldVal; } } else { return -1; } }
- 最重要的核心点是找前驱结点,通过是否有前驱结点,将删除结点分为两种情况
- 走index-1步,就能找到索引为index结点的前驱结点
- 记得解除被删除结点与后面结点的联系(最好写一下)
删除第一个值为val的结点
/** * 删除第一个为值为val的结点 * @param val */ public void removeByValOnce(int val){ if (head==null){ //因为不能判断索引值的合法性,所以要防止链表为空链表 System.out.println("链表为空,删除失败"); return; } Node node=head;//定义要被删除的结点 if (node.val==val){ head=head.next; node.next=null; return; } else { //说明头结点不是我们要删除的结点,所以其他情况肯定有前驱结点 Node prev=head;//定义前驱结点 //因为我们在前面判断过head是不是被删除的结点, //所以在这我们定义的prev=head肯定不是被删除结点 while (prev.next!=null){ if (prev.next.val==val){ node=prev.next; prev.next=node.next; node.next=null; return; } prev=prev.next; } System.out.println("删除失败"); } }删除全部的val的结点
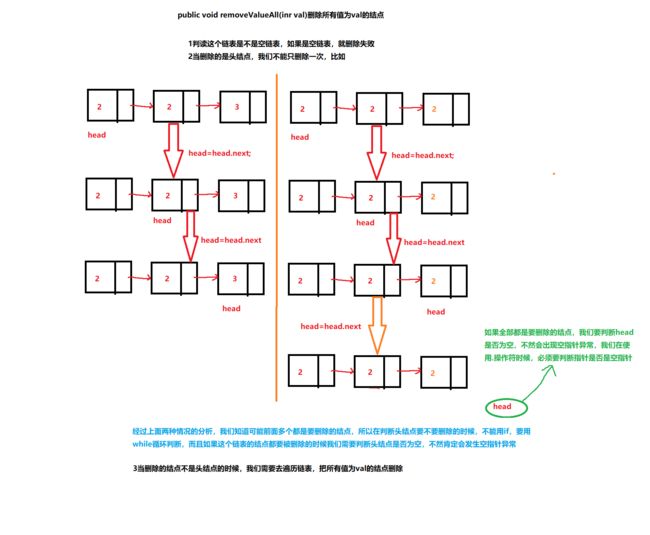
/** * 删除所有值为val的结点 * @param val */ public void removeByValueAll(int val){ Node node=head;//定义要被删除的结点 if (head==null){ System.out.println("链表为空,删除失败"); return; } while (head!=null&&head.val==val){//因为head会在这个循环变换,所以要判断是否为空指针 node=head; head=head.next; node.next=null; size--; } if (head==null){ return; }else { Node prev=head; while (prev.next!=null){ if (prev.next.val==val){ node=prev.next; prev.next=node.next; node.next=null; size--; } else { prev=prev.next; } } } }删出头结点
public int removeFirst() { return remove(0); }删除尾结点
public int removeLast() { return remove(size - 1); }







单链表的实现(带虚拟头结点的版本)
- 为什么要带虚拟头结点,我们发现在删除,修改,插入结点等的时候,我们都要跟区分头结点和其他结点这两种情况处理,比较麻烦,但是如果添加虚拟头结点,在进行这些操作就不需要区分头结点和其他结点这两种情况了
- 什么是虚拟头结点,我们把单链表当作一个火车,结点就是一个个车厢,没有虚拟的头结点的单链表就像没有火车头的火车,我们只能把最前面的车厢当作意义上的火车头来表示这辆火车,虚拟头结点就是事实上的火车头,不管你怎么添加车厢,火车头永远是它,且火车头坐乘客(头结点不存储数据)
- 链表的索引是不包括虚拟头结点,就像说这辆火车的第几个车厢,不是从火车头开始数,而是从第一个车厢开始数
Node和SingleLinkListWithDummyNode的数据结构实现
public class SingleLinkListWithDummyHead { int val; Node dummyHead= new Node();//虚拟头结点 //这个结点是实实在在存在的,不像之前的head只是一个引用,并没有new新的结点 }public class Node {//类比火车的车厢 int val;// 存储当前结点的数据 Node next;//引用类型,存储下一个结点的数据 public Node() { } public Node(int val, Node next) { this.val = val; this.next = next; } //使用有参构造方法,在添加结点时会使代码简便很多 public Node(int val) { this.val = val; } }链表的打印功能
public String toString (){ String ret=""; for (Node node=dummyHead.next;node!=null;node=node.next){ ret+=node.val; ret+="->"; } ret+="NULL"; return ret; }增加结点功能
头插法
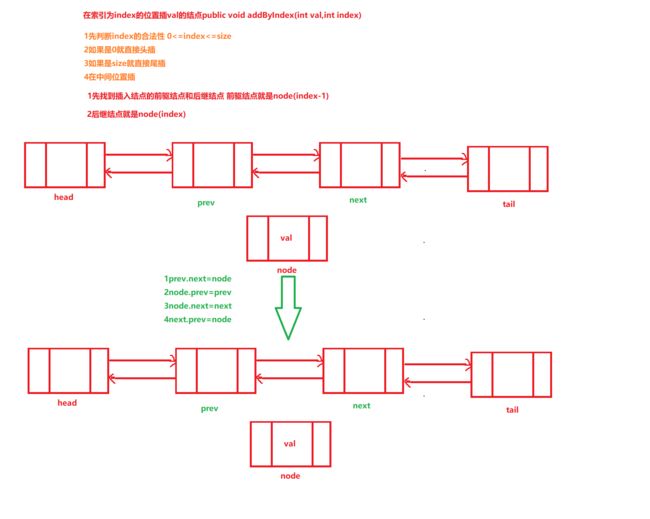
public void addFirst(int val){ // 最普通的写法 // Node node=new Node(); // node.val=val; // node.next=dummyHead.next; // dummyHead.next=node; // size++; //利用构造函数 // Node node=new Node(val,dummyHead.next); // dummyHead.next=node; // size++; //利用构造函数和匿名对象 dummyHead.next=new Node(val,dummyHead.next); //因为程序是从右向左运行,所以先执行new Node(val,dummyHead.next)的内容 size++; }在任意索引为index位置插入结点
public void addByIndex(int val,int index){ if (index<0||index>size){ System.out.println("索引不规范,添加失败"); return; }else { Node prev=dummyHead;//为插入结点的前驱结点 for (int i = 0; i < index; i++) { prev=prev.next; } // 第一种 普通方法 // Node node=new Node(); // node.val=val; // node.next=prev.next; // prev.next=node; // size++; //利用有参构造函数 // Node node=new Node(val,prev.next); // prev.next=node; // size++; //利用有参构造函数和匿名对象 prev.next=new Node(val,prev.next); size++; } }在尾部添加一个结点
/** * 在尾部添加一个值为val的结点 * @param val */ public void addLast(int val){ addByIndex(val,size); }判断索引合法性
private boolean rangeIndex(int index){ if (index>0&&index
- 这个索引的判断用于删除,修改,查询不用于添加
- 因为只在类的内部使用,所以用private封装起来
查询功能
/** * 查找索引为index的val值 * @param index * @return */ public int getByIndex(int index){ if (rangeIndex(index)){ Node node=dummyHead.next; for (int i = 0; i < index; i++) { node=node.next; } return node.val; } else { return -1; } } /** * 查找第一个值为val的index * @param val * @return */ public int getByValue(int val){ int index=0; Node node=null; for (node=dummyHead.next;node!=null;node=node.next){ if (node.val==val){ return index; } index++; } return -1; } /** * 查找链表中是否存在val的结点 * @param val * @return */ public boolean contains(int val){ int ret=getByValue(val); return ret!=-1; }修改功能
public int set (int val,int index){ if (rangeIndex(index)) { Node node = dummyHead.next; for (int i = 0; i < index; i++) { node = node.next; } int oldVal = node.val; node.val = val; return oldVal; }else { return -1; } }删除功能
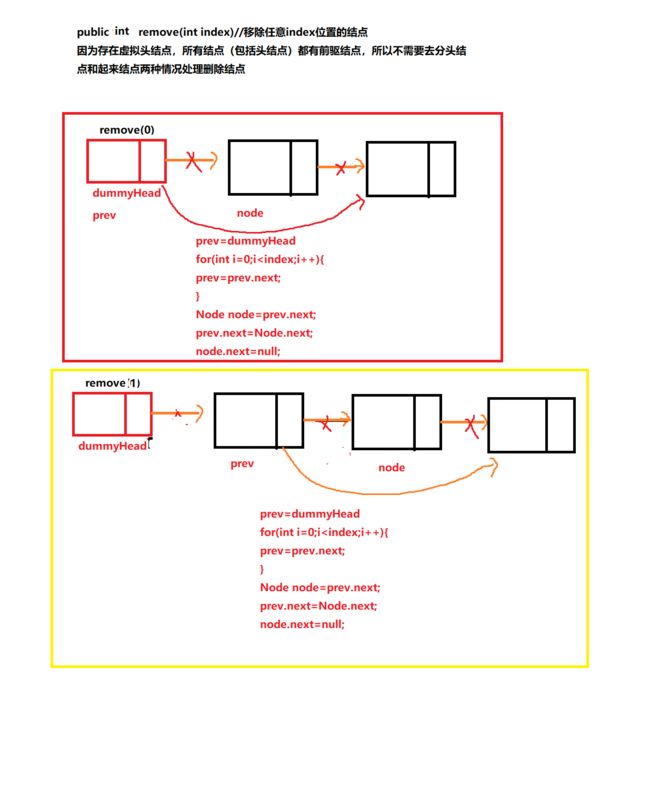
public int remove(int index)
public int remove(int index){ if (rangeIndex(index)){ Node prev= dummyHead; for (int i = 0; i < index; i++) { prev=prev.next; } Node node=prev.next; int oldVal=node.val; prev.next=node.next; node.next=node=null; size--; return oldVal; } else { return -1; } }删除第一个值为val的结点
public int removeByValueOnece(int val){ Node prev=dummyHead;//定义前驱结点 int index=0; while (prev.next!=null){ Node node= prev.next;//定义要删除的结点 if (node.val==val){ prev.next=node.next; node.next=null; size--; return index; }else { prev=prev.next; index++; } } return -1; }删除所有值为val的结点
public void removeByValueAll(int val){ Node prev=dummyHead;//定义前驱结点 while (prev.next!=null){ Node node= prev.next;//定义要删除的结点 if (node.val==val){ prev.next=node.next; node.next=null; size--; }else { prev=prev.next; } } }删除头结点
public void removeFirst(){ remove(0); }删除尾结点
public void removeLast(){ remove(size); }




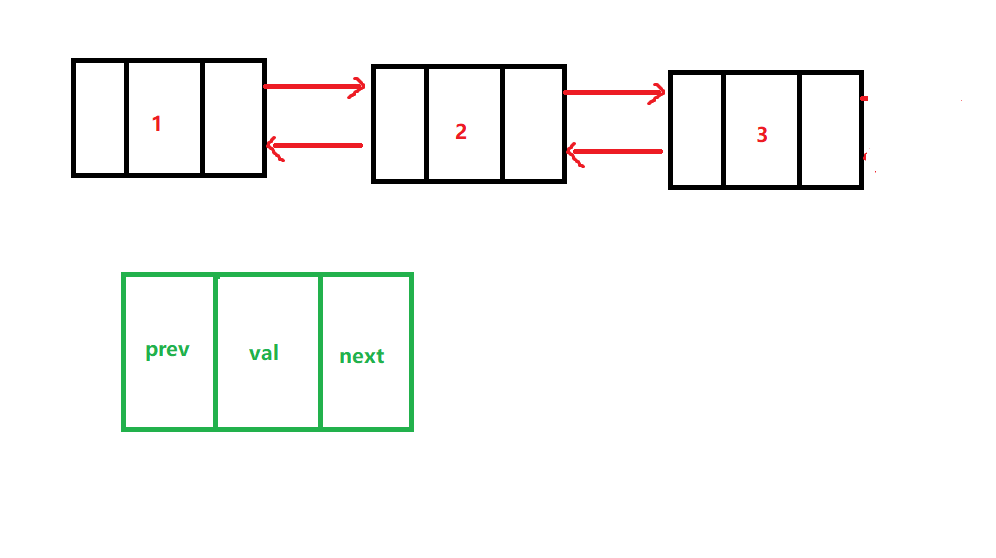
双向链表的实现
什么是双向链表
像这样可以指向本结点的前驱节点也可以指向本结点的后继节点的链表
为什么要引入双向链表
从前面知道单链表过于局限,如果想得到一个结点,只能从前往后去遍历,在实际应用中是比较少的,所以我们引入了这种双向链表,既可以通过本结点向前走也可以向后走的链表
在JDK中LinkList--->双向链表
双向链表及结点的数据结构实现
public class DoubleLinkList { private ListNode head;//头结点 private ListNode tail;//尾结点 private int size;//表示当前有多少个结点,也表示下一个要添加的结点的索引值 }public class DoubleLinkedNode { ListNode prev;//指向前驱结点 int val;//当前结点存储的值 ListNode next;//指向后继结点 public DoubleLinkedNode() { } public DoubleLinkedNode(int val) { this.val = val; } public DoubleLinkedNode(ListNode prev, int val, ListNode next) { this.prev = prev; this.val = val; this.next = next; } }打印功能
public String toString(){ String ret=""; for ( DoubleLinkedNode node=head;node!=null;node=node.next) { ret+=node.val; ret+="->"; } ret+="NULL"; return ret; }插入功能
头插法
public void addFirst(int val) { // DoubleLinkedNode node=new DoubleLinkedNode(); // node.val=val; // if (head==null){ // head=node; // tail=node; // }else { // node.next=head; // head.prev=node; // head=node; // // } // size++; //可以化简成这样 DoubleLinkedNode node=new DoubleLinkedNode(null,val,head); //利用构造方法 if (head==null){ tail=node; }else { head.prev = node; } //对于头插来说,无论链表为不为空,最后head=node; head=node; size++; }尾插法
public void addTail(int val){ DoubleLinkedNode node=new DoubleLinkedNode(tail,val,null); if (head==null){ head=node; }else { tail.next=node; } tail=node; size++; }在索引为index的位置插入一个结点
public void addByIndex(int val,int index){ if (index<0||index>size){ System.out.println("索引不规范,添加失败"); }else { if (index==0){ addFirst(val); return; } if (index==size){ addTail(val); return; } DoubleLinkedNode prev=node(index-1); DoubleLinkedNode next=node(index); DoubleLinkedNode node=new DoubleLinkedNode(prev,val,next); prev.next=node; next.prev=node; size++; } }这种是用双指针来实现,我们来一种更难理解的单指针来实现,只使用它的前驱节点
public void addByIndex(int val,int index){ if (index<0||index>size){ System.out.println("索引不规范,添加失败"); }else { if (index==0){ addFirst(val); return; } if (index==size){ addTail(val); return; } DoubleLinkedNode prev=node(index-1); DoubleLinkedNode node=new DoubleLinkedNode(prev,val,prev.next); prev.next.prev=node; prev.next=node; size++; } }根据索引找到结点的地址
public DoubleLinkedNode node(int index){ DoubleLinkedNode node=null; if (index>=size/2){ node=tail; for (int i = size-1; i > index; i--) { node=node.prev; } }else { node=head; for (int i = 0; i < index; i++) { node=node.next; } } return node; }检查索引是否规范(用于删除,查找,修改,不用于添加)
private boolean rangeIndex(int index) { if (index>0&&index查找功能
z
public int getByIndex(int index){ if (rangeIndex(index)) { return node(index).val; }else { return -1; } }public int getByValue(int value){ int index=0; for (DoubleLinkedNode node=head;node!=null;node=node.next){ if (node.val==value){ return index; } index++; } return -1; }public boolean contain(int value){ return getByValue(value)!=-1; }删除功能
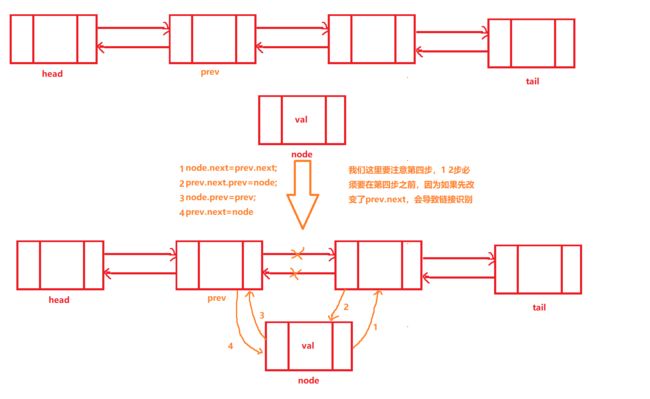
删除节点的操作
在这我们引入非常重要的一种思想,就是分治思想
private void unlink(DoubleLinkedNode node){ // DoubleLinkedNode prev=node.prev; DoubleLinkedNode next=node.next; if (prev==null){//前驱为空,删除头结点 // head=head.next; head=next; }else { prev.next=next; node.prev=null; } if (next==null){ tail=prev; }else { next.prev=prev; node.next=null; } size--; }删除索引为index的结点
public int removeByIndex(int index){ if (rangeIndex(index)){ DoubleLinkedNode node=node(index); int oldVal=node.val; unlink(node); return oldVal; }else { return -1; } }删除头结点
public void removeFirst() { removeByIndex(0); }删除尾结点
public void removeLast() { removeByIndex(size - 1); }删除第一个值为value的结点
public void removeByValueOnec(int value){ for(DoubleLinkedNode node=head;node!=null;node=node.next){ if (node.val==value){ unlink(node); break; } } }删除所有值为value的结点
public void removeByValueAll(int value){ for(DoubleLinkedNode node=head;node!=null;){ if (node.val==value){ DoubleLinkedNode x=node.next; //因为删除node,它的next就断了找不到后继结点了 unlink(node); node=x; }else { node=node.next; } } }