深入学习 Redis - 深挖经典数据类型之 zset
目录
前言
一、zset 类型
1.1、操作命令
zadd / zrange(添加 / 查询)
zcard(个数)
zcount(区间元素个数)
zrevrange(逆序展示)
zrangebyscore(按分数找元素)
zpopmax / zpopmin(删除)
bzpopmax / bzpopmin(阻塞删除)
zrank / zrevrank(排名)
zscore(分数)
zrem(删除)
zremrangebyrank / zremrangebyscore(删除指定区间)
zincrby(增加分数)
交集、并集、差集说明
zinterstore / zunionstore(交集 / 并集)
1.2、内部编码方式
1.3、使用场景
排行榜系统
前言
redis 中所有的 key 都是字符串,value 的类型是存在差异的,因此出现了操控不同 value 的命令,接下来,就一起来学习一下吧~
Ps1:接下来,我给出的指令都是按照 Redis 官方文档的语法格式来解析的,[ ] 相当于一个独立的单元,表示可选项(可有可无),其中 | 表示 “或者” 的意思,多个只能出现一个,[ ] 和 [ ] 之间是可以同时存在的.
Ps2:一个快速失去年终奖的小技巧 —— 清除 redis 上所有的数据 =》 FLUSHALL,这个操作可以把 redis 上所有的键值对全部带走.
一、zset 类型
1.1、操作命令
Zset 是一个有序且唯一的集合,在 zset 中的 member 同时引入了一个属性 score(分数),支持浮点类型,也就是说每一个 member 都安排一个分数,并且默认按照分数进行升序排序.
Ps:zset 中的 member 和 score 不是键值对的关系,可以称为是一个 "pair",类似于 C++ 中的 std::pair。
对于有序集合来说,既可以通过 member 找到对应的 score ,又可以通过 score 找到匹配的 member。
zadd / zrange(添加 / 查询)
使用 zadd 往有序集合中,添加元素和分数.
时间复杂度是 O(log N),这是由于 zset 是有序结构,新增元素需要放在合适的位置上,底层是通过 跳表 这个数据结构实现的.
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...]
以下是对几个选项的说明:
- NX | XX:的使用和之前 set 添加元素使用一样,这里值得注意的是 不加 NX | XX 选项时,当 member 不存在,此时就会达到 “添加新 member” 的效果,如果当前 member 已经存在,此时就会更新分数.
- LT | GT:LT(less than)表示一旦要进行更新分数,如果分数比之前小,则更新成功,否则不跟新;GT(greater than)反之.
- CH:默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更新的元素的个数。
- INCR:此时命令类似 zincrby 的效果,将元素的分数加上指定的分数。此时只能指定⼀个元素和 分数。
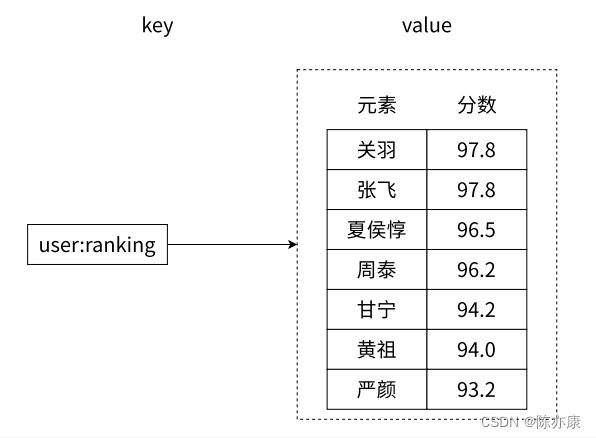
使用 zrange 查看 有序集合 中的元素详情(类似于 lrange 可以指定下标构成区间)
ZRANGE key start stop [WITHSCORES]Ps:加上 withscores ,就可以连分数一起显示.


![]()
zcard(个数)
获取 zset 中的元素个数.
ZCARD key
zcount(区间元素个数)
获取分数在 min 和 max 之间(默认是闭区间)的元素个数,其中 min 和 max 本身就是浮点数类型,可以哦那个 inf 表示无穷大, -inf 表示 负无穷大.
ZCOUNT key min max时间复杂度是 O(log N),具体执行流程如下:
先根据 min 找到对应的元素,再根据 max 找到对应的元素(这里的时间复杂度就是 O(log N) ),这里实际上 zset 内部会记录每个元素当前的 “排行 / 次序”,因此查到元素后就知道元素的 “次序”(下标),就可以直接把 max 对应的元素次序和 min 对应的元素次序,做减法即可.

Ps:如果想要排除边界值,可以使用括号,但是表示比较奇葩~,使用 ( 表示开区间,例如我要获取(70,98)这个区间的个数,就需要如下写法表示
一个好的设定是符合直觉的,但为什么这么设定?
这是为了考虑兼容性的原因:一旦在新的版本中引入和之前不兼容的特性,成本是非常高的(不兼容的案例最典型的就是 IPv6),一般来说,如果确实需要做出这种不兼容的修改,可以先把这个要修改的内容标记成 “弃用”(给程序员打个预防针),同时推出新的版本,若干个版本之后,再逐渐把这样的功能完成修改.

zrevrange(逆序展示)
zrevrange 中的 rev 就是 reverse 的缩写,表示逆序的意思。默认是升序,通过 zrevrange 就可以实现分数降序排序.
ZREVRANGE key start stop [WITHSCORES]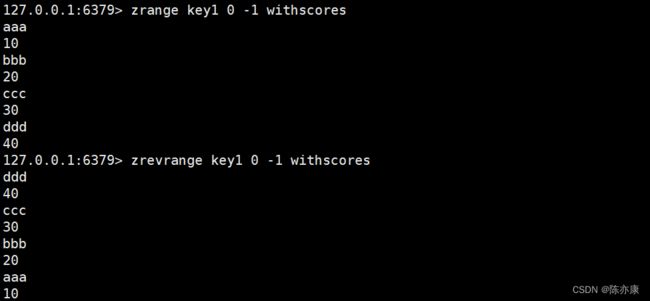
zrangebyscore(按分数找元素)
按照分数来找元素,和 zcount 类似.
ZRANGEBYSCORE key min max [WITHSCORES]Ps:这个命令可能在 6.2.0 之后废弃,并且将功能合并到 zrange 中.

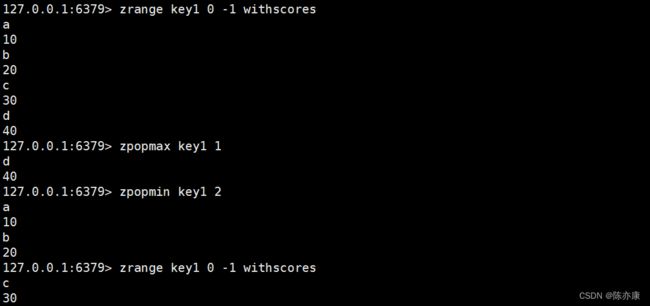
zpopmax / zpopmin(删除)
zpopmax 用来删除分数最高的 count 个元素.
zpopmin 用来删除分数最低的 count 个元素.
Ps:若分数一样,就按照字典序来删除其中的 count 个元素
ZPOPMAX key [count]
ZPOPMIN key [count]时间复杂度为 O(log(N) * M),其中:
- N 表示有序集合的元素个数.
- M 表示要删除 count 个元素.
使用 zpopmax 删除的是最大值,在有序集合中就是最后一个元素(尾删),既然是尾删,为什么我们不把最后一个元素的位置的记录下来,后续删除不就直接就 O(1) 了嘛?
但是很遗憾, redis 目前并没有这么做~
事实上,redis 的源码中,针对有序集合,确实是记录尾部的位置,但在删除的时候,并没有用上这个特性,而是直接使用了一个 “通用的删除函数”(给定一个 member 的值,进行查找找到位置后再进行删除).
但这里我认为是存在优化空间的,确实可以通过记录+尾删达到 O(1) 的复杂度,但是这种优化的活要优化在刀刃上~ 优化一般是要找到性能瓶颈,进行针对的优化,但是当前这个 log N 的速度也不慢,如果 N 不是夸张的大,基本是可以近似 O(N) 的~
比如去追一个妹子:
- 经常在她面前刷存在感,混个脸熟.(1个月)
- 约出来一起玩(叫上很多僚机). (2个月)
- 单独约出来玩.(3个月)
- 确定关系.(1年)
那么如果你在第一条上使劲优化,是没啥乱用的~
bzpopmax / bzpopmin(阻塞删除)
阻塞版本的 zpopmax / zpopmin,这里的 有序集合 可以认为是一个 带阻塞功能 的 "优先级队列",在队列为空的时候阻塞,直到其他客户端插入元素为止.
BZPOPMAX key [key ...] timeout
BZPOPMIN key [key ...] timeout
timeout 表示超时时间,表示最多阻塞多久,单位是 s,支持小数形式.
时间复杂度是 log(N).
Ps:当 bzpopmax / bzpopmin 监听了多个 key,表示是从这若干个 key 中只删除一次.


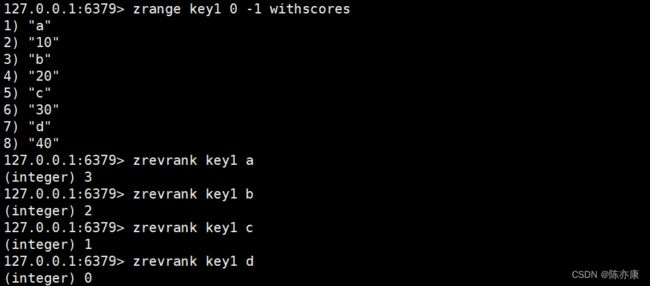
zrank / zrevrank(排名)
zrank 和 zrevrank 都是返回指定元素的排名(下标),其中 zrank 按照升序排序,zrevrank 按照降序排序.
时间复杂度为 O(log N),主要是有个查询位置的过程(可以认为是在堆中查找元素)。
ZRANK key memberZREVRANK key member

zscore(分数)
获取指定元素的分值.
ZSCORE key member时间复杂度是 O(1),之前根据 member 找元素,都是 logN ,这里虽然也是要先找元素,但是 redis 对于此处的查询做了特殊的优化,付出了额外的空间代价.
zrem(删除)
删除指定的 member 元素.
ZREM key member [member ...]
时间复杂度是 O(logN * M),其中 N 表示有序集合中元素的个数(因为要先找到元素),M 是 member 的个数.

zremrangebyrank / zremrangebyscore(删除指定区间)
zremrangebyrank 是指定下标描述范围来进行删除(元素升序排序).
zremrangebyscore 是指定分数区间进行删除.
Ps:区间都是闭合的(左闭右闭).
ZREMRANGEBYRANK key start stop
ZREMRANGEBYSCORE key min max时间复杂度是 O(logN * M),其中 N 表示有序集合中元素的个数(因为要先找到元素),M 是要删除的元素个数.


zincrby(增加分数)
为指定的元素的关联分数添加指定的分数值。
ZINCRBY key increment member
Ps:修改分数后,任然保持升序.

交集、并集、差集说明
zinter、zunion 、zdiff 这三个命令是从 redis 6.2 开始支持的,咱们使用的是 redis 5 ,此处不涉及.
zinterstore / zunionstore(交集 / 并集)
求出多个 key 之间的交集,并保存到一个新的集合中,合并的同时元素按照不同方式得到新的分值.
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE ] 几个参数的说明:
destination:表明了要把结果存储到哪一个 zset 中.
numkeys:是一个整数,描述了后面又几个 key 参与交集运算(这样设定是为了将自定义的 key 和后面的参数区分开来,类似于 HTTP 协议中 Content-Length 的作用——解决 TCP 面向字节流传输的粘包问题).
weights:权重,相当于一个系数,会乘上当前的分数(类似于数学中的权值,假如我是一个好看有才华的妹子,那么追我的不同小哥哥身上都会有不同的权值,比如长得帅占5%、会舔占2%、有钱占93%......).
addregete:这里提供了三种参数,描述了相交的元素分数的处理方式(若不设置,默认是求和).
Ps:zunionstore 用法 和 zinterstore 基本一致.

1.2、内部编码方式
内部编码方式有以下两种:
- skiplist:跳表,类似于 leetcode 上的一个经典题目,“复制带随机指针的链表”,跳表也是链表,不同于普通的链表,每一个节点上有多个指针域,巧妙的搭配这些指针域的指向就可以做到,从跳表上查询元素的时间复杂度是 O(logN),相比于树形结构,更适合范围获取元素.
- ziplist:压缩列表,当哈希表里的元素比较少的时候,就优化成了 ziplist 了,能够节省空间(压缩的原因:redis 上有很多 key,可能某些 key 的 value 是 hash,此时如果 key 特别多,对应的 hash 也特别多,但是每个 hash 又不是特别大的情况下,就尽量去压缩,让整体占用内存更小了).
、
Ps:如果有序集合中元素较少,或者单个元素体积较小,使用 ziplist 来存储,这样更节省内存空间。如果元素较多,或者单体过大,就是用 skiplist 来存储了.
1.3、使用场景
排行榜系统
这种场景有很多:微博热搜、游戏天梯排行、成绩排行......
例如使用 zset 来实现 游戏天梯排行,只需要把玩家的信息和对应的分数给放到有序集合中即可,自动就生成一个排行榜,随时可以按照排行(下标),按照分数,进行范围查询~
也可以通过 zincrby 来修改分数,排行也能自适应调整(logN).
玩家那么多,zset 能存下吗?
userId 4 个字节 score 8 个字节来理解,那么表示一个玩家大概是 12 个字节,往多了算,1 亿玩家,大概是 12亿 字节 => 1.2 GB(这里的单位换算一定要张口就来~ 影响升职加薪),这大么?
游戏排行榜的先后顺序还是比较容易确定的,但是像 微博热度 这种就不太好算~
他是根据综合数值来衡量的:
- 浏览量
- 点赞量
- 转发量
- 评论量
这就需要根据每一个维度的权重,来计算综合得分,此时就可以借助 zinterstore / zunionstore 按照加权的方式来处理了,具体的,member 就是 微博 的 id,而 score 就是通过 zinterstore / zunionstore 按照约定好的权重,进行集合运算即可,最后得到的集合分数就是热度,排行榜也就出来了.
