Elasticsearch Query DSL
Elasticsearch Query DSL
这里使用的 Elasticsearch 的版本为 7.12.1。
1、基本概念
1.1 文档(Document)
ElasticSearch 是面向文档的,文档是所有可搜索数据的最小单位,例如 MySQL 的一条数据记录。
文档会被序列化成为 json 格式,保存在 ElasticSearch 中。
每个文档都有一个唯一 ID,例如 MySQL 中的主键 ID。
JSON文档
一篇文档包括了一系列的字段,例如数据中的一条记录。
json 文档,格式灵活,不需要预先定义格式。
文档的元数据
GET /users/_search

_index :文档所属的索引名
_type:文档所属类型名
_id:文档唯一ID
_score:相关性分数
_source:文档的原始JSON数据
1.2 索引
索引是文档的容器,是一类文档的结合,每个索引都有自己的mapping定义,用于定义包含的文档的字段和类型
每个索引都可以定义 mapping 和 setting,mapping 是定义字段类型,setting 定义不同的数据分布。
GET /users
{
"users" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"userName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "users",
"max_result_window" : "10000000",
"creation_date" : "1640698832865",
"number_of_replicas" : "1",
"uuid" : "w0nGfHpKQki7CqKYpzi7Kw",
"version" : {
"created" : "7120199"
}
}
}
}
}
1.3 Type
7.0之前,一个Index可以设置多个type,所以当时大多数资料显示的都是type类型与数据库的表。
7.0之后,一个索引只能创建一个type,_doc。
若不好理解,可以对比MySQL类比一下:
在es6.0以前,关系型数据库的术语和Elasticsearch的术语的对应关系:
| 关系型数据库 | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | 类型(types) |
| 行(rows) | 文档(documents) |
| 列(columns) | 字段(fields) |
es6.0以后废弃了类型这个概念,于是在es6.x和7.x,有如下对应关系:
| 关系型数据库 | Elasticsearch |
|---|---|
| 表(tables) | 索引(indices) |
| 行(rows) | 文档(documents) |
| 列(columns) | 字段(fields) |
1.4 节点
节点是一个ElasticSearch的实例,本质上就是java的一个进程,一台机器可以运行多个ElasticSearch进程,但生
产环境下还是建议一台服务器运行一个ElasticSearch实例。
每个节点都有名字,通过配置文件配置,或者启动时 -E node.name=node1。
每个节点在启动后,会分配一个UID,保存在data目录下。
主节点:master
默认情况下任何一个集群中的节点都有可能被选为主节点,职责是创建索引、删除索引、跟踪集群中的节点、决定
分片分配给相应的节点。索引数据和搜索查询操作会占用大量的内存、cpu、io资源。因此,为了保证一个集群的
稳定性,应该主动分离主节点跟数据节点。
数据节点:data
看名字就知道是存储索引数据的节点,主要用来增删改查、聚合操作等。数据节点对内存、cpu、io要求比较高,
在优化的时候需要注意监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
负载均衡节点:client
该节点只能处理路由请求,处理搜索,分发索引等操作,该节点类似于Nginx的负载均衡处理,独立的客户端节点
在一个比较大的集群中是非常有用的,它会协调主节点、数据节点、客户端节点加入集群的状态,根据集群的状态
可以直接路由请求。
预处理节点:ingest
在索引数据之前可以先对数据做预处理操作,所有节点其实默认都是支持ingest操作的,也可以专门将某个节点配
置为ingest节点。
1.5 分片
分片分为主分片,副本分片。
主分片:用以解决数据水平扩展的问题,将数据分布到集群内的所有节点上,一个分片是一个运行的Lucene(搜索
引擎)实例,主分片数在创建时指定,后续不允许修改,除非Reindex。
副本:用以解决数据高可用的问题,可以理解为主分片的拷贝,增加副本数,还可以在一定程度上提高服务的可用
性。
在生产环境中分片的设置有何影响
分片数设置过小会导致无法增加节点实现水平扩展,单个分片数据量太大,导致数据重新分配耗时。假设你给索引
设置了三个主分片 ,这时你给集群加了几个实例,索引也只能在三台服务器上。
分片数设置过大导致搜索结果相关性打分,影响统计结果的准确性,单个节点上过多的分片,会导致资源浪费,同
时也会影响性能。
从ElasticSearch7.0开始,默认的主分片设置为1,解决了over-sharding的问题。
1.6 集群
查看集群健康状态
GET _cluster/health

green:主分片与副本都正常分配
yellow:主分片全部正常分配,有副本分片未能正常分配
red:有主分片未能分配,当服务器的磁盘容量超过85%时创建了一个索引
2、索引和文档操作
2.1 查询所有索引
GET /_cat/indices

GET /_cat/indices?v

# 查看状态为绿色的索引
GET /_cat/indices?v&health=green

# 根据文档数据倒序
GET /_cat/indices?v&s=docs.count:desc
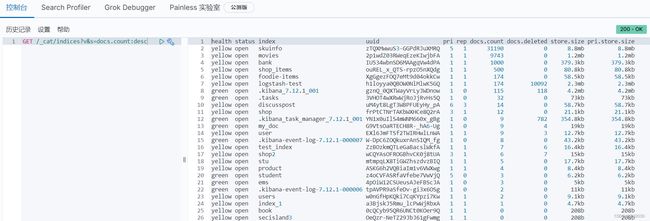
# 查看索引具体字段
GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs,count,mt

# 查看索引所占的内存
GET /_cat/indices?v&h=i,tm&s=tm:desc

# 获取索引状态
GET /_cat/indices/movies?v&s=index

2.2 删除某个索引
DELETE /test_index

2.3 新增索引
PUT /test_index

2.4 查看索引
GET /test_index

# 查看索引的文档总数
GET /test_index/_count

2.5 创建映射
PUT /test_index/_mapping
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"store": false
},
"city": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"store": false
},
"age": {
"type": "long",
"store": false
},
"description": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"store": false
}
}
}

2.6 查看映射
GET /test_index/_mapping

2.7 新增文档数据
自动生成id
POST /test_index/_doc
{
"name": "李四",
"age": 22,
"city": "深圳",
"description": "李四来自湖北武汉!"
}

指定id
PUT /test_index/_doc/1
{
"name": "Tom",
"age": 22,
"city": "深圳",
"description": "Tom来自美国!"
}

POST和PUT的区别:
使用PUT时需要在后面指定
_id,比如PUT /dangdang/_doc/6中的6就是指定的_id,POST可以指定也可以不指定。
POST和PUT指定
_id之后如果该_id存在的话就会先删除原先的文档,后添加新的文档。
PUT /test_index/_create/1
{
"name": "Tom",
"age": 22,
"city": "深圳",
"description": "Tom来自美国!"
}

PUT /test_index/_create/10
{
"name": "Tom",
"age": 22,
"city": "深圳",
"description": "Tom来自美国!"
}

指定_create ,如果该id的文档已经存在,操作失败。
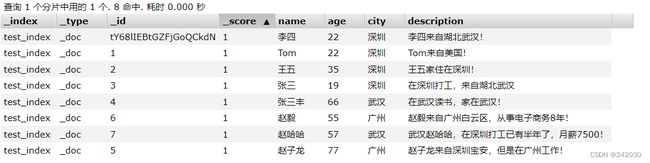
我们再增加几条记录:
#新增文档数据 id = 2
PUT /test_index/_doc/2
{
"name": "王五",
"age": 35,
"city": "深圳",
"description": "王五家住在深圳!"
}
#新增文档数据 id = 3
PUT /test_index/_doc/3
{
"name": "张三",
"age": 19,
"city": "深圳",
"description": "在深圳打工,来自湖北武汉"
}
#新增文档数据 id = 4
PUT /test_index/_doc/4
{
"name": "张三丰",
"age": 66,
"city": "武汉",
"description": "在武汉读书,家在武汉!"
}
#新增文档数据 id = 5
PUT /test_index/_doc/5
{
"name": "赵子龙",
"age": 77,
"city": "广州",
"description": "赵子龙来自深圳宝安,但是在广州工作!"
}
#新增文档数据 id = 6
PUT /test_index/_doc/6
{
"name": "赵毅",
"age": 55,
"city": "广州",
"description": "赵毅来自广州白云区,从事电子商务8年!"
}
#新增文档数据 id = 7
PUT /test_index/_doc/7
{
"name": "赵哈哈",
"age": 57,
"city": "武汉",
"description": "武汉赵哈哈,在深圳打工已有半年了,月薪7500!"
}
2.8 查看文档
GET /test_index/_doc/1

2.9 修改数据
a、替换操作
更新数据可以使用之前的增加操作,这种操作会将整个数据替换掉,代码如下:
#更新数据,id=4
PUT /test_index/_doc/4
{
"name": "张三丰",
"description": "在武汉读书,家在武汉!在深圳工作!"
}
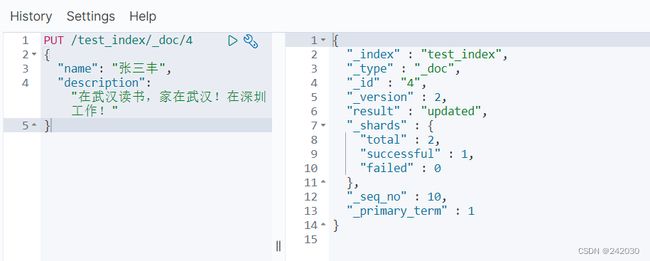
使用GET命令查看:
#根据ID查询
GET /test_index/_doc/4

b、更新操作
我们先使用下面命令恢复数据:
#恢复文档数据 id=4
PUT /test_index/_doc/4
{
"name": "张三丰",
"age": 66,
"city": "武汉",
"description": "在武汉读书,家在武汉!"
}
使用POST更新某个列的数据
POST /test_index/_update/1
{
"doc":{
"name":"think in java2",
"bir":"2021-06-03 10:34:00"
}
}
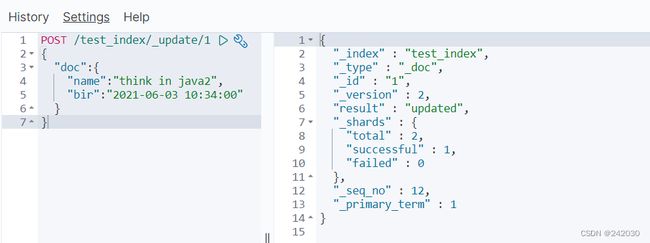
POST /test_index/_update/1 _update是关键字,doc也是关键字,如果doc里的字段文档里没有,则会
在文档里新增这个字段。
_update方法不会删除原有文档,而是实现真正的数据更新。
使用GET命令查看:
#根据ID查询
GET /test_index/_doc/1

2.10 删除Document
# 删除数据
DELETE /test_index/_doc/1


2.11 批量操作,添加、删除、修改
支持在一次Api调用中,对不同的索引进行操作,支持index、create、update、delete。
操作中单条操作失败,不会影响其它继续操作,并且返回结果包括了每一条操作执行的结果。
PUT /test_index/_doc/_bulk
{"index":{}}
{"name": "赵子龙1","age": 77,"city": "广州","description": "赵子龙来自深圳宝安,但是在广州工作!"}
{"index":{}}
{"name": "赵子龙2","age": 77,"city": "广州","description": "赵子龙来自深圳宝安,但是在广州工作!"}
{"delete":{"_id":"2"}}
{"delete":{"_id":"4"}}
{"update":{"_id":"5"}}
{"doc":{"name":"marry","age":20}}
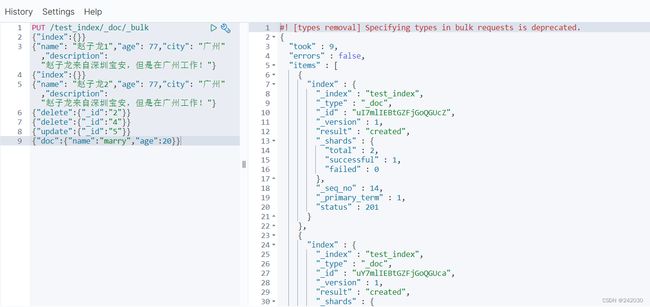

index:向索引中添加文档,可以添加多个文档;可以在新增的时候添加id:{"index":{"_id":"1"}}
delete:删除文档,可以删除多个文档;
update:修改文档,可以修改多个文档;
也可以进行create操作:
{"create":{"_id":"3"}}
{"name":"kaka_create"}
这里需要大家注意:bulk api 对json语法有严格的要求,每个json串不能换行,只能放一行,同时一个json和另一
个json串之间必须有一个换行。
bulk api 可以同时操作多个索引,例如:
POST /_bulk
{"index":{"_index" : "test1","_id" : "1"}}
{"name":"kaka_bulk"}
{"delete":{"_index":"test1","_id":"2"}}
{"create":{"_index":"test2","_id":"3"}}
{"name":"kaka_create"}
{"update":{"_id":"1","_index":"test1"}}
{"doc":{"name":"kaka_bulk"}}
2.12 数据查询
a、查询所有数据
#查询所有
GET /test_index/_search

b、根据ID查询
#根据ID查询
GET /test_index/_doc/3

c、Sort排序
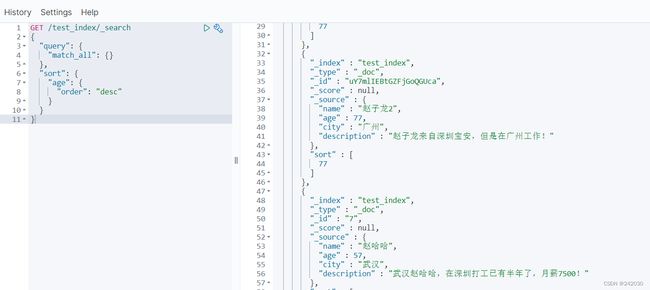
#搜索排序
GET /test_index/_search
{
"query": {
"match_all": {}
},
"sort": {
"age": {
"order": "desc"
}
}
}
d、分页
#分页实现
GET /test_index/_search
{
"query": {
"match_all": {}
},
"sort": {
"age": {
"order": "desc"
}
},
"from": 0,
"size": 2
}
解释:
from:从下N的记录开始查询
size:每页显示条数

2.13 批量读取
GET /_mget
{
"docs": [
{"_index":"test_index","_id":"1"},
{"_index":"movies","_id":"2"}
]
}

2.14 批量搜索
POST /test_index/_msearch
{}
{"query":{"match_all":{}},"size":1}
{"index":"movies"}
{"query":{"match_all":{}},"size":1}

3、条件过滤
# 只搜索test_index索引下的内容
GET /test_index/_search
# 搜索全部索引下的内容
GET _search
3.1 term过滤
term主要用于分词精确匹配,如字符串、数值、日期等
不适合情况:
1、列中除英文字符外有其它值
2、字符串值中有冒号或中文
3、系统自带属性如_version
如下案例:
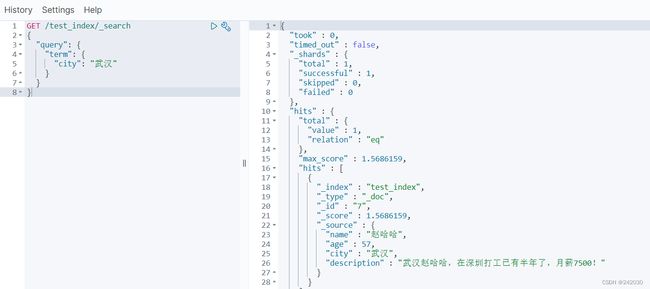
#过滤查询-term
GET /test_index/_search
{
"query": {
"term": {
"city": "武汉"
}
}
}
3.2 terms 过滤
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去
做匹配 。
#过滤查询-terms 允许多个Term
GET /test_index/_search
{
"query": {
"terms": {
"city": ["武汉", "广州"]
}
}
}

3.3 range 过滤
range 过滤允许我们按照指定范围查找一批数据,例如我们查询年龄范围。
#过滤-range 范围过滤
#gt表示> gte表示=>
#lt表示< lte表示<=
GET /test_index/_search
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 57
}
}
}
}

3.4 exists过滤
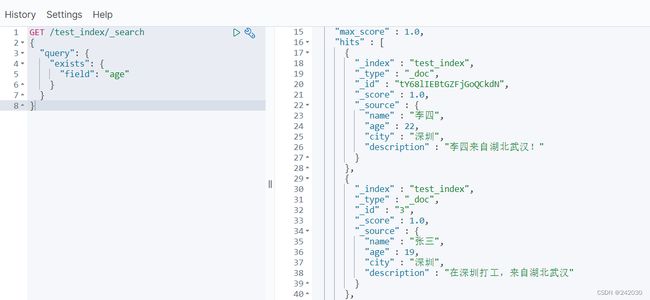
exists 过滤可以用于查找拥有某个域的数据。
#过滤搜索 exists:是指包含某个域的数据检索
GET /test_index/_search
{
"query": {
"exists": {
"field": "age"
}
}
}
3.5 bool 过滤
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含一下操作符:
-
must: 多个查询条件的完全匹配,相当于 and。 -
must_not: 多个查询条件的相反匹配,相当于 not。 -
should: 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组。
#过滤搜索 bool
#must : 多个查询条件的完全匹配,相当于 and。
#must_not : 多个查询条件的相反匹配,相当于 not。
#should : 至少有一个查询条件匹配, 相当于 or。
GET /test_index/_search
{
"query": {
"bool": {
"must": [{
"term": {
"city": {
"value": "深圳"
}
}
}, {
"range": {
"age": {
"gte": 20,
"lte": 99
}
}
}]
}
}
}

3.6 match_all 查询
可以查询到所有文档,是没有查询条件下的默认语句。
#查询所有 match_all
GET /test_index/_search
{
"query": {
"match_all": {}
}
}

3.7 match 查询
match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析match一下查询字符。
#字符串匹配
GET /test_index/_search
{
"query": {
"match": {
"description": "武汉"
}
}
}

3.8 prefix 查询
以什么字符开头的,可以更简单地用 prefix ,例如查询所有以张开始的用户描述。
#前缀匹配 prefix
GET /test_index/_search
{
"query": {
"prefix": {
"name": {
"value": "赵"
}
}
}
}
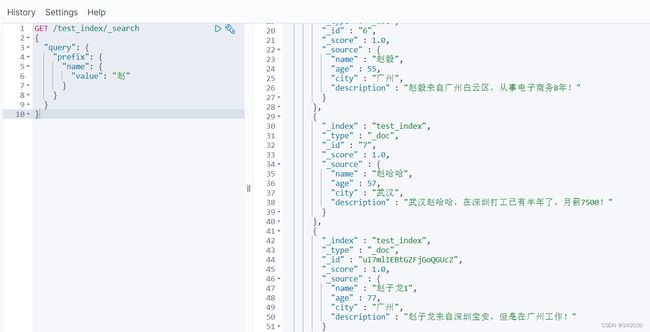
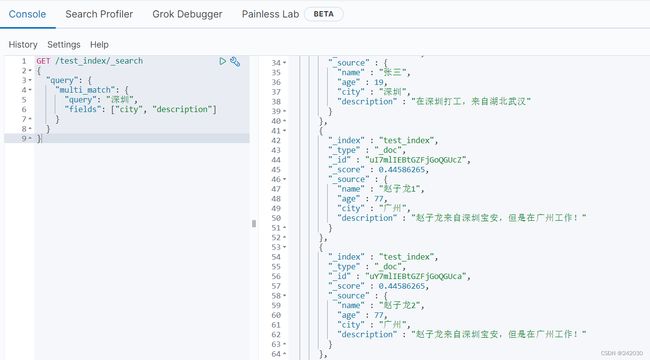
3.9 multi_match 查询
multi_match查询允许你做match查询的基础上同时搜索多个字段,在多个字段中同时查一个。
#多个域匹配搜索
GET /test_index/_search
{
"query": {
"multi_match": {
"query": "深圳",
"fields": ["city", "description"]
}
}
}
4、使用Analyzer进行分词
首先你得知道什么是分词:Analysis把全文本转换为一系列单词的过程叫做分词
Analysis通过Analyzer实现的,可以通过ElasticSearch内置的分析器、或使用定制分析器
分词器除了写入时转换此条,查询query时也需要用相同的分析器对查询语句进行分析
这里需要注意的是通过分词转化后把单词的首字母变为小写
Analyzer的组成
Character Fiters :针对原始文本处理,例如去除html
Tokenizer :按照规则切分单词
Token Filter :将切分的单词进行加工,转为小写,删除stopwords并增加同义词
ElasticSearch的内置分词器
# Standard Analyzer - 默认分词器,按词切分,小写处理
# 只做单词分割、并且把单词转为小写
GET /_analyze
{
"analyzer":"standard",
"text":"If you don't expect quick success, you'll get a pawn every day"
}

# Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
# 按照非字母切分例如字母与字母之间的——,非字母的都被去除例如下边的3
GET /_analyze
{
"analyzer" :"simple",
"text":"3 If you don't expect quick success, you'll get a pawn every day kaka-niuniu"
}
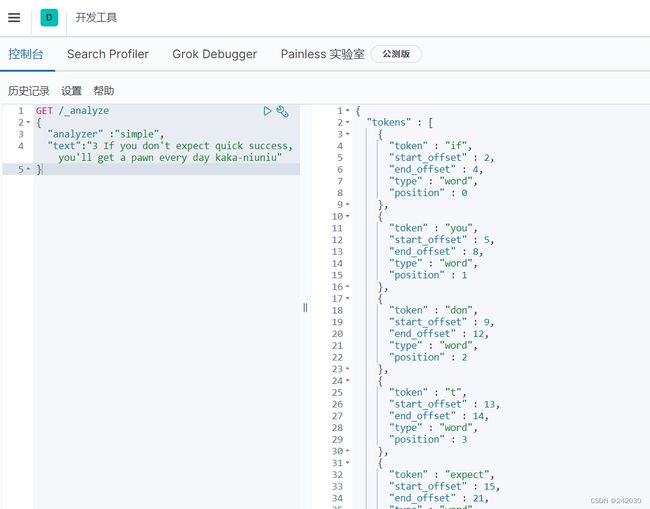
# Whitespace Analyzer - 按照空格切分,不转小写
# 仅仅是根据空格切分,再无其它
GET /_analyze
{
"analyzer":"whitespace",
"text":"3 If you don't expect quick success, you'll get a pawn every day"
}

# Stop Analyzer - 小写处理,停用词过滤(the,a, is)
# 按照非字母切分例如字母与字母之间的——,非字母的都被去除例如下边的 2
# 相比Simple Analyze,会把the,a,is等修饰性词语去除
GET /_analyze
{
"analyzer":"stop",
"text":"4 If you don't expect quick success, you'll get a pawn every day"
}
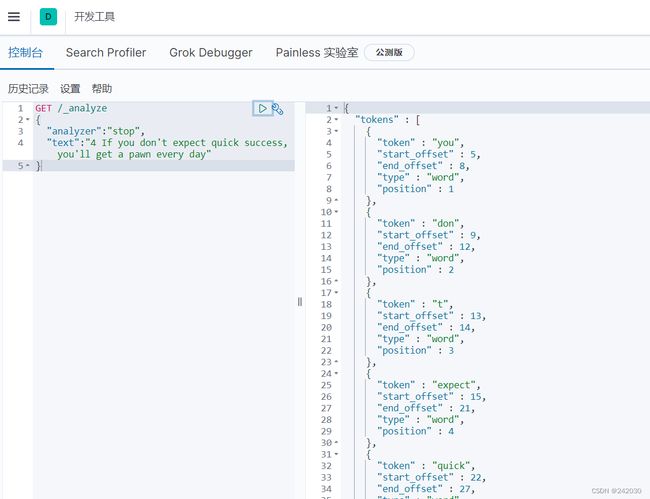
# Keyword Analyzer - 不分词,直接将输入当作输出
# 不做任何分词,直接把输入的输出,假如你不想使用任何分词时就可以使用这个
GET /_analyze
{
"analyzer":"keyword",
"text":"5 If you don't expect quick success, you'll get a pawn every day"
}

# Patter Analyzer - 正则表达式,默认\W+(非字符分隔)
# 通过正则表达式进行分词,默认是\W+,非字符的符号进行分割
GET /_analyze
{
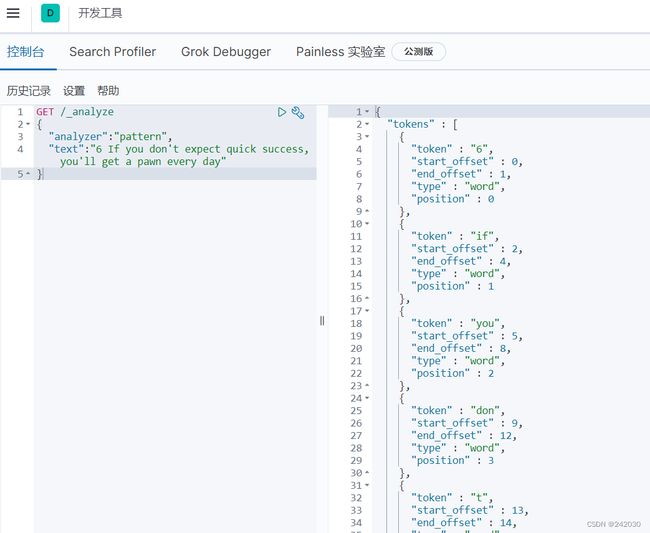
"analyzer":"pattern",
"text":"6 If you don't expect quick success, you'll get a pawn every day"
}
# Language 一提供了30多种常见语言的分词器
# 通过不同语言进行分词
# 会把复数转为单数 ,会把单词的ing去除
GET /_analyze
{
"analyzer":"english",
"text":"7 If you don't expect quick success, you'll get a pawn every day kakaing kakas"
}

# 中文分词器
# 这个需要安装分词插件
GET /_analyze
{
"analyzer":"ik_max_word",
"text":"你好,我是咔咔"
}

5、Search Api
查询语法:
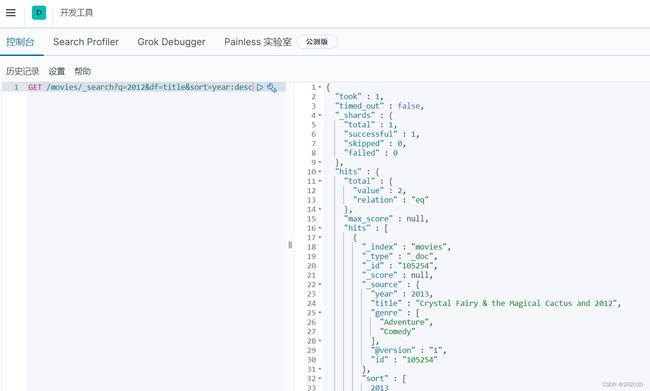
GET /movies/_search?q=2012&df=title&sort=year:desc
q:指定查询语句内容,使用Query String Syntax
df:查询字段,不指定时,会对所有字段进行查询
sort:排序、from和size用于分页
profile:可以查看查询是如果被执行的
5.1 指定字段查询、泛查询
指定字段查询就是加上df即可、泛查询什么都不加。
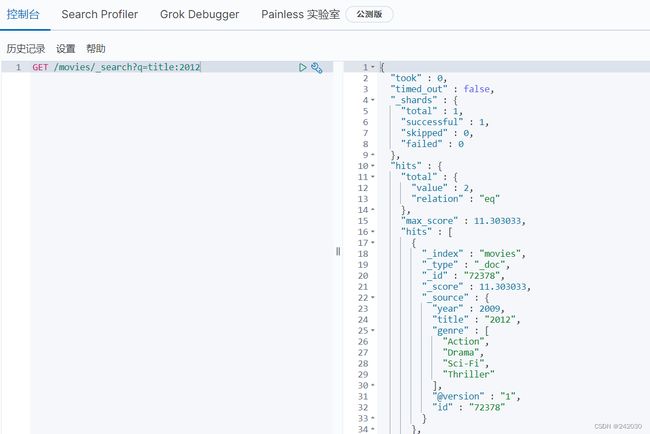
例如指定字段查询的是title中存在2012的数据
GET /movies/_search?q=title:2012
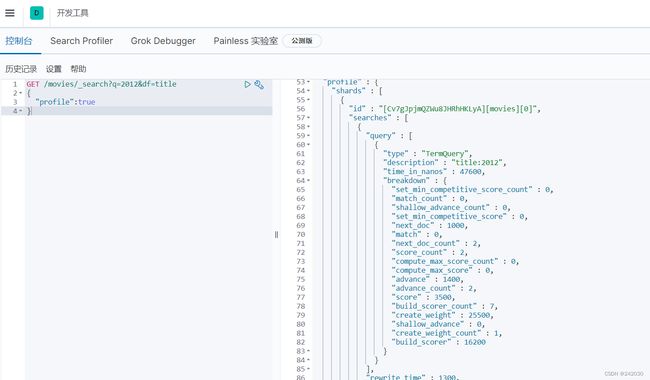
同样也可以这样来写指定字段查询
GET /movies/_search?q=2012&df=title
查看查询是如果被执行的:
GET /movies/_search?q=2012&df=title
{
"profile":true
}
5.2 分组与引号查询
若你查询值为Beautiful Mind 则等效于Beautiful OR Mind ,类似于MySQL中的or语句,意思为查询的字段
中包含 Beautiful 或者 Mind 都会被查询出来。
若你查询值为"Beautiful Mind" 则等效于Beautiful AND Mind ,类似于MySQL中的and语句,意思为查询
的字段中不仅要包含Beautiful 而且还需要包含 Mind ,跟MySQL中不同的是顺序也不能变。
注意:这里你乍一眼看过去没啥区别, 其实区别就在于有无引号
# 需要字段title中存在beautiful和mind,并且两者的顺序不能乱
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile":"true"
}

# 需要字段title中出现beautiful 或 mind 都可以
GET /movies/_search?q=title:(Beautiful Mind)
{
"profile":"true"
}
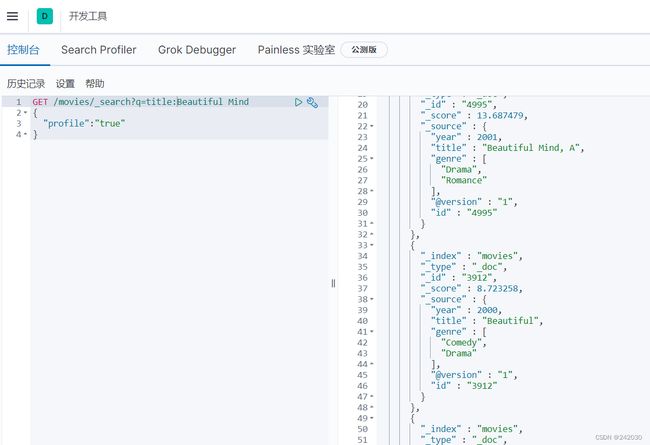
5.3 布尔操作
可以使用AND / OR / NOT 或者 && / || / ! 这里你会发现使用的都是大写,+表示must(必须存在),-表
示not mast(必须不存在)。
# title 里边必须有beautiful和mind
GET /movies/_search?q=title:(Beautiful AND Mind)
{
"profile":"true"
}

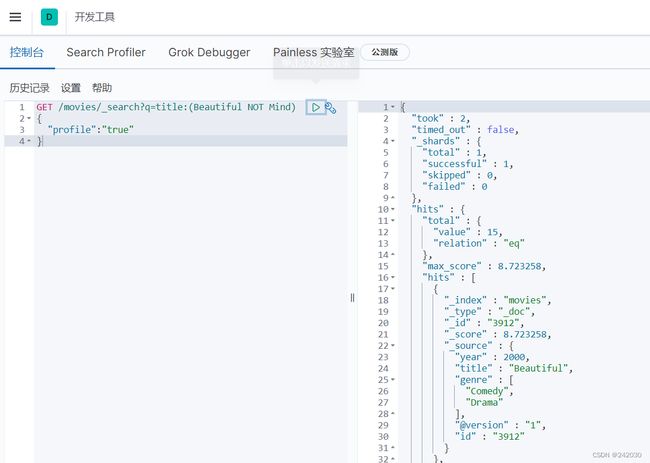
# title里边包含beautiful必须没有mind
GET /movies/_search?q=title:(Beautiful NOT Mind)
{
"profile":"true"
}
# title里包含beautiful或者mind
GET /movies/_search?q=title:(Beautiful OR Mind)
{
"profile":"true"
}

5.4 范围查询、通配符查询、模糊匹配
# year年份大于1996的电影
GET /movies/_search?q=year:>1996
{
"profile":"true"
}

# title中存在b的数据
GET /movies/_search?q=title:b*
{
"profile":"true"
}

# 对于模糊匹配还是非常有必要的,因为会存在一起用户会输错单词,我们就可以给做近似度匹配
GET /movies/_search?q=title:beautifl~1
{
"profile":"true"
}

6、Request Body Search
在日常开发过程中,最经常用的还是在Request Body中做。
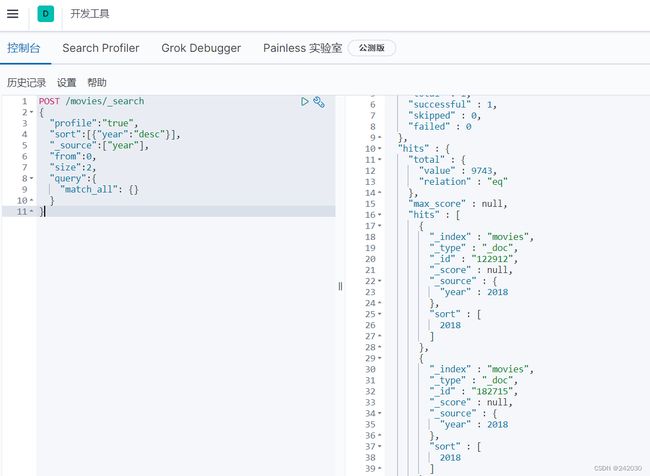
6.1 正常查询
sort :需要排序的字段
_source:查哪些字段
from:页数
size:每页数量
POST /movies/_search
{
"profile":"true",
"sort":[{"year":"desc"}],
"_source":["year"],
"from":0,
"size":2,
"query":{
"match_all": {}
}
}
6.2 脚本字段
POST /movies/_search
{
"script_fields":{
"new_field":{
"script":{
"lang":"painless",
"source":"doc['year'].value+'年'"
}
}
},
"query":{
"match_all": {}
}
}
这个案例就是把当前数据的year 拼上 “年” 组成的新字段然后返回,返回结果如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ThoWFOwK-1690463881683)(…/…/images/Elasticsearch/0263.png)]
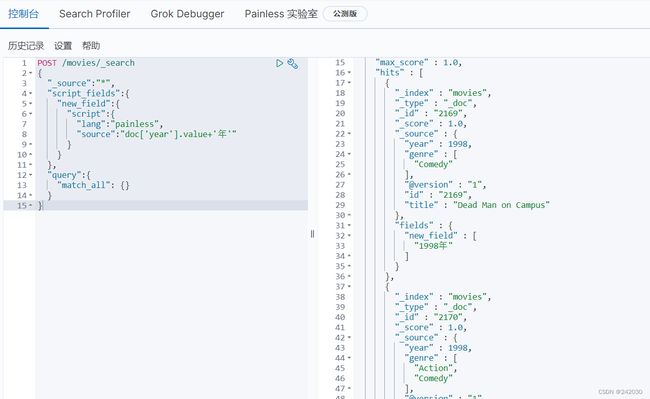
从上面的结果可以看到只返回了脚本字段,没有返回原始字段,那如何让原始字段也跟着一起返回呢?
只需要在request body中加上_source即可,当然也可以查询指定字段"_source":["id","title"]
POST /movies/_search
{
"_source":"*",
"script_fields":{
"new_field":{
"script":{
"lang":"painless",
"source":"doc['year'].value+'年'"
}
}
},
"query":{
"match_all": {}
}
}
查看返回结果
6.3 查询表达式Match
# title中包含sleepaway 或者 camp 即可
# 可以看到跟GET/movies/_search?q=title:(Beautiful Mind) 分组查询返回结果是一致的
GET /movies/_search
{
"query":{
"match":{
"title":"Sleepaway Camp"
}
},
"profile":"true"
}

# title中必须包含sleepaway 和 camp 并且顺序不能乱
# 可以看到跟GET /movies/_search?q=title:(Beautiful AND Mind)是一致的
GET /movies/_search
{
"query":{
"match":{
"title":{
"query":"Sleepaway Camp",
"operator":"AND"
}
}
},
"profile":"true"
}

# title 中查询Sleepaway 和 Camp中间可以有一个任意值插入
# GET /movies/_search?q=title:beautifl~1
GET /movies/_doc/_search
{
"query":{
"match_phrase":{
"title":{
"query":"Sleepaway Camp",
"slop":1
}
}
},
"profile":"true"
}
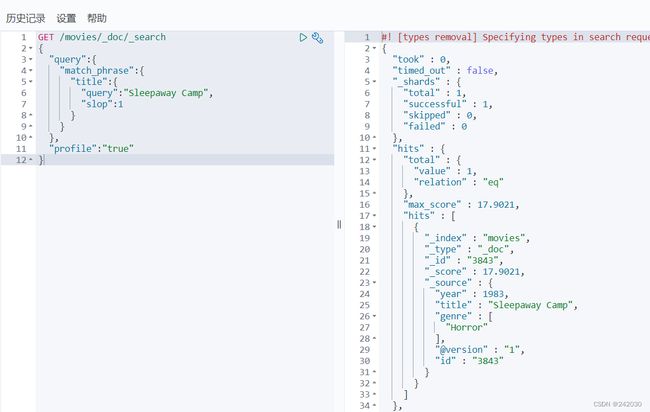
7、 Query String 和 Simple Query String
# Query String 中可以使用and跟url 的query string一样
# title 中必须存在sleepaway 和 camp 即可
# 跟url的 GET /movies/_search?q=title:(Beautiful Mind) 一致
POST /movies/_search
{
"query":{
"query_string":{
"default_field":"title",
"query":"Sleepaway AND Camp"
}
},
"profile":"true"
}

# simple_query_string 不支持and的使用,可以看到是把and当做一个词来进行查询
# title 中存在sleepaway 或 camp 即可
# "description" : "title:sleepaway title:and title:camp"
POST /movies/_search
{
"query":{
"simple_query_string": {
"query": "Sleepaway AND Camp",
"fields": ["title"]
}
},
"profile":"true"
}

# 如果想让simple_query_string 执行布尔操作,则需要给加上default_operator
# title中必须存在sleepaway 和 camp 即可
POST /movies/_search
{
"query":{
"simple_query_string": {
"query": "Sleepaway Camp",
"fields": ["title"],
"default_operator": "AND"
}
},
"profile":"true"
}

8、Mapping和常见字段类型
什么是Mapping
Mapping类似于数据库中的schema,主要包括定义索引的字段名称,定义字段的数据类型,配置倒排索引设置
什么是Dynamic Mapping
Mapping有一个属性为dynamic,其定义了如何处理新增文档中包含的新增字段,其有三个值可选默认为true
true:一旦有新增字段的文档写入,Mapping也同时被更新
false:Mapping不会被更新并且新增的字段也不会被索引,但是信息会出现在_source中
strict:文档写入失败
常见类型
| Json类型 | ElasticSearch类型 |
|---|---|
| 字符串 | 日期格式为data、浮点数为float、整数为long、设置为text并且增加keyword子字段 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象 | object |
| 数组 | 取第一个非空数值的类型所定 |
| 控制 | 忽略 |
PUT /kaka/_doc/1
{
"text":"kaka",
"int":10,
"boole_text":"false",
"boole":true,
"float_text":"1.234",
"float":1.234,
"loginData":"2005-11-24T22:20"
}

# 获取索引kaka的mapping
GET /kaka/_mapping

8.1 自定义Mapping
设置字段不被索引
设置字段不被索引使用index,只需要给字段再加一个index:false即可,同时注意一下mapping的设置格式
按照步骤走,你会得到一个这样的错误Cannot search on field [mobile] since it is not
indexed,意思就是不能搜索没有索引的字段:
PUT /kaka
{
"mappings":{
"properties":{
"firstName":{
"type":"text"
},
"lastName":{
"type":"text"
},
"mobile":{
"type":"text",
"index":false
}
}
}
}

POST /kaka/_doc/1
{
"firstName":"kaka",
"lastName":"Niu",
"mobile":"123456"
}

GET /kaka/_search
{
"query":{
"match": {
"mobile":"123456"
}
}
}

设置copy_to
设置方式如下,copy_to设置后再搜索时可以直接使用你定义的字段进行搜索:
PUT /kaka
{
"mappings":{
"properties":{
"firstName":{
"type":"text",
"copy_to":"allSearch"
},
"lastName":{
"type":"text",
"copy_to":"allSearch"
}
}
}
}
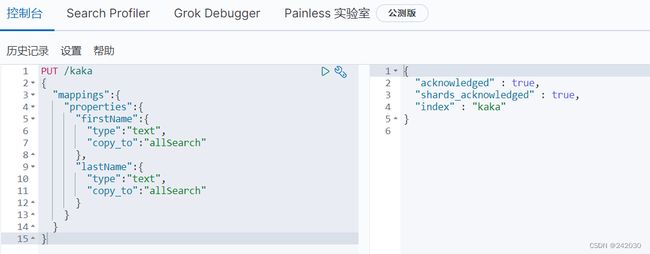
为了方便查看,这里咔咔再插入两条数据:
POST /kaka/_doc/1
{
"fitstName":"kaka",
"lastName":"niuniu"
}
POST /kaka/_doc/2
{
"fitstName":"kaka",
"lastName":"kaka niuniu"
}

进行查询,返回的只有id为2的这条数据,所以说使用copy_to后,代表着所有字段中都包含搜索的词
POST /kaka/_search
{
"query":{
"match":{
"allSearch":"kaka"
}
},
"profile":"true"
}
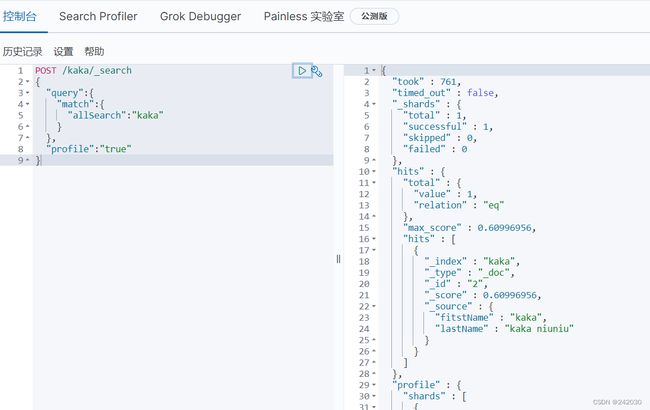
9、自定义分词器
分词器是由Character Fiters、Tokenizer、Token Filter组成的。
Character Filters 主要是对文本的替换、增加、删除,可以配置多个Character Filters ,需要注意的是设置后
会影响Tokenizer的position、offset信息。
Character Filters 自带的有 HTMl strip 去除html标签、Mapping 字符串的替换、Pattern replace 正则匹配
替换Tokenizer 处理的就是分词,内置了非常多的分词详细可以在第二期文章中查看。
Token Filters 是将Tokenizer 分词后的单词进行增加、修改、删除,例如进行转为lowercase小写字母、stop
去除修饰词、synonym近义词等。
9.1 自定义Character Filters
# Character Fiters之html的替换
# 会把text中的html标签都会去除掉
POST /_analyze
{
"tokenizer":"keyword",
"char_filter":["html_strip"],
"text":"咔咔闲谈"
}

# Character Fiters之替换值
# 会把text中的 i 替换为 kaka、hope 替换为 wish
POST /_analyze
{
"tokenizer":"keyword",
"char_filter":[
{
"type":"mapping",
"mappings":["i => kaka","hope => wish"]
}
],
"text":"I hope,if you don't expect quick success, you'll get a pawn every day."
}

# Character Fiters之正则表达式
# 使用正则表达式来获取域名信息
POST /_analyze
{
"tokenizer":"keyword",
"char_filter":[
{
"type":"pattern_replace",
"pattern":"http://(.*)",
"replacement":"$1"
}
],
"text":"http://www.kakaxiantan.com"
}

9.2 自定义Token Filters
现在用的分词器是whitespace,这个分词器是把词使用空格隔开,但是现在还想让词变小写并过滤修饰词,应
该怎么做呢?
POST /_analyze
{
"tokenizer":"whitespace",
"filter":["stop","lowercase"],
"text":"If on you don't expect quick success, you'll get a pawn every day"
}

9.3 实战自定义分词
本节开篇就知道analyze是通过Character Fiters、Tokenizer、Token Filter组成的,那么在自定义时这三个都是可
以自定义的,自定义分词必存在analyzer、tokenizer、char_filter、filter。
这部分的定义都是需要在下面定义好规则,否则无法使用:
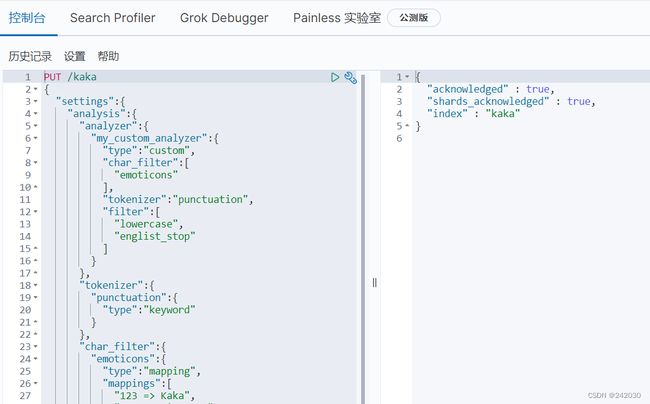
# 实战自定义analyze
PUT /kaka
{
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"char_filter":[
"emoticons"
],
"tokenizer":"punctuation",
"filter":[
"lowercase",
"englist_stop"
]
}
},
"tokenizer":{
"punctuation":{
"type":"keyword"
}
},
"char_filter":{
"emoticons":{
"type":"mapping",
"mappings":[
"123 => Kaka",
"456 => xian tan"
]
}
},
"filter":{
"englist_stop":{
"type":"stop",
"stopwords":"_english_"
}
}
}
}
}
# 执行自定义的分词
POST /kaka/_analyze
{
"analyzer":"my_custom_analyzer",
"text":" 123 456"
}

10、Index Template
在一个新索引新建并插入文档后,会使用默认的setting、mapping,如果你有设定settings、mappings会覆盖
默认的settings、mappings配置。
# 创建索引并插入文档
POST /kaka/_doc/1
{
"gongzhonghao":"123"
}

# 获取settings、mappings
GET /kaka

接下来创建一个自己的模板:
# 设置一个只要是test开头的索引都能使用的模板,在这个模板中我们将字符串中得数字也转为了long类型,而非text
PUT /_template/kaka_tmp
{
"index_patterns":["test*"],
"order":1,
"settings":{
"number_of_shards":1,
"number_of_replicas":2
},
"mappings":{
# 让时间不解析为date类型,返回是text类型
"date_detection":false,
# 让双引号下的数字解析为long类型,而非text类型
"numeric_detection":true
}
}
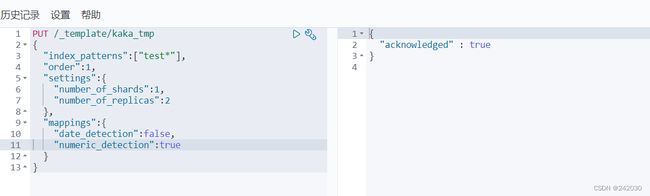
创建索引:
POST /test_kaka/_doc/1
{
"name":"123",
"date":"2022/01/13"
}

GET /test_kaka
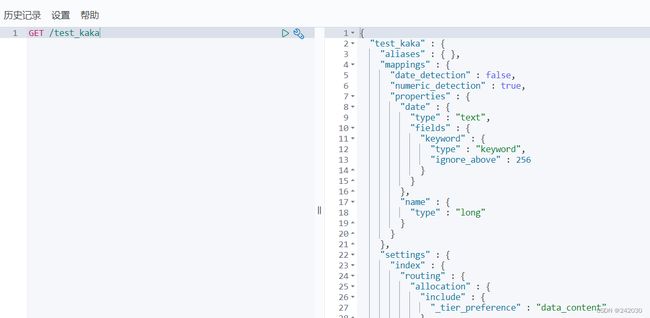
11、聚合查询
GET /test_index/_search
{
"query": {
"match": {
"address": "Lane"
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age"
}
},
"balanceAvg":{
"avg": {
"field": "age"
}
}
}
}