Golang基础
前言
这两个月看的golang的教程也不少。但是总感觉自己的基础知识不扎实。本篇为看完一本书记载的。后续会不断补充。
本篇博客不会记录太基础的知识。如果需要基础知识,教程有的是。本篇记录一下一些重要的用法和自己的理解。本篇也不会写的很深因为我golang水平并不高。只是作为一个入门笔记。
在本篇之前可以学习下基础教程:Go Tutorial - Learn Go from the Basics with Code Examples
一 初识Go
go语言是 2006年1月2号下午3点4分5秒。这个时间创立的。所以一些时间的format函数用到了这个奇葩的时间。
go语言是由Google公司开发的一款静态型(运行之前检查编译)&编译型语言。带有垃圾回收(很关键,不用我们释放)对并发支持非常牛逼的语言。因为go中 goroutines的存在允许以协程态运行任务。一个线程可以跑多个任务而不阻塞。从而高效的使用CPU计算资源来完成运转。 go的goroutines与nginx这种 epoll事件驱动属于两种多路IO的形式。 多个goroutines用通道通信。
go语言的代码可以直接输出为目标操作系统的可执行文件(windows linux...) Go不像java使用虚拟机。go只有运行时(runtime)提供垃圾回收和goroutines 调度。go有自己的链接器,不依赖操作系统。因此使用Go写的代码,编译成可执行文件。直接运行就成为一个进程了。
go 使用并发编译。所以说编译也很快的!
go弃了 i++ ++i 这个对于编程语言初学者的来说不太好理解的东西。比如java里面 a = i ++ a=++i a是两个值。
但是在go里面 i++这种东西变成了一个语句。也就是 a:=i++ 会编译报错。
写Go就像java似的,先在电脑上面搞一个SDK。
例如 Windows版的。go1.12.1.windows.amd64.msi 代表Windows 64位CPU 默认goroot是在c://go下、
二 语法&&流程控制
Go声明变量跟java不太一样。go将类型放在变量的后面。
吐槽一下 type s *[]*Hello 这玩楞你看着不懵? 这种类型写法真恶心。
也可以在函数中 a:=1这么赋值。不过 := 这个符号只能是左边变量没有全部被初始化(声明)过才可以、
var a int 声明之后变量有一个初始值。切片,函数,map,channel,struct,指针变量的初始化为nil,数字型(整,浮点)为0
go实现两个变量的换值也是非常方便,不需要再使用临时变量了。
a,b:=10,9
fmt.Println(a,b) //10 9
a,b=b,a
fmt.Println(a,b) //9 10go中有匿名变量这个操作(哑元变量) a,_ :=GetElements(); 假设这个函数返回两个值。 第二个值我们不需要。那么用_在对应位置替换,就不会分配命名空间和内存了。是一个不错的特性。
go是一个比java还强类型的语言(我认为)。go中的 int64 int32 uint32 这种被认为是三个数据类型。
[3]int []int [4]int这也被认为是三个数据类型。-_-切片和数组。任何不一样大小的数组就被认为是多个类型。
我们不用声明具体是多少位的,go会根据编译时的操作系统来给变量分配是多少位的来满足性能。
go的强制类型转换是 int(field) 这样 java是 (int) 对于整型强转换要小心位数不够导致数值不对!!
c:=10.02 -----go
fmt.Println(int(c)) //10double v = 10.02; -----java
System.out.println((int)v);Go中的字符串处理采用uint8也就是byte 和 rune也就是int32 两种。第一种是ascll码。第二种是UTF-8编码。
Unicode ASCLL都是字符集。字符集为每个字符分配一个唯一ID UTF-8是一种编码规则。比如几个字节认为是一个字(汉字)UTF-8是变长的。1-4个字节不等来编码一个字、
Go中也是有指针的。想当初我学C的时候,指针真的是听挺难理解的概念。 * &
var a int &a就获取到a变量的内存地址了。指针的值实际上就是内存地址的值 32/64平台对应位数的地址。
b:=&a b此时就可以理解为是一个指针了(内存地址) *b就是对内存地址的取值。 *&是互补的
&获取内存地址 *获取内存地址存储的值。 go中有个方法为创建对应类型的指针 new(Type)
程序的内存分配离不开栈和堆。在java中是这样。在go中依然是这样的。
对于栈来说。下面程序label处会进行栈内存分配。stack函数退出即释放内存地址。栈内存比较快,但是比较少。
func stack() (d int){
var a int //label
a = a + 1
var c int //label
d = c + b
return
}对于堆来说。可以分配大量的内存。速度较栈慢、对于堆的内存是由垃圾回收器进行回收的。
在内存分配时会出现变量逃逸这个变量分配方式。决定在内存分配时是使用栈还是堆。这是属于编译器层面的东西。
变量是否被取地址||变量是否发生逃逸是分配在堆还是栈的判断条件。
取长度的len()函数 这个字符串默认取的是ASCLL码。所以汉字的话长度就不一定是多少了。每个中文占3个字节。
i, j := len("我的妈呀"), len("asdf")
fmt.Println(i, "---", j) //12 --- 4此时len肯定不行啊,这跟我们想要的4不一样。所以我们使用其他方法来获取汉字字符串的长度。如下获取和遍历
n := utf8.RuneCountInString("这个还行asd")
fmt.Println(n) //7
str:="哈哈哈asdf"
for _,s:=range str{
fmt.Printf("%c \n",s)
}或者使用 []rune数组转一下字符串先、
i, j := len([]rune("我的妈呀")), len("asdf")对于strings.Index等方法采用的是len的计算长度方式,所以中文算3个字节。
Go中的字符串也是不可变的,跟java一样。不可变就表明线程安全无需加锁。不需要写时复制。hash值也是一份。
如下代码,我们是通过修改[]byte这个切片来修改字符串的。
a:="hello world"
b:=[]rune(a) //可以用[]rune 也可以用 []byte rune中文不会乱码
fmt.Println(string(b),"--",&b)
for i:=5;i<10;i++{
b[i] = ' '
}
fmt.Println(string(b),"--",&b)字符串中类似java中stringBuilder玩法。我们知道java中String做拼接会生成很多对象,多个+操作非常耗时、所以引入stringbuilder和stringBuffer builder只能在线程安全的环境下使用。其本身是线程不安全的。
go中也是有类似这个stringBuilder的东西来进行高效的字符串连接的。 bytes.Buffer是线程不安全的。没有锁、
var stringBuilder bytes.Buffer //声明字节缓冲
stringBuilder.WriteString("哈喽") //把字符串写入缓冲区
stringBuilder.WriteString("沃德")
fmt.Println(stringBuilder.String()) //将缓冲以字符串形式输出go的特殊常量 iota
这个常量在遇到 const 的时候就会被重置为0 然后在const的()内递增。只要遇到const就是0起始、
例如如下代码 name = 0 a= 0 b=1 c=2
const name = iota
const (
a = iota
b
c
)
在定义常量组时,如果不提供初始值,则表示将使用上行的表达式。
即下面 i = 1<<0 j = 3<<1 k = 3 <<2 j = 3<<3 左移就是扩大2倍。移位操作。所以 i = 1 j = 6 k = 12 j = 24 k使用j的表达式,l使用k的表达式。
const (
i = 1 << iota //1左移itoa
j = 3 << iota //3左移itoa
k //3左移itoa
l
)
func main() {
//i= 1 j= 6 k= 12 l= 24
fmt.Println("i=", i," j=", j," k=", k, " l=", l)
}类型别名
如下所示 带等号 = 的那个是设置的别名。在代码的时候会有感觉,但是编译后跟int就是一个东西。
type coin int //类型定义
type intAlias = int //类型别名
func main() {
var a coin
fmt.Printf("%T \n",a) //main.coin
var b intAlias
fmt.Printf("%T",b) //int
}类型定义是定义一个完全新的类型。享有原类型的方法和结构。
类型别名跟原类型是一个东西。在编译后会变成原类型。
对于使用别名的类型,不能在本地添加成员方法,因为不是一个包。
对于一些流程控制的使用
if err:=connect();err!=nil { //执行了connect函数。函数出错就输出一下日志。 控制了变量err的作用域
doSomething
}还有一个for循环非常好用的 range 可以作用于 数组,切片,字符串,map,channel 获取索引&值
arr:=[]int{1,2,3,4}
for i,v:=range arr{
fmt.Printf("index %d,val %v \n",i,v)
}对于switch 语句go语言默认每个case 都有break 如果想顺延需要加 fallthrough
goto这个东西规范都是禁止的。其他流程意义类似java
三 存储
这小节记录一下容器。java中的collection这种东西。
go有数组和切片的概念。区别就是数组的长度是固定的,切片的长度理解为动态的。
切片的底层实现是一个指向数组的指针,一个len 一个cap属性。
切片的截取采用 a[1:3] 这样。 1是开始元素下标,3是截止元素下标。左闭右开区间。 a[1:]1往后都要。
可以用make([]int, 2, 10 )创建切片 参数表示: type,len,cap 被make的切片是被直接分配内存的。
append方法是给切片追加元素,cap不够就按原cap两倍扩容。超过1024字节就按原cap的四分之一扩。
append有个坑就是,追加的元素没超过原cap不会生成新的slice切片、会在原切片操作。操作不当会造成值的覆盖
当超过原cap时进行扩充,生成新的slice 就没事了。
要想删除切片中的元素,就需要将该元素的前后切片append到一起。
map是有删除函数的 delete(map,key) go没有直接清空一个map的方法。可以新创建一个map 没用的map等垃圾回收就可以用了。垃圾回收效率也非常高。但是map是线程不安全的。不能同时进行读写操作。会抛异常。
fatal error: concurrent map read and map write
map的数据结构是哈希链表。使用链地址法。听上去跟java一样。但是实现不太一样。
go中的map有 bucket hmap等数据结构。
sync.map是支持并发读写的线程安全容器。如下store 存/改 load取 delete 删 a.delete(key)
//a:=make(map[string]int)
a:=sync.Map{}
go func() {
for{
a.Store("a",1)
}
}()
go func() {
for{
fmt.Println(a.Load("a"))
time.Sleep(time.Second)
}
}()
a.Range(func(key, value interface{}) bool { //遍历
fmt.Println("---",key,value)
return true
})
wg:=&sync.WaitGroup{}
wg.Add(1)
wg.Wait()sync.map没有直接获取长度的方法,只能自己遍历++算一下。因此性能很差。毕竟加锁,肯定相对差一点。
go中的链表。 container/list包中 类似 java中的 List
l := list.New()
element := l.PushBack("asd") //*Element
l.PushBack(11)
fmt.Println(l.Len())
l.Remove(element)
for i:=l.Front();i!=nil;i=i.Next(){
fmt.Println(i.Value)
}list不建议使用。感觉不太好。没有泛型。
四 函数
函数可以作为回调。
func connect ()error{
return errors.New("asd")
}
func main() {
var f func()error
f=connect
_ = f()
}函数可以作为值赋值给函数类型的变量。 也可以在形式参数时声明。也可以作为匿名函数存在、
Go 函数可以是一个闭包。闭包是一个函数值,它引用了函数体之外的变量。 这个函数可以对这个引用的变量进行访问和赋值;换句话说这个函数被“绑定”在这个变量上。
没有闭包的时候,函数执行完毕后就无法再更改函数中变量的值,内存被释放掉;有了闭包后函数就成为了一个变量的值,只要变量没被释放,函数就会一直处于存活并独享的状态,因此可以后期更改函数中变量的值。内存没被释放。
如下所示。label这个返回的匿名函数在main的for循环中执行多次、但是这个匿名函数中所引用的外部变量tmp3的值是有状态的。每次的调用会使变量的值+1 直到程序死掉。而非外部变量tmp2没有递增输出、
func add() func(int) int {
sum,tmp,tmp3 := 0,0,0
tmp++
fmt.Println("tmp: ",tmp)
return func(x int) int { //label
tmp2:=0
tmp2++
tmp3++
fmt.Println("tmp2: ",tmp2," tmp3: ",tmp3)
sum += x
return sum
}
}
func main() {
//tmp: 1
//tmp2: 1 tmp3: 1
//tmp2: 1 tmp3: 2
//tmp2: 1 tmp3: 3
//13
res := add() //res是返回的匿名函数
for i := 1; i < 3; i++ {
res(i)
}
fmt.Println(res(10))
}go中还有类型推断的断言
m:=make(map[string]interface{})
m["a"]=1
for _,v:=range m{
switch v.(type){ //注意此处的v必须是interface{} 相当于object
case bool:
fmt.Println("bool") //一般类型断言与switch一起用。
case int:
fmt.Println("int")
default:
fmt.Println("none")
}
}defer
defer类似java中的finally 只不过写的随意一点,写哪都行。defer有一个调用栈。对于多个defer调用的函数按编码顺序入栈,所以执行的时候就是逆序执行了。因为栈的后进先出特性。
error
一个可能造成错误的函数,需要返回值中返回一个错误接口,如果调用是成功的,错误接口将返回nil 否则返回错误、
这个是一个非常好的函数设计理念。
通过errors.New("")返回一个error。 但是在一些时候我们需要自定义error-----重写Error方法就行了。
对于panic 和 recover 的玩法。
程序不行的时候触发panic 如果没在defer中发现recover函数就会宕机。
如果在触发panic的函数中的defer中(无论回调还是什么,只要在一个函数中) 使用了recover函数 就不会宕机,继续执行defer的内容,执行完毕后,退出宕机点的函数,继续执行。
五 结构体
结构体是一个比类更有扩展的东西。
使用new & 构造的类型实例的类型是类型的指针。
new就不作示范了。源码返回的就是 *Type 下面这个用&构造的结构体实例是指针类型、
type hellos struct {
name,describe string
}
func main() {
h:=&hellos{describe:"hello"}
(*h).name="asd" //等价于 h.name 语法糖可以省略额外部分
fmt.Println(h,reflect.TypeOf(h)) //&{asd hello} *main.hellos
}当结构体实例化时才会被分配内存。除了上面的方式外还有一种初始化方式,按顺序写变量。不建议用这种,不清晰。
对于go的继承玩法,就只能写成结构体嵌套。
在java中我们给类写实例方法和静态方法。 在go中有接收器这一个概念。相当于this 接收器分为值接收和指针接收。
官方建议将接收器的变量命名为类型的第一个小写字母。 (p *Pointer)
指针接收器和值接收器的区别如下
指针接收器的成员变量在方法中的修改,在方法结束后依然有效。
而值接收器在方法中对成员变量的修改在方法外不可见。
在最开始我认为值接收器就是对值的复制从而存在两个变量两个内存地址,原值没法感受到改变,指针则是把内存地址给共享了,然后改了就能看见。直到我做了一个测试发现不是这样的。
type hello struct {
name,describe string
}
func (h hello) setName(name string) {
fmt.Println("hello.setName: ",unsafe.Pointer(&h))//hello.setName: 0xc000048460
h.name = name
}
func (h *hello) setDes(des string) {
fmt.Println("hello.setDes: ",unsafe.Pointer(&h))//hello.setDes: 0xc00007e020
h.describe = des
}
func main() {
h:=&hello{name:"default"}
fmt.Println(reflect.TypeOf(h)) //*main.hello
fmt.Println("main.h: ",unsafe.Pointer(h))//main.h: 0xc000048420
h.setName("newName")
h.setDes("newDes")
fmt.Printf("h.name: %s,h.describe: %s",h.name,h.describe)//h.name: default,h.describe: newDes
}对于值接收器就是值被复制一份。如果值很大,那么会造成很大的内存开销。对于指针接收器则是指针被复制一份。传给方法一个指针这个指针存储的是原数据的指针。并不是直接像java那样直接的共享内存地址。
接收器和参数传递的区别就是接收器方法属于某个结构体!
public class GoTest {
public static void hello(GoTest goTest){
System.out.println(goTest);//zy.service.effective.eight.GoTest@3f99bd52
}
public static void main(String[] args) {
GoTest goTest = new GoTest();
System.out.println(goTest);//zy.service.effective.eight.GoTest@3f99bd52
hello(goTest);
}
}不光结构体可以有他的方法。类型也可以。
type str string
func(s str)say(){
fmt.Println("say")
}
func main() {
var s str = "sss"
s.say()
}结构体可以类型内嵌和结构体内嵌。就是不写变量名。及其恶心。不明白这么定义语法的意义在哪、乱七八糟的。一点也不清晰。强烈建议不要这么写。
六 接口
又可以吐槽了。go中的接口满足两个条件就算。
1.一个结构体的函数名返回值参数与接口中定义的一样
2.接口中所有定义的函数,在结构体中都有对应的函数。
满足上述这两条就算结构体实现了这个接口。可以看到没有像java这样implements 关键字说明实现关系、
那么问题来了。写了很多代码之后。鬼知道你实现啥接口了????????
接口也可以嵌套。结果你懂的。就是全都得实现,更难看。
接口的玩法跟java差不多。都是表示行为用的。
七 包
这个跟java类似。就是main方法必须main包才能run起来package main
关于gopath和go modules包管理总结在这。Golang 从gopath到 go modules_finalheart的博客-CSDN博客_gopath
照目前趋势用go modules就可以了。gopath缺点太多了。
别的没啥说的,这个init函数需要注意一下。
init函数一个go文件中可以写多个,但是写多个没有任何意义,不要这样干。嵌套引用的package init函数由最内层的开始被调用。下面写了一个小demo 一目了然。
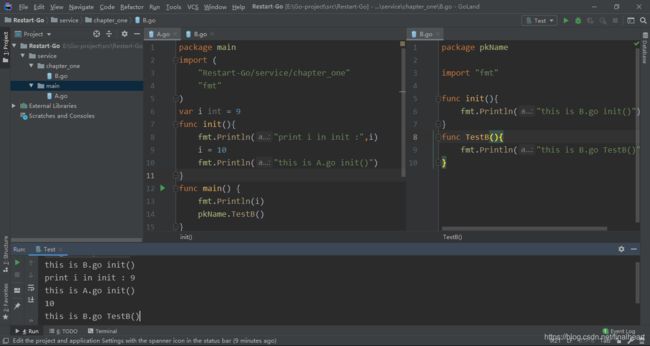
1.可以看到import包的时候写的是真实的mkdir的目录名,而main函数中我引入时使用的是pkName这个我自定义的包名。
2.init先加载引入的包也就是B.go 而且init是自动调用的。
3.我设定了 i 这个变量,目的是让你明白init函数是执行在全局变量赋值初始化之后的。因为输出的是9而不是0
八 并发 GoRoutines
这个是学go语言必须掌握和懂的。因为学go就是为了用这玩楞。
应知应会
学计算机肯定知道进程是内存分配的单元。线程是操作系统(cpu)调度的最小单元。因为线程共享进程中的内存所以存在一系列并发资源竞争问题。go中提出了一个用户态协程的概念goroutines 这个是go语言层面支持的,不需要在用代码处理了。
进程之间通信通过中间件、socket等等。线程之间通信通过共享内存。而这个routines之间通信建议通过channel通道、因为也是可以通过共享内存的,但是这样就很low。
关于goroutines 它不是线程级别的。多个goroutines跑在一个线程里面,通过一个CPU调度。因为存在一个处理器来记录每个goroutines的执行位置。发生阻塞会向处理器发送状态,然后处理器切换别的goroutines运行。当然如果没阻塞也会进行goroutines的切换(抢占式)。从而挖掘单核CPU的计算能力。高并发环境比线程切换快超级多。
go func 就可以了。异步跑一个你想干的活。
runtime.GOMAXPROCS(runtime.NumCPU()) //获取机器的CPU数量,设置进去。默认就是这个设置。goroutines这个是处理并发的,不是并行。并行是指在一个时刻开始多个任务。并发是指在一个时间间隔开启多个相同处理任务。就比如http包的 l.accept()
goroutines与其他语言的coroutine的区别
最主要区别:goroutines是抢占式的。而c#、lua、Python中使用的coroutine是由本身决定的,yield从而交出CPU占用权。
channel
通道是一种线程安全的工具,一个时刻只能一个goroutines写和消费。先进先出,像队列。
通道一般是多个goroutines协调任务通信用的。channel是可以带缓冲的 make(chan int,10)10个缓冲,只有写第11个才会阻塞。
有定时器和延迟器这两个玩意。
ticker:=time.NewTicker(time.Second) //每到时间间隔就执行
timer:=time.NewTimer(time.Second) //延迟执行
for{
select {
case <-ticker.C:
fmt.Println("touch ticker")
case <-timer.C:
fmt.Println("timer stop")
}
}同步
编程离不开同步,goroutines也离不开,因为不确定goroutines跑在哪几个线程里面。如果跑在一个线程里面肯定没问题,但是跑在多个线程里面就会发生竞争。线程不安全。
与java里面的Atomic类一样go里面也有atomic.
import "sync/atomic"
var a int64
func main() {
//AddInt64 atomically adds delta to *addr and returns the new value.
//func AddInt64(addr *int64, delta int64) (new int64)
atomic.AddInt64(&a,1) //可以直接return 线程安全。
}在go里面还可以使用互斥锁sync.Mutex,类似java里面的synchronized 为了多任务执行完再往下走。go推出了一个叫做sync.WaitGroup等待组的东西。就是java里面的CountDownLatch
var (
a int
lock sync.Mutex //互斥锁
)
func add(wg *sync.WaitGroup){
lock.Lock()
defer lock.Unlock()
a++ //线程不安全。加锁后安全。
wg.Done()
}
func main() {
wg:= sync.WaitGroup{}
for i:=0;i<1000;i++{
wg.Add(1)
go add(&wg)
}
wg.Wait()
fmt.Println(a)
}读写锁类似
var (
rwLock sync.RWMutex
x int
)
func get()int{
rwLock.RLock()
defer rwLock.RUnlock()
return x
}
func addX(wg *sync.WaitGroup){
rwLock.Lock()
defer rwLock.Unlock()
x++
wg.Done()
}
func main() {
wg:= sync.WaitGroup{}
for i:=0;i<1000;i++{
wg.Add(1)
go addX(&wg)
}
wg.Wait()
fmt.Println(x)
}
九 反射
首先理解Type与Kind Kind相当于一个大分类。
type NewInt int
type M struct {
}
func main() {
m:= M{}
t:=reflect.TypeOf(m)
fmt.Println(t.Kind(),"---",t.Name()) //struct --- M
var n NewInt = 10
nType := reflect.TypeOf(n)
fmt.Println(nType.Kind(),"---",nType.Name()) //int --- NewInt
m1:=&M{}
t2:=reflect.TypeOf(m1)
fmt.Println(t2.Kind(),"---",t2.Name()) //ptr ---
t2=t2.Elem() //指针类型需要Elem来获取
fmt.Println(t2.Kind(),"---",t2.Name()) //struct --- M
}其中有一个tag的概念,这个在做json、bson等转格式的时候其实也用到了。
type M struct {
Name string `json:"names"`
desc string
}
func main() {
m:= M{}
t:=reflect.TypeOf(m)
field, _ := t.FieldByName("Name")
str := field.Tag.Get("json")
fmt.Println(str) //names
}还有一些反射的用法就不作探究了。平时编程的时候用的比较少。
十 Go 的命令
下面的测试中,我的gopath是E:\Go-project
go build
1.go build会在当前文件夹将指定文件编译成可执行文件。 go build hello.go ./hello
2.也可以把多个文件编译在一个EXE中。go build a.go service.go 以第一个文件名作为EXE的名称。
需要注意的是go build 编译的go文件只能有一个有main 函数。
3.go build -o reName.exe a.go service.go 这样使用-o 参数就编译出了一个自定义名称的可执行文件。
4.go build 编译一个包的话必须这个包在gopath的src下面,否则报如下错。
can't load package: package go-tools: cannot find package "go-tools" in any of:
C:\Go\src\go-tools (from $GOROOT)
E:\Go-project\src\go-tools (from $GOPATH)
5.编译包 需要写从src下面一直到有go文件的目录。哪怕目录里面没有main函数也不会报错就是不好用而已。可以看到下图中我在Restart-Go下,并不是直接的src下。但是写目录的时候一定要写相对src的路径。(B.go没有main但是可以编译,不好用)
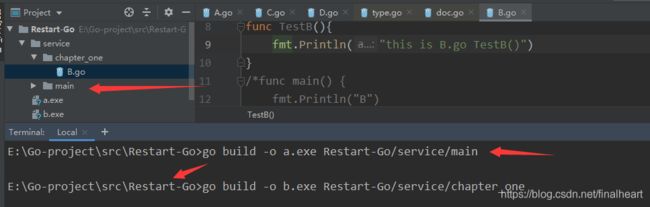
go build 会根据GO111MODULE 环境变量值的不同而不一样, 为on时是开启了go modules 这样gopath的目录不会被编译打包。
GO111MODULE 为auto时就可以打包到go mod gopath的文件。
go build 交叉编译
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build main.go
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build main.go
go run (编译后运行)
1.go run x.go 这个x.go里面必须得有main函数。否则如下
# command-line-arguments
runtime.main_main·f: function main is undeclared in the main package
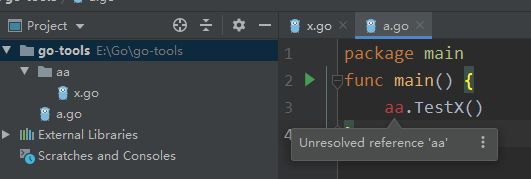
2.go run不会在运行目录生成可执行文件,会在一个临时目录生成。 go run a.go --a dd 后面是参数。
3.需要注意的是如果不在gopath下。是不能被引用到的。如下图。哪怕这看起来是上级的文件,但是引用不了。除非你在gopath下通过src的相对路径import 然后使用 package名称命名来引用方法就可以了。
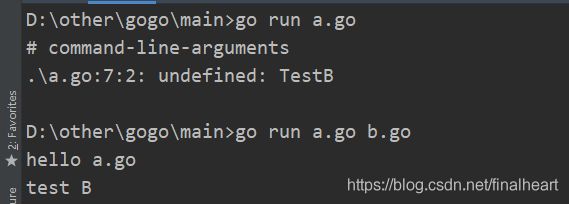
4.go run 是跟gopath关系不大的。但是同一包得指定引用的其他文件。如下图所示。

go install(编译并安装)
1.go install也是与gopath紧密相关的。紧密到只能在gopath下的相对src的目录可以进行安装。
2.安装gopath下的目录(Restart-Go在gopath/src下) go install Restart-Go/service/main
会固定在gopath/bin下创建刚才install编译的可执行文件(也可能是在某处创建然后挪到bin下,不探究这个)

3.执行 go install 前提是package main不能有main包才会在 pkg 目录生成一个 .a文件、 下面报错是main包没有main函数。但是想编译到pkg目录下的东西是提供给别的程序用的。不需要main函数。(个人是这么理解的) 所以包不能声明为main包。

go get
这个可以说是第二常用的命令了。用这个本地得有git/svn当然我有git 像SVN这种比较旧的我就刚开始学编程时用过。
go get github.com/golang/go 这样就下载到gopath下面了。 一般加 -v 参数。别的参数我感觉一般情况没啥用。
go get -v github.com/golang/go 如下图

go test
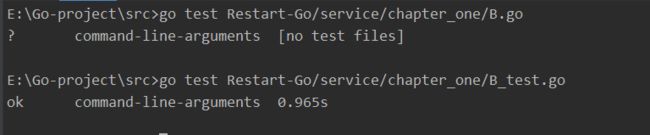
1.单元测试。有一个要求是必须以 _test为go文件的结尾才能使用测试。如果不加 _test会报错。
2. 测试用例需要以Test为开始 并且是下面这个参数、
func TestHelloB(t *testing.T) {
t.Logf("hello")
}3.go test 时的一些参数 go test -v B_test.go 输出详情。 -run TestHelloB($) 可以正则的指定运行用例。
4.go test 时引用其他包里面的文件需要把那个文件也写在go test命令中 就像build一样。
go test a_test.go b.go c.go
5.go test还可以做性能测试。测试函数需要以Benchmark开头。如下
func BenchmarkTestB(b *testing.B) {
var n int
for i:=0;i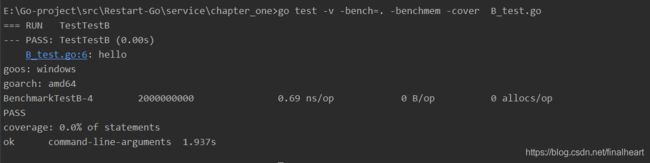
-bench=. 就相当于普通测试的那个 -run -cover是覆盖率。 -benchmem是内存信息、
0B/op是每次调用分配的字节数 0 allocs/op 是每一次调用有0次分配。
十一 Others
1.首先明确channel的性能并不比锁sync.Mutex 及sync.WaitGroup这种好、使用channel传输数据使goroutines之间通信才是最好的使用方式。
2.反射是动态的特性,但是性能并不是太好。当然以我目前的水平还用不好反射这个特性。
3.接口的nil值是需要 value和type都为nil才可以的。
type Impl struct {
}
func (i Impl)String()string{
return "asd"
}
func Get()fmt.Stringer{
var i *Impl = nil
return i //return nil
}
func main() {
s:= Get()
var i *Impl = nil
if i == nil {
fmt.Println("i nil") //i nil
}
if s == nil {
fmt.Println("nil")
}else {
fmt.Println("not nil") //not nil
}
}上面这个demo中 Get方法返回的是一个指针,不是nil 在与nil比较时就不相等了。如果想改就改成return nil。
4.go里面的map要使用非动态类型数组(不要用切片) 非指针,非函数非闭包作为key 因为key哈希得一样,不能是动态的。
5.对于结构体里面可以声明像 sync.Mutex waitGroup这种东西,然后使用接收器方法来用这些东西同步结构体变量。
推荐的一个博客:Go 语言设计与实现 | Go 语言设计与实现 可以作为进阶学习资源。