内核源码获取:https://www.kernel.org
Linux内核版本号由3组数字组成:第一个组数字.第二组数字.第三组数字
- 第一个组数字:目前发布的内核主版本。
- 第二个组数字:偶数表示稳定版本;奇数表示开发中版本。
- 第三个组数字:错误修补的次数。
软件包管理器:
- RPM(Red Hat Package Manager)
- DPKG (Debian Package)
1.配置与编译内核
内核源码目录:/usr/src/linux
配置方式:
- make config : 为每一个内核支持的特性向用户提问。(Ctrl+c 强行退出配置)
- “y”——把该特性编译进内核
- “m”——该特性作为模块编译
- “n”——不对该特性提供支持
- make oldconfig : 与make config类似,作用是在现有内核设置文件基础上建立一个新的设置文件,只会向用户提问有关新内核特性的问题。
在内核升级过程中,make oldconfig非常有用。用户可以将现有内核的设置文件.config复制到新内核的源码目录中,执行make oldconfig,此时,用户只需要回答那些针对新增特性的问题
- make menuconfig : 基于终端的一种配置方式,提供了文本模式的图形用户界面
- make xconfig : x windows配置方式
- make gconfig
- make defconfig : 按照默认的配置文件arch/i386/defconfig对内核进行配置,生成的.config可以用作初始配置,然后再使用make menuconfig进行定制化配置。
- make allyesconfig : 尽可能多的使用“y”设置内核选项值,生成的配置中包括了全部的内核特性
- make allmodconfig : 尽可能多地使用“m”设置内核选项值来生成配置文件。
.config 文件:.config文件位于内核源码树的顶层目录。修改配置:
- 找一个旧的.config文件作参考。
- 修改.config文件
- 备份、重用.config文件
配置选项
- 裁剪内核:去掉不需要的特性以及将部分特性编译为可加载的模块
- 深入研究子系统:从该子系统所涵盖的配置选项入手(代码目录下的Kconfig文件入手),掌握它的各部分实现代码之间的分布关系,避重就轻地进行代码分析
1.1 系统中与编译相关的目录及文件
- /boot/vmlinuz-
: 用于启动的压缩内核镜像 - /boot/system.map-
: 存储内核符号表 - /boot/initrd.img-
: 镜像文件,将驱动程序和命令工具打包,在开机的时候在内存开辟一段区域,释放到那里运行。 - /boot/grub/menu.lst : GRUB配置文件
- /lib/modules/ : 包含内核模块及其他人间
- /lib/modules/
/build/ : 存放编译新模块所需的文件 - /lib/modules/
/kernel/ : 存放模块的ko文件 - /lib/modules/
/modules.alias : 模块别名定义 - /lib/modules/
/modules.dep : 定义了模块间的依赖关系 - /lib/modeles/
/modules.symbols : 标识符号属于哪个模块
构建编译环境
- modutils : 模块工具
- kernel-package : 包括了make-kpkg等工具
- patch : 内核打补丁
- build-essential : 提供gcc、make等工具
1.2 内核打补丁
- 补丁定义:是一个文本文档,由diff工具创建,存放了两个不同版本源代码之间的差异
- linux 内核有两种补丁:
- 1、增量型补丁 :表示这个补丁是在前一补丁版上生成的,例如 patch-2.4.9 是在 2.4.8 内核的基础上生成的。
- 2、差分型补丁:表示这个补丁是对上一个 base version 的基础上生成的,例如 2.6.20.6 是在 2.6.20 的基础上生成的,而不是在 2.6.20.5 基础杀功能生成的。
- 常用的 patch 模式
- a)从 2.x.y → 2.x.y+1 : 直接升级
- b)从 2.x.y.z → 2.x.y+1 :先用 patch -R 退回到 2.x.y 再升级到 2.x.y+1
- c)从 2.x.y → 2.x.y+1.z :先升级到 2.x.y+1 ,再直接升级到 2.x.y+1.z
- d)从 2.x.y.z → 2.x.y.z+1 :先用 patch -R 退回到 2.x.y 再升级到 2.x.y.z+1
.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
.tar.bz2
解压:tar jxvf FileName.tar.bz2 或tar --bzip xvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
内核打补丁实例:
从2.6.10升级到2.6.12.6,需要下载 linux-2.6.10 , patch-2.6.11,patch-2.6.12,patch-2.6.12.6
[root@mail linux-2.6.10]# pwd
/usr/src/kernels/linux-2.6.10
[root@mail linux-2.6.10]# ll -h patch*
-rw-r--r-- 1 root root 22M Sep 27 22:31 patch-2.6.11
-rw-r--r-- 1 root root 24M Sep 27 22:31 patch-2.6.12
-rw-r--r-- 1 root root 50K Sep 27 22:31 patch-2.6.12.6
[root@mail linux-2.6.10]#
[root@mail linux-2.6.10]# head -n5 Makefile
VERSION = 2
PATCHLEVEL = 6
SUBLEVEL = 10
EXTRAVERSION =
NAME=Woozy Numbat
[root@mail linux-2.6.10]#
[root@mail linux-2.6.10]# head -3 patch-2.6.11
diff -Nru a/CREDITS b/CREDITS
--- a/CREDITS 2005-03-01 23:39:08 -08:00
+++ b/CREDITS 2005-03-01 23:39:08 -08:00
[root@mail linux-2.6.10]# patch -s -p1 < patch-2.6.11
[root@mail linux-2.6.10]#
[root@mail linux-2.6.10]# head -n5 Makefile
VERSION = 2
PATCHLEVEL = 6
SUBLEVEL = 11
EXTRAVERSION =
NAME=Woozy Numbat
[root@mail linux-2.6.10]#
[root@mail linux-2.6.10]# patch -s -p1 < patch-2.6.12
[root@mail linux-2.6.10]#
[root@mail linux-2.6.10]# head -5 Makefile
VERSION = 2
PATCHLEVEL = 6
SUBLEVEL = 12
EXTRAVERSION =
NAME=Woozy Numbat
[root@mail linux-2.6.10]#
[root@mail linux-2.6.10]# patch -s -p1 < patch-2.6.12.6
[root@mail linux-2.6.10]#
[root@mail linux-2.6.10]# head -n5 Makefile
VERSION = 2
PATCHLEVEL = 6
SUBLEVEL = 12
EXTRAVERSION = .6
NAME=Woozy Numbat
[root@mail linux-2.6.10]#
[root@mail kernels]# mv linux-2.6.10 linux-2.6.12.6
[root@mail kernels]# ll -d linux-2.6.12.6
drwxrwxr-x 18 bob bob 4096 Sep 27 22:31 linux-2.6.12.6
[root@mail kernels]#
内核编译
(1)下载源码解压
(2)配置内核
make menuconfig(3)编译内核
make(4)安装内核模块,将内核模块复制到/lib/modules/
make modules_install(5)安装内核,主要完成了3个工作:a)复制生成的内核映像到/boot目录 b)生成initrd-
make install(6)重启进入新内核
1.3 自由软件的编译与安装
自由软件以源代码文件压缩包的形式发布,用户必须自己编译源代码才能使用。
自由软件组织结构:
- INSTALL:描述安装步骤
- README文件:有关软件的一般信息
- COPYING(LICENSE):许可证
- CONTRIB/CREDITS:相关人员列表
- CHANGES:最近修改以及故障修正
- Makefile:编译
- configure/Imakefile:针对特殊系统自定义生成新的Makefile
- src : 保存源文件以及二进制文件
- 配置文件、数据示例文件或资源文件
安装前配置:
1. AutoConf
目录中存在一个名为configure的文件,执行./configure ,创建编译需要的文件(Makefile),直接对源代码进行修改,规则如下:
- 作者了解配置软件需要进行哪些测试(如:你使用哪一版的库文件),他使用一种精确的语法将这些测试编写进configure.in文件
- 运行AutoConf从configure.in文件生成configure自动配置脚本,该脚本将在配置软件的时候运行所需的测试
- 最终用户执行该脚本,这样AutoConf就会为编译进行配置
如果配置出错,一般来说都是找不到某个库文件,可以采取以下措施:
- 在config.log中找到配置过程的每一步骤,从而找到错误原因
- 检查提示的库文件是否安装 find / -name "libguile"
- 检查编译器是否能够访问该库文件
- 检查库文件相应的头文件是否已安装于正确地方
- 检查磁盘空间是否足够
- 检查环境变量是否设置正确
2. imake
目录中存在一个名为Imakefile的文件,使用imake配置
3. shell脚本
执行 make install 完成安装
2 浏览内核源代码
内核源码目录结构:
- Documentation 文档
- arch 体系相关代码
- drivers 驱动程序
- fs 虚拟文件系统
- include 头文件
- init 初始化代码
- ipc 进程间通信
- kernel 内核中最核心的部分:进程调度,创建,撤销
- lib 库
- mm 内存管理
- net 网络相关代码
- scripts 配置内核脚本文件
- block
- crypto 加密和散列算法
- security 不同的Linux安全模型的代码
- sound 声卡驱动
- usr 实现用于打包和压缩的cpio等
代码浏览工具:
- Windows Source Insight
- Linux Vim + Cscope
GCC扩展:GCC提供了很多C语言扩展,内核所使用的C语法并不完全符合ANSI C标准
- 语句表达式:GCC把包含在括号中的符合语句看做是一个表达式,称为语句表达式,它允许在一个表达式内使用循环、跳转、局部变量,并可以出现在任何允许表达式出现的地方
- 零长度数组:可变长数组,并不占用结构的空间,但它意味着这个结构的长度充满了变数
- 可变参数宏
- 标号元素:通过执行索引或结构域名,允许初始化值以任意顺序出现。
const struct file_operations ext2_file_operetions = { .llseek = generic_file_llseek, .read = do_sync_read, ... }; - 特殊属性(_attribute_):GCC允许声明函数、变量和类型的特殊属性,以便指示编译器进行特定方面的优化和更仔细的代码检查。
- noreturn:用于函数,表示该函数从不返回
- format(archrtype, string-index, first-to-check):用于函数,表示该函数使用printf、scanf、strftime或strfmon风格的参数,并可以让编译器检查函数声明和函数实际调用参数之间的格式化字符串是否匹配
- unused : 函数或变量可能并不适用
- section("section-name") : 让编译器将函数或变量放在指定的节中。
- aligned(ALIGNMENT): 设定一个指定大小的对齐格式,以字节为单位
- packed : 最小可能对齐
- 内建函数
- _builtion_except (long exp, long c):分支预测,优化程序
++++ include/linux/compiler.h #define likely(x) _bulitin_expect(!!(x),1) #define unlikely(x) _bulitin_expect(!!(x),0)
- _builtion_except (long exp, long c):分支预测,优化程序
内嵌汇编
- 与硬件打交道
- 频繁被调用的地方,提高时间效率
- 空间效率、
- 介于汇编和C之间的一种中间语言
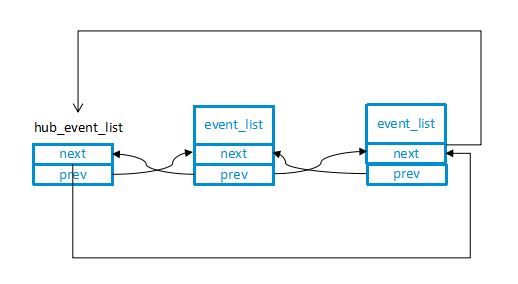
内核中的链表:内核链表实现位于include/linux/list.h
struct list_head{
struct list_head *next,*prev;
}内核中链表没有数据域,不是在链表结构中包含数据,而是在描述数据类型的结构中包含链表。
- 声明和初始化
// List_HEAD宏在编译时静态初始化 #define LIST_HESF_INIT(name) {&(name),&(name)} #define LIST_HEAD(name)\ struct list_head name =LIST_HEAD_INIT(name) //运行时初始化 static inline void INIT_LIST_HEAD(struct list_head *list) { list->net = list; list->prev = list; }无论使用哪一个,新生成的链表头都初始化为指向自己。
-
判断链表是否为空
static inline int list_empty(const struct list_head *head) { return head->next == herad; } -
插入
static inline void list_add(struct list_head *new,struct list_hrad *head) { _list_add(new,head,head->next); } static inline void list_add_tail(struct list_head *new,struct list_hrad *head) { _list_add(new,hrad->prev,head); }listadd()将数据插入到head之后,list_add_tail()将数据插入到head->prev之后。对于循环链表来说,表头的next、prev分别指向链表中的第一个和最后一个节点,所以list_add()和list_add_tail()的区别不大。
-
删除
static inline void list_replace_init(struct list_head *old, struct list_head *new) { list_replace(old,new); INIT_LIST_HEAD(old); } -
遍历
#define list_entry(ptr, type, member) container_of(ptr, type, member)
Kconfig和Makefile
Kconfig结构
- 菜单项: config可以定义一个菜单项
config MODVERSIONS bool "Set version information on all module symbols" depends on MODULES help Usually,modules have to be recompiled whenever you switch to a new后面几行定义了该菜单项的属性,包括类型、依赖关系、选择提示、帮助信息和缺省值等。类型包括bool、tristate、string、hex和int。bool类型的只能选中或不选择,tristate类型的菜单项多了编译成内核模块的选项。
-
菜单组织结构
-
使用关键字”menu“显式声明为菜单
menu "BUS ..." ... endmenu -
通过以来关系确定菜单结构
config MODULES bool "Enable loadable module support" config MODVESIONS bool "Set version information on all module symbols" depends on MODULES comment ”module support disabled“ depends on !MUDULES
-
-
Kconfig文件描述可一系列的菜单选项,除帮助信息外,文件中的每一行都以一个关键字开始,主要有config、menuconfig、choice/endchoice、comments、menu/endmenu、if/endif、source等。
代码分析示例
- README文件描述了各个子目录的作用
- subsys_initcall指定初始化函数,可以理解为module_init,只不过因为该部分代码比较核心,开发者们把它看做一个系统,而不仅仅是一个模块。
- _init标记:_init修饰的所有代码都会被放在.init.text节,初始化结束后就可以释放这部分内存。那么内核是如何调用到_init所修饰的这些初始化函数的?
#define subsys_initcall(fn) _define_initcall("4",fn,4)出现了一个新的宏_define_initcall,它用来将指定的函数指针fn存放到.initcall.init节,对于subsys_initcall宏,则表示把fn存放到.initcall.init的字节.initcall4.init。
-
内核可执行文件由许多链接在一起的对象文件组成。对象文件有许多节,如文本、数据、init数据、bass等。这些对象文件都是由一个称为链接器脚本的文件链接并装入的。这个链接器脚本的功能是将输入对象文件的各节映射到输出文件中。换句话说,它将所有输入对象文件都链接到单一的可执行文件中,将该可执行文件的各节装入指定地址处。
.initcall.init : AT(ADDR(.initcall.init) - 0xC0000000) { __initcall_start = .; *(.initcall0.init) *(.initcall0s.init) *(.initcall1.init) *(.initcall1s.init) *(.initcall2.init) *(.initcall2s.init) *(.initcall3.init) *(.initcall3s.init) *(.initcall4.init) *(.initcall4s.init) *(.initcall5.init) *(.initcall5s.init) *(.initcallrootfs.init) *(.initcall6.init) *(.initcall6s.init) *(.initcall7.init) *(.initcall7s.init) __initcall_end = .; }
模块参数
引导模块时,可以向它传递参数。要使用模块参数加载模块,这样写:
insmod module.ko [param1=value param2=value ...]3.系统初始化
3.1 引导过程
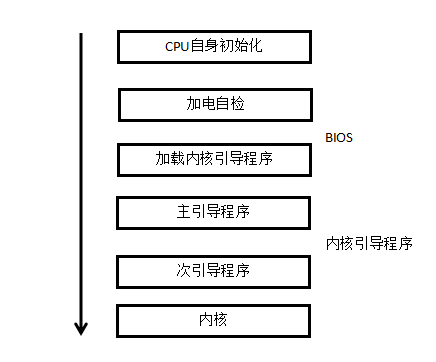
(1)CPU自身初始化
CPU自身初始化是引导过程的第一步,接下来,CPU从某个固定位置(一般是0Xfffffff0)取得指令并执行。该指令为跳转指令,跳转到BOIS代码的首部。
注意:CPU不关心BOIS是否存在,它只是执行该地址中保存的任何指令
(2)BOIS
BOIS被固化于主板上一个容量相对较小的只读存储器(Read-Only Memory,ROM)中,它的工作主要有两个:
- 加电自检(POST:Power On Self Test):硬件自检——内存检测、系统总线检测
- 加载内核引导程序:读取启动设备第一个扇区,即首512字节的信息。该扇区又被称之为主引导记录(Master Boot Recored, MBR)。MBR保存了内核引导程序的开始部分,BIOS将其加载到内存并执行。
加载内核引导程序之后,POST部分的代码会被从内存中清理出来,但仍然会有部分的运行时服务保留在内存中,供目标操作系统使用。
(3)内核引导程序
- MBR中的主引导程序:512字节的映像,包含446字节的程序代码和64字节的分区表,最后两个字节固定位0xAA55,用于检查MBR是否有效。主引导程序扫描分区表,寻找活动分区,将位于活动分区引导记录中的次引导程序加载到内存中并执行。
- 次引导程序负责加载Linux内核映像,并将控制权转交给内核
PC环境中,内核引导程序常用LILO(Linux Loader)和GRUB(Grand Unified Bootloader),在嵌入式环境中,常用U-Boot和Redboot。
(4)内核
内核映像被加载到内存并获得控制权之后,内核阶段开始工作。通常,内核映像以压缩形式存储,并不是一个可执行的内核。因此,内核阶段的首要工作是自解压压缩映像。
head.S的start(硬件设置) -> star_up32(设置基本的运行环境:堆栈等) -> misc.c(解压内核) -> 页表初始化,启动内存分页功能
最后,init/main.c中的star_kernel函数被调用,进入体系结构无关的内核部分。自此,内核的引导过程告一段落,进入内核的初始化过程。
3.2 内核初始化
3.2.1 GCC在c语言中内嵌汇编asm __volatile__
在内嵌汇编中,可以将C语言表达式指定为汇编指令的操作数,而且不用去管如何将C语言表达式的值读入哪个寄存器,以及如何将计算结果写回c变量,你只要告诉程序中C语言表达式与汇编指令操作数之间的对应关系即可,GCC会自动插入代码完成必要的操作。
__asm__ __volatile__("hlt");说明:__asm__表示后面的代码为内嵌汇编; __volatile__表示编译器不要优化,后面指令保持原样。
使用内嵌汇编,要先编写汇编指令模板,然后将C语言表达式与指令的操作数相关联,并告诉GCC对这些操作有哪些限制条件。
__asm__ __volatile__("movl %1,%0":"=r"(result):"m"(input));"movl %1,%0"是指令模板,“%0”和“%1”代表指令的操作数,称为占位符,内嵌汇编靠它们将C语言表达式与指令操作数相对应。指令模板后面用小括号括起来的是C语言表达式,本例中只有两个:“result”和“input”,他们按照出现的顺序分别与指令操作数“%0”、“%1”对应;注意对应顺序:第一个C表达式对应“%0”;第二个表达式对应“%1”,依次类推,操作数至多有10个,分别用“%0”,“%1”,...,“%9”表示。在每个操作数前面有一个用引号括起来的字符串,字符串的内容是对该操作数的限制或者要求。“result”前面的限制字符串是“==r”,其中“="表示“result”是输出操作数,“r”表示需要将“result”与某个通用寄存器相关联,先将操作数的值读入寄存器,然后在指令中使用相应寄存器,而不是“result”本身,当然指令执行完后需要将寄存器中的值存入变量“result”,从表面上看好像是指令直接对“result”进行操作,实际上GCC做了一些隐式处理,这样我们可以少写一些指令。“input”前面的“m”表示该表达式需要先放入某个寄存器,然后在指令中使用该寄存器参加运算。
C表达式或者变量与寄存器的关系由GCC自动处理,我们只需使用限制字符串指导GCC如何处理即可。限制字符必须与指令对操作数的要求相匹配,否则产生的 汇编代码将会有错。
内嵌汇编语法如下:
__asm__(汇编语句模板: 输出部分: 输入部分: 破坏描述部分)
共四个部分:汇编语句模板,输出部分,输入部分,破坏描述部分,各部分使用":"格开,汇编语句模板必不可少,其他三部分可选,如果使用了后面的部分,而前面部分为空,也需要用":"格开,相应部分内容为空。例如:
__asm__ __volatile__("cli": : :"memory")
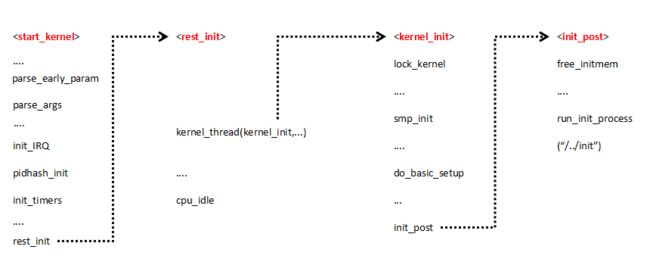
3.2.2 start_kernel函数
asmlinkage void __init start_kernel(void)
{
char * command_line;
extern struct kernel_param __start___param[], __stop___param[];
/*
当只有一个CPU的时候这个函数什么都不做,多个CPU返回启动的CPU的号
*/
smp_setup_processor_id();
/*
* Need to run as early as possible, to initialize the
* lockdep hash:
*/
unwind_init();
lockdep_init();
/*关闭当前CPU中断*/
local_irq_disable();
early_boot_irqs_off();
/*每个中断都有一个中断描述符(struct irq_desc)来进行描述,
这个函数的作用是设置所有中断描述符的锁*/
early_init_irq_lock_class();
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them
*/
/*获取最大内核锁,锁定整个内核*/
lock_kernel();
/*如果定义了CONFIG_GENERIC_CLOCKEVENTS,注册clockevents框架*/
tick_init();
boot_cpu_init();
/*初始化页地址,使用链表将其链接起来*/
page_address_init();
printk(KERN_NOTICE);
/*显示内核的版本信息*/
printk(linux_banner);
/*每种体系结构都有自己的setup_arch()函数,是体系相关的,
具体编译哪个由源码树顶层目录下的Makefile中的ARCH变量决定*/
setup_arch(&command_line);
setup_command_line(command_line);
unwind_setup();
/*每个CPU分配pre-cpu结构内存,并复制.data.percpu段的数据*/
setup_per_cpu_areas();
smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */
/*
* Set up the scheduler prior starting any interrupts (such as the
* timer interrupt). Full topology setup happens at smp_init()
* time - but meanwhile we still have a functioning scheduler.
*/
/*进程调度器初始化*/
sched_init();
/*
* Disable preemption - early bootup scheduling is extremely
* fragile until we cpu_idle() for the first time.
*/
/*禁止内核抢占*/
preempt_disable();
build_all_zonelists();
page_alloc_init();
/*打印Linux启动命令行参数*/
printk(KERN_NOTICE "Kernel command line: %s\n", boot_command_line);
/*对内核选项的两次解析*/
parse_early_param();
parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param,
&unknown_bootoption);
/*检查中断是否已经打开,如果打开,则关闭中断*/
if (!irqs_disabled()) {
printk(KERN_WARNING "start_kernel(): bug: interrupts were "
"enabled *very* early, fixing it\n");
local_irq_disable();
}
sort_main_extable();
/*trap_init函数完成对系统保留中断向量(异常、非屏蔽中断以及系统调用)的初始化,
init_IRQ函数则完成其余中断向量的初始化*/
trap_init();
/*初始化RCU(Read-Copy Update)机制*/
rcu_init();
init_IRQ();
/*初始化hash表,便于从进程的PID获得对应的进程描述符指针*/
pidhash_init();
/*初始化定时器相关数据结构*/
init_timers();
/*对高精度时钟进行初始化*/
hrtimers_init();
/*初始化tasklet_softirp和hi_softirp*/
softirq_init();
timekeeping_init();
/*初始化系统时钟*/
time_init();
/*对内核的profile(一个内核调试工具)功能进行初始化*/
profile_init();
if (!irqs_disabled())
printk("start_kernel(): bug: interrupts were enabled early\n");
early_boot_irqs_on();
local_irq_enable();
/*
* HACK ALERT! This is early. We're enabling the console before
* we've done PCI setups etc, and console_init() must be aware of
* this. But we do want output early, in case something goes wrong.
*/
/*初始化控制台以显示printk的内容,在此之前调用的printk只是把数据存放到缓冲区里*/
console_init();
if (panic_later)
panic(panic_later, panic_param);
/*如果定义了CONFIG_LOCKDEP,则打印锁依赖信息,否则什么也不做*/
lockdep_info();
/*
* Need to run this when irqs are enabled, because it wants
* to self-test [hard/soft]-irqs on/off lock inversion bugs
* too:
*/
locking_selftest();
#ifdef CONFIG_BLK_DEV_INITRD
if (initrd_start && !initrd_below_start_ok &&
initrd_start < min_low_pfn << PAGE_SHIFT) {
printk(KERN_CRIT "initrd overwritten (0x%08lx < 0x%08lx) - "
"disabling it.\n",initrd_start,min_low_pfn << PAGE_SHIFT);
initrd_start = 0;
}
#endif
/*虚拟文件系统的初始化*/
vfs_caches_init_early();
cpuset_init_early();
mem_init();
/*slab初始化*/
kmem_cache_init();
setup_per_cpu_pageset();
numa_policy_init();
if (late_time_init)
late_time_init();
/*
一个非常有趣的CPU性能测试函数,可以计算出CPU在1s内执行了多少次一个极短的循环,
计算出来的值经过处理后得到BogoMIPS值
*/
calibrate_delay();
pidmap_init();
/*接下来的函数中,大多数都是为有关的管理机制建立专用的slab缓存*/
pgtable_cache_init();
/*初始化优先级树index_bits_to_maxindex数组*/
prio_tree_init();
anon_vma_init();
#ifdef CONFIG_X86
if (efi_enabled)
efi_enter_virtual_mode();
#endif
/*根据物理内存大小计算允许创建进程的数量*/
fork_init(num_physpages);
proc_caches_init();
buffer_init();
unnamed_dev_init();
key_init();
security_init();
vfs_caches_init(num_physpages);
radix_tree_init();
signals_init();
/* rootfs populating might need page-writeback */
page_writeback_init();
#ifdef CONFIG_PROC_FS
proc_root_init();
#endif
cpuset_init();
taskstats_init_early();
delayacct_init();
/*测试该CPU的各种缺陷,记录检测到的缺陷,以便于内核的其他部分以后可以使用它们的工作*/
check_bugs();
acpi_early_init(); /* before LAPIC and SMP init */
/* Do the rest non-__init'ed, we're now alive */
/*创建init进程*/
rest_init();
}
3.2.3 reset_init函数
/*
* We need to finalize in a non-__init function or else race conditions
* between the root thread and the init thread may cause start_kernel to
* be reaped by free_initmem before the root thread has proceeded to
* cpu_idle.
*
* gcc-3.4 accidentally inlines this function, so use noinline.
*/
static void noinline __init_refok rest_init(void)
__releases(kernel_lock)
{
int pid;
/*reset_init()函数最主要的历史使命就是启动内核线程kernel_init*/
kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
numa_default_policy();
/*启动内核线程kthreadd,运行kthread_create_list全局链表中的kthread*/
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
kthreadd_task = find_task_by_pid(pid);
unlock_kernel();
/*
* The boot idle thread must execute schedule()
* at least once to get things moving:
*/
/*增加idle进程的need_resched标志,并且调用schedule释放CPU,将其赋给更应该获取CPU的进程*/
init_idle_bootup_task(current);
preempt_enable_no_resched();
schedule();
preempt_disable();
/* Call into cpu_idle with preempt disabled */
/*进入idle循环以消耗空闲的CPU时间片,该函数从不返回。
然而,当有实际工作要处理时,该函数就会被抢占*/
cpu_idle();
}
3.2.4 kernel_init函数
/*完成设备驱动初始化,调用init_post函数启动用户空间的init进程*/
static int __init kernel_init(void * unused)
{
lock_kernel();
/*
* init can run on any cpu.
*/
/*修改进程的CPU亲和力*/
set_cpus_allowed(current, CPU_MASK_ALL);
/*
* Tell the world that we're going to be the grim
* reaper of innocent orphaned children.
*
* We don't want people to have to make incorrect
* assumptions about where in the task array this
* can be found.
*/
/*把当前进程设为接受其他孤儿进程的进程*/
init_pid_ns.child_reaper = current;
__set_special_pids(1, 1);
cad_pid = task_pid(current);
smp_prepare_cpus(max_cpus);
do_pre_smp_initcalls();
/*激活SMP系统中其他CPU*/
smp_init();
sched_init_smp();
cpuset_init_smp();
/*此时与体系结构相关的部分已经初始化完成,现在开始调用do_basic_setup函数
初始化设备,完成外设及其驱动程序(直接编译进内核的模块)的加载和初始化*/
do_basic_setup();
/*
* check if there is an early userspace init. If yes, let it do all
* the work
*/
if (!ramdisk_execute_command)
ramdisk_execute_command = "/init";
if (sys_access((const char __user *) ramdisk_execute_command, 0) != 0) {
ramdisk_execute_command = NULL;
prepare_namespace();
}
/*
* Ok, we have completed the initial bootup, and
* we're essentially up and running. Get rid of the
* initmem segments and start the user-mode stuff..
*/
init_post();
return 0;
}
3.2.5 init_post函数
/* This is a non __init function. Force it to be noinline otherwise gcc
* makes it inline to init() and it becomes part of init.text section
*/
static int noinline init_post(void)
{
/*内核初始化已经接近尾声,所有的初始化函数都已经被调用,free_initmem可以舍弃内存的__init_begin
至__init_end(包括.init.setup、.initcall.init)之间的数据。所有使用__init标记过的函数和使用__initdata
标记过的数据,在free_initmem函数执行后都不能使用,它们曾经获得内存现在可以重新用于其他目的*/
free_initmem();
unlock_kernel();
mark_rodata_ro();
system_state = SYSTEM_RUNNING;
numa_default_policy();
/*打开控制台设备,这样init进程就拥有一个控制台,并可以从中读取输入信息,也可以向其中写入信息,
实际上init进程除了打印打印错误信息以外,并不使用控制台,但是如果调用的是shell或者其他需要交互的
进程,而不是init,那么就需要一个可以交互的输入源。如果执行成功open,/dev/console即成为init的标准
输入源(文件描述符0)
*/
if (sys_open((const char __user *) "/dev/console", O_RDWR, 0) < 0)
printk(KERN_WARNING "Warning: unable to open an initial console.\n");
/*调用dup打开/dev/console文件描述符两次,这样该控制台设备就可以供标准输出和标准错误
使用(文件描述符1和2)*/
(void) sys_dup(0);
(void) sys_dup(0);
/*如果内核命令行中给出了到init进程的直接路径,这里就试图执行init。
因为当kernel_execve函数成功执行目标程序时并不返回,只有失败时,才能执行相关的表达式。
接下来的几行会在几个地方查找init,按照可能性由高到低的顺序依次是:/sbin/init,
这是init标准的位置;/etc/init和/bin/init,两个可能的位置。
*/
if (ramdisk_execute_command) {
run_init_process(ramdisk_execute_command);
printk(KERN_WARNING "Failed to execute %s\n",
ramdisk_execute_command);
}
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
if (execute_command) {
run_init_process(execute_command);
printk(KERN_WARNING "Failed to execute %s. Attempting "
"defaults...\n", execute_command);
}
/*init可能出现的所有地方,如果没有发现,系统可能因此崩溃*/
run_init_process("/sbin/init");
run_init_process("/etc/init");
run_init_process("/bin/init");
/*试图建立一个交互的shell(/bin/sh)来代替,希望root用户可以修复上面找不到init的错误,并重新启动*/
run_init_process("/bin/sh");
/*由于某些原因,init甚至不能创建shell,当前面的所有情况都失败时,调用panic。这样内核就会试图同步
磁盘,确保其状态一致。如果超过了内核选项中定义的时间,它也可能会重新启动机器*/
panic("No init found. Try passing init= option to kernel.");
}
3.3 init进程
当内核被引导并进行初始化之后,内核启动了自己的第一个用户空间应用程序,即init。这是调用的第一个使用标准C库编译的程序,其进程编号始终为1。
- init负责触发其他必须的进程,以使系统进入整体可用的状态。
- 根据/etc/inittab文件来完成,包括设置getty进程接受用户登录,设置键盘、字图,设置网络等。
基于这种设计模式,init进程是系统中所有进程的起源,init进程产生getty进程,getty进程产生login进程,login进程又产生shell进程,然后我们使用shell,就可以产生每一个需要执行的进程。
3.4 内核选项解析
Linux允许用户传递内核配置选项给内核,内核在初始化过程中调用parse_args函数对这些选项进行解析,并调用相应的处理函数。
- 内核选项使用格式“变量名=值”
- 如果在内核启动时使用模块参数,必须添加模块名作为前缀:“模块名.参数=值”
- 从Documentation/kernel-parameters.txt文件可以查询到某个子系统已经注册的内核选项
内核选项使用__setup宏来注册
//include/linux/init.h
#define __setup(str,fn) __setup_param(str,fn,fn,0)str是内核选项的名字,fn是该内核选项关联的处理函数。
early_param也可以注册内核选项,但是必须要在其他内核选项之前被处理
__setup和early_param注册的内核选项所关联的处理函数存放在.init.setup节。
.init.setup : AT(ADDR(.init.setup) - LOAD_OFFSET) {
__setup_start = .;
*(.init.setup)
__setup_end = .;
}内核启动之后,.init.setup节会被释放,其中存放的内存选项不再需要,用户不能够在系统运行时查看或修改它们。
3.5 子系统初始化
kernel_init -> do_basic_setup -> do_initcalls 完成各子系统初始化函数调用。
初始化函数位置:
.initcall.init : AT(ADDR(.initcall.init) - LOAD_OFFSET) {
__initcall_start = .;
INITCALLS
__initcall_end = .;
}
#define INITCALLS \
*(.initcall0.init) \
*(.initcall0s.init) \
*(.initcall1.init) \
*(.initcall1s.init) \
*(.initcall2.init) \
*(.initcall2s.init) \
*(.initcall3.init) \
*(.initcall3s.init) \
*(.initcall4.init) \
*(.initcall4s.init) \
*(.initcall5.init) \
*(.initcall5s.init) \
*(.initcallrootfs.init) \
*(.initcall6.init) \
*(.initcall6s.init) \
*(.initcall7.init) \
*(.initcall7s.init)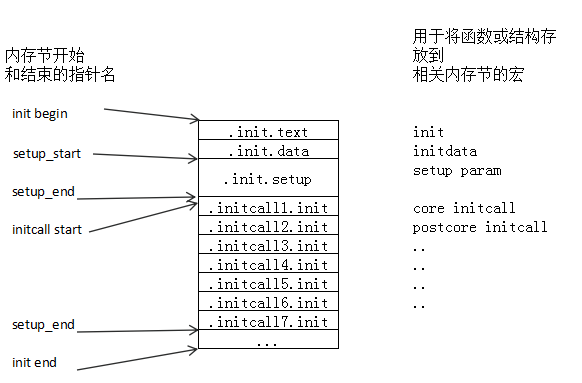
函数或结构存放到相关内存的宏位于 include/linux/init.h,.initcall.init的内容会使用free_initmem函数释放
内核中的Makefile主要有如下3种:
- 内核源码树根目录里的Makefile。虽说只有一个,但地位远远高于其他Makefile,其中定义了所有与体系无关的变量和目标。
- arch/*/Makefile 与体系结构相关,它会被根目录下的Makefile包含,为kbuild提供体系结构的特定信息。而它又包含了arch/*/目录下面各级子目录下的那些Makefile
- driver/等各个子目录下的那些Makefile
4.系统调用
系统调用就是用户应用程序访问并使用内核所提供的各种服务的途径。
通常情况下,应用程序通过操作系统提供的应用编程接口(API:基于POSIX标准)而不是直接通过系统调用来编程。
POSIX:Portable Operating System Interface of UNIX,可移植操作系统接口
系统调用表sys_call_table存储了所有系统调用对于的服务例程的函数地址,在arch/i386/kernel/syscall_table.S文件中被定义,系统调用在内核中的执行就是从该表中获取对应的服务例程并执行的过程。
每个系统调用都拥有一个独一无二的系统调用号,用户应用通过它,而不是系统调用的名称,来指明要执行哪个系统调用。每个系统调用号都依次对应了sys_call_table中的某一项,内核正是将系统调用号作为下标去获取sys_call_table中的服务例程函数地址。
系统调用服务例程集中声明在include/linux/syscalls.h,首先,函数定义中必须添加asmlinkage标记,通知编译器仅从堆栈中获取该函数的参数。其次,必须返回一个long类型的返回值表示成功或者错误,通常返回0表示成功,返回负值表示错误。
为什么需要系统调用?
- 系统调用可以为用户空间提供访问硬件资源的统一接口,以至于应用进程不必去关注具体的硬件访问操作。
- 系统调用可以对系统进行保护,保证系统的稳定和安全。
系统调用执行过程
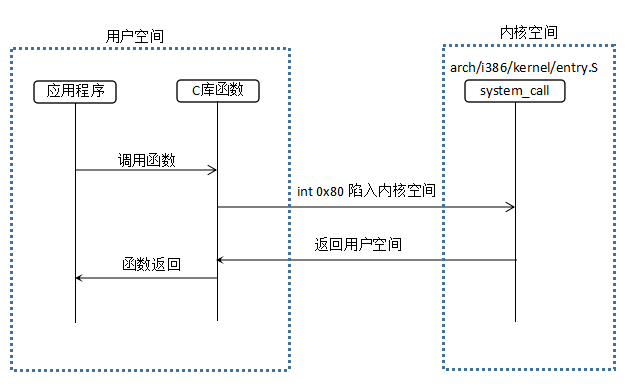
(1)用户空间到内核空间
系统调用的执行需要一个用户空间到内核空间的状态转换,不同的平台具有不同的指令可以完成这种转换,这种指令也被称为操作系统陷入(operating system trap)指令。Linux通过软中断来实现这种陷入,具体对于x86架构来说,是软中断0x80,也即int $0x80汇编指令。int $0x80指令被封装在C库中,对于用户应用来说,基于可移植性的考虑,不应该直接调用int $0x80指令。陷入指令的平台依赖性,也正是系统调用需要在C库进行封装的原因之一。
通过软中断0x80,系统会跳转到一个预设的内核空间地址,它指向了系统调用处理程序(不是系统调用服务例程),即在arch/i386/kernel/entry.S文件中使用汇编语言编写的system_call函数。
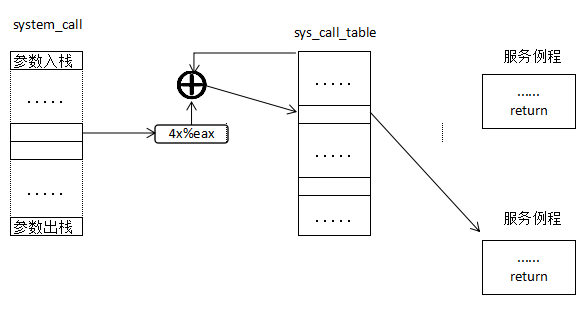
(2)system_call函数到系统调用服务例程
所有的系统调用都会跳转到这个预设的内核空间地址执行system_call函数,当软中断被执行时,系统调用号会被放入eax寄存器,同时,sys_call_table每一项占用4个字节。这样,system_call函数可以读取eax寄存器获得当前系统调用的系统调用号,将其乘以4生成偏移地址,然后以sys_call_table为基址,基址加上偏移地址所指向的内容即是应该执行系统调用服务例程的地址。
若是传递参数到内核,如write系统调用的服务例程原型为:
sys_write(ungigned int fd,const char *buf,size_t count);调用write系统调用时就需要传递文件描述符fd、要写入的内容buf以及写入字节数count等几个内容到内核。ebx、ecx、edx、esi以及edi寄存器可以用于传递这些额外参数。
系统调用服务例程定义中的asmlinkage标记表示编译器从堆栈中获取参数。在进入system_call函数前,用户应用将参数存放到对应寄存器中,system_call函数执行时会首先将这些寄存器压入堆栈。
系统服务例程直接从堆栈中获取数据并修改,在system_call函数退出后,用户应用可以直接从寄存器中获得被修改的参数。
sys_dup是最简单的服务例程之一,它是Linux输入、输出重定向的基础。在Linux中,执行一个shell命令时通常会自动打开3个标准文件:标准输入文件(stdin),对应键盘;标准输出文件(stdout)和标准错误输出文件(stderr),对应终端的屏幕。
sys_dup()是如何完成输入、输出的重定向的呢?
当我们在shell终端输入“echo hello”命令时,将会要求shell进程执行一个可执行文件echo,参数为“hello”。当shell进程接收到命令后,先在/bin目录下找到echo文件,然后创建一个子进程去执行/bin/echo,并将参数传递给它,而这个子进程从shell进程继承了3个标准输入/输出文件,即stdin、stdout和stderr,文件号分别为0,1,2。它的工作很简单,就是将参数“hello”写到stdout文件中,通常是我们的屏幕上。
但是如果我们将命令改成“echo hello > txt”,则在执行时输出将会被重定向到磁盘文件txt中。假定之前该shell进程只有上述3个标准文件打开,则该命令将按如下序列执行:
- 打开或创建文件txt,如果txt中原来有内容,则清除原来的内容,其文件号为3.
- 通过dup系统调用复制文件stdout的相关数据结构到文件号4
- 关闭stdout,但是由于4号文件也同时引用stdout,所以stdout文件并未真正关闭,只是腾出1号文件号位置。
- 通过dup系统调用,复制3号文件(即文件txt),由于1号文件关闭,其位置空缺,故3号文件被复制到1号,即进程中原来指向stdout的指针指向了txt.
- 通过系统调用fork和exec创建子进程并执行echo,子进程在执行cat前关闭3号和4号文件,只留下0、1、2三个文件,请注意,这时的1号文件已经不是stdout而是文件txt了。当cat想向stdout文件写入“hello”时自然就写入到了txt中。
- 回到shell进程后,关闭指向txt的1号与3号文件,再用dup和close系统调用将2号恢复至stdout,这样shell就恢复了0、1、2三个标准输入/输出文件。
如何实现一个新的系统调用?
4个步骤:编写系统调用服务例程;添加系统调用号;修改系统调用表;重新编译内核并测试新添加的系统调用。
(1)编写系统调用服务例程
asmlinkage long sys_hello(void)
{
printk("Hello!\n");
return 0;
}通常,应该为新的系统调用服务例程创建一个新的文件进行存放,但也可以将其定义在其他文件之中,并加上注释做必要说明。同时,还要在include/linux/syscalls.h文件中添加原型声明:
asmlinkage long sys_hello(void);如果需要传递信息,则sys_hello函数可以实现为:
asmlinkage long sys_hello(const char __user *_name)
{
char *name;
long ret;
name = strndup_user(_name,PAGE_SIZE);//从用户空间复制字符串name的内容
if(IS_ERR(name)){ //判断指针是否有错
ret = PTR_ERR(name); //返回这个错误代码
goto error;
}
printk("Hello!\n");
return 0;
error:
return error;
}__user标记表示所修饰的指针为用户空间指针,不能在内核空间直接引用,原因如下:
- 用户空间指针在内核空间可能是无效的
- 用户空间的内存是分页的,可能引起页错误
- 如果可以直接引用,就相当于用户空间可以直接访问内核空间,产生安全问题
(2)添加系统调用号
更新include/asm-i386/unistd.h添加一个系统调用号
#define __NR_eventfd 323
#define __NR_fallocate 324
#define __NR_hello 325 //分配hello系统调用号为325
#ifdef __KERNEL__
#define NR_syscalls 326 //将系统调用数目加1修改为326(3)修改系统调用表(sys_call_table)
.long sys_utimensat /* 320 */
.long sys_signalfd
.long sys_timerfd
.long sys_eventfd
.long sys_fallocate
.long sys_hello //hello系统调用服务例程
(4)重新编译内核并测试
针对hello系统调用的测试程序如下:
#include
#include
#include
#define _NR_hello 325
int main(int argc, char *argv[])
{
syscall(_NR_hello);
return 0;
} 添加系统调用需要修改内核源代码,重新编译内核,如果更进一步希望自己添加的系统调用能够得到广泛的应用,就需要得到官方的认可并分配一个固定的系统调用号,还需要将该系统调用在每个需要支持的体系结构上实现,因此最好使用其他方法和内核交换信息:
- 使用设备驱动程序
- 使用proc虚拟文件系统
- sysfs文件系统