《趣谈Linux》总结二:系统初始化
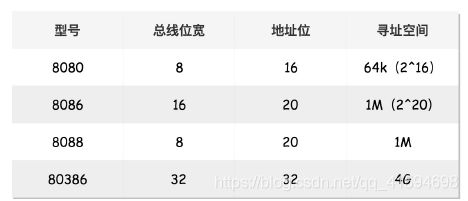
4 x86架构
对于linux来说,如果下面的硬件环境千差万别,就会很难集中精力做出让用户易用的产品;
毕竟天天适配不同的平台,就已经够辛苦了;
x86 架构就是这样一个开放的平台。
4.1 计算机的工作模式
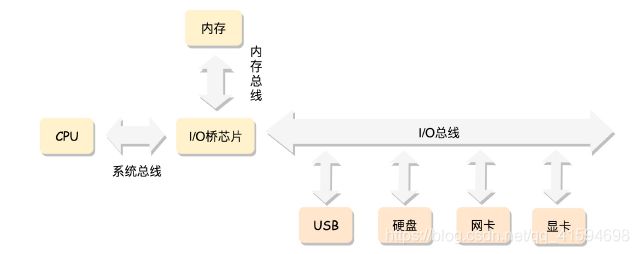
对于一个计算机来讲,最核心的就是CPU(Central Processing Unit,中央处理器)。这是这台计算机的大脑,所有的设备都围绕它展开。
CPU 和其他设备连接,要靠一种叫作总线(Bus)的东西,其实就是主板上密密麻麻的集成电路,这些东西组成了 CPU 和其他设备的高速通道。
在这些设备中,最重要的是内存(Memory)。
原因:因为单靠 CPU 是没办法完成计算任务的,很多复杂的计算任务都需要将中间结果保存下来,然后基于中间结果进行进一步的计算;CPU 本身没办法保存这么多中间结果,这就要依赖内存了。
还有一些其他设备,例如显卡会连接显示器、磁盘控制器会连接硬盘、USB 控制器会连接键盘和鼠标等等。
CPU 和内存是完成计算任务的核心组件,所以这里重点介绍一下CPU 和内存是如何配合工作的:
- CPU和内存的配合
CPU 其实也不是单纯的一块,它包括三个部分,运算单元(算)、数据单元(存)和控制单元(指挥);
运算单元只管算,例如做加法、做位移等等;
但是,它不知道应该算哪些数据,运算结果应该放在哪里。
运算单元计算的数据如果每次都要经过总线,到内存里面现拿,这样就太慢了,所以就有了数据单元;
数据单元包括 CPU 内部的缓存和寄存器组,空间很小,但是速度飞快,可以暂时存放数据和运算结果。
有了放数据的地方,也有了算的地方,还需要有个指挥到底做什么运算的地方,这就是控制单元;
控制单元是一个统一的指挥中心,它可以获得下一条指令,然后执行这条指令;
这个指令会指导运算单元取出数据单元中的某几个数据,计算出个结果,然后放在数据单元的某个地方。
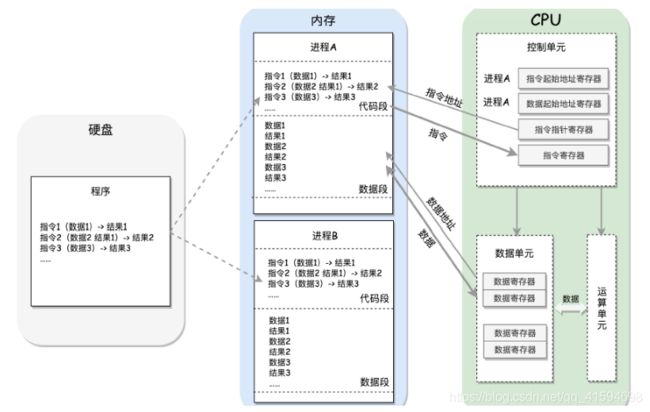
每个进程都有一个程序放在硬盘上,是二进制的,再里面就是一行行的指令,会操作一些数据。
进程一旦运行,比如图中两个进程 A 和 B,会有独立的内存空间,互相隔离;
程序会分别加载到进程 A 和进程 B 的内存空间里面,形成各自的代码段。(真实情况更复杂)
程序运行的过程中要操作的数据和产生的计算结果,都会放在数据段里面:
- CPU 怎么执行这些程序,操作这些数据,产生一些结果,并写入回内存呢?
CPU 的控制单元里面,有一个指令指针寄存器,执行的是下一条指令在内存中的地址;
控制单元会不停地将代码段的指令拿进来,先放入指令寄存器。
指令分两部分:
第一部分是做什么操作,例如是加法还是位移;
二一部分是操作哪些数据。
如何执行指令:把第一部分交给运算单元,第二部分交给数据单元。
数据单元根据数据的地址,从数据段里读到数据寄存器里,就可以参与运算了;
运算单元做完运算,产生的结果会暂存在数据单元的数据寄存器里;
最终,会有指令将数据写回内存中的数据段。
CPU 里有两个寄存器,专门保存当前处理进程的代码段的起始地址,以及数据段的起始地址;(指令起始地址寄存器,数据起始地址寄存器)
这里面写的都是进程 A,那当前执行的就是进程 A 的指令,等切换成进程 B,就会执行 B 的指令了,这个过程叫作进程切换(Process Switch),这是多任务的基础
- 总线
CPU 和内存来来回回传数据,靠的都是总线。
总线上主要有两类数据:
一个是地址数据,也就是我想拿内存中哪个位置的数据,这类总线叫地址总线(AddressBus);
另一类是真正的数据,这类总线叫数据总线(Data Bus)。
所以说,总线有点像连接 CPU 和内存这两个设备的高速公路,说总线到底是多少位,就类似
说高速公路有几个车道;
这两种总线的位数意义是不同的:
地址总线的位数,决定了能访问的地址范围到底有多广:例如只有两位,那 CPU 就只能认 00,01,10,11 四个位置,超过四个位置,就区分不出来了。位数越多,能够访问的位置就越多,能管理的内存的范围也就越广。
数据总线的位数,决定了一次能拿多少个数据进来:例如只有两位,那 CPU 一次只能从内存拿两位数;要想拿八位,就要拿四次。位数越多,一次拿的数据就越多,访问速度也就越快。
4.2 x86作用
CPU 数据总线和地址总线越来越宽,处理能力越来越强,但始终开放、统一、兼容:
“开放”,意味着有大量其他公司的软硬件是基于这个架构来实现的,不能为所欲为,想怎么改怎么改,一定要和原来的架构兼容,而且要一直兼容,这样大家才愿意跟着你这个开放平台一直玩下去。如果朝令夕改,那其他厂商就惨了。
4.2.1 8086处理器
CPU组件:
4.2.1.1 数据单元
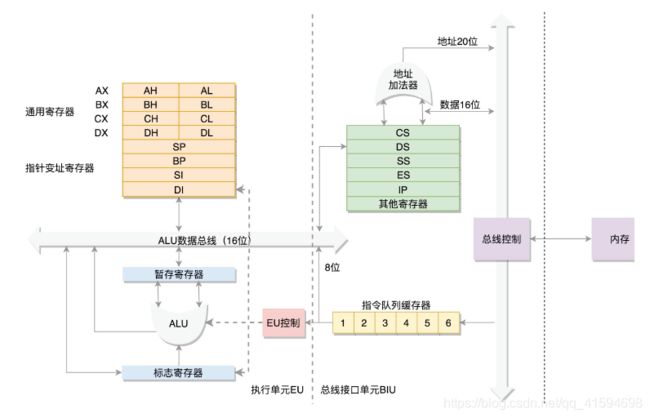
为了暂存数据,8086 处理器内部有 8 个 16 位的通用寄存器,也就是刚才说的 CPU 内部的数据单元;
分别是AX、BX、CX、DX、SP、BP、SI、DI
这些寄存器主要用于在计算过程中暂存数据
这些寄存器比较灵活,其中 AX、BX、CX、DX 可以分成两个 8 位的寄存器来使用,分别是 AH、
AL、BH、BL、CH、CL、DH、DL,其中 H 就是 High(高位),L 就是 Low(低位)的意思;
这样,比较长的数据也能暂存,比较短的数据也能暂存;
在计算机刚刚起步的时代,16位就算很长了,所以要划分
4.2.1.2 控制单元
- IP 寄存器
即指令指针寄存器(Instruction Pointer Register),指向代码段中下一条指令的位置;
CPU 会根据它来不断地将指令从内存的代码段中,加载到 CPU 的指令队列中,然后交给运算单元去执行。
- 切换进程所需的寄存器
每个进程都分代码段和数据段,为了指向不同进程的地址空间,有四个 16位的段寄存器,分别是 CS、DS、SS、ES。
CS 是代码段寄存器(Code Segment Register):通过它可以找到代码在内存中的位置;
DS 是数据段的寄存器(Data Register):通过它可以找到数据在内存中的位置;
SS 是栈寄存器(Stack Register):栈是程序运行中一个特殊的数据结构,数据的存取只能从一
端进行,秉承后进先出的原则,push 就是入栈,pop 就是出栈
ES 是附加段寄存器(Extra Segment) :其他几个段寄存器不够用的时候,可以考虑使用 ES 段寄存器,
DS作用:如果运算中需要加载内存中的数据,需要通过 DS 找到内存中的数据,加载到通用寄存器中。(交互)
如何加载?
对于一个段,有一个起始的地址,而段内的具体位置称之为偏移量(Offset);
在 CS 和 DS 中都存放着一个段的起始地址:代码段的偏移量在 IP 寄存器中,数据段的偏移量会放在通用寄存器中;
出现的问题:CS 和 DS 都是 16 位的,也就是说,起始地址都是 16 位的,IP 寄存器和通用寄存器都是 16 位的,偏移量也是 16 位的,但是 8086 的地址总线地址是 20 位。怎么凑够这 20 位呢?
解决方法:使用“起始地址 *16+ 偏移量”,也就是把 CS 和 DS 中的值左移 4 位,变成 20 位的,加上 16 位的偏移量,这样就可以得到最终 20 位的数据地址。
SS作用:凡是与函数调用相关的操作,都与栈紧密相关;
例如,A 调用 B,B 调用 C。当 A 调用 B 的时候,要执行 B 函数的逻辑,因而 A 运行的相关信息就会被 push 到栈里面;
当 B 调用 C 的时候,同样,B 运行相关信息会被 push 到栈里面,然后才运行 C 函数的逻辑;
当 C 运行完毕的时候,先 pop 出来的是 B,B 就接着调用 C 之后的指令运行下去;
B 运行完了,再 pop 出来的就是 A,A 接着运行,直到结束。

从DS例子可以算出,无论真正的内存多么大,对于只有 20 位地址总线的 8086 来讲,能够区分出的地址也就 2^20=1M,超过这个空间就访问不到了。为什么呢?如果你想访问 1M+X的地方,这个位置已经超过 20 位了,由于地址总线只有 20 位,在总线上超过 20 位的部分根本是发不出去的,所以发出去的还是 X,最后还是会访问 1M 内的 X 的位置。
那一个段最大能有多大呢?因为偏移量只能是 16 位的,所以一个段最大的大小是 2^16=64k。
4.2.2 32位处理器
在 32 位处理器中,有 32根地址总线,即32位,可以访问 2^32=4G 的内存。
在开放架构的基础上,如何保持兼容呢?
1.首先,通用寄存器进行扩展,可以将 8 个 16 位的寄存器扩展到 8 个 32 位的,但是依然可以保留 16 位的和 8 位的使用方式。
为什么高 16 位不分成两个 8 位使用呢?因为这样就不兼容了呀!
其中,指向下一条指令的指令指针寄存器 IP,就会扩展成 32 位的,同样也兼容 16 位的。

而改动比较大,有点不兼容的就是段寄存器(Segment Register):CS、DS、SS、ES
因为原来的模式没有把 16 位当成一个段的起始地址,也没有按 8 位或者 16 位扩展的形式,而是根据当时的硬件,弄了一个不上不下的 20 位的地址。
这样每次都要左移四位,也就意味着段的起始地址不能是任何一个地方,只是能整除 16 的地方。
如果新的段寄存器都改成 32 位的,明明 4G 的内存全部都能访问到(寄存器跟总线的位数相同),还左移不左移四位呢?
所以索性就重新定义:CS、SS、DS、ES 仍然是 16 位的,但是不再是段的起始地址;
段的起始地址放在内存的某个地方。这个地方是一个表格,表格中的一项一项是段描述符(Segment Descriptor);
这里面才是真正的段的起始地址。而段寄存器里面保存的是在这个表格中的哪一项,称为选择子(Selector)。
这样,将一个从段寄存器直接拿到的段起始地址的操作变成了先间接地从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址。
这样段起始地址就会很灵活了;
当然为了快速拿到段起始地址,段寄存器会从内存中拿到 CPU 的描述符高速缓存器中。
当然,改了设计就不兼容了,怎么办呢?
将前一种模式称为实模式(Real Partern),后一种模式称为保护模式(Protected Partern);
当系统刚刚启动的时候,CPU 是处于实模式的,这个时候和原来的模式是兼容的;
也就是说,哪怕你买了 32 位的 CPU,也支持在原来的模式下运行,只不过快了一点而已。
当需要更多内存的时候,你可以遵循一定的规则,进行一系列的操作,然后切换到保护模式,就能够用到 32 位 CPU 更强大的能力。
这也就是说,不能无缝兼容,但是通过切换模式兼容,也是可以接受的。
4.3 总结

接下来看一下,CPU 如何从启动开始,逐渐从实模式变为保护模式的。
5 从BIOS到bootloader
从实模式开始,讲解操作系统的启动过程
5.1 BIOS时期
计算机需要有一个指导来进行启动,BIOS可以起这个作用
在主板上,有一个东西叫ROM(Read Only Memory,只读存储器)。
这和平常说的内存RAM(Read Access Memory,随机存取存储器)不同;
平时买的内存条是可读可写的,这样才能保存计算结果;
而 ROM 是只读的,上面早就固化了一些初始化的程序,也就是BIOS(Basic Input and Output System,基本输入输出系统)。
安装好操作系统时,刚启动的时候,按某个组合键,显示器会弹出一个蓝色的界面,这能够调整启动顺序的系统就是 BIOS,然后可以执行它:
刚启动时,内存很小,要好好利用:(假设只有1M)

在 x86 系统中,将 1M 空间最上面的 0xF0000 到 0xFFFFF 这 64K 映射给 ROM;
也就是说,到这部分地址访问的时候,会访问 ROM:
当电脑刚加电的时候,会做一些重置的工作:将 CS 设置为 0xFFFF,将 IP 设置为 0x0000;
所以第一条指令就会指向 0xFFFF0,正是在 ROM 的范围内;
在这里,有一个 JMP 命令会跳到 ROM 中做初始化工作的代码,于是,BIOS 开始进行初始化的工作。
5.1.1 BIOS流程
1.BIOS 要检查一下系统的硬件是否没问题
2.要有系统调用,只不过自己就是干活的;
这个时期你提供的服务很简单,但也会有零星需求。
这个时候,要建立一个中断向量表和中断服务程序,因为现在你还要用键盘和鼠标,这些都要通过中断进行的。
这个时期要输出一些结果,因为需要自己来,所以还要充当输入系统;
做了什么工作,做到了什么程度,都要主动显示出去,也就是在内存空间映射显存的空间,在显示器上显示一些字符(输出系统):
5.2 bootloader时期
BIOS只能保证系统成立,但不能保证系统做大做强,需要寻找操作系统,操作系统就很强了;
所以BIOS做完任务后,要开始从引导扇区开始找操作系统
那么操作系统在哪儿呢?
一般都会在安装在硬盘上;
在 BIOS 的界面上有一个启动盘的选项
启动盘有什么特点呢?
它一般在第一个扇区,占 512 字节,而且以 0xAA55 结束。这是一个约定,当满足这个条件的时候,就说明这是一个启动盘,在 512 字节以内会启动相关的代码。
这些代码是谁放在这里的呢?
在 Linux 里面有一个工具,叫Grub2,全称 Grand UnifiedBootloader Version 2。顾名思义,就是搞系统启动的;
可以通过 grub2-mkconfig -o /boot/grub2/grub.cfg 来配置系统启动的选项;
这里面的选项会在系统启动的时候,成为一个列表,让你选择从哪个系统启动;
使用 grub2-install /dev/sda,可以将启动程序安装到相应的位置。
grub2 第一个要安装的就是 boot.img;
它由 boot.S 编译而成,一共 512 字节,正式安装到启动盘的第一个扇区。这个扇区通常称为MBR(Master Boot Record,主引导记录 / 扇区);
上文说的BIOS 完成任务后,会将 boot.img 从硬盘加载到内存中的 0x7c00 来运行。由于 512 个字节实在有限,boot.img 做不了太多的事情。它能做的最重要的一个事情就是加载grub2 的另一个镜像 core.img。
引导扇区就是上文说的引导BIOS去找操作系统的“导游”,它虽然不知道“宝典”在哪里,但是它知道谁知道,即core.img。
core.img 就是寻找操作系统的真正入口,它们知道的和能做的事情就多了一些;
core.img 由lzma_decompress.img、diskboot.img、kernel.img 和一系列的模块组成,功能比较丰富,能做
很多事情
boot.img和core.img组成的扇区:

boot.img 先加载的是 core.img 的第一个扇区;
如果从硬盘启动的话,这个扇区里面是diskboot.img,对应的代码是 diskboot.S。
boot.img 将控制权交给 diskboot.img 后,diskboot.img 的任务就是将 core.img 的其他部分加载进来:
先是解压缩程序 lzma_decompress.img,再往下是 kernel.img,最后是各个模块 module对应的映像;
这里需要注意,它不是 Linux 的内核,而是 grub 的内核。
lzma_decompress.img 对应的代码是 startup_raw.S,本来 kernel.img 是压缩过的,现在执行的时候,需要解压缩。
在这之前,我们所有遇到过的程序都非常非常小,完全可以在实模式下运行;
但是随着我们加载的东西越来越大,实模式这 1M 的地址空间实在放不下了,所以在真正的解压缩之前,lzma_decompress.img 调用 real_to_prot,切换到保护模式;
这样就能在更大的寻址空间里面,加载更多的东西。
5.2.1 从实模式切换到保护模式
切换到保护模式后,需要把哪些是操作系统的权限,哪些是可以授权给别人的,都分的清清楚楚;
这样就可以分出多个子系统,同时进行多个进程
切换到保护模式要干很多工作,大部分工作都与内存的访问方式有关:
第一项是启用分段,就是在内存里面建立段描述符表,将寄存器里面的段寄存器变成段选择子,指向某个段描述符,这样就能实现不同进程的切换了。
第二项是启动分页。能够管理的内存变大了,就需要将内存分成相等大小的块
保护模式需要做一项工作,那就是打开 Gate A20,也就是第 21根地址线的控制线。
在实模式 8086 下面,一共就 20 个地址线,可访问 1M 的地址空间;
如果超过了这个限度怎么办呢?当然是绕回来了;
在保护模式下,第 21 根要起作用了,于是我们就需要打开 Gate A20。
切换保护模式的函数 DATA32 call real_to_prot 会打开 Gate A20,也就是第 21 根地址线的控制线。
这样,我们就有大把空间了。
接下来要对压缩过的 kernel.img 进行解压缩,然后跳转到kernel.img 开始运行;
这时就是真正进行操作系统的选择:
kernel.img 对应的代码是 startup.S 以及一堆 c 文件,在 startup.S 中会调用 grub_main,这是grub kernel 的主函数。
在这个函数里面,grub_load_config() 开始解析我们上面提到的 grub.cfg 文件里的配置信息。
如果是正常启动,grub_main 最后会调用 grub_command_execute (“normal”, 0, 0),最终会调用grub_normal_execute() 函数。在这个函数里面,grub_show_menu() 会显示出让你选择的那个操作系统的列表。
选择启动某个操作系统,就要开始调用 grub_menu_execute_entry() ,开始解析并执行你选择的那一项,这时候操作系统就启动完毕了
解析:
例如里面的 linux16 命令,表示装载指定的内核文件,并传递内核启动参数;
于是grub_cmd_linux() 函数会被调用,它会首先读取 Linux 内核镜像头部的一些数据结构,放到内存中的数据结构来,进行检查;
如果检查通过,则会读取整个 Linux 内核镜像到内存。
如果配置文件里面还有 initrd 命令,用于为即将启动的内核传递 init ramdisk 路径;于是grub_cmd_initrd() 函数会被调用,将 initramfs 加载到内存中来。
当这些事情做完之后,grub_command_execute (“boot”, 0, 0) 才开始真正地启动内核。
5.3 总结
BIOS->引导扇区boot.img->diskboot.img->lzma_decompress.img(实模式到保护模式、建立分段分页、打开地址线)->kernel.img(选择某个操作系统)->启动内核
6 内核初始化
从实模式切换到了保护模式,有了更强的寻址能力后,就开始启动内核
内核的启动从入口函数 start_kernel() 开始;
在 init/main.c 文件中,start_kernel 相当于内核的main 函数;
打开这个函数,你会发现,里面是各种各样初始化函数 XXXX_init,用来初始化子系统:
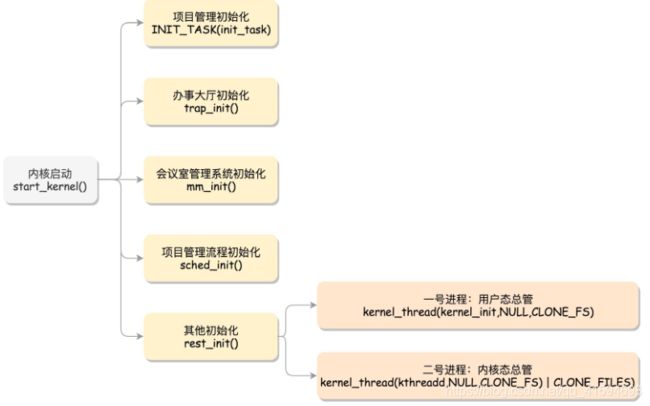
6.1 初始化子系统
6.1.1 进程管理子系统:INIT_TASK(init_task)
首先是进程管理子系统。
将来肯定要运行各种各样的进程,因此,进程管理体系和进程管理流程首先要建立起来。
在操作系统里面,先要有个创始进程;
有一行指令 set_task_stack_end_magic(&init_task),这里面有一个参数 init_task,它的定义是
struct task_struct init_task = INIT_TASK(init_task);
它是系统创建的第一个进程,我们称为0 号进程;
这是唯一一个没有通过 fork 或者 kernel_thread 产生的进程,是进程列表的第一个。
进程列表(Procese List):进程管理工具,里面列着我们所有运行的进程。
6.1.2 系统调用:trap_init()
第二个要初始化的就是系统调用。
有了系统调用,我们就可以响应进程的需求。
这里面对应的函数是 trap_init(),里面设置了很多中断门(Interrupt Gate),用于处理各种中断;
其中有一个 set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32),这是系统调用的中断门;
系统调用也是通过发送中断的方式进行的。当然,64 位的有另外的系统调用方法
6.1.3 内存管理系统:mm_init()、sched_init()
mm_init() 用来初始化内存管理模块。
进程需要进程管理进行调度,需要执行一定的调度策略;
sched_init() 就是用于初始化调度模块。
vfs_caches_init() 会用来初始化基于内存的文件系统 rootfs。在这个函数里面,会调用 mnt_init()-init_rootfs();
这里面有一行代码:register_filesystem(&rootfs_fs_type);
在 VFS 虚拟文件系统里面注册了一种类型,定义为 struct file_system_type rootfs_fs_type;
文件系统是我们的进程资料库,为了兼容各种各样的文件系统,我们需要将文件的相关数据结构和操作抽象出来,形成一个抽象层对上提供统一的接口,这个抽象层就是 VFS(Virtual FileSystem),虚拟文件系统。
6.1.4 其他初始化:rest_init()
最后,start_kernel() 调用的是 rest_init(),用来做其他方面的初始化,这里面做了好多的工作。
6.1.4.1 初始化1号进程
rest_init 的第一大工作是,用 kernel_thread(kernel_init, NULL, CLONE_FS) 创建第二个进程,这个是1 号进程。
1 号进程对于操作系统来讲,有“划时代”的意义。因为它将运行一个用户进程;
这意味着这个操作系统可以把程序交付他人完成;
比喻:这个 1 号进程就相当于老板带了一个大徒弟,有了第一个,就有第二个;后面大徒弟开枝散叶,也能带很多徒弟,形成一棵进程树。
一旦有了用户进程,公司的运行模式就要发生一定的变化;
因为原来只有操作系统,所有东西都是私有的,无论多么关键的资源,第一,不会有人给你抢,第二,不会有人恶意破坏、恶意使用。
但是现在有了其他进程,就要开始做一定的区分,哪些是核心资源,哪些是非核心资源;
内存也要分开,哪些是普通的进程能够访问的,哪些是能够访问核心资源的
x86 提供了分层的权限机制,把区域分成了四个 Ring,越往里权限越高,越往外权限越低:
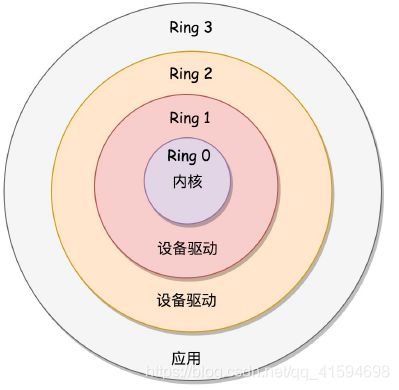
操作系统很好地利用了这个机制:
将能够访问关键资源的代码放在 Ring0,我们称为内核态(Kernel Mode);
将普通的程序代码放在 Ring3,我们称为用户态(User Mode)。
现在系统已经处于保护模式,保护模式除了可访问空间大一些,还有另一个重要功能,就是“保护”;
也就是说,当处于用户态的代码想要执行更高权限的指令,这种行为是被禁止的,要防止他们为所欲为。
那如果用户态的代码想要访问核心资源,怎么办呢?系统调用是统一的入口,用户态代码在这里请求就行;
系统调用后面就是内核态,用户态代码不用管后面发生了什么,做完了返回结果就可以了。
当一个用户态的程序运行到一半,要访问一个核心资源,例如访问网卡发一个网络包,就需要暂停当前的运行,调用系统调用,接下来就轮到内核中的代码运行了;
首先,内核将从系统调用传过来的包,在网卡上排队,轮到的时候就发送。发送完了,系统调用就结束了,返回用户态,让暂停运行的程序接着运行。
这个暂停怎么实现呢?其实就是把程序运行到一半的情况保存下来。
例如,我们知道,内存是用来保存程序运行时候的中间结果的,现在要暂时停下来,这些中间结果不能丢,因为再次运行的时候,还要基于这些中间结果接着来;
另外就是,当前运行到代码的哪一行了,当前的栈在哪里,这些都是在寄存器里面的。
所以,暂停的那一刻,要把当时 CPU 的寄存器的值全部暂存到一个地方,这个地方可以放在进程管理系统很容易获取的地方;
当系统调用完毕,返回的时候,再从这个地方将寄存器的值恢复回去,就能接着运行了:
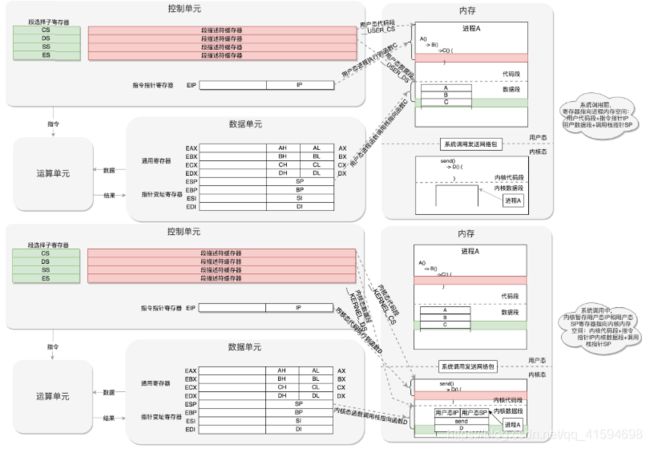
这个过程就是这样的:用户态 - 系统调用 - 保存寄存器 - 内核态执行系统调用 - 恢复寄存器 - 返回用户态,然后接着运行:

- 从内核态到用户态
再回到 1 号进程启动的过程。
当前执行 kernel_thread 这个函数的时候,我们还在内核态。
那么如何跨越这道屏障,到用户态去运行一个程序呢?很少听说“先内核态再用户态”的,如何实现?
kernel_thread 的参数是一个函数 kernel_init,也就是这个进程会运行这个函数;
在 kernel_init里面,会调用 kernel_init_freeable();
从 kernel_init可以看到,1 号进程运行的是一个文件,调用的是do_execve(它的作用是运行一个执行文件。加一个 do_ 的往往是内核系统调用的实现,即do_execve就是一个系统调用),它会尝试运行 ramdisk 的“/init”,或者普通文件系统上的“/sbin/init”“/etc/init”“/bin/init”“/bin/sh”。不同版本的 Linux 会选择不同的文件启动,但是只要有一个起来了就可以。
如何利用执行 init 文件的机会,从内核态回到用户态呢?
从系统调用的过程可以得到启发:“用户态 - 系统调用 - 保存寄存器 - 内核态执行系统调用 -恢复寄存器 - 返回用户态”,然后接着运行。
而刚才运行 init 文件,会调用 do_execve,所以会从内核态执行系统调用开始。
然后会加载这个程序的二进制文件,它是有一定格式的。Linux 下一个常用的格式是ELF(Executable and Linkable Format,可执行与可链接格式);
加载过程中,保存用户态寄存器信息:将用户态的代码段 CS 设置为 __ USER_CS、用户态的数据段 DS 设置为 __USER_DS,以及指令指针寄存器 IP、栈指针寄存器SP。
最终从系统调用中返回:CS和指令指针寄存器 IP 恢复了,指向用户态下一个要执行的语句;
DS 和函数栈指针 SP 也被恢复了,指向用户态函数栈的栈顶。
所以,下一条指令,就从用户态开始运行了。
- ramdisk
系统调用时,init从内核到用户态了;
一开始到用户态的是 ramdisk 的 init,后来会启动真正根文件系统上的 init,成为所有用户态进程的祖先。
ramdisk是一个基于内存的文件系统
出现的原因:
因为 init 程序是在文件系统上的,文件系统一定是在一个存储设备上的,例如硬盘;
Linux 访问存储设备,要有驱动才能访问;
如果存储系统数目很有限,那驱动可以直接放到内核里面,因为前面我们加载过内核到内存里了(初始化子系统时),现在可以直接对存储系统进行访问。
但是存储系统越来越多了,如果所有市面上的存储系统的驱动都默认放进内核,内核就太大了。这该怎么办呢?
可以先弄一个基于内存的文件系统;
内存访问是不需要驱动的,这个基于内存的文件系统就是 ramdisk。
这个时候,ramdisk 是根文件系统。
然后,我们开始运行 ramdisk 上的 /init,等它运行完了就已经在用户态了;
/init 这个程序会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了;
有了真正的根文件系统,ramdisk 上的 /init 会启动文件系统上的 init。
接下来就是各种系统的初始化。启动系统的服务,启动控制台,用户就可以登录进来了。
此时rest_init 的第一个大事情完成,形成了用户态所有进程的祖先。
6.1.4.2 创建2号进程
用户态的所有进程都有祖宗进程了,那内核态的进程有没有一个人统一管起来呢?
有的,rest_init第二大事情就是创建第三个进程,就是 2 号进程。
kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES) :这里又一次使用 kernel_thread 函数创建
进程。
这里需要指出一点,函数名 thread 可以翻译成“线程”,这也是操作系统很重要的一个概念。
它和进程有什么区别呢?为什么这里创建的是进程,函数名却是线程呢?
从用户态来看,创建进程其实就是立项,也就是启动一个项目。这个项目包含很多资源,例如内存空间、磁盘文件等;
这些东西都属于这个进程,但是这个进程需要人去执行;
有多个人并行执行不同的部分,这就叫多线程(Multithreading);
如果只有一个人,那它就是这个项目的主线程。
但是从内核态来看,无论是进程,还是线程,我们都可以统称为任务(Task),都使用相同的数据结构,平放在同一个链表中。
这里的函数 kthreadd,负责所有内核态的线程的调度和管理,是内核态所有线程运行的祖先。
这下用户态和内核态都有人管了,可以开始运行程序了。
6.2 总结
内核的初始化过程,主要做了以下几件事情:
1.各个子系统的创建
2.用户态祖先进程的创建
3.内核态祖先进程的创建

7 系统调用
内核初始化完成后,系统进入了用户态,可以开始运行程序了。
本节解析系统调用子系统的实现原理,因为后面介绍的每一个模块,都涉及系统调用。站在系统调用的角度,层层深入下去,就能从某个系统调用的场景出发,了解内核中各个模块的实现机制。
如果觉得系统调用还是不够方便,Linux 还提供了 glibc 这个中介;
它更熟悉系统调用的细节,并且可以封装成更加友好的接口,可以直接使用。
7.1 glibc 对系统调用的封装
以最常用的系统调用 open,打开一个文件为线索来学习系统调用,看看从 glibc 如何调用到内核的 open。
在 glibc 的源代码中,有个文件 syscalls.list,里面列着所有 glibc 的函数对应的系统调用。
另外,glibc 还有一个脚本 make-syscall.sh,可以根据 syscalls.list,对于每一个封装好的系统调用,生成一个文件;
这个文件里面定义了一些宏,例如 #define SYSCALL_NAME open;
glibc 还有一个文件 syscall-template.S,使用 上面的#define SYSCALL_NAME open 宏,定义了这个系统调用的调用方式。
syscall-template.S里的PSEUDO 也是一个宏;
里面对于任何一个系统调用,会调用 DO_CALL。
DO_CALL这也是一个宏,这个宏 32 位和 64 位的定义是不一样的。
7.2 32位系统的调用过程
- 概述
32位的情况可看i386 目录下的 sysdep.h 文件:将请求参数放在寄存器里面,根据系统调用的名称,得到系统调用号,放在寄存器eax 里面,然后执行 ENTER_KERNEL。
ENTER_KERNEL:触发一个软中断,通过它就可以陷入(trap)内核。
在内核启动的时候初始化系统调用时,使用的是trap_init(),其中有一个方法是软中断的陷入门:
set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32);
当接收到一个系统调用的时候,entry_INT80_32 就被调用了;
entry_INT80_32会通过 push 和 SAVE_ALL 将当前用户态的寄存器,保存在 pt_regs 结构里面,即进入内核之前,保存所有的寄存器;
然后调用 do_syscall_32_irqs_on:
将系统调用号从 eax 里面取出来,然后根据系统调用号,在系统调用表中找到相应的函数进行调用,并将寄存器中保存的参数取出来,作为函数参数。
当系统调用结束之后,即在 entry_INT80_32 之后,紧接着调用的是 INTERRUPT_RETURN;
它的定义,也就是 iret;
iret 指令将原来用户态保存的现场恢复回来,包含代码段、指令指针寄存器等。这时候用户态进程恢复执行。
- 总结

7.3 64 位系统调用过程
- 概述
64位的情况可看x86_64 下的 sysdep.h 文件:和之前一样,还是将系统调用名称转换为系统调用号,放到寄存器 rax;
这里是真正进行调用,不是用中断了,即改用syscall指令;
而且传递参数的寄存器也变了。
syscall 指令还使用了一种特殊的寄存器,我们叫特殊模块寄存器(Model Specific Registers,简称 MSR);
这种寄存器是 CPU 为了完成某些特殊控制功能为目的的寄存器,其中就有系统调用。
在系统初始化的时候,trap_init 除了初始化上面的中断模式,这里面还会调用 cpu_init->syscall_init;
cpu_init->syscall_init里有这样的代码:
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);
rdmsr 和 wrmsr 是用来读写特殊模块寄存器的,MSR_LSTAR 就是一个特殊模块寄存器;
当syscall 指令调用的时候,会从这个寄存器里面拿出函数地址来调用,也就是调用entry_SYSCALL_64。
entry_SYSCALL_64先保存了很多寄存器到 pt_regs 结构里面,例如用户态的代码段、数据段、保存参数的寄存
器,然后调用 entry_SYSCALL64_slow_pat->do_syscall_64。
在 do_syscall_64 里面,从 rax 里面拿出系统调用号,然后根据系统调用号,在系统调用表sys_call_table 中找到相应的函数进行调用,并将寄存器中保存的参数取出来,
所以,无论是 32 位,还是 64 位,都会到系统调用表 sys_call_table 这里来。
- 总结+与32对比(左64,右32)
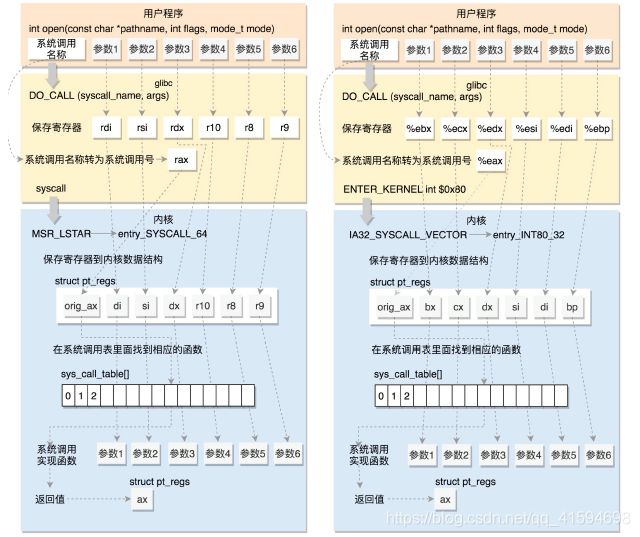
7.4 系统调用表
在研究系统调用表之前,我们看 64 位的系统调用返回的时候,执行的是 USERGS_SYSRET64。定
义如下:
#define USERGS_SYSRET64 \
swapgs; \
sysretq;
这里,返回用户态的指令变成了 sysretq。
接下来开始分析
不管是32位还是64位方式的系统调用,最终都是到了系统调用表;
但是到底调用内核的什么函数呢??系统调用表 sys_call_table 是怎么形成的呢?
32 位的系统调用表定义在 arch/x86/entry/syscalls/syscall_32.tbl 文件里;(问题2)
64 位的系统调用表定义在arch/x86/entry/syscalls/syscall_64.tbl 里:
第一列的数字是系统调用号,32 位和 64 位的系统调用号是不一样的;
第三列是系统调用的名字;
第四列是系统调用在内核的实现函数,都是以 sys_ 开头。
系统调用在内核中的实现函数要有一个声明;
声明往往在 include/linux/syscalls.h 文件中:32位为syscalls_32.h,64位为syscalls_64.h
真正的实现这个系统调用,一般在一个.c 文件里面,例如 sys_open 的实现在 fs/open.c 里面
此时,声明和实现都完成了。
接下来,在编译的过程中,需要根据 syscall_32.tbl 和 syscall_64.tbl 生成自己的 unistd_32.h 和 unistd_64.h;
生成方式在 arch/x86/entry/syscalls/Makefile 中;
这里面会使用两个脚本:
第一个脚本 arch/x86/entry/syscalls/syscallhdr.sh,会在文件中生成 #define __NR_open;
第二个脚本 arch/x86/entry/syscalls/syscalltbl.sh,会在文件中生成__SYSCALL(__NR_open, sys_open);
这样,unistd_32.h 和 unistd_64.h 就是对应的系统调用号和系统调用实现函数之间的对应关系(答问题1)。
在文件 arch/x86/entry/syscall_32.c,定义了这样一个表:里面 include 了头文件syscalls_32.h ,从而所有的32位 sys_ 系统调用都在这个表里面了;
同理,在文件 arch/x86/entry/syscall_64.c,定义了这样一个表,里面 include 了头文件syscalls_64.h,这样所有的64位 sys_ 系统调用就都在这个表里面了。
7.5 总结
重点分析 64 位的系统调用:
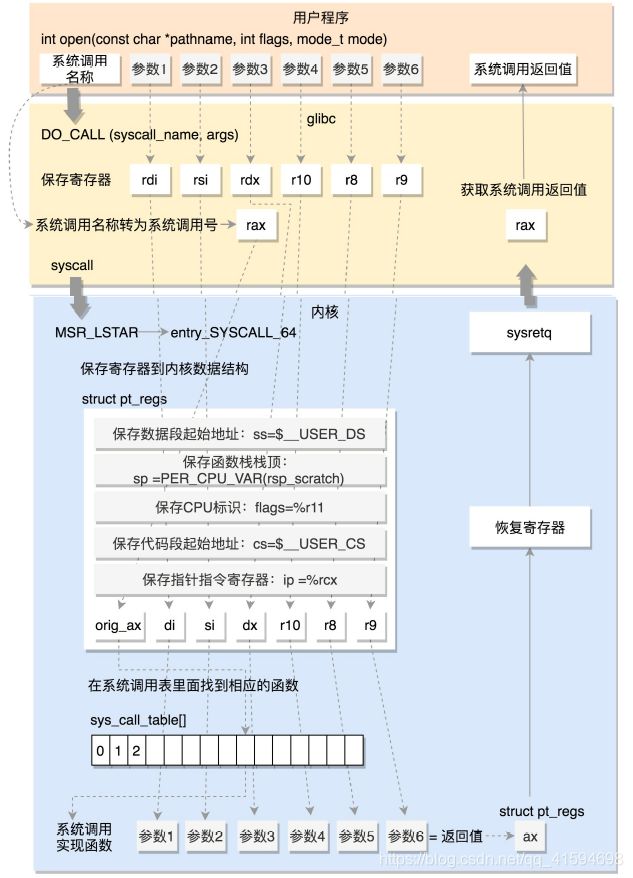
本质就是使用寄存器保存数据,调用到内核的函数,最后还是通过寄存器返回原先的位置,带上调用的结果