springboot mybatis 事务_MyBatis的一级缓存竟然还会引来麻烦?
端午假期相信不少小伙伴都在偷偷学习吧(说好了放假一起玩耍呢,结果又背着我学习),这不,刚过了端午,我的一个沙雕程序猿圈子里就有人讨论起来问题了,这个问题聊起来好像挺麻烦,但实际上问题是很简单的,下面咱来讨论下这个问题。
原问题
MyBatis 一级缓存与 SpringFramework 的声明式事务有冲突吗?在 Service 中开启事务,连续查询两次同样的数据,结果两次查询的结果不一致。
—— 使用 Mapper 的 selectById 查出来实体,然后修改实体的属性值,然后再 selectById 一下查出来实体,对比一下之前查出来的,发现查出来的是刚才修改过的实体,不是从数据库查出来的。
—— 如果不开启事务,则两次请求查询的结果是相同的,控制台打印了两次 SQL 。
初步分析
讲道理,看到这个问题,我一下子就猜到是 MyBatis 一级缓存重复读取的问题了。
MyBatis 的一级缓存默认开启,属于 SqlSession 作用范围。在事务开启的期间,同样的数据库查询请求只会查询一次数据库,之后重复查询会从一级缓存中获取。当不开启事务时,同样的多次数据库查询都会发送数据库请求。
上面的都属于基础知识了,不多解释。重点是,他修改的实体是直接从 MyBatis 的一级缓存中查询出来的。咱都知道,查询出来的这些实体肯定属于对象,拿到的是对象的引用,咱在 Service 里修改了,一级缓存中相应的也就会被影响。由此可见,这个问题的核心原因也就很容易找到了。
问题复现
为了展示这个问题,咱还是简单复现一下场景吧。
工程搭建
咱使用 SpringBoot + mybatis-spring-boot-starter 快速构建出工程,此处 SpringBoot 版本为 2.2.8 ,mybatis-spring-boot-starter 的版本为 2.1.2 。
pom
核心的 pom 依赖有 3 个:
org.springframework.boot spring-boot-starter-weborg.mybatis.spring.boot mybatis-spring-boot-starter 2.1.2com.h2database h2 1.4.199复制代码数据库配置
数据库咱们依然选用 h2 作为快速问题复现的数据库,只需要在 application.properties 中添加如下配置,即可初始化一个 h2 数据库。顺便的,咱把 MyBatis 的配置也简单配置好:
spring.datasource.driver-class-name=org.h2.Driverspring.datasource.url=jdbc:h2:mem:mybatis-transaction-cachespring.datasource.username=saspring.datasource.password=saspring.datasource.platform=h2spring.datasource.schema=classpath:sql/schema.sqlspring.datasource.data=classpath:sql/data.sqlspring.h2.console.settings.web-allow-others=truespring.h2.console.path=/h2spring.h2.console.enabled=truemybatis.type-aliases-package=com.linkedbear.demo.entitymybatis.mapper-locations=classpath:mapper/*.xml复制代码初始化数据库
上面咱使用了 datasource 的 schema 和 data 初始化数据库,那自然的就应该有这两个 .sql 文件。
schema.sql :
create table if not exists sys_department ( id varchar(32) not null primary key, name varchar(32) not null);复制代码data.sql :
insert into sys_department (id, name) values ('idaaa', 'testaaa');insert into sys_department (id, name) values ('idbbb', 'testbbb');insert into sys_department (id, name) values ('idccc', 'testccc');insert into sys_department (id, name) values ('idddd', 'testddd');复制代码编写测试代码
咱使用一个最简单的单表模型,快速复现场景。
entity
新建一个 Department 类,并声明 id 和 name 属性:
public class Department { private String id; private String name; // getter setter toString ......}复制代码mapper
MyBatis 的接口动态代理方式可以快速声明查询的 statement ,咱只需要声明一个 findById 即可:
@Mapperpublic interface DepartmentMapper { Department findById(String id);}复制代码mapper.xml
对应的,接口需要 xml 作为照应:(此处并没有使用注解式 Mapper )
select * from sys_department where id = #{id} 复制代码service
Service 中注入 Mapper ,并编写一个需要事务的 update 方法,模拟更新动作:
@Servicepublic class DepartmentService { @Autowired DepartmentMapper departmentMapper; @Transactional(rollbackFor = Exception.class) public Department update(Department department) { Department temp = departmentMapper.findById(department.getId()); temp.setName(department.getName()); Department temp2 = departmentMapper.findById(department.getId()); System.out.println("两次查询的结果是否是同一个对象:" + temp == temp2); return temp; }}复制代码controller
Controller 中注入 Service ,并调用 Service 的 update 方法来触发测试:
@RestControllerpublic class DepartmentController { @Autowired DepartmentService departmentService; @GetMapping("/department/{id}") public Department findById(@PathVariable("id") String id) { Department department = new Department(); department.setId(id); department.setName(UUID.randomUUID().toString().replaceAll("-", "")); return departmentService.update(department); }}复制代码主启动类
主启动类中不需要什么特别的内容,只需要记得开启事务就好:
@EnableTransactionManagement@SpringBootApplicationpublic class MyBatisTransactionCacheApplication { public static void main(String[] args) { SpringApplication.run(MyBatisTransactionCacheApplication.class, args); }}复制代码运行测试
以 Debug 方式运行 SpringBoot 的主启动类,在浏览器中输入 http://localhost:8080/h2 输入刚才在 application.properties 中声明的配置,即可打开 h2 数据库的管理台。
执行 SELECT * FROM SYS_DEPARTMENT ,可以发现数据已经成功初始化了:
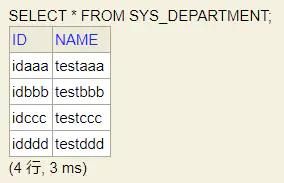
image.png
下面测试效果,在浏览器中输入 http://localhost:8080/department/idaaa ,控制台中打印的结果为 true,证明 MyBatis 的一级缓存生效,两次查询最终得到的实体类对象一致。
解决方案
对于这个问题的解决方案,其实说白了,就是关闭一级缓存。最常见的几种方案列举一下:
- 全局关闭:设置 mybatis.configuration.local-cache-scope=statement
- 指定 mapper 关闭:在 mapper.xml 的指定 statement 上标注 flushCache="true"
- 另类的办法:在 statement 的 SQL 上添加一串随机数(过于非主流。。。)select * from sys_department where #{random} = #{random}
原理扩展
其实到这里,问题就已经解决了,但先不要着急,思考一个问题:为什么声明了 local-cache-scope 为 statement ,或者mapper 的 statement 标签中设置 flushCache=true ,一级缓存就被禁用了呢?下面咱来了解下这背后的原理。
一级缓存失效的原理
在 DepartmentService 中,执行 mapper.findById 的动作,最终会进入到 DefaultSqlSession 的 selectOne中:
public T selectOne(String statement) { return this.selectOne(statement, null);}@Overridepublic T selectOne(String statement, Object parameter) { // Popular vote was to return null on 0 results and throw exception on too many. List list = this.selectList(statement, parameter); if (list.size() == 1) { return list.get(0); } else if (list.size() > 1) { throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size()); } else { return null; }}复制代码可见 selectOne 的底层是调用的 selectList ,之后 get(0) 取出第一条数据返回。
selectList 的底层会有两个步骤:获取 MappedStatement → 执行查询,如下代码中的 try 部分:
public List selectList(String statement, Object parameter, RowBounds rowBounds) { try { MappedStatement ms = configuration.getMappedStatement(statement); return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); }}复制代码执行 query 方法,来到 BaseExecutor 中,它会执行三个步骤:获取预编译的 SQL → 创建缓存键 → 真正查询。
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameter); CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); return query(ms, parameter, rowBounds, resultHandler, key, boundSql);}复制代码这里面的缓存键是有一定设计的,它的结构可以简单的看成 “ statementId + SQL + 参数 ” 的形式,根据这三个要素,就可以唯一的确定出一个查询结果。
到了这里面的 query 方法,它就带着这个缓存键,执行真正的查询动作了,如下面的这段长源码:(注意看源码中的注释)
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } // 如果statement有设置flushCache="true",则查询之前先清理一级缓存 if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List list; try { queryStack++; // 先检查一级缓存 list = resultHandler == null ? (List) localCache.getObject(key) : null; if (list != null) { // 如果一级缓存中有,则直接取出 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { // 一级缓存没有,则查询数据库 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } if (queryStack == 0) { for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } // issue #601 deferredLoads.clear(); // 如果全局配置中有设置local-cache-scope=statement,则清除一级缓存 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { // issue #482 clearLocalCache(); } } return list;}复制代码上面的注释中,可以发现,只要上面的三个解决方案,任选一个配置,则一级缓存就会失效,分别分析下:
- 全局设置 local-cache-scope=statement ,则查询之后即便放入了一级缓存,但存放完立马就给清了,下一次还是要查数据库;
- statement 设置 flushCache="true" ,则查询之前先清空一级缓存,还是得查数据库;
- 设置随机数,如果随机数的上限足够大,那随机到相同数的概率就足够低,也能类似的看成不同的数据库请求,那缓存的 key 都不一样,自然就不会匹配到缓存。