python爬虫
爬虫面试题汇总
一.项目问题:
1.你写爬虫的时候都遇到过什么反爬虫措施,你最终是怎样解决的
1.你写爬虫的时候都遇到过什么反爬虫措施,你最终是怎样解决的
通过headers反爬虫:解决策略,伪造headers
基于用户行为反爬虫:动态变化去爬取数据,模拟普通用户的行为, 使用IP代理池爬取或者降低抓取频率,或 通过动态更改代理ip来反爬虫
基于动态页面的反爬虫:跟踪服务器发送的ajax请求,模拟ajax请求,selnium
和phtamjs。或 使用selenium + phantomjs 进行抓取抓取动态数据,或者找到动态数据加载的json页面。
验证码 :使用打码平台识别验证码
数据加密:对部分数据进行加密的,可以使用selenium进行截图,使用python自带的pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。
2.你写爬虫的时候 使用的什么框架 选择这个框架的原因是什么?
scrapy。
优势:
可以实现高并发的爬取数据, 注意使用代理;
提供了一个爬虫任务管理界面, 可以实现爬虫的停止,启动,调试,支持定时爬取任务;
代码简洁
劣势:
1.可扩展性不强。
2.整体上来说: 一些结构性很强的, 定制性不高, 不需要太多自定义功能时用pyspider即可, 一些定制性高的,需要自定义一 些 功能时则使用Scrapy。
二.scrapy框架专题部分(很多面试都会涉及到这部分)
(1)请简要介绍下scrapy框架。
(2)为什么要使用scrapy框架?scrapy框架有哪些优点?
(3)scrapy框架有哪几个组件/模块?简单说一下工作流程。
4.scrapy的去重原理(指纹去重到底是什么原理)
5.scrapy中间件有几种类,你用过哪些中间件*
6.scrapy中间件再哪里起的作用7,scrapy实现分布式抓取简单点来说8,分布式的去重原理9,海量数据的去重原理
三.代理问题:
1.为什么会用到代理
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会会禁止这个IP的访问。所以我们需要设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
2.代理怎么使用(具体代码, 请求在什么时候添加的代理)
3.代理失效了怎么处理
事先用检测代码检测可用的代理,每隔一段时间更换一次代理,如果出现302等状态码,则立即更换下一个可用的IP。
四.验证码处理:
1.登陆验证码处理
图片验证码:先将验证码图片下载到本地,然后使用云打码识别;
滑动验证码:使用selenium模拟人工拖动,对比验证图片的像素差异,
*2.爬取速度过快出现的验证码处理
设置setting.py中的DOWNLOAD_DELAY,降低爬取速度;
用xpath获取验证码关键字,当出现验证码时,识别验证码后再继续运行。
3.如何用机器识别验证码**
对接打码平台
对携带验证码的页面数据进行抓取
将页面中的验证码进行解析, 将验证码图片下载到本地
将验证码图片提交给打码平台进行识别, 返回识别后的结果
云打码平台使用:
1.爬虫:自动的抓取互联网上信息的脚本文件。
2.爬虫可以解决的问题:
(1)解决冷启动问题
(2)搜索引擎的根基:做搜索引擎少不了爬虫
(3)建立知识图谱,帮助建立机器学习知识图谱
(4)可以制作各种商品的比价软件,趋势分析。
3.爬虫分类
(1)通用爬虫:搜索引擎的主要组成,作用就是将互联网的上页面整体的爬取下来之后,保存到本地。
(2)聚焦爬虫:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。通用爬虫和聚焦爬虫的区别:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
4.爬虫遵循的协议:robot协议
定义:网络爬虫排除标准。
作用:告诉搜索引擎哪里可以爬,哪里不可以爬。
5.通用爬虫工作流程
(1)抓取网页:通过搜索引擎将待爬取的url加入到通用爬虫的url队列中,进行网页内容的爬取
(2)数据存储:将爬取下来的网页保存到本地,这个过程会有一定的去重操作,如果某个网页的内 容大部分内容都会重复,搜索引擎可能不会保存。
(3)预处理:提取文字,中文分词,消除噪音(比如版权声明文字,导航条,广告等)。
(4)设置网站排名,为用户提供服务。
6.一些反爬及其应对措施
( 1)通过user-agent来判断是否是爬虫。
解决方案:可以通过伪装请求头中的user-agent来解决。若user-agent被检测到,可以找大量的user-agent,放入列表,然后进行更换
(2)将IP进行封杀。
解决方案:可以通过代理来伪装IP。
(3)通过访问频率来判断是否是一个爬虫。
解决方案:可以通过设置请求间隔,和爬取间隔。
(4)当一定时间内的总请求数超过上限,弹出验证码。
解决方案:对于简单的验证码图片可以使用tesseract来处理,对于复杂的可以去打码平台。
(5)通过JS来获取页面数据。
解决方案:可以使用selenium+phantomjs来加载JS获取数据。
02 介绍搜索引擎
1.搜索引擎的主要组成
通用爬虫:就是将互联网的上页面整体的爬取下来之后,保存到本地。通用爬虫要想爬取网页,需要网站的url.但是搜索引擎是可以搜索所有网页的。那么通用爬虫url就要涉及到所有网页,这个‘所有’是如何做到的:
- 新网站向搜索引擎主动提交网址;
- 在其他网站上设置新网站外链;
- 搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
2.搜索引擎的工作流程(通用爬虫的工作流程)
(1)抓取网页:通过搜索引擎将待爬取的URL加入到通用爬虫的URL队列中,进行网页内容的爬取。
(2)数据存储:将爬取下来的网页保存到本地,这个过程会有一定的去重操作,如果某个网页的内 容大部分内容都会重复,搜索引擎可能不会保存。
(3)预处理:提取文字,中文分词,消除噪音(比如版权声明文字,导航条,广告等)。
(4)设置网站排名,为用户提供服务。
3.搜索引擎的局限性
(1)搜索引擎只能爬取原网页,但是页面90%内容都是无用的。
(2)搜索引擎不能满足不同行业,不同人的特定需求。
(3)通用搜索引擎只能爬取文字信息,不能对音频、图片等进行爬取。
(4)只能基于关键字查询,无法基于语义查询。
03 介绍HTTP
网络七层协议:

1.HTTP协议特点
- HTTP协议是超文本传输协议;
- HTTP协议是一个应用层协议;
- 无连接:每次请求都是独立的;
- 无状态,表示客户端每次请求都不能记录请求状态,就是两条请求直接不可通信。
2.HTTP工作过程
- 地址进行DNS解析,将URL解析出对应的内容
- 封装HTTP请求数据包
- 封装成TCP包,建立TCP连接(TCP的三次握手)
- 客户端发送请求
- 服务器接收请求,发送响应
- 客户端接收到响应,进行页面渲染
- 服务器关闭TCP连接(TCP的四次挥手)
3.HTTP协议和HTTPS协议的区别
- HTTP协议是使用明文数据传输的网络协议,明文传输会让用户存在一个非常大的安全隐患。端口80
- HTTPS协议可以理解为HTTP协议的安全升级版,就是在HTTP的基础上增加了数据加密。端口443
- HTTPS协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议要比HTTP协议安全。
4.HTTP通信
HTTP通信由两部分组成:客户端请求消息与服务器响应消息。
5.关于响应常见的响应码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qsr8yoz2-1668657261409)(img/v2-2ee19f6a9219ce14cc72f80fa0927efd_720w-1668514533172.webp)]
6.客户端请求(Get和Post区别)
(1)组成:请求行、请求头部、空行、请求数据四个部分组成
(2)请求方法Get/Post
(3)Get和Post的区别GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pHhp6KOP-1668657261409)(img/v2-523b6efc9610675e76405106e75bc817_720w-1668514533175.webp)]
(4)常见的请求头
User-Agent:客户端请求标识
Accept:传输文件类型。Referer :请求来源
cookie (cookie):在做登录的时候需要封装这个头
Content-Type (POST数据类型)
7.服务器响应
(1)组成:状态行,响应头,空行,响应正文。
(2)常见的响应头
Content-Type:text/html;资源文件的类型,还有字符编码
Content-Length:响应长度
Content-Size响应大小
Content-Encoding告诉客户端,服务端发送的资源是采用什么编码的
Connection:keep-alive这个字段作为回应客户端的
Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个TCP连接发送HTTP请求。
04 URL
统一资源定位符:
基本格式:scheme://host[:port#]/path/…/?query-string
协议://服务器ip地址:端口号/资源路径/?key1=参数1&key2=参数2
scheme:协议(例如:HTTP、HTTPS、FTP)
host/IP:服务器的IP地址或者域名
port:服务器的端口(如果是走协议默认端口,缺省端口80),用来从互联网进入电脑
path:访问资源的路径,就是为了在电脑中找到对应的资源路径
query-string:参数,发送给http服务器的数据
anchor:锚(跳转到网页的指定锚点位置)
Q:当我们在浏览器输入一个URL,为什么可以加载出一个页面?为什么抓包的过程中请求一个URL,出现很多的资源请求?
当我们在浏览器输入一个URL,客户端会发送这个URL对应的一个请求到服务器获取内容。服务器收到这个请求,解析出对应内容,之后将内容封装到响应里发送到客户端
当客户端拿到这个HTML页面,会查看这个页面中是否有CSS、JS、image等URL,如果有,在分别进行请求,获取到这些资源。
客户端会通过HTML的语法,将获取到的所有内容完美的显示出来。
05 Cookie和Session
产生原因:由于HTTP是一个无状态的协议,每次请求如果需要之前的一些信息,无法记录,因此为了解决这个问题,产生了一种记录状态技术,Cookie和Session。
Cookie指某些网站为了辨别用户身份,进行会话跟踪而存储在用户本地终端上的数据,种类有会话Cookie和持久Cookie。
(1)会话Cookie指存在浏览器内存的Cookie,当浏览器关闭,会话Cookie会失效;
(2)持久Cookie是保存在硬盘上的Cookie。
Session用来存储特定的用户会话所需的属性及其配置信息。
Cookie是在客户端记录状态,Session是在服务端记录状态。
联系:当客户端发送一个Cookie,服务器会从这个Cookie中找到sessionID,再查找出相应的Session信息返回给客户端,来进行用户页面的流转。如果通过sessionID来查找Session的时候,发现没有Session(一般第一次登陆或者清空了浏览器),那么就会创建一个Session。
06 hashlib密码加密
def get_hex(value):
md5_ = hashlib.md5()
md5_.update(value.encode('utf-8'))
return md5_.hexdigest()
07 关于response.text乱码问题
response的常用属性:
1.获取字符串类型的响应正文:response.text
2.获取bytes类型的响应正文:response.content
3.响应正文字符串编码:response.encoding
4.状态码:response.status_code5.响应头:response.headers
response.text乱码问题:
#方法一:转换成utf-8格式
response.encoding='utf-8'
print(response.text)
#方法二:解码为utf-8 :
with open('index.html','w',encoding='utf-8') as fp: fp.write(response.content.decode('utf-8'))
08 代理
代理的作用:
1、突破自身IP 访问限制, 访问一些平时不能访问的站点。
2、访问一些单位或团体内部资源:比如使用教育网内地址段免费代理服务器, 就可以用于对教育网开放的各类FTP 下载上传, 以及各类资料查询共享等服务。
3、提高访问速度:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时, 同时也将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区中取屮信息传给用户,以提高访问速度。
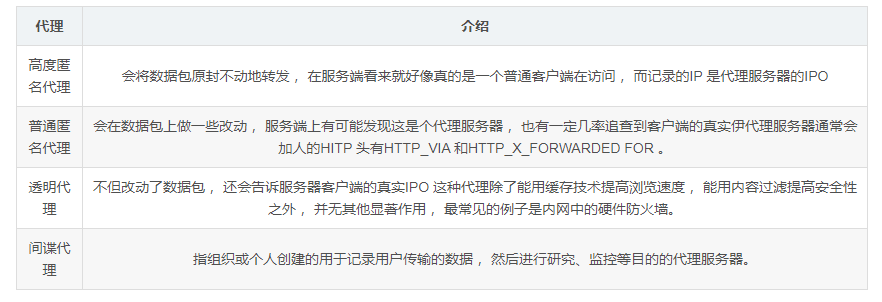
4、隐藏真实IP :上网者也可以通过这种方法隐藏自己的IP , 免受攻击。对于爬虫来说, 我们用代理就是为了隐藏自身IP , 防止自身的被封锁。代理根据匿名程度的分类:
09 JSON数据
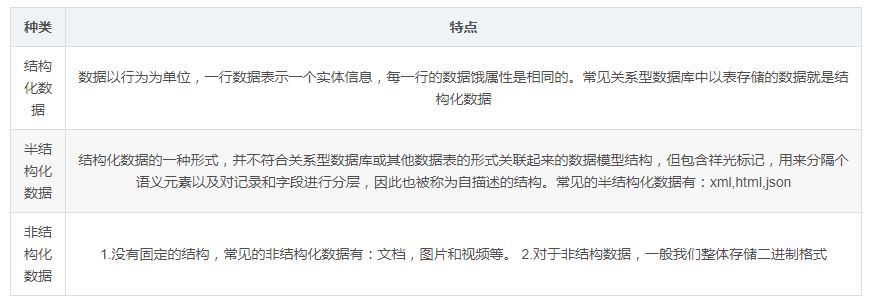
数据的分类:
JSON的本质:是一个字符串,JSON是对JS对象的字符串表达式,它使用文本形式表示一个JS对象的信息。
JSON使用:
(1)json.dumps(Python的list或者dict),将Python的list或者dict返回为一个JSON字符串;
(2)json.loads(json字符串),将JSON字符串返回为Python的list或者dict;
(3)json.dump(list/dict,fp),将Python的list或者dict转为一个JSON字符串,保存到文件中;
(4)json.load(fp) ,从JSON文件中读出JSON数据,并转换为Python的list或者dict。
10 正则表达式
1、贪婪和非贪婪
(1)正则默认是贪婪模式,所以数量控制符默认是取最大值,也是贪婪。例如*
(2)非贪婪是用?来控制,尽量匹配最少的次数,0次或一次。2、Python使用格式:
pattern=re.compile('正则表达式')
print(pattern.match(字符串,start,end))#默认从头开始匹配,只匹配一次,返回一个match对象
print(pattern.search(字符串,start,end))#从任意位置开始匹配,只匹配一次,返回一个match对象
print(pattern.findall(字符串,start,end))#全文多次匹配,将匹配到的结果放到一个list返回给我们
print(pattern.finditer(字符串,start,end))#全文多次匹配,将匹配到的结果放到一个match对象的迭代器返回
3、常见的正则题目
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eZzN7NZe-1668657261412)(img/v2-bfb2247d9fe4f4a4592620c746b261f2_720w-1668514533192.webp)]
作者:编程文青李狗蛋
https://www.nowcoder.com/discuss/1031358来源:牛客网
因为 cookie 存在过期的现象,一个很好的处理方法就是做一个异常类,如果有异常的话 cookie 抛出异常类在执行程序。
2、动态加载又对及时性要求很高怎么处理?
Selenium + Phantomjs,尽量不使用 sleep 而使用 WebDriverWait
3、谈一谈你对 Selenium 和 PhantomJS 了解?
Selenium 是一个 Web 的自动化测试工具,可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。Selenium 库里有个叫 WebDriver 的 API。WebDriver 有点儿像可以加载网站的浏览器,但是它也可以像 BeautifulSoup 或者其他 Selector 对象一样用来查找页面元素,与页面上的元素进行交互 (发送文本、点击等),以及执行其他动作来运行网络爬虫。
PhantomJS 是一个基于 Webkit 的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。相比传统的 Chrome 或 Firefox 浏览器等,资源消耗会更少。
如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScript、Cookie、headers,以及任何我们真实用户需要做的事情。
主程序退出后,selenium 不保证 phantomJS 也成功退出,最好手动关闭 phantomJS 进程。(有可能会导致多个 phantomJS 进程运行,占用内存)。
WebDriverWait 虽然可能会减少延时,但是目前存在 bug(各种报错),这种情况可以采用 sleep。phantomJS 爬数据比较慢,可以选择多线程。如果运行的时候发现有的可以运行,有的不能,可以尝试将 phantomJS 改成 Chrome。
4、代理 IP 里的“透明”“匿名”“高匿”分别是指?
(1) 透明代理
它的意思是客户端根本不需要知道有代理服务器的存在,但是它传送的仍然是真实的 IP。你要想隐藏的话,不要用这个。
(2) 普通匿名代理
普通匿名代理能隐藏客户机的真实 IP,但会改变我们的请求信息,服务器端有可能会认为我们使用了代理。不过使用此种代理时,虽然被访问的网站不能知道你的 ip 地址,但仍然可以知道你在使用代理,当然某些能够侦测 ip 的网页仍然可以查到你的 ip。
(3) 高匿名代理
高匿名代理不改变客户机的请求,这样在服务器看来就像有个真正的客户浏览器在访问它,这时客户的真实 IP 是隐藏的,服务器端不会认为我们使用了代理。
设置代理有以下两个好处
- 让服务器以为不是同一个客户端在请求
- 防止我们的真实地址被泄露,防止被追究
5、robots 协议有什么用处?
Robots 协议:网站通过 Robots 协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
6、为什么 requests 请求需要带上 header?
原因是:模拟浏览器,欺骗服务器,获取和浏览器一致的内容
header 的形式:字典
headers = {“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36”}
用法: requests.get(url,headers=headers)
7、dumps,loads 与 dump,load 的区别?
json.dumps() 将 pyhton 的 dict 数据类型编码为 json 字符串
json.loads() 将 json 字符串解码为 dict 的数据类型
json.dump(x,y) x 是 json 对象, y 是文件对象,最终是将 json 对象写入到文件中
json.load(y) 从文件对象 y 中读取 json 对象
8、平常怎么使用代理的?
(1) 自己维护代理池
(2) 付费购买(目前市场上有很多 ip 代理商,可自行百度了解,建议看看他们的接口文档(API&SDK))
9、IP 存放在哪里?怎么维护 IP?对于封了多个 ip 的,怎么判定 IP 没被封?
存放在数据库(redis、mysql 等)
维护多个代理网站
一般代理的存活时间往往在十几分钟左右,定时任务,加上代理 IP 去访问网页,验证其是否可用,如果返回状态为 200,表示这个代理是可以使用的。
10、怎么获取加密的数据?
(1) Web 端加密可尝试移动端(app)
(2) 解析加密,看能否破解
(3) 反爬手段层出不穷,js 加密较多,只能具体问题具体分析
11、假如每天爬取量在 5、6 万条数据,一般开几个线程,每个线程 ip 需要加锁限定吗?
(1) 5、6 万条数据相对来说数据量比较小,线程数量不做强制要求(做除法得一个合理值即可)
(2) 多线程使用代理,应保证不在同时一刻使用一个代理 IP
12、怎么监控爬虫的状态?
(1) 使用 python 的 STMP 包将爬虫的状态信心发送到指定的邮箱
(2) Scrapyd、pyspider
(3) 引入日志
)
9、IP 存放在哪里?怎么维护 IP?对于封了多个 ip 的,怎么判定 IP 没被封?
存放在数据库(redis、mysql 等)
维护多个代理网站
一般代理的存活时间往往在十几分钟左右,定时任务,加上代理 IP 去访问网页,验证其是否可用,如果返回状态为 200,表示这个代理是可以使用的。
10、怎么获取加密的数据?
(1) Web 端加密可尝试移动端(app)
(2) 解析加密,看能否破解
(3) 反爬手段层出不穷,js 加密较多,只能具体问题具体分析
11、假如每天爬取量在 5、6 万条数据,一般开几个线程,每个线程 ip 需要加锁限定吗?
(1) 5、6 万条数据相对来说数据量比较小,线程数量不做强制要求(做除法得一个合理值即可)
(2) 多线程使用代理,应保证不在同时一刻使用一个代理 IP
12、怎么监控爬虫的状态?
(1) 使用 python 的 STMP 包将爬虫的状态信心发送到指定的邮箱
(2) Scrapyd、pyspider
(3) 引入日志