【NLP经典论文精读】Language Models are Unsupervised Multitask Learners
Improving Language Understanding by Generative Pre-Training
- 前言
- Abstract
- 1. Introduction
- 2. Approach
-
- 2.1 Training Dataset
- 2.2 Input Representation
- 2.3 Model
- 3. Experiments
-
- 3.1 Language Modeling
- 3.2 Children's Book Test
- 3.3 LAMBADA
- 3.4 Winograd Schema Challenge
- 3.5 Reading Comprehension
- 3.6 Summarization
- 3.7 Translation
- 3.8 Question Answering
- 4. Generalization vs Memorization
- 5. Related Work
- 6. Discussion
- 阅读总结
前言
一篇对我特别有启发的文章,虽然GPT-2的性能不尽如人意,但是其背后的思想还是特别值得学习和借鉴,如果没有GPT-2的出现,可能当今的大模型时代就不会来临。
Paper: https://insightcivic.s3.us-east-1.amazonaws.com/language-models.pdf
Code: https://github.com/openai/gpt-2
Abstract
典型的自然语言理解任务都需要在特定任务下进行监督学习,然而本文证明在百万级别WebText数据集下,模型可以在没有任何显式监督情况下学习任务。语言模型的规模对于zero-shot相当重要,增加它可以以对数线性的方式提高性能。此外,作者还发现能够从自然语言演示中学习任务。
1. Introduction
当前的机器学习系统对数据分布和任务规范敏感,不具有通用能力。作者希望建立一个通用的系统,无需监督数据直接应用到特定的任务。作者认为当前机器学习系统泛化能力差的原因在于仅在单一任务上进行监督训练,因此将目光转向了多任务训练,这是一个有前途的提高模型性能的框架。当前的语言模型最好的系统结合了预训练和微调范式,但是面对特定任务时仍需进行监督训练,因此,本文将这两个工作结合到一起,演示了语言模型在zero-shot设置下执行下游任务,取得了先进的成果。
2. Approach
方法的核心是语言建模,语言建模通常被构建成一组示例 ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn)的无监督分布估计,每个示例可以由可变长度的token序列 ( s 1 , s 2 , . . . , s n ) (s_1,s_2,...,s_n) (s1,s2,...,sn)组成,由于语言具有自然的顺序,因此通常将token上的联合概率分解为条件概率的乘积:
p ( x ) = ∏ i = 1 n p ( s n ∣ s 1 , . . . , s n − 1 ) p(x)=\prod_{i=1}^{n} p(s_n|s_1,...,s_{n-1}) p(x)=i=1∏np(sn∣s1,...,sn−1)
由于通用系统能够执行多个不同任务,因此对于相同的输入,还需要加入任务的条件。由于监督学习与无监督学习目标相同,因此无监督学习的目标也是监督学习目标的全局最小值。无监督学习的问题在于能否通过优化任务目标以实现收敛,通过实验可以证明,足够大的语言模型能够在这种设置下执行多任务学习,但是学习速度比监督学习慢得多。
2.1 Training Dataset
先前的工作都是在单一领域数据集上进行训练,本文的方法鼓励构建尽可能大和多样化的数据集,以便收集尽可能多的领域和上下文中的任务的自然语言演示。
一个有前景的方法是网络抓包,虽然数量级大,但是文本质量低。为此,本文设计了新的网络抓取方式,仅抓取由人类过滤的网页,得到了包含4500万个链接的数据集WebText,经过清洗后,包含超过800万个文档,共40GB文本。为了防止数据泄露,删除了维基百科出现的文本。
2.2 Input Representation
通用的语言模型能够输出所有字符的概率。当前的语言模型需要对数据进行预处理, 包括大小写、分词和词表外单词。虽然将unicode字符串转换为UTF-8字节序列可以满足任何建模要求,但是在大规模数据集上,字符级LM无法与词级LM相提并论。
字节配对编码(BPE)是在字符级和词级语言建模之间的妥协。可以有效地在频繁的符号序列中插入词级输入,并在不频繁的符号序列中插入字符级输入。它基于Unicode实现,基础词表的大小达到了130000个。
但是直接将BPE应用于字符序列并不理想,会导致词表槽位和模型规模不匹配。为了避免这种情况,作者提出一种策略,阻止在字符类别之间合并,让BPE可以更好处理字符序列,从而提高语言模型性能。这种输入表示将词级LM的经验优势(表征能力强)和字符级通用性结合到一起,使得在任何数据集上都可以评估语言模型,无需对数据进行预处理。
2.3 Model
模型部分基于Transformer,层归一化移动到每个子块的输入(之前是输出),类似于预激活残差网络。此外还在最终的自注意力块后添加了额外的层归一化。初始化时将残差层的权重缩放为 1 / N 1/\sqrt{N} 1/N,词表扩大到50257个。
3. Experiments
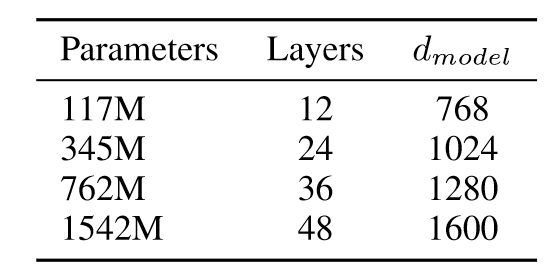
作者在以上四个设置的模型下进行了实验,前两个参数量分别对标GPT和BERT。
3.1 Language Modeling
作为实现零样本学习的第一步,作者想要了解模型如何在预训练语言建模上学习zero-shot能力。许多数据集需要在分布外进行测试,模型需要去预测高标准化的文本,例如标点符号,缩进,甚至未见的单词。
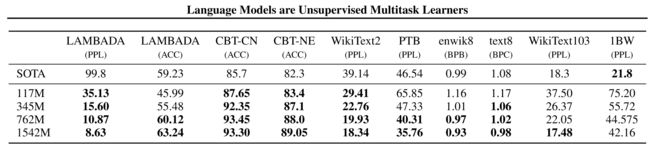
结果如上表所示,通过使用作者的方法,在困惑度上获得了2.5—5的提升,说明采用BPE可以有效提高语言模型的性能。
WebText LM可以很好地跨域和数据集迁移在,在zero-shot设置下提升了8个数据集中的7个的现有水平。其中,在具有长文本依赖的LAMBADA数据集上取得了巨大改进,但是在1BW上表现很差,可能的原因是该数据集删除了所有长程文本结构。
3.2 Children’s Book Test
CBT数据集旨在检查LM在不同类别单词上的表现:命名实体、名词、动词和介词。CBT以完形填空为测试目标,测试完型填空的准确性。GPT-2在普通名词上取得了93.3%的成果,在NER上取得了89.1%的成果,均高于SOTA。
3.3 LAMBADA
为了测试模型应对远程依赖的能力,作者在LAMBADA上进行实验,将困惑度从99.8提升到8.6,将准确率从19%提升到52.66%,分析错误表明,大多数预测是有效的序列,但不是有效的结尾,说明缺少额外的约束,加入额外的停用词后,准确率进一步提升到63.24%。
3.4 Winograd Schema Challenge
Winograd Schema Challenge旨在通过测量系统解决文本中歧义的能力来测量系统执行常识推理的能力。
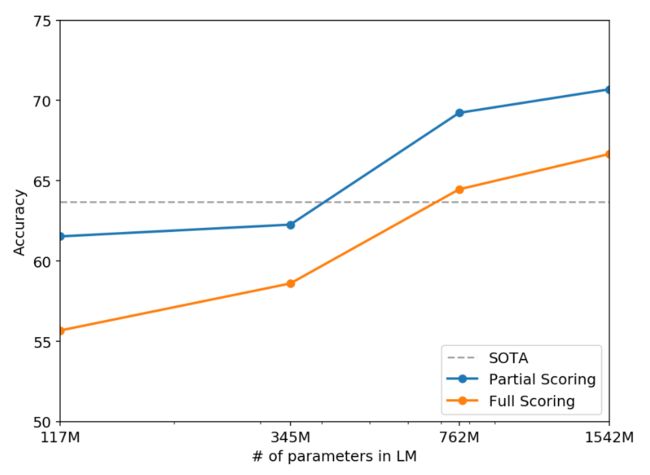
结果如上图所示,GPT-2将最先进的准确率提高了7%。
3.5 Reading Comprehension
CoQA来自7个不同领域的文档,配有提问者和问答者关于文档的对话。该数据集测试模型阅读理解和依赖历史对话能力。基于GPT-2的、缺少问题答案对的实验F1得分达到了55,而基于BERT的监督系统达到了接近人类的89 F1得分。虽然GPT-2的zero-shot效果惊人,但是答案经常使用简单的启发式方法。
3.6 Summarization
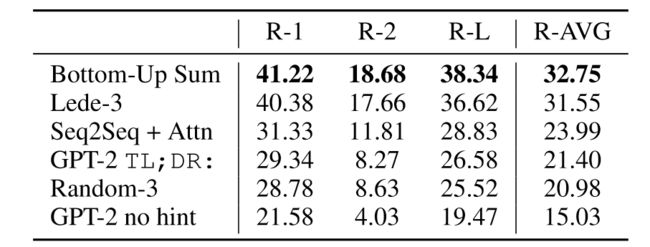
为了诱导GPT-2进行摘要任务,在文章后面添加文本“TL;DR”,使用Top-k随机采样生成100个词标记以减少重复,作者采用这100个词生成的前三句作为摘要。部分结果见附录表14,上表是实验对比结果,虽然GPT-2的性能并不高,但是可以发现加了特殊的提示符后,模型的的性能上升了6.4,这表明语言模型能够通过自然语言来调用特定任务的行为。
3.7 Translation
翻译任务上GPT-2表现不佳,但是仍然优于2017年的基线,甚至是在预训练部分剔除了非英语内容下实现的。
3.8 Question Answering
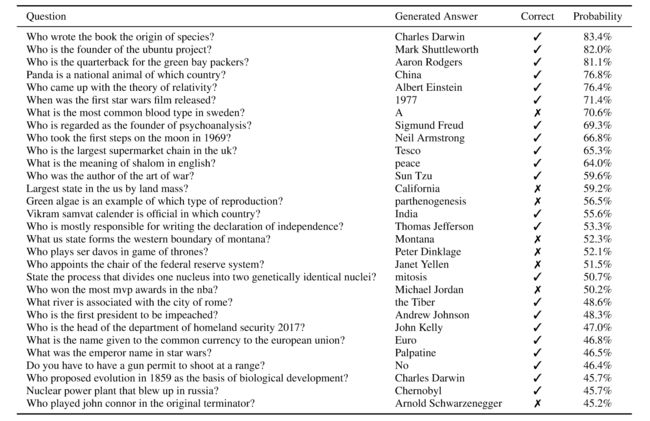
作者在SQUAD等阅读理解数据集上进行评估,发现随着模型规模的增大,GPT-2的性能有显著提升,虽然还是有差距,这表明模型容量是迄今为止神经系统在此类任务上表现不佳的一个主要因素。上表是部分生成的结果。
4. Generalization vs Memorization
最新的研究表明,很多数据集会出现部分训练内容和测试内容重复的现象,这就造成了知识泄露。WebText也可能有类似的现象,因此分析有多少测试数据集出现在训练集也非常重要。
为了研究这个问题,作者创建了包含8-grams的WebText训练集token的布隆过滤器。这些布隆过滤器可以让作者在给定数据集的情况下计算出现在WebText中的概率。结果如下表所示:

可以看到常见的数据集与WebText有1—6%的重叠,令人惊讶的是,许多数据集与自己的训练集重叠更为惊人,平均达到了5.9%。作者又通过一些具体的数据集的分析得出,虽然WebText与一些数据集重叠会对结果提供了微小的帮助,但是对于大多数数据集,它们训练集和测试集的重叠率更高。
理解和量化高度相似的文本对性能的影响是一个重要的研究问题。下图是WebText训练集和测试集的表现:

二者性能相似,并且随着模型的大小增加而增高。这表明GPT-2在WebText数据集上仍有提升空间,也就是说,通过增大模型大小或采取其他优化策略,模型的性能可能会得到进一步的提升。
5. Related Work
略。
6. Discussion
许多研究致力于学习并理解监督学习和无监督学习的范式。本文结果表明,无监督学习是一个有前途的研究领域,这个发现有助于解释应用在下游任务上的预训练语言模型的成果。虽然GPT-2零样本水平远未达到可用水平,但是作者发现,当模型进一步增大,会在一定程度上优于普通基线。未来作者将进一步探索微调的上限。
阅读总结
GPT-2作为OpenAI打消BERT嚣张气焰的主要武器,从实验结果来看,显然是远远不够的,但是作为承上启下的GPT-2,却是GPT家族不可或缺的一部分。在我看来,如果没有GPT,就没有BERT,如果没有GPT-2,就没有如今大模型时代的辉煌。本质上,GPT-2就是GPT的简单延续,它看到BERT用了更到的数据集进行预训练,所以自己也用了一个更大的数据集,看到BERT模型很大,索性将自己变得更大,这一下子不得了,或许是运气和实力的双重加持,让GPT-2团队有了如下的发现:
- Prompt。肯定会有人提出质疑,说prompt最开始应该是从GPT-3开始的,实际上,GPT-2也使用了Prompt。OpenAI团队显然不想和BERT在一个单一的赛道上争得你死我活(也没必要,确实性能也没比人家好多少),因此直接将目光转移到零样本场景,但是零样本场景下缺少微调的步骤,面对不同的问题无法使用特殊的token,因此作者采用了用自然语言的方式来表述问题,这样就删去了未见的特殊token,这种形式本质上可以理解为prompt,也正是因为这意外的发现,才让OpenAI团队在这一基础上继续深挖。
- 性能与预训练数据集。也是通过实验,作者发现随着模型规模增大,在数据集上预训练,训练集和测试集仍能同步提升,这就说明WebText数据集还有进一步挖掘的潜力,或者说,模型规模越大,再匹配相应规模的数据集,模型的性能会稳步提高。
这篇文章对论文写作者也有一定的启发:
- 学会换一个角度思考问题。面对同一赛道的模型,发现自己的模型在相同的设置下并没有优势,可以想办法从更general的角度出发,论述其通用性,格局一定要大一点。
- 即使部分实验结果不好,也要仔细分析原因,没准就能够发现模型的缺陷和一些潜在优势,为之后的工作打下基础。
- 如果在先前工作基础上做文章,模型架构没有大的变化,一定要想办法在一些细节的地方做文章,比如文中就详细分析了数据集的构建、词表的构建、数据集相似性分析和解决方案,让工作不再单一。