【MySQL】库的操作
废话不多说,直接上操作:
目录
一、查看数据库
二、创建数据库
2.1 数据库的字符集及校验规则
2.1.1 查看系统默认字符集
2.1.2 查看系统默认校验规则
2.1.3 查看数据库支持的字符集
2.1.4 查看数据库支持的校验规则
2.2 创建数据库时设置字符集和校验规则
2.2.1 创建数据库时设置字符集
2.2.2 创建数据库时设置校验规则
三、验证不同的校验规则对数据库的影响
四、删除数据库
五、查看自己所处数据库
六、修改数据库
七、显示创建语句
八、数据库的备份与恢复
九、查看数据库连接情况
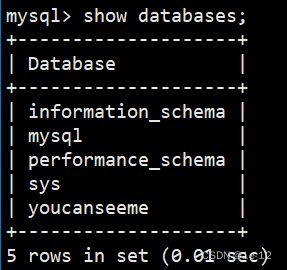
一、查看数据库
show databases;我们可以使用上述sql语句来查看自己的数据库中有那些库(要注意database后面有字母s):

现在有一个问题:这些库是以什么方式存储在自己的Linux系统中的呢?
我们可以查看mysql的配置文件/etc/my.cnf
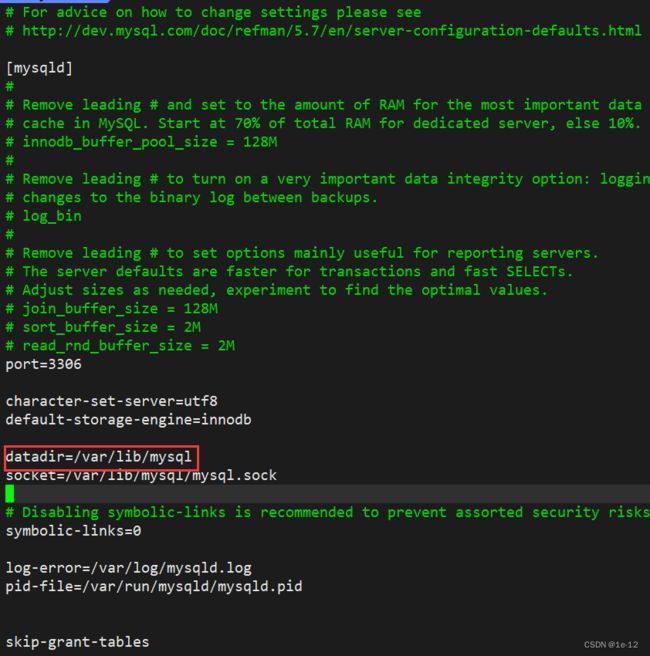
这里面我们可以看到有一个datadir,其后面就是mysql默认存储数据的目录
我们进去看看:

我们可以发现一个特点我们在mysql下查看到的库在保存数据的目录下都相对应一个目录!
那库和目录之间有什么关系呢?
我们在该数据目录下创建一个目录试试看:

创建完,我们再去mysql下查看一下库:
我们发现库中多了一个我们刚刚创建的目录名!
现在我们来删除这个目录:
![]()
删除完后我们发现mysql下刚刚存在相对应的库也不见了:

从上述过程中我们可以得出一个结论:在Linux环境下mysql所创建的库就是在存储数据的目录下创建相对应的目录
但是这样直接创建目录来创建数据库是不合理的,我们还是要使用标准的sql语句在mysql下创建:
二、创建数据库
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name对上述语法解释一下:
大写的表示关键字(在使用语句时大小写都可以,这里用大写只是为了区分)
[] 是可选项(如IF NOT EXISTS表示如果数据库不存在就创建,在使用时可以不添加)
db_name表示要创建数据库的库名
CHARACTER SET: 指定数据库采用的字符集
COLLATE: 指定数据库字符集的校验规则
我们下面来用最简单的语法来创建一个数据库:
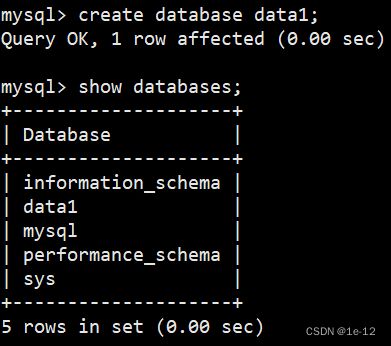
可以看到我们成功的创建了一个名为data1的数据库
接下来我们要讲解一下创建数据库时的字符集及校验规则:
2.1 数据库的字符集及校验规则
数据库作为存储数据的工具,存储和读取数据时使用的编码格式就很显得重要。
数据库字符集可以决定所创建的数据库存储数据时使用什么样的编码格式
数据库校验规则可以决定所创建的数据库对比字段、读取数据所使用的编码格式
2.1.1 查看系统默认字符集
我们可以用下面的sql指令来查看系统默认的编码集
show variables like 'character_set_database';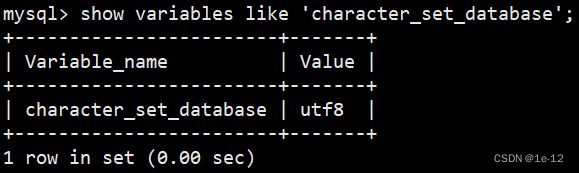
由于我们在环境搭建时将配置文件中让server端的编码格式为utf8,所以系统默认使用utf8来作为默认的字符集
2.1.2 查看系统默认校验规则
我们可以用下面的sql指令来查看系统默认的校验集
show variables like 'collation_database';
由于我们在环境搭建时将配置文件中让server端的编码格式为utf8,所以系统默认使用utf8来作为默认的校验规则
2.1.3 查看数据库支持的字符集
show charset;
2.1.4 查看数据库支持的校验规则
show collation;
2.2 创建数据库时设置字符集和校验规则
2.2.1 创建数据库时设置字符集
创建数据库时设置字符集在mysql中有两种语法格式:
create database db_name charset=所要设置的字符集;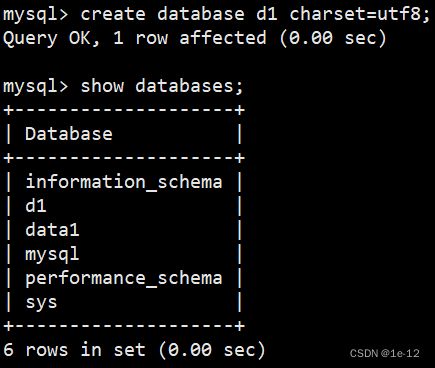
创建后我们可以到所创建库的对应的目录中查看其编码说明文件db.opt:
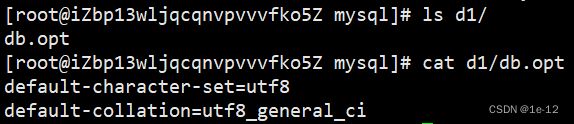
我们可以看到其使用的字符集为utf8
还有一种设置格式为:
create database db_name character set 所要设置的字符集;
创建后查看其编码说明文件db.opt:
我们可以看到其使用的字符集为gbk
2.2.2 创建数据库时设置校验规则
create database db_name collate 想要设置的校验规则;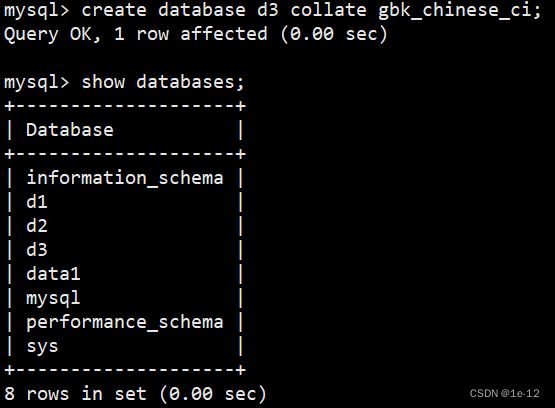
创建后查看其编码说明文件db.opt:

我们可以看到其使用的校验规则为gbk_chinese_ci
当然我们也可以在创建数据库时字符集和校验规则一起设置:
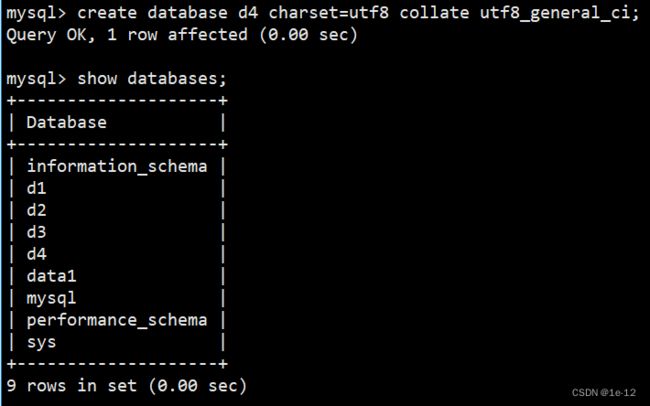
创建后查看其编码说明文件db.opt:

我们可以看到其使用的字符集为utf8,校验规则为utf8_general_ci
三、验证不同的校验规则对数据库的影响
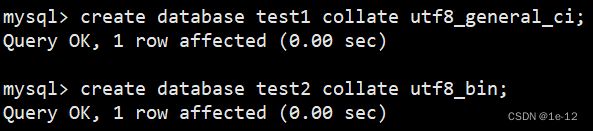
我们现在分别创建两个数据库,一个校验规则使用utf8_ general_ ci(不区分大小写),另一个校验规则使用utf8_ bin(区分大小写):
再向两个库中插入相同的表,并且添加相同的数据(对于表的操作我们在后面会详细讲解):
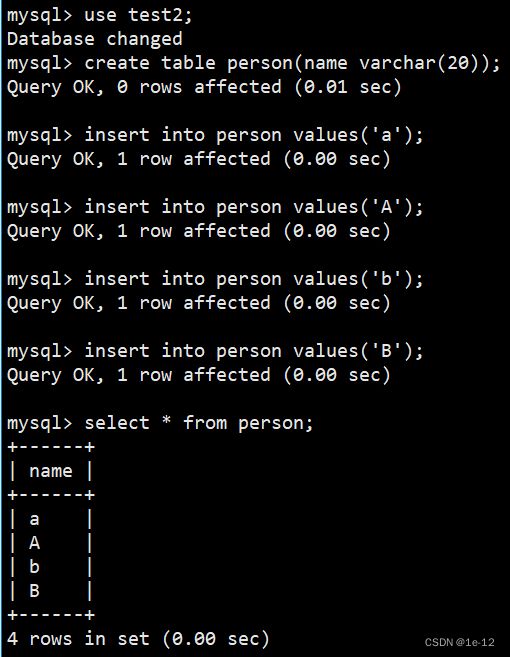
现在我们可以看到这两个数据库都有着相同的一份表,并且表的数据都相同
下面我们分别对其进行筛选查询(在表中查找name为a的数据):
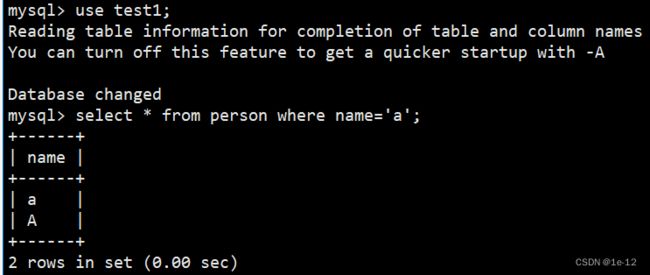

我们可以看到使用utf8_ general_ ci(不区分大小写)校验规则的库查询结果有A和a,另一个校验规则使用utf8_ bin(区分大小写)的库查询结果只有a。
在这里我们可以看到校验规则的不同对数据库的影响
四、删除数据库
删除数据库很简单:
DROP DATABASE [IF EXISTS] db_ name;例如:
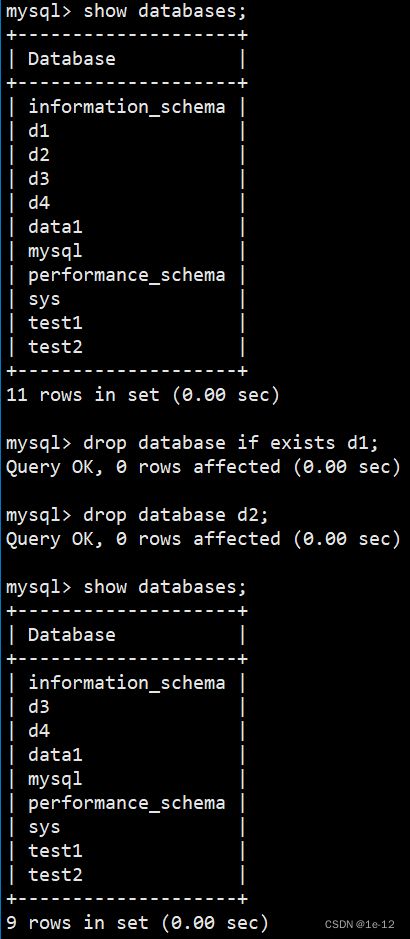
但是要注意:对应的数据库目录被删除,里面的数据表也会全部被删
所以这里不推荐对数据库进行删除操作
五、查看自己所处数据库
我们今后要对表进行操作需要进入到某个数据库中,经过一系列操作我们有可能忘了我们在那个数据库中,这时我们可以使用下面语句来查看自己所处的数据库:
select database();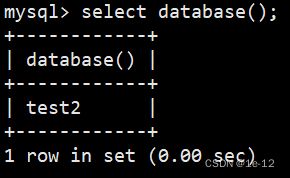
可以看到现在处于test2这个数据库中
六、修改数据库
对数据库的修改主要指的是修改数据库的字符集和校验规则
ALTER DATABASE db_name [alter_spacification [,alter_spacification]...] alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name我们现在来对test2这个数据库做影响修改,在修改前其编码集为utf8:

下面对其进行修改:
![]()
再来查看其字符集和校验规则:

七、显示创建语句
show create database db_name;上面该指令可以查看数据库的创建语句:

我们可以看到test2这个数据库创建时的语句为CREATE DATABASE 'test2'
数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字
后面加了/* 的语句不是注释,表示当前mysql版本大于4.01版本,就执行这句话(也就是字符集使用gbk编码)
八、数据库的备份与恢复
如果我们想要备份一个数据库,我们可以对其所在的目录直接继续拷贝。但是这样是不推荐的,这样拷贝下来的目录可能在不同的版本的mysql下不能识别。
最好的方式是使用mysqldump工具(在我们安装mysql时已经下载好了)来进行备份:
# mysqldump -P3306 -u root -p -B db_name > 数据库备份存储的文件路径
我们来实操一下:

下面我们来备份一下test2这个数据库:

我们现在已经备份一份test2数据库到test2.sql这个文件中,我们来看看这个文件里存了些什么:
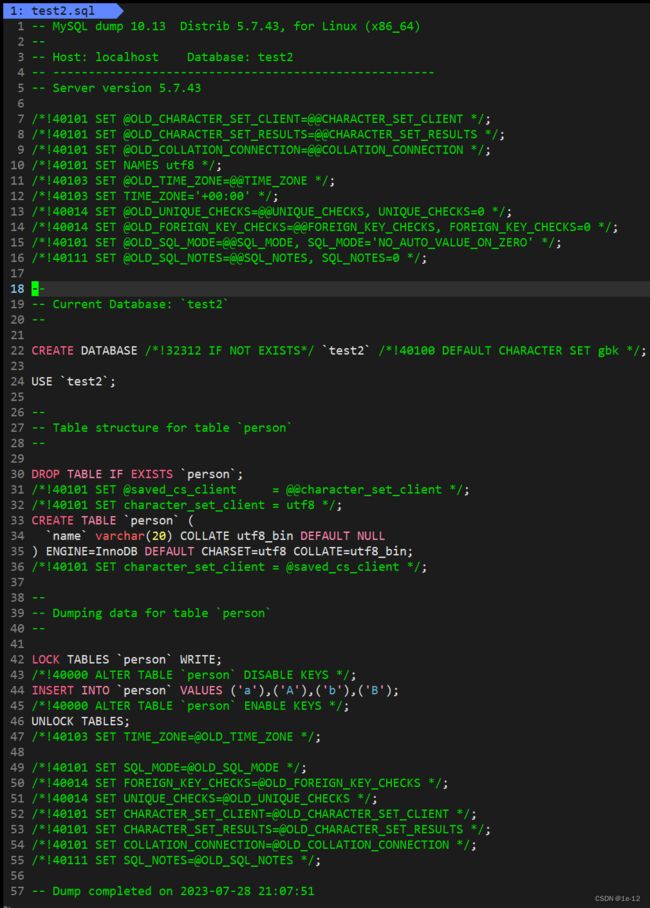
我们可以看到这个文件里不仅仅留有库中表的数据,还有创建库和表的指令
现在我们将test2这个数据库删了,试试看能不能从备份文件中恢复:

恢复时会使用source语句:
source 备份文件的路径;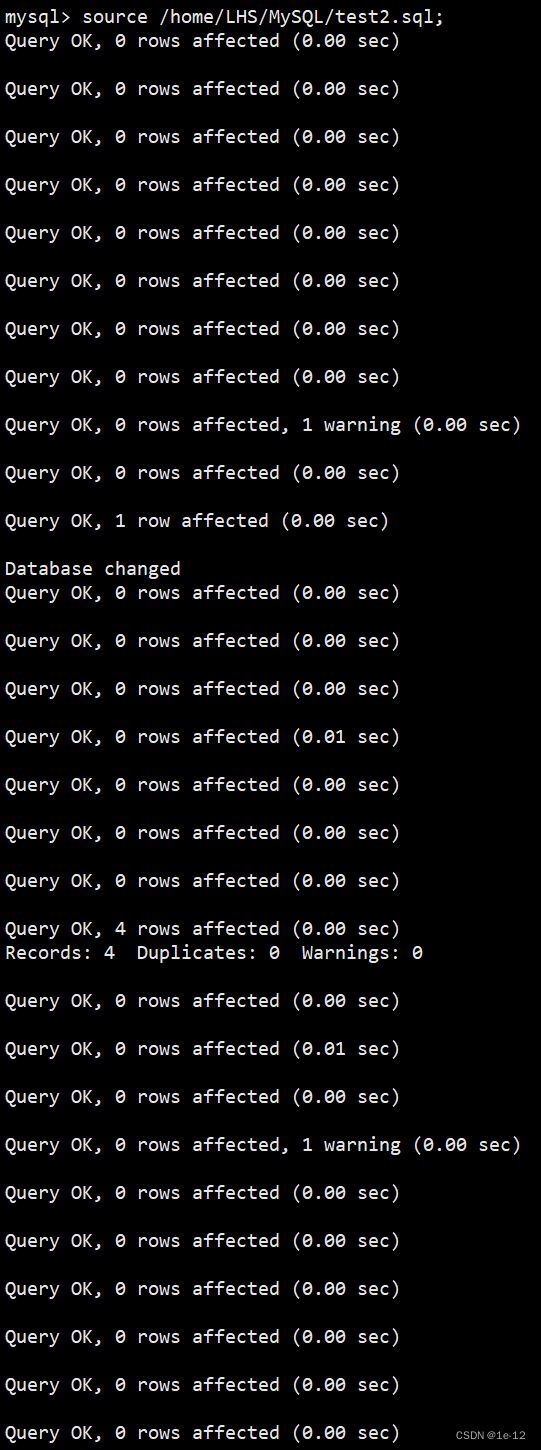
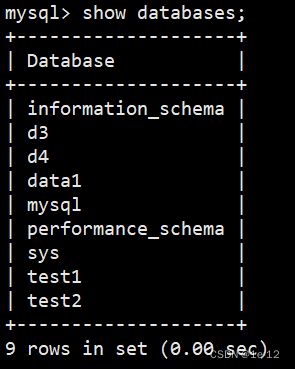
我们可以看到test2这个数据库又回来了,我们查看一下该数据库中的数据:
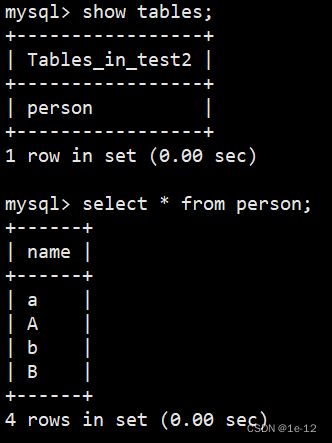
完璧归赵~
注意了:
如果备份的不是整个数据库,而是其中的几张表,我们可以这样子:
# mysqldump -u root -p 数据库名 表名1 表名2 > 备份存储的文件路径
同时备份多个数据库可以这样子:
# mysqldump -u root -p -B 数据库名1 数据库名2 ... > 备份存储的文件路径
下面解释一下:-B选项是在备份时加上数据库的创建指令,以便在恢复时直接指向该这里创建和原数据库一样的库。所以如果备份数据库时没有带上-B参数, 在恢复数据库时,需要先创建空数据库,再在该数据库下使用source来还原。
九、查看数据库连接情况
show processlist;上面语句可以让我们看到谁在连接我们的数据库,以及连接人在干什么:
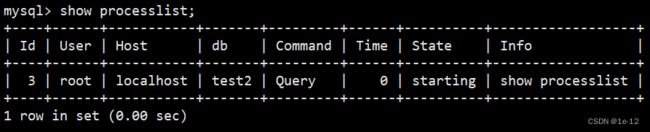
如果查出某个用户不是你正常登陆的,很有可能你的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看。
本期博客到这里就结束了,下期再见~
更多MySQL技能请看:http://t.csdn.cn/W9dQl
博主努力更新中~