二十章:基于弱监督语义分割的亲和注意力图神经网络
0.摘要
弱监督语义分割因其较低的人工标注成本而受到广泛关注。本文旨在解决基于边界框标注的语义分割问题,即使用边界框注释作为监督来训练准确的语义分割模型。为此,我们提出了亲和力注意力图神经网络(A2GNN)。按照先前的做法,我们首先生成伪语义感知的种子,然后基于我们新提出的亲和力卷积神经网络(CNN)将其形成语义图。然后,构建的图被输入到我们的A2GNN中,其中一个亲和力注意力层被设计用来从软图边缘获取短距离和长距离信息,以准确地将语义标签从可信的种子传播到未标记的像素。然而,为了确保种子的准确性,我们只采用有限数量的可信像素种子标签用于A2GNN,这可能导致训练的监督不足。为了缓解这个问题,我们进一步引入了一个新的损失函数和一种一致性检查机制,以利用边界框约束,从而可以为模型优化提供更可靠的引导。实验证明,我们的方法在Pascal VOC 2012数据集上取得了新的最先进性能(val: 76.5%,test: 75.2%)。更重要的是,我们的方法可以轻松应用于基于边界框的实例分割任务或其他弱监督语义分割任务,在PASCAL VOC或COCO数据集上具有最先进或可比较的性能。我们的源代码将在https://github.com/zbf1991/A2GNN上公开。
1.引言
弱监督语义分割旨在使用弱标注作为监督来进行像素级语义预测。根据提供的注释级别,弱监督可以分为涂抹级别[1],[2],[3],边界框级别[4],[5],[6],[7],点级别[8]和图像级别[9],[10],[11],[12]。在本文中,我们主要关注基于边界框监督的语义分割(BSSS)。BSSS的关键挑战在于如何准确地估计给定边界框内的伪对象掩码,以便可以使用当前流行的全卷积网络(FCN)[13],[14],[15],[16]通过生成的伪掩码来学习可靠的分割网络。
先前的BSSS任务中,大多数方法[4],[5],[6],[17]使用对象提议[18],[19]提供一些种子标签作为监督。这些方法遵循一个常见的流程,即使用对象提议[18],[19]和CRF [20]生成伪掩码,然后将其作为真实标签用于训练分割网络。然而,由于分割掩码和对象提议之间存在差距,这种流程通常无法生成准确的伪标签。为了克服这个限制,随后提出了基于图的学习方法,使用从提议中挖掘出的有信心但有限数量的像素作为监督。与先前的方法相比,基于图的学习,特别是图神经网络(GNN),可以直接在不同节点之间建立远距离边,并从多个连接节点聚合信息,从而能够抑制标签噪声的负面影响。此外,即使只有有限的标签,GNN在半监督任务中也表现出色。
最近,GraphNet [21]尝试使用图卷积网络(GCN)[22]来进行BSSS任务。他们通过将像素在超像素中进行分组,将图像转换为无权重图[23]。然后,将图输入到标准的GCN中,使用交叉熵损失生成伪标签。然而,它存在两个主要缺点限制了其性能:(1)GraphNet [21]构建了一个无权重的图作为输入,然而,这样的图不能准确地提供足够的信息,因为它平等对待所有边,边的权重要么是0,要么是1,虽然在实践中,并不是所有连接的节点都有相同的亲和力。(2)使用GraphNet [21]会导致错误的特征聚合,因为输入节点和边并不是100%准确的。例如,对于一张包含狗和猫的图片,狗毛和猫毛的初始节点特征可能非常相似,这将在它们之间产生一些连接的边,因为边是基于特征相似性构建的。这样的边会导致误报情况,因为GraphNet [21]只考虑初始边用于特征传播。因此,如果能够有效地减轻不同语义之间像素之间的强相关性,就可以获得更好的传播模型,生成更准确的伪对象掩码。
为了解决上述问题,我们设计了一种亲和力注意力图神经网络(A2GNN)。具体而言,我们提出了一种新的亲和力卷积神经网络(CNN),将图像转换为带权重的图,而不是使用传统方法构建无权重图。我们认为带权重的图比无权重图更适合,因为它可以为不同的节点对提供不同的亲和力。图1显示了我们构建的图与先前方法[21]的区别。可以看到,先前的方法只考虑局部连接的节点,并且基于超像素[23]构建了一个无权重图,而我们考虑了局部和远距离边,并且构建的带权重图将一个像素视为一个节点。
其次,为了生成准确的伪标签,我们设计了一个新的GNN层,在其中应用了注意机制和边权重,以确保准确的传播。因此,弱/无边连接或低注意力的节点之间的特征聚合可以显著减少,从而相应地消除错误的传播。节点的注意力随着训练的进行而动态变化。
然而,为了保证监督的准确性,我们只选择了一部分有信心的种子标签作为监督,这对于网络优化来说是不足够的。例如,在一张图片中,只有大约40%的前景像素被标记,并且它们中没有一个是100%可靠的。为了进一步解决这个问题,我们引入了一个多点(MP)损失来增强A2GNN的训练。我们的MP损失采用了在线更新机制,从边界框信息中提供额外的监督。此外,为了加强我们的A2GNN的特征传播,MP损失试图缩小相同语义对象的特征距离,使同一对象的像素能够与其他像素区分开来。最后,考虑到选择的种子标签可能不完全可靠,我们引入了一个一致性检查机制,通过将其与MP损失中使用的标签进行比较,从选择的种子标签中删除那些噪声标签。
为了验证我们的A2GNN的有效性,我们在PASCAL VOC数据集上进行了大量实验。特别是,在验证集上我们实现了新的mIoU得分为76.5%。此外,我们的A2GNN还可以进一步平滑地转化为进行边界框监督的实例分割(BSIS)任务或其他弱监督语义分割任务。根据我们的实验,我们在所有这些任务中取得了新的最先进或可比较的性能。
我们的主要贡献总结如下:
- 我们提出了一个新的框架,有效地结合了CNN和GNN的优势,用于弱监督语义分割。据我们所知,这是第一个可以轻松应用于所有现有的弱监督语义分割设置和边界框监督实例分割设置的框架。
- 我们设计了一个新的亲和力CNN网络,将给定的图像转换为一个不规则的图,其中图节点特征和节点边同时生成。与现有方法相比,我们方法构建的图对于各种弱监督语义分割设置更准确。
- 我们提出了一个新的GNN,A2GNN,其中设计了一个新的GNN层,可以通过基于边权重和节点注意力的信息聚合有效地减轻不准确的特征传播。我们进一步提出了一种新的损失函数(MP损失),利用边界框约束挖掘额外可靠的标签,并通过一致性检查去除现有的标签噪声。
- 我们的方法在PASCAL VOC 2012数据集上实现了最先进的BSSS性能(验证集:76.5%,测试集:75.2%),以及PASCAL VOC 2012和COCO数据集上的最先进的BSIS性能(mAPr0.5:59.1%,mAPr0.7:35.5%,mAPr0.75:27.4%)。同时,将所提出的方法应用于其他弱监督语义分割设置时,也实现了最先进或可比较的性能水平。
 图1. 我们构建的图与之前方法[21]的区别。 (a) 基于超像素的方法[21]。 (b) 我们的方法。沿边的数字表示边的值,软边允许边权重在0和1之间的任何值。
图1. 我们构建的图与之前方法[21]的区别。 (a) 基于超像素的方法[21]。 (b) 我们的方法。沿边的数字表示边的值,软边允许边权重在0和1之间的任何值。
2.相关工作
2.1.弱监督语义分割
根据监督信号的定义,弱监督语义分割通常可以分为以下几类:基于涂鸦标签[1]、[2]、[3]、基于边界框标签[4]、[5]、[6]、基于点标签[8]和基于图像级别类别标签[9]、[10]、[11]。与图像级别类别标签相比,涂鸦、边界框和点标签是更强的监督信号,因为它们提供了类别和定位信息。而图像级别标签只提供了最低的注释成本下的图像类别标签。
不同的监督方式使用不同的方法生成伪标签。对于涂鸦监督,Lin等人[2]使用基于超像素的方法(例如SLIC [23])扩展初始涂鸦,并使用FCN模型[13]获得最终的预测结果。Tang等人提出了两种正则化损失[1],[3],使用约束能量损失函数扩展涂鸦信息。对于点监督,Bearman等人[8]直接在损失函数中引入了通用的物体先验。对于图像级别监督,通常使用类别激活图(CAM)[24]作为种子来生成伪标签。例如,Ahn和Kwak设计了一个亲和网络[9]来获得转移概率矩阵,并使用随机游走[25]生成伪标签。Huang等人[26]提出使用种子区域生长算法[27]从初始的可信类别激活图中获取伪标签。对于边界框监督,SDI [5]使用将MCG [28]与GrabCut [29]相结合的分割提议生成伪标签。Song等人提出了一种基于边界框的方法[6],使用基于边界框的类别掩码和填充率引导的自适应损失来生成伪标签。Box2Seg [30]试图设计一个适用于利用噪声标签作为监督的分割网络。
根据相同的定义,弱监督实例分割有不同的子任务级别:图像级别[12]和边界框级别[5],[7]。对于图像级别任务,Ahn等人尝试使用亲和网络[12]生成实例的伪标签。对于边界框任务,SDI [5]使用将MCG [28]与GrabCut [29]相结合的分割提议生成伪标签,而Hsu等人[7]试图设计一个新的损失函数,依赖于边界框监督来采样正负像素。
2.2.图神经网络
通常,针对半监督任务设计了许多不同的图神经网络(GNN)方法[22],[31],[32],[33],并且它们取得了令人满意的性能。最近,GNN已经成功应用于各种计算机视觉任务,如人物搜索[34],图像识别[35],3D姿态估计[36]和视频对象分割[37]等。
针对边界框任务,提出了使用GCN [22]的GraphNet [21]用于弱监督语义分割。具体而言,首先基于CAM技术[24]将边界框监督转换为初始的像素级监督。然后,应用超像素方法[23]生成图节点。他们使用预训练的CNN模型获取节点特征,该特征使用对所有像素进行平均池化计算得到。之后,根据节点与其8个相邻节点之间的L1距离计算邻接矩阵。随后,使用GCN将初始的像素级标签传播到整体伪标签。最后,将所有伪标签输入到一个语义分割模型进行训练。GraphNet证明了GNN是弱监督语义分割的一种可能解决方案。然而,该方法存在一些局限性。首先,使用超像素作为节点引入了错误的节点标签,并且通过阈值构建邻接矩阵会丢失一些重要的详细信息。其次,该方法的性能受限于GNN [22]的使用,它只考虑非加权邻接矩阵。最后,GraphNet只使用交叉熵损失,不能减轻错误节点、边和标签的影响。
为了克服以往基于图的学习方法的局限性,我们设计了一种新的方法A2GNN,它以更准确的加权图作为输入,并通过同时考虑注意机制和边权重来聚合特征。同时,我们提出了一种新的损失函数,提供额外的监督,并对特征聚合施加限制,因此我们的A2GNN可以生成高质量的伪标签。
3.生成像素级种子标签
初始化弱监督任务的常见做法是从弱监督中生成像素级的种子标签[21],[38],[39]。对于边界框语义分割任务,可以使用图像级别和边界框级别的标签。我们使用这两种标签来生成像素级的种子标签,因为图像级别标签可以生成前景种子,而边界框级别标签可以提供准确的背景种子。为了将图像级别标签转换为像素级别标签,我们使用基于CAM的方法[9],[12],[24],[38]。为了从边界框监督中生成像素级别标签,我们使用Grab-cut [29]来生成初始标签,不属于任何边界框的像素被视为背景标签。最后,这两种类型的标签被融合在一起生成像素级的种子标签。 具体来说,我们使用SEAM [38],这是一个自监督分类网络,从图像级别监督生成像素级的种子标签。假设一个包含类别集合C = [c0, c1, c2, ..., cN-1]的数据集,其中c0表示背景,其余表示前景类别。从图像级别监督生成的像素级种子标签如下所示:
其中MI是生成的种子标签。NetSEAM(·)是SEAM [38]中使用的分类CNN。 对于边界框语义分割任务,除了图像级别标签外,它还提供了边界框级别标签。我们还从边界框标签生成像素级标签,因为它可以提供准确的背景标签和目标定位信息。给定一张图像,假设边界框集合为B = {B1, ..., BM}。对于带有标签LBk的边界框Bk,其高度和宽度分别为h和w。我们使用Grab-cut [29]从边界框监督中生成种子标签,每个边界框的种子标签定义如下:
 其中S(MI-Bk)是MI中针对边界框Bk预测的类别集合。LBk∈/S(MI-Bk)表示MI中对于边界框Bk没有正确的预测标签,因此我们使用MBk的预测结果作为最终的种子标签。 在图2中,给出了一个示例来演示将边界框监督转换为像素级种子标签的过程。通过组合MI和MB,我们可以得到像素级种子标签。
其中S(MI-Bk)是MI中针对边界框Bk预测的类别集合。LBk∈/S(MI-Bk)表示MI中对于边界框Bk没有正确的预测标签,因此我们使用MBk的预测结果作为最终的种子标签。 在图2中,给出了一个示例来演示将边界框监督转换为像素级种子标签的过程。通过组合MI和MB,我们可以得到像素级种子标签。
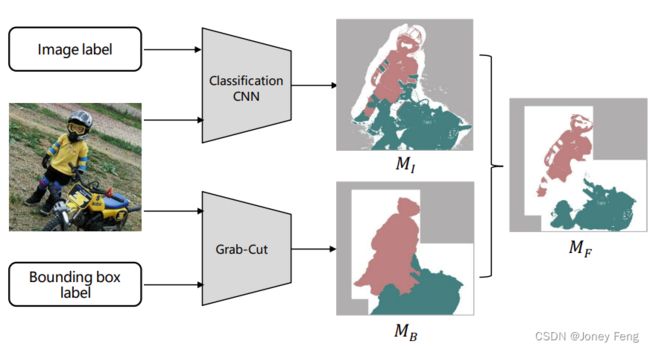
图2. 生成像素级种子标签的示例。给定一张带有标签的图像,我们首先使用分类CNN和SEAM [38]方法从图像级别标签生成MI。同时,使用Grab-cut将边界框标签转换为像素级标签MB。最后,将MI和MB进行整合,得到像素级种子标签MF。每种颜色代表一个类别,“白色”表示像素标签未知。
4.提出的A2GNN(Affinity Attention Graph Neural Network)
4.1.概括
为了利用GNN生成准确的像素级伪标签,存在三个主要问题:(1) 如何提供有用的监督信息并尽可能减少标签噪声。(2) 如何将图像数据转换为准确的图数据。(3) 如何基于构建的图和监督信息生成准确的伪标签。
在本节中,我们将详细介绍所提出的A2GNN方法来解决上述三个主要问题。为了生成准确的图,我们提出了一种新的亲和力CNN来将图像转换为图。为了为图提供准确标记的节点,我们选择高度可信的像素级种子标签作为节点标签,并同时根据边界框监督引入额外的在线更新标签,同时通过一致性检查进一步改进像素级种子标签。为了生成准确的伪标签,我们设计了一个新的GNN层,因为先前的GNN,如GCN [22]或AGNN [32],是基于标签100%准确的假设设计的,而在这种情况下,没有前景像素标签是100%可靠的。
图3展示了我们方法的主要流程,可以分为三个步骤: (1) 生成可信的种子标签。在这一步中,根据第3节的解释,图像级别标签和边界框级别标签都被转换为初始的像素级种子标签。然后,选取具有高置信度的像素级种子标签作为可信的种子标签(第4.2节)。 (2) 将图像转换为图。在这一步中,我们提出了一种新的亲和力CNN来生成图。同时,选取的可信种子标签将被转换为相应的节点标签。 (3) 生成最终的像素级伪标签。使用转换后的图作为输入训练A2GNN,并对图中的所有节点进行预测。在将节点伪标签转换为像素标签后,生成最终的像素级伪标签。
之后,使用上述像素级伪标签作为监督,训练BSSS任务的FCN模型,例如Deeplab [14], [15],或训练BSIS任务的MaskR-CNN [16]。 在接下来的部分,我们首先介绍如何提供有用的监督信息,然后解释如何从图像中构建图(第4.3节)。最后,我们将介绍A2GNN,包括其亲和力注意力层(第4.4节)和损失函数(第4.5节)。
4.2.自信的种子标签选择
一种直观的解决方案是将从公式(4)中获得的像素级种子标签MF用作种子标签。然而,MF存在噪声,直接使用它将对CNN/GNN的训练产生不利影响。因此,在本文中,我们只选择MF中高度可信的像素级种子标签作为最终的种子标签。具体而言,我们使用动态阈值从公式(1)中的像素标签MI中选择置信度排名前40%的像素标签M0I,遵循[40]的方法。然后,所选的种子标签被定义为: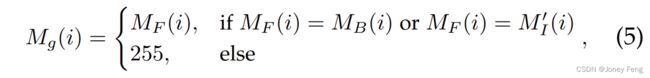
其中,255表示标签未知。MB和MF分别从公式(3)和公式(4)中获得。图3(右上方)说明了可信标签的选择。 尽管噪声标签可以被大幅减少,但是可信标签的选择存在两个主要限制:1)它也会删除一些正确的标签,使得剩下的标签数量稀缺,并且主要集中在有区分度的物体部分(例如人头),而不是均匀分布在整个物体上;2)仍然存在非准确的标签。
为了解决BSSS任务中标签稀缺的问题,我们提出从可用的边界框中挖掘额外的监督信息。假设所有的边界框都是紧密的,对于边界框内的随机行或列像素,至少有一个像素属于物体。识别这些节点可以提供额外的前景标签。通过使用在线更新的标签,我们引入了一个新的一致性检查机制,进一步从Mg中删除一些噪声标签。由于这些过程依赖于我们A2GNN的输出,我们将在第4.5节中详细描述这一过程。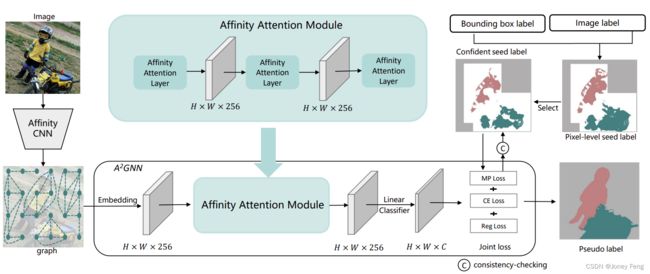
图3. 我们提出的A2GNN的框架。首先,我们使用边界框和图像级别标签生成像素级种子标签。然后,我们使用亲和力CNN将图像转换为图。同时,我们从像素级种子标签中选择可信的标签作为节点标签(白色区域的节点标签未知)。最后,A2GNN将图数据作为输入,节点标签作为监督,生成伪标签。
4.3.图构建
4.3.1.亲和卷积神经网络(Affinity CNN)
我们提出了一种新的亲和力CNN,使用可用的亲和力标签作为监督,从图像中生成准确的图。这是因为亲和力CNN具有以下优点。首先,它将一个像素视为一个节点,而不是将一个超像素视为一个节点,这样可以减少噪声。其次,亲和力CNN使用节点亲和力标签作为训练监督,确保为该特定任务生成适合的节点特征,而先前的GraphNet [21]使用分类监督进行训练。第三,在与GraphNet [21]中构建的仅表示为0和1的短距离无权图(边)相比,亲和力CNN可以构建具有软边的加权图,涵盖较长距离,从而提供更准确的节点关系。与先前的工作[9],[12],[41],[42]中使用公式(4)中的所有噪声标签作为监督的方法不同,我们的亲和力CNN只使用在公式(5)中定义的可信种子标签作为监督,以预测不同像素之间的关系。 为了训练我们的亲和力CNN,我们首先从公式(5)中的可信像素级种子标签Mg生成无类别标签:

需要注意的是,仅使用可信标签作为监督来训练CNN是不足够的,尤其是当仅考虑LAc作为损失函数时。为了将有标签的区域扩展到无标签的区域,我们提出了一种亲和力规范化损失函数LAr,以鼓励从有标签的像素向其连接的无标签像素传播。换句话说,我们考虑满足以下公式的所有像素对,而不仅仅考虑Rpair中的像素对:
4.3.2.将图像转换为图形
通常,图被表示为G = (V, E),其中V是节点的集合,E是边的集合。设vi∈ V表示一个节点,Ei,j表示节点vi和vj之间的边。X∈R Ng∗Dg是表示所有节点特征的矩阵,其中Ng是节点的数量,Dg是特征的维度。在X中,第i个特征,表示为xi,对应于节点vi的特征。所有有标签的节点的集合被定义为V l,剩余节点的集合表示为V u,而V = V l ∪ V u。 在训练过程中,我们的亲和力CNN使用无类别的亲和力标签作为监督,并学习预测像素之间的关系。在推理过程中,给定一个图像,我们的亲和力CNN将同时输出V,X和E,用于构建一个如图4所示的图。具体而言,节点vi及其特征xi对应于骨干网络中连接特征图中的第i个像素及其所有通道的特征。对于两个节点vi和vj,它们的边Eij定义为: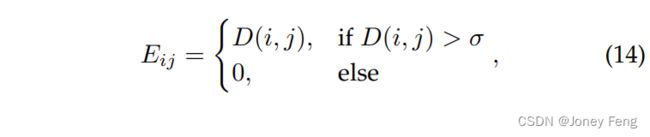
其中i和j是特征图中的像素,D(i, j)是从公式(8)中获得的值。在这里,我们使用一个阈值σ(在我们的实验中设置为1e-3)将一些低亲和力的边设为0。最后,我们生成归一化的特征:
4.4.亲和注意力层
现有的研究[22],[32]已经研究了有效的GNN架构,其中大多数是基于图节点和边信息100%准确的假设设计的。然而,在BSSS任务中,情况并非如此。我们提出了一个带有注意机制的新的GNN层来缓解这个问题。如图3所示,在提出的A2GNN中,在嵌入层之后应用了一个亲和力注意模块。亲和力注意模块包括三个称为亲和力注意层的新GNN层。最后,跟随一个输出层来预测所有节点的类别标签。具体而言,我们在第一层中使用一个特征嵌入层,后面跟随一个ReLU激活函数,将初始节点特征映射到分配特征的相同维度:
其中WL+1是输出层的参数集。图5展示了我们亲和力注意层的流程图。与GCN层[22]和AGNN层[43]相比,我们的亲和力注意层充分利用了节点相似性和边权重信息。
4.5.A2GNN的训练
如第4.2节所述,我们仅选择自信标签作为监督,这对于网络优化是不够的。为了解决这个问题,我们对A2GNN施加了多重监督。具体而言,我们设计了一个新的联合损失函数,包括交叉熵损失、正则化浅层损失[3]和多点(MP)损失: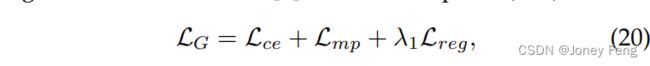
其中Lce是使用在第4.2节生成的带标签节点Mg的交叉熵损失。Lreg是使用浅层特征(即颜色和空间位置)的正则化损失。Lmp是新提出的使用边界框监督的多点(MP)损失。
4.5.1.交叉熵损失
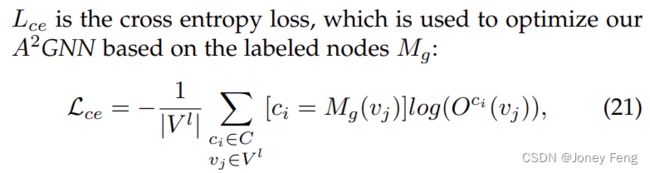
其中V_l是所有带标签节点的集合。Mg(vj)表示节点vj的标签。|·|用于计算元素的数量。Oci(vj)是节点vj属于类别ci的预测概率。V_l是带标签节点的集合。
4.5.2.正则化损失
4.5.3.多点损失
受到[7]的启发,我们设计了一个名为多点(MP)损失的新损失项,以从边界框中获得额外的监督。这是因为在第4.2节生成的带标签节点数量有限且不完全可靠,可以通过边界框信息来补充。MP损失基于以下考虑。假设所有边界框都很紧密,在一个边界框内的随机行或列像素中,至少有一个像素属于对象,如果我们能找到所有这些节点,那么我们可以将它们标记为对象类别,并在嵌入空间中将它们的距离缩小。因此,MP损失使对象易于区分。
具体而言,对于边界框中的每一行/列,被分类为边界框类别标签概率最高的节点被视为选定节点。按照第3节中的定义,假设图像中的边界框集合为B,对于B中的任意边界框Bj,首先我们需要为每一行/列选择概率最高的像素:
在公式(26)中,使用d(·,·)来计算特征距离,其中我们设置d(·,·)= 1- cos(·,·)。H(km)和H(kn)分别对应于节点km和kn的最后一个亲和力注意层HL+1中的特征。Np和Nf都是求和项的数量。MP损失试图在嵌入空间中将选定的节点拉近,而与它们连接的所有其他节点也会受益于此损失。这是因为GNN层可以被视为一个聚合来自相连节点的特征的层,它会鼓励其他相连的节点与它们共享相似的特征。换句话说,MP损失将使属于同一对象的节点易于区分,因为它们被分配到嵌入空间中的相似特征上。在我们的模型中,我们只对Kj(公式(24))施加MP损失,而不是所有带标签节点。这是因为Mg中的其他节点仍然具有噪声标签,并且与此同时,Mg中的带标签前景节点更关注对象的判别性部分。
4.5.4.一致性检查
如第4.2节所述,尽管我们选择了一些自信的种子标签作为监督,但噪声标签仍然是不可避免的。考虑到我们在MP损失中提供了一些额外的在线标签,即在框中的每一行/列中选择概率最高的像素作为附加标签,我们假设MP损失中的大多数附加标签是正确的,然后对于每个框,我们首先使用框内所有附加标签的特征生成一个原型: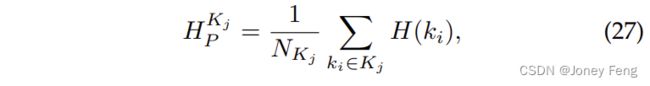
其中H^Kj_P表示第j个边界框的原型,NKj是选定像素的数量。 然后对于每个边界框,我们计算公式(5)中所有选定的自信种子标签与原型之间的距离,并最终将远离原型的种子标签视为噪声标签,并在每次迭代中将其移除:
5.实现细节
为了从图像级别标签生成像素级别的种子标签,我们使用与SEAM [38]相同的分类网络,即ResNet-38 [50]。所有参数与[38]中保持一致。
我们的亲和度CNN采用与上述分类网络相同的主干网络。同时,在最后三个残差块中使用了空洞卷积,它们的空洞率分别设置为2、4和4。如图4所示,这三个残差块的输出通道分别为512、1024和4096。一个节点特征是这三个输出的连接特征,因此一个节点的特征维度为5632。由于我们需要使用特征来计算距离,因此使用了三个1×1卷积核来降低这三个残差块的特征维度,输出通道分别设置为64、128和256。最后,使用一个具有448个通道的1×1卷积核来获得最终的特征图FA。按照[9]的做法,我们在训练和推断中将r设置为5。公式(9)中的λ设置为3,σxy = 6,σrgb = 0.1。
我们的A2GNN在第4.4节中提到有五个层,第一层和三个亲和力注意层的输出通道数为256。公式(20)中的λ1设置为0.01。在Lreg中,我们采用了与公式(13)相同的参数。我们使用Adam作为优化器[51],学习率为0.03,权重衰减为5×10^(-4)。在训练过程中,总共进行100个epoch,丢弃率为0.5。训练过程分为两个阶段:在第一阶段(前50个epoch),不使用Lreg和一致性检查,而在第二阶段,使用所有的损失和一致性检查。我们在第一层之后使用了dropout。在训练和推断过程中,我们使用双线性插值来恢复原始分辨率。在推断过程中,使用CRF [20]作为后处理方法。CRF的一元势使用公式(19)中的最终输出概率O,而二元势对应于不同节点的颜色和空间位置。所有CRF参数与[9]、[40]相同。需要注意的是,对于BSIS任务,我们需要将上述伪标签转换为实例掩码。给定一个边界框,我们直接将位于边界框内并与其具有相同类别的像素分配给一个实例。
对于BSSS任务,我们选择Deeplab-Resnet101 [14]、PSPNet [45]和Tree-FCN [49]作为我们的全监督语义分割模型进行公平比较。对于BSIS任务,我们采用MaskR-CNN [16]作为最终的实例分割模型,并使用Resnet-101作为主干网络。按照与[7]相同的后处理方法,我们使用CRF [20]来优化我们的最终预测结果。 所有实验在4个Nvidia-TiTan X GPU上运行。对于Pascal VOC 2012数据集,生成像素级别的种子标签大约需要12个小时,训练亲和度CNN大约需要12个小时,使用A2GNN生成伪标签大约需要16个小时。
6.实验
6.1.数据集
我们在PASCAL VOC 2012 [52]和COCO [53]数据集上评估了我们的方法。对于PASCAL VOC 2012数据集,我们还使用了增强数据SBD [54],整个数据集包括10,582张训练图像,1,449张验证图像和1,456张测试图像。对于COCO数据集,我们在默认的训练集(80K张图像)上进行训练,然后在test-dev集上进行测试。 对于PASCAL VOC 2012数据集,我们采用平均交并比(mIoU)作为弱监督语义分割的评价标准,采用平均精确率(mAP)[55]作为弱监督实例分割的评价标准。按照之前的工作采用的相同评价协议,我们报告了三个阈值(0.5、0.7、0.75)下的mAP,分别表示为mAPr0.5,mAPr0.7和mAPr0.75。对于COCO数据集,按照[56]的做法,我们报告了mAP、mAPr0.5、mAPr0.75、mAPs、mAPm和mAPl。
6.2.与当前方法的比较
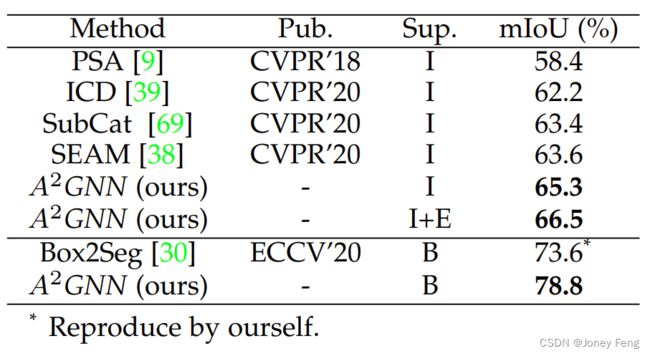
弱监督语义分割:在表1中,我们将我们的方法与其他最先进的BSSS方法进行了比较。对于使用deeplab作为分割模型的情况,可以看出我们的方法在像素级监督(Deeplab-Resnet101 [14]与CRF)上达到了96.1%的上界。与其他方法相比,我们的方法取得了新的最先进性能。特别是,我们的deeplab-resnet101 [49]方法在mIoU上的表现比Box-Sup [4]、WSSL [17]高出了很大的幅度,分别约为11.8%和13.2%。此外,与唯一的图学习解决方案GraphNet [21]相比,我们的Deeplab-Resnet101方法的表现要好得多,mIoU(不使用CRF)提高了10.9%。我们还可以观察到,我们的性能甚至比使用MCG [18]和BSDS [19]作为额外像素级监督的SDI [5]更好。当使用PSPNet [45]作为分割模型时,我们的方法在不使用CRF进行后处理的情况下获得了74.4%的mIoU,甚至高于[47]中使用CRF的结果。最后,我们的Tree-FCN [49]方法在这个任务中超过了最先进的Box2Seg [30]。请注意,Box2Seg专注于使用边界框的噪声标签设计分割网络,因此使用他们的网络作为最终的分割网络可以进一步提高我们的性能。
弱监督实例分割:在表2中,我们将我们的方法与其他最先进的BSIS方法进行了比较。可以看出我们的方法在所有评估标准下都取得了新的最先进性能。具体而言,我们的方法比SDI [5]在mAPr0.5和mAPr0.75上分别提高了14.3%和11.1%。同时,与在这个任务上的最先进方法BBTP [7]相比,我们的方法在mAPr0.7和mAPr0.75上显著优于它,分别约为5.1%和5.8%。在mAPr0.75上的性能提高比mAPr0.7和mAPr0.5更多,这也表明我们的方法可以生成保留物体结构细节的掩模。一个有趣的观察是,我们的方法甚至比完全监督的方法SDS [55]表现更好。
在图6中,我们比较了我们的方法与其他一些公开可用源代码的最先进方法之间的一些定性结果。具体而言,我们将我们的结果与SDI [5]进行了BSSS任务的比较,与BBTP [7]进行了BSIS任务的比较。可以看出,与其他方法相比,我们的方法产生了覆盖物体细节的更好的分割掩模。 在表3中,我们对我们的方法与其他方法在COCO test-dev数据集上进行了比较。可以看出,我们的方法比LIID [61]表现要好得多,mAPr50提高了16.8%。此外,我们的方法甚至与完全监督的方法MNC [60]表现相竞争,这也表明了我们方法的有效性。
表1 在PASCAL VOC 2012验证集和测试集上与其他方法的比较,针对BSSS任务。F:完全监督。S:涂鸦监督。B:边界框监督。Seg.:完全监督分割模型。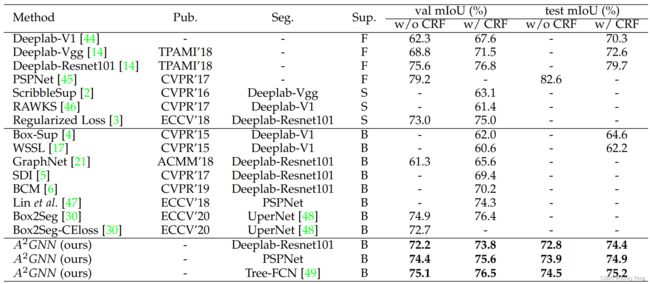
表2 在PASCAL VOC 2012验证集上与其他方法的比较,针对BSIS任务。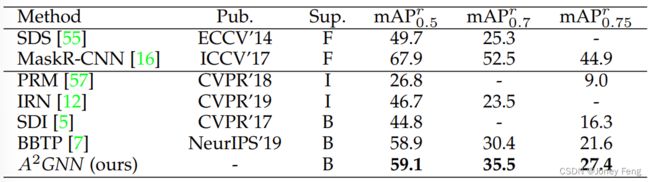
6.3.消融研究
由于BSIS的伪标签是从BSSS任务中生成的,因此在本节中,我们将仅对BSSS任务进行消融研究。我们只在训练集上评估伪标签的mIoU,而不涉及验证集和测试集。
在图7中,我们对BSSS任务中的我们的A2GNN与其他方法进行了比较。可以看出,我们的A2GNN比其他GNN方法表现要好得多,仅使用交叉熵损失时,相比AGNN [32]提高了1.9%的mIoU,而完整的A2GNN在大幅度上表现优于AGNN [32](提高了6.9%)。
在表4(a)中,我们探索了我们方法中不同模块对生成伪标签的影响。Baseline表示我们使用SEAM [38]生成前景种子标签,然后使用边界框监督生成背景。RW表示我们遵循SEAM [38]使用随机游走生成伪标签。可以看出,所提出的方法表现优于基准方法。每个模块都显著提高了性能。
在表4(b)中,我们研究了我们的联合损失函数的有效性。可以看出,与仅采用交叉熵损失的A2GNN相比,我们的MP损失可以提高其性能2.1%,验证了我们的MP损失的有效性。通过一致性检查,性能提高到77.2%,表明了我们提出的一致性检查机制的有效性。当通过这三个损失以及我们的一致性检查机制进行联合优化时,性能进一步提高到78.8%。
在表4(c)中,我们研究了构建图的不同方法。超像素(S.P.)表示我们采用[21]来生成图节点及其特征。距离(Dis.)表示我们使用特征图的L1距离来构建图边。可以看出,当直接使用特征图中的像素作为节点时,性能有所提高,表明其比使用超像素更准确。当我们使用我们的亲和力CNN来构建图时,性能显著提高了4.1%,这表明我们的方法可以构建比其他方法更准确的图。
在表4(d)中,我们研究了我们的亲和力注意力层的有效性。可以发现,如果我们单独使用注意力模块或亲和力模块,mIoU得分都低于完整的A2GNN,这表明我们设计的GNN层的有效性。 在表4(e)中,我们展示了我们提出的亲和力CNN的损失函数和标签的联合影响。可以看出,当仅使用LAc时,MF标签的表现优于Mg标签。这是因为Mg标签仅提供了有限的像素,并且这些像素通常位于对象的区分部分(如人的头部)。当仅使用LAc时,这样有限的标签是不足够的。当我们同时使用LAc和LAr时,Mg标签的表现要比MF标签好得多,这表明LAr可以准确地将有标签区域传播到无标签区域。
此外,我们还分析了对我们的A2GNN的监督的影响。具体地,我们分别比较了在我们的A2GNN中使用MF(在公式(4)中)和Mg(在公式(5)中)作为监督时的结果。与MF相比,Mg具有较少的注释节点,但每个注释更可靠。在Pascal VOC 2012训练集上,MF和Mg的mIoU得分分别为73.2%和78.8%。这个结果验证了高可信标签的利用的有效性。
表3 在COCO test-dev数据集上,对弱监督实例分割进行了与其他方法的比较。E:额外的数据集[58]具有实例级注释。S4Net:显著实例分割模型[59]。
图6. 我们的A2GNN和其他最先进方法在PASCAL VOC 2012验证数据集上的定性结果。(a) 原始图像。(b) 语义分割的真值。(c) BSSS的SDI [5]。(d) 我们的BSSS结果。(e) BSIS的BBTP [7]。(f) 我们的BSIS结果。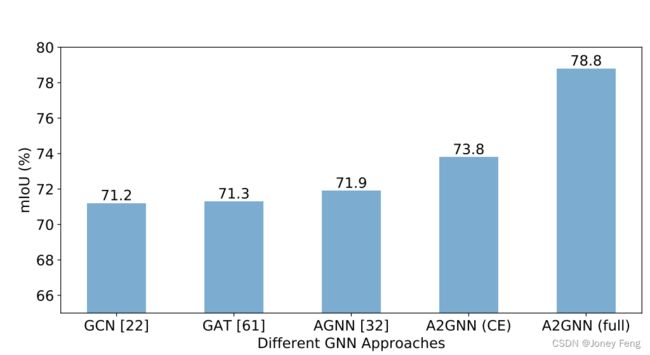
图7. 在Pascal VOC 2012训练集上,我们的A2GNN与其他GNNs(GCN [22],GAT [62],AGNN [32])的比较。"CE"表示仅使用交叉熵损失。
表4 对Pascal VOC 2012训练数据集进行的BSSS消融研究(a) 我们方法中不同模块的评估。RW:随机游走[38]。H:亲和力注意层。C.C.:一致性检查。 (b) 我们A2GNN中损失函数的评估。C.C.:一致性检查。 (c) 构建图的不同方法的评估。S.P.:超像素。Feat.:特征图。Dis.:距离。Aff:亲和力CNN。 (d) A2GNN中亲和力注意层的评估。 (e) 使用不同种子标签对亲和力CNN和损失函数的性能比较。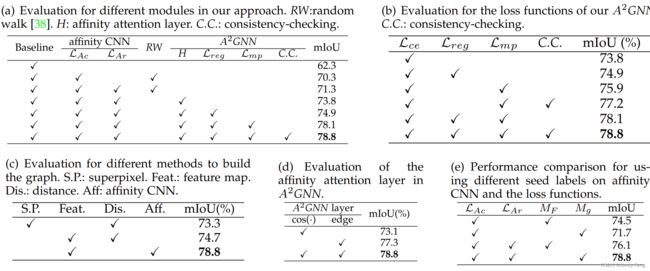
7.应用到其它弱监督语义分割任务
为了将我们的方法应用于其他弱监督语义分割任务,例如涂鸦、点和图像级别,我们需要忽略我们提出的MP损失(第4.5.3节)和一致性检查(第4.5.4节),因为它们依赖于边界框监督。此外,我们需要将不同的弱监督信号转换为像素级种子标签。除此之外,所有其他步骤和参数与BSSS任务中的相同。在接下来的章节中,我们将介绍如何将不同的弱监督信号转换为像素级种子标签,然后我们将报告这些任务的实验结果。
表5 在PASCAL VOC 2012验证和测试数据集上与其他最先进方法的比较。Sup.:分割模型。F:全监督。S:涂鸦。P:点。I:图像级别标签。E:额外显著数据集。“highlight”表示特定任务的最佳性能。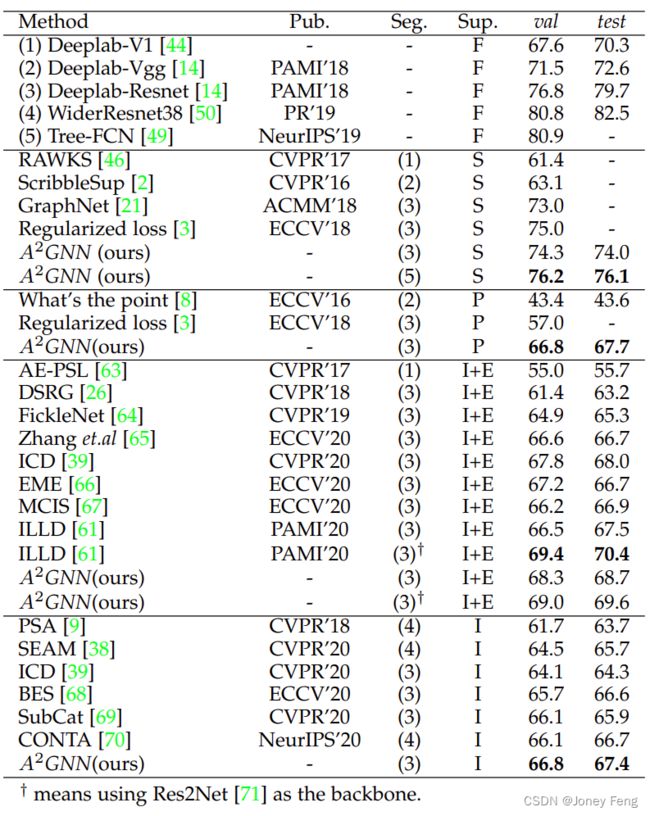
7.1.生成像素级种子标签
如第3节所述,初始化弱监督任务的常见做法是从给定的弱监督生成像素级种子标签。对于不同的弱监督,我们使用不同的方法将它们转换为像素级种子标签。
图像级别监督:我们直接使用公式(5)中定义的M0来训练我们的亲和力CNN,并将其用作训练我们的A2GNN的Mg。最终的伪标签使用比例(1:3)来融合我们的结果和随机游走的结果来生成。
涂鸦监督:对于涂鸦监督的语义分割任务,对于图像中的每个类别(包括背景),它提供一个或多个涂鸦作为标签。我们使用超像素方法[23]来从初始涂鸦中获取扩展的标签MS。为了获得训练我们的亲和力CNN的种子标签,我们将MS与M0I合并,使用以下规则:如果MS中的像素标签已知(不是255),则Mg中相应的标签将与MS相同。否则,像素标签将被视为与M0I相同的标签。为了生成A2GNN的节点标签,我们直接使用Mg = MS,因为它为图像中约10%的像素提供了准确的标签。
点监督:对于点监督的语义分割,对于图像中的每个对象,它提供一个点作为监督,并且没有背景的注释。为了训练我们的亲和力CNN,我们直接使用M0I。为了为A2GNN生成节点监督,我们使用超像素方法[23]从初始点标签中获取扩展标签MP。然后使用与涂鸦任务相同的设置生成Mg。
对于我们的亲和力CNN和A2GNN,我们使用与我们的边界框任务相同的设置。
图8. 我们在PASCAL VOC 2012验证数据集上展示了我们A2GNN的定性结果。我们展示了不同级别的监督信号的结果(第3-6行)。较强的监督信号(例如涂鸦)比较弱的信号(例如点、图像级别标签)产生更准确的结果。
7.2.实验评估
在表5中,我们比较了我们的方法与其他最先进的弱监督语义分割方法之间的性能。 对于点监督,我们的方法在PASCAL VOC验证集和测试集上分别达到了66.8%和67.7%的mIoU,实现了最先进的性能。与其他两种方法[8]和[3]相比,我们的方法在PASCAL VOC 2012验证数据集上的mIoU分别增加了23.4%和9.8%。
对于图像级别的监督任务,我们的A2GNN在验证集和测试集上的mIoU分别达到了66.8%和67.4%。值得注意的是,PSA [9]、SEAM [38]和CONTA [70]使用Wider ResNet-38 [50]作为分割模型,其上限比Deeplab-Resnet101 [14]更高。使用Deeplab-Resnet101 [14]作为分割模型,Subcat [69]是这个任务的最先进方法,但它需要多轮训练过程。此外,我们的方法使用Deeplab-Resnet101 [14]实现了66.8%的mIoU,在验证集上达到了我们的上限的87.0%(Deeplab-Resnet [14]的76.8%的mIoU得分)。
此外,在图像级别的监督任务中,一些方法[26],[39],[61],[64]使用显著性模型和额外的像素级显著性数据集[72]或实例像素级显著性数据集[58]生成更准确的伪标签。遵循这些方法,我们也使用了显著性模型。具体而言,我们使用了ICD[39]中的显著性方法[73]生成初始种子标签,然后使用我们的方法生成最终的伪标签。从表5可以看出,我们的方法在其他方法(使用ResNet101作为骨干网络)上表现出色。在类似于ILLD [61]的情况下,我们还使用Res2Net [71]作为分割骨干网络进行评估,我们的性能进一步提升到69.0%和69.6%。对于这种设置,我们没有为种子标签设计特定的去噪方案。尽管如此,我们的性能与其他最先进的方法相当,例如[61],这也证明了我们的方法可以很好地推广到所有弱监督任务中。
对于涂鸦监督任务,我们的方法也实现了最新的最先进性能。 在表6中,我们进行了对PASCAL VOC训练集上伪标签的比较评估。可以看出我们的方法优于其他方法。与最先进的方法SEAM [38]相比,我们的方法获得了1.7%的mIoU改进。我们还比较了我们的方法和Box2Seg [30]之间的伪标签质量。可以看出我们的方法大幅优于Box2Seg [30],提高了5.2%的mIoU。 在图8中,我们还展示了上述三个任务的更多定性结果。可以看出,更强的监督导致更好的性能,并保留更多的分割细节。
表6 在PASCAL VOC训练数据集上评估伪标签的mIoU(%)性能比较。
8.概括
我们提出了一种新的系统A2GNN,用于边界框监督的语义分割任务。通过我们提出的亲和度注意力层,即使输入图中存在噪声,特征也可以被准确地聚合。此外,为了减轻标签稀缺性问题,我们进一步提出了MP损失和一种一致性检查机制,为模型优化提供更可靠的指导。广泛的实验证明了我们提出的方法的有效性。此外,所提出的方法还可以应用于边界框监督的实例分割和其他弱监督的语义分割任务。作为未来的工作,我们将研究如何生成更可靠的种子标签和更准确的图,从而减轻输入图中的噪声水平,使我们的A2GNN能够生成更准确的伪标签。