pytorch深度学习 --CNN(basic)
浅谈CNN卷积神经网络(1)
- 一、Convolutional Neural Network
-
- 1. CNN的几层网络结构
- 2.卷积运算过程
-
- 1.Convolution – Single Input Channel(单通道运算)
- 2.Convolution – 3 Input Channels(三通道)
- 3.Convolution – padding
- 4.Max Pooling Layer
- (1)A Simple Convolutional Neural Network
- 二、卷积神经网络实现MINST数据集数字识别代码

一、Convolutional Neural Network
1. CNN的几层网络结构
- 输入层:Input Layer
- 卷积计算层:CONV Layer
- ReLU激励层:ReLU Incentive Layer
- 池化层:Pooling Layer
- 全连接层(线性层):Fully Connect Layer
本文研究数据集为MINST数据集,以达到对其进行10分类。MINST数据集它的样本图片都是一通道、宽高为28,即1* 28* 28。

首先输入MINST数据集,为1 * 28*28,经过一个5 * 5的卷积得到features maps为4 * 24 *24,在做卷积的过程中,输入的样本会丧失掉原有的空间结构,但其会保留空间信息。接下来通过一个2 * 2的下采样得到4 * 12 * 12的Fearture maps,而我们下采样的目的就是为了减少我们数据的数据量,以达到降低它的运算要求。经过过一系列的卷积和下采样会得到一个8 * 4 * 4的Feature maps。而后我们通过全连接层将其展开成一列线性,再将其映射分类成0-10,共10各类别。
一般称对前面的输入进行卷积和下采样的流程为Feature EXtraction,即特征提取器,将图像的特征信息提取出来。而后面部分称之为分类器,即我们通过某种方法通过它的特征将其分类,此处分为10类。
2.卷积运算过程
1.Convolution – Single Input Channel(单通道运算)
输入为1x5x5,卷积核为3x3。根据kernel为3x3,我们首先在input输入里以左上角开始画出3x3的框,对它和kernel进行数乘。从而得到输出值。接下来我们滑动窗口,得到剩余的输出值。


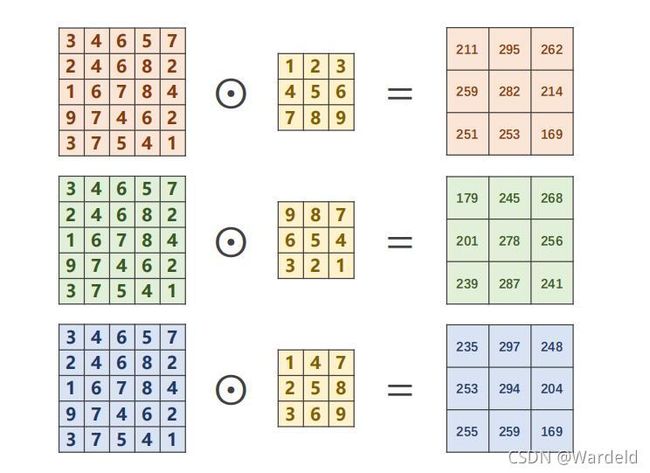
2.Convolution – 3 Input Channels(三通道)
在日常生活学习中,我们一般常用的是三通道进行卷积,而我们规定一般有几个通道,就会有几个卷积核。一个通道对应一个输出,三个通道对应三个输出,最后对其进行加权求和就可得到最后输出。

代码如下(示例):
import torch
in_channels, out_channels= 5, 10
width, height = 100, 100
kernel_size = 3
batch_size = 1
input = torch.randn(batch_size,
in_channels,
width,
height)
conv_layer = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)
输出结果为
torch.Size([1, 5, 100, 100])
torch.Size([1, 10, 98, 98])
torch.Size([10, 5, 3, 3])
3.Convolution – padding
当我们输入为5x5,卷积核为3x3,我们想让他的输出也为5x5时,此时要对它的输入作扩充,外圈加0,变成7x7,从而乘以卷积核就可得到一个5x5的输出。


代码如下(示例):
import torch
input = [3, 4, 7, 8, 9,
4, 5, 7, 5, 4,
1, 2, 5, 3, 4,
1, 2, 5, 2, 4,
5, 6, 5, 3, 8]
# 将输入转化为1*1*5*5,,即一张照片、一个通道、w*h=5*5
input = torch.Tensor(input).view(1, 1, 5, 5)
# 输入输出为1,卷积核为3,机进行3*3卷积,外部填充1,无偏置量
# conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
# 输入输出为1,卷积核为3,机进行3*3卷积,卷积核滑动步长为2,无偏置量
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False)
kernel = torch.Tensor([1, 2, 3, 4, 5, 6, 7, 8, 9]).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(kernel.shape)
print(input)
print(kernel)
print(output)
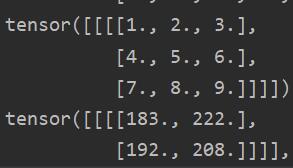
**注意:**此处padding为1,即外部进行填充一圈0,窗口滑动步长为用stride来表示,bias为偏置量。
输出部分结果为
4.Max Pooling Layer
在下采样过程中我们用的最多的就是最大池化层,在做Max Pooling 的过程中,默认stride为2,例如对下面4x4的输入进行2x2的Max Pooling,我们将其输入划分为4个小的2x2的,在各自的2x2中找出最大值。即为输出所得到的。

(1)A Simple Convolutional Neural Network
下面是一个简单的CNN神经网络,输入为1x28x28,经过5x5卷积,输入通道为1,输出通道为10.得到一个10x24x24.然后进过最大池化得到10x12x12的feature maps。并经过后续一系列的卷积、最大池化和全连接层得到最后输出为10个分类的线性向量。

二、卷积神经网络实现MINST数据集数字识别代码
# -*- coding:utf-8 -*-
"""
作者:${Mr.wu}
日期:2021年11月04日
"""
import torch
import torch.nn.functional as F
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
batch_size = 64
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]
)
train_datasets = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loder = DataLoader(train_datasets, shuffle=True, batch_size=batch_size)
test_datasets = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(train_datasets, shuffle=False, batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
model = model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimzer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loder, 0):
inputs, targe = data
inputs, targe = inputs.to(device), targe.to(device)
optimzer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targe)
loss.backward()
optimzer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%5d],loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, targe = data
inputs, targe = inputs.to(device), targe.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += targe.size(0)
correct += (predicted == targe).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for i in range(10):
train(i)
test()
执行结果:
