LLaMA模型论文《LLaMA: Open and Efficient Foundation Language Models》阅读笔记
文章目录
-
- 1. 简介
- 2.方法
-
- 2.1 预训练数据
- 2.2 网络架构
- 2.3 优化器
- 2.4 高效的实现
- 3.论文其余部分
- 4. 参考资料
1. 简介
LLaMA是meta在2023年2月开源的大模型,在这之后,很多开源模型都是基于LLaMA的,比如斯坦福大学的羊驼模型。
LLaMA的重点是比通常情况下使用更多的语料,来训练一系列可在各种推理预算下实现可能的最佳性能的语言模型。
摘要翻译:我们在此介绍LLaMA,这是一个参数范围从7B到65B的基础语言模型集合。我们在数万亿个token上训练了我们的模型,并表明在不使用私有和不可公开获得的数据集的情况下,仅仅使用公开可用的数据,是有可能训练最先进的模型的。特别的是,LLaMA-13B在大多数基准测试中都优于175B大小的GPT-3,而LLaMA-65B可以与最好的模型Chinchilla-70B and PaLM-540B匹敌。我们向研究社区开源所有的模型。
2.方法
2.1 预训练数据
训练集数据覆盖了不同的领域的数据,具体如下图。值得注意的是,这些数据集都是可公开获得的,不包括私有数据。
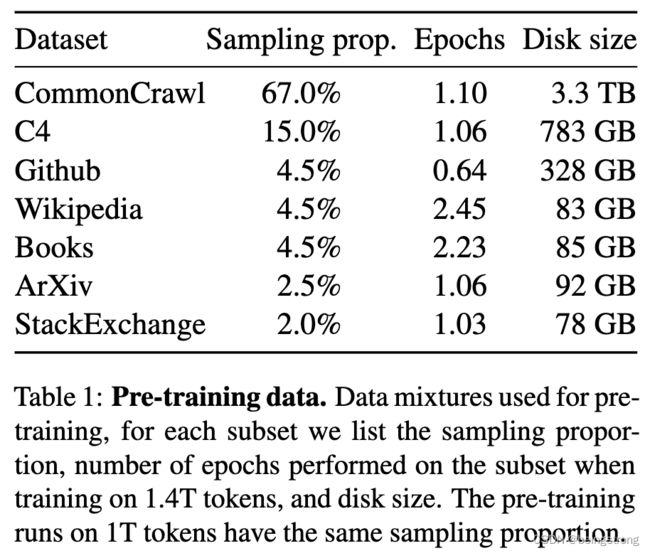
数据集的详情如下:
English CommonCrawl [67%]:用CCNet pipeline的方式预处理了从2017至2020年的5个CommonCrawl dump: 在行级别去重数据,用fastText线性分类器进行语言判断并去掉非英语页面,使用n-gram语言模型过滤掉低质量内容。训练了一个线性模型来分类页面是否是Wikipedia的参考页或随机抽样的页面,并丢掉没有被分类为参考页的页面。
C4 [15%]: 预处理过程也有去重和质量过滤,与CCNet采用了不一样的质量过滤,主要采用启发式规则如一个网页中标点负荷或句子和词的个数。
Github [4.5%]: 使用Google Bigquery上的Github数据集,只保留Apache、BSD、MIT开源协议的项目。根据代码行的长度、字母数字并用的字符的比例采用启发式规则过滤掉低质量文件,并用正则表达式去掉样板文件如头文件。最后用精确匹配的方式在文件级别上删除重复数据。
Wikipedia [4.5%]: 使用从2022年6-8月的Wikipedia dumps文件,覆盖20种Latin或Cyrillic语言: bg, ca, cs, da, de, en, es, fr, hr, hu, it,nl, pl, pt, ro, ru, sl, sr, sv, uk。去掉数据中的超链接、注释及其他格式化样板文件。
Gutenberg and Books3 [4.5%]: 这是两个书本语料数据集,在书本级别进行去重,去掉超过90%重复内容的书本。
ArXiv [2.5%]: 这个数据集是为了添加科学数据,去掉参考数目和第一部分之前的所有内容。并去掉了.tex文件中的注释以及用户编写的内联扩展定义和宏,以提高论文之间的一致性。
Stack Exchange [2%]: 保留前28个数据量的网站的数据,去掉了HTML 标签,并对答案按照评分从高到低排序。
Tokenizer: 使用BPE 算法,采用SentencePiece的实现。并且将所有数字拆分为单独的数字,并回退到byte来分解未知的 UTF-8 字符。
最后生成的整个训练数据集在分词后包括大约1.4T的tokens。除了Wikipedia和书籍数据集被用来训练了2个epoch外,其他的数据在训练阶段都只被使用了一次。
2.2 网络架构
网络也是基于transformer架构,在原始transformer上做了修改,具体如下(括号中的模型名表示曾受此模型启发):
Pre-normalization [GPT-3]: 对transfromer的每一个sub-layer的输入作归一化,使用了RMSNorm 归一化函数。
SwiGLU activation function [PaLM]: 将ReLu激活函数替换成SwiGLU激活函数。使用 2 3 4 d \frac{2}{3}4d 324d的尺度(PaLM的尺度是 4 d 4d 4d)
Rotary Embeddings [GPTNeo]: 在网络的每一层使用rotary positional embeddings (RoPE),而不是原论文中的绝对位置嵌入向量。
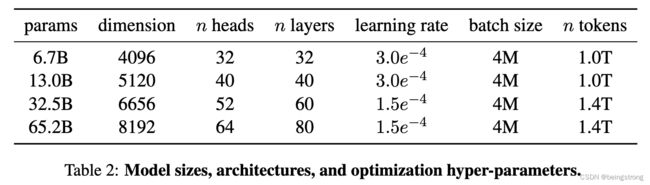
各个大小的模型的超参数如下图
2.3 优化器
- 模型使用AdamW 优化器,对应的超参: β 1 = 0.9 , β 2 = 0.95 \beta_1 = 0.9, \ \beta_2 = 0.95 β1=0.9, β2=0.95
- 使用cosine learning rate schedule, 最后的学习率是最大学习的10%
- 使用0.1的weight decay, 大小为1.0的gradient clipping
- 使用2000步的warmup,随模型大小改变学习率和batch size(如上图,不过从图片里batch size看起来貌似是一样的)
2.4 高效的实现
为了提高模型的训练速度,做了以下优化操作:
- 使用causal multi-head attention的有效实现来减少内存使用和运行时间。用的是xformers的代码,通过不存储被掩码的注意力权重和key/query分数来实现的。
- 用checkpointing减少反向传播过程中要重复计算的激活函数的量。也就是存储了计算昂贵的激活函数,比如线性层的输出,通过自己实现反向传播层而不是使用pytorch的实现来达到这个目的。 为了从这个改动中获益,需要使用模型和序列并行来减少模型的内存,此外,还尽可能地重叠激活计算和 GPU 之间的网络通信(由于 all_reduce 操作)。
当训练65B参数的模型时,实现代码可以在2048块的80GB内存的A100 GPU上达到 380 t o k e n s / s e c / G P U 380\ tokens/sec/GPU 380 tokens/sec/GPU的处理速度,也就是用1.4T tokens的数据集训练模型大约21天。
3.论文其余部分
-
与GPT-3一样,考虑模型在Zero-shot和few-shot任务上的效果,在20个benchmarks进行了验证实验,考虑到LLaMA最大的模型为65B,其性能还是不错的。
-
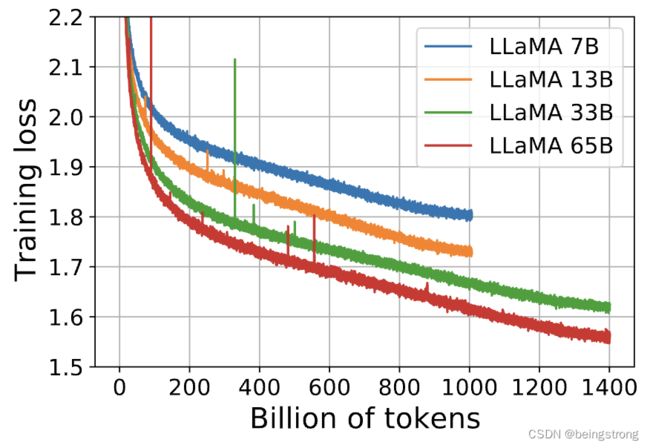
在模型训练过程中,也跟踪了模型在问答和常识基准库上的效果。大部分基准库上模型随着训练时间逐渐提升。

- 作者们对大模型的偏见、毒性、错误信息也进行评估,在RealToxicityPrompts上发现模型越大,毒性越强。
- 对5个月训练期间的碳足迹进行估算,大约花了2,638 MWh电,大概1,015 t的二氧化碳。
4. 参考资料
- Touvron, Hugo, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozière, et al. n.d. “LLaMA: Open and Efficient Foundation Language Models.”
- 开源代码