网络爬虫协程案例(M3U8电影抓取)
文章目录
- 网页分析
- 数据抓取
-
- 获取m3u8文件地址
- 获取所有视频片段
- 视频解密
- 视频合并
- 完整代码
抓取目标:新版6v电影网电影资源
以电影《逃出白垩纪》为例:
https://www.66s.cc/e/DownSys/play/?classid=4&id=20778&pathid1=0&bf=0
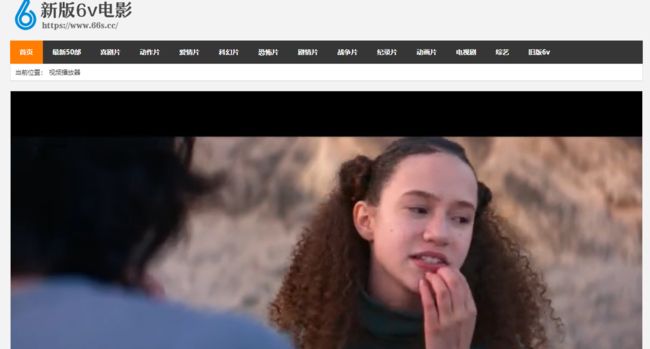
网页分析
打开网页后,按F12打开开发者工具,首先清空已加载的数据包,点击视频让其播放,可以看到在视频播放的期间不断会有新的数据包生成,并且这些数据包都是以.ts结尾。
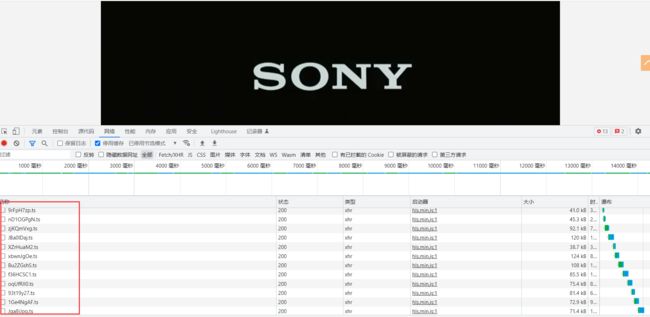
再次刷新页面,可以看到下方生成了一个m3u8数据包,打开该数据包点击预览,可以看到该数据包的返回内容。

从该数据包的返回内容不难看出,该数据包中的内容对应的就是每个视频小片段。我们只需要拿到该数据包,就能通过该数据包去获取所有的小视频片段,然后将所有的小视频片段合成在一起即可获得完整视频文件。
我们可以复制m3u8文件中的一个视频地址,将其下载到本地,但是在将其打开的时候又出现了问题,该片段无法播放。
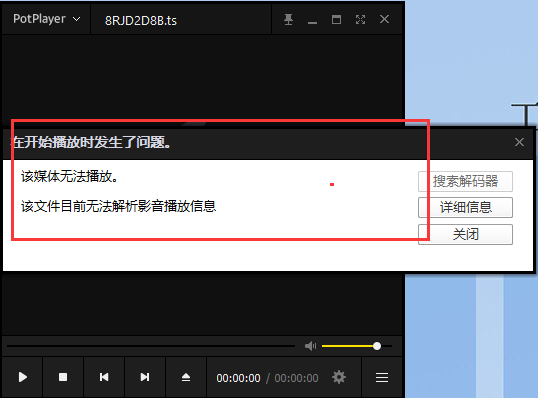
原因是因为,每个小片段视频都被加密了。
再次回到m3u8文件,我们观察发现文件中有这样一段代码。
#EXT-X-KEY:METHOD=AES-128,URI="https://baidu.shanshanku.com/20230407/pEMMQxLE/1200kb/hls/key.key"

该内容表示视频被加密了,使用的是AES加密算法,密钥文件在链接 https://baidu.shanshanku.com/20230407/pEMMQxLE/1200kb/hls/key.key
我们只需拿到该密钥文件,对视频内容进行解密即可。(注意:并不是所有视频资源都被加密,根据实际情况进行选择)。
到现在为止所有需要用到的地址都存储在m3u8文件,那么如何通过视频地址获取到其对应的m3u8文件地址呢?
网页首页资源,搜索iframe,在iframe中存储着实际的视频播放页面。

复制地址https://baidu.sd-play.com/share/pVP2a2If0TuCIGBU,在浏览器中打开可以看到实际视频页面内容。

然后再该页面中打开开发者工具,查看页面源代码,可以看到在该页面中有对应的m3u8地址。
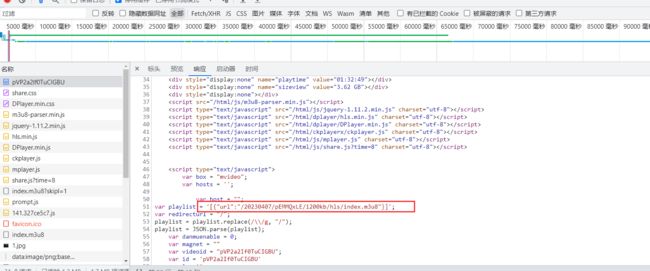
到此,网页分析过程结束。
数据抓取
视频分析过程比较简单,但是实际在抓取视频时,并没有这么简单。
抓取步骤如下:
- 获取
m3u8文件地址 - 根据
m3u8文件,获取所有视频片段 - 观察视频是否经过加密,如果经过加密则需要进行解密
- 合并所有解密后的视频片段
获取m3u8文件地址
注意在这里我们需要访问电影首页,那么就顺便将电影名称也自动获取到,后续在进行相关数据的存储时可以存储到文件夹中。
并且经过分析我们发现,并不是所有的电影iframe都对应的是实际的视频播放页面地址,有部分电影是直接对应的m3u8文件,这种情况需要进一步处理。
import requests
from lxml import etree
import re
url = 'https://www.66s.cc/e/DownSys/play/?classid=2&id=20862&pathid1=0&bf=0' # 66v电影网视频地址
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
}
def get_m3u8_url(url: str):
"""
这里m3u8地址有多种情况
1. iframe直接链接到m3u8文件
2. 通过一个中间包
3. 通过两个中间包
"""
res = requests.get(url, headers=headers)
res_html = etree.HTML(res.text)
# 获取电影名称
video_name = res_html.xpath('//title/text()')[0].split('-')[0].strip()
# 获取iframe地址
iframe_url = str(res_html.xpath('//iframe/@src')[0])
# iframe直接链接到m3u8文件
if iframe_url.endswith('m3u8'):
return iframe_url, video_name
# 通过一个中间包,获取m3u8文件地址
iframe_res = requests.get(iframe_url, headers=headers)
m3u8_url = re.findall("url: '(.*?)',", iframe_res.text, re.S)
if len(m3u8_url) == 0:
m3u8_url = iframe_url.rsplit('/', maxsplit=2)[0] + re.findall('"url":"(.*?)"', iframe_res.text, re.S)[0]
else:
m3u8_url = m3u8_url[0]
print(m3u8_url)
return m3u8_url, video_name
if __name__ == '__main__':
url = 'https://www.66s.cc/e/DownSys/play/?classid=4&id=20778&pathid1=0&bf=0' # 66v电影网视频地址
# 获取m3u8地址和电影名称
# get_m3u8_url(url)
m3u8_url, video_name = get_m3u8_url(url)

获取所有视频片段
首先,解析m3u8文件,将其密钥和所有视频地址存储下来。
import os
# 创建电影名称文件夹
def makedir_video(video_name: str):
if not os.path.exists(video_name):
os.mkdir(video_name)
# 获取所有的视频地址
def get_videos_url(video_name, m3u8_url: str):
res = requests.get(m3u8_url, headers=headers)
# 保存m3u8文件
m3u8_filename = m3u8_url.split(r'/')[-1]
with open(os.path.join(video_name, m3u8_filename), 'w', encoding='GBK') as f:
f.write(res.text)
all_videos_url = []
for i in res.text.strip().split('\n'):
# 判断视频是否加密,如果加密则将秘钥存储下来文件名为:enc.key,如果未加密则不存储任何文件
if 'AES' in i and 'KEY' in i:
key_uri = re.findall('URI="(.*?)"', i)[0]
if "http" not in key_uri:
key_uri = r'/'.join(m3u8_url.split(r'/')[:-1]) + '/' + key_uri
key = requests.get(key_uri, headers=headers).content
with open(os.path.join(video_name, 'enc.key'), 'wb') as f:
f.write(key)
if i.startswith('#') or len(i) == 0:
continue
all_videos_url.append(i)
print(all_videos_url)
return all_videos_url
if __name__ == '__main__':
url = 'https://www.66s.cc/e/DownSys/play/?classid=4&id=20778&pathid1=0&bf=0' # 66v电影网视频地址
# 获取m3u8地址和电影名称
# get_m3u8_url(url)
m3u8_url, video_name = get_m3u8_url(url)
# # # # 创建电影名称文件夹
makedir_video(video_name)
# # # # 根据m3u8地址,获取所有的视频地址,并判断是否加密
all_videos = get_videos_url(video_name, m3u8_url)

运行完毕后再对应电影的文件夹下会生成index.m3u8文件和enc.key文件

现在我们已经有了所有的视频地址,接下来只需要根据视频地址将所有的视频下载下来即可。
由于总共视频片段较多,如果使用传统的代码运行方式进行运行,将会十分耗时,故在这里我们采用协程异步操作来进行访问和下载。
由于使用协程会对服务器产生较大的访问压力,所有在这里我们引入信号量去控制访问协程的并发数,减轻服务器访问压力。
其次,由于这里的请求采用的是异步操作,所有很有可能出现中间部分视频片段第一次下载失败的情况,在这里我们处理的方式是,先让其重复访问10次,如果10次还没有访问到视频资源,则将其记录到对应的文件中,便于后续对其进行进一步分析,为什么没有访问到资源?
import asyncio
import aiofiles
import aiohttp
async def download_video(filepath, video_url, sem):
async with sem: # 使用信号量控制访问频率
for i in range(10):
try:
video_name = video_url.split(r'/')[-1]
async with aiohttp.ClientSession() as session:
async with session.get(video_url, headers=headers) as res:
content = await res.content.read()
async with aiofiles.open(os.path.join(filepath, video_name), 'wb') as f:
await f.write(content)
break
except Exception as e:
if i == 9:
with open(filepath+'_Error.txt', 'a', encoding='utf-8') as f:
f.write(video_url+'\n')
print(f'----- {video_name}下载失败,请求次数达到上限({i+1}次),已写入文件{filepath+"_Error.txt"} -----')
break
print(f'----- {video_name}下载失败,正在重试{i} -----')
print(e)
async def download_all_videos(sem_num, filepath, all_videos_url):
# 信号量, 用来控制协程的并发量
sem = asyncio.Semaphore(sem_num) # 极个别电影需要控制在5左右
tasks = []
for video_url in all_videos_url:
tasks.append(asyncio.create_task(download_video(filepath, video_url, sem)))
await asyncio.wait(tasks)
if __name__ == '__main__':
url = 'https://www.66s.cc/e/DownSys/play/?classid=4&id=20778&pathid1=0&bf=0' # 66v电影网视频地址
# 获取m3u8地址和电影名称
# get_m3u8_url(url)
m3u8_url, video_name = get_m3u8_url(url)
# # # # 创建电影名称文件夹
makedir_video(video_name)
# # # # 根据m3u8地址,获取所有的视频地址,并判断是否加密
all_videos = get_videos_url(video_name, m3u8_url)
# # # # 根据视频地址下载视频
sem_num = 100 # 用于控制并发量
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(download_all_videos(sem_num, video_name, all_videos))
可以看到数据已经下载成功。
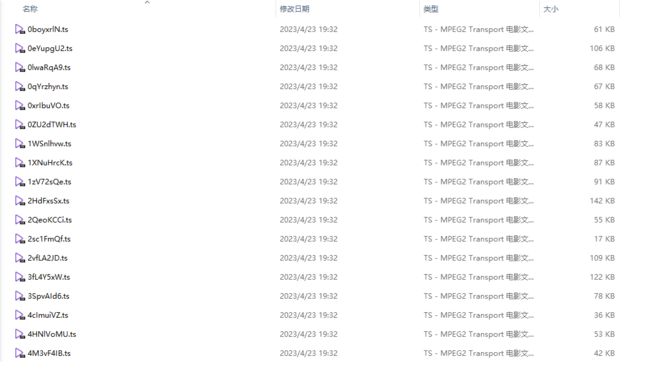
并且是有部分片段第一次是无法获取到数据的,并且越往后走这种情况出现得越多。我们也可以在请求过程中加入timeout参数,控制代码一定时间内无响应的话就中断请求,重新请求,加快效率。否则最后几个包可能需要耗费大量的时间才能抓下来。

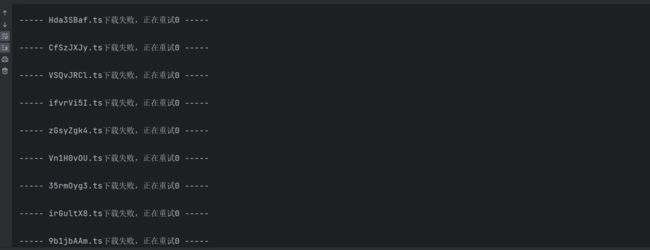
但是大部分经过二次访问都可以获取到视频片段。

例如这里的Hda3SBaf.ts片段,第一次没有获取到,但是第二次获取到了,在文件夹中也能搜索到。
视频解密
跟我们前面分析的一样,这里的视频文件是无法打开的。
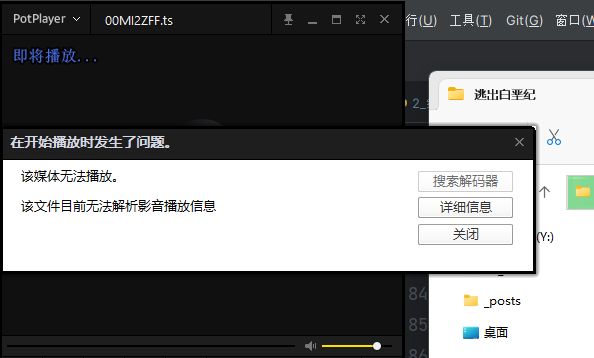
而且前面我们已经将其对应的密钥文存储到了enc.key文件中。直接使用该文件对视频进行解密即可。
由于解密过程是需要先将视频读取进来,解密完成后还要将其再次存储下来,同样需要大量的IO操作,故也使用的是协程异步的方式去操作。
解密使用的是AES算法,要调用AES进行解密需要先下载pycryptodome,下载完毕后即可使用from Crypto.Cipher import AES方式进行调用。
这里为了适配没有加密的视频,做了一个判断,是否有加密文件存在,如果有才是加密的视频。如果没有则直接跳过此步骤。
from Crypto.Cipher import AES # pip install pycryptodome
async def parse_video(video_file, video_name, new_video_name, key):
print(os.path.join(video_name, video_file))
print(os.path.join(new_video_name, video_file))
async with aiofiles.open(os.path.join(video_name, video_file), 'rb') as f1, aiofiles.open(os.path.join(new_video_name, video_file), 'wb') as f2:
content = await f1.read()
# aes解密视频
aes = AES.new(key=key, mode=AES.MODE_CBC, IV=b'0000000000000000')
new_content = aes.decrypt(content)
new_content = PKCS7_unpad(new_content)
await f2.write(new_content)
print(f'------ {video_file}解密成功 ------')
async def parse_all_videos(video_name):
all_file = os.listdir(video_name)
new_video_name = video_name + '_parse'
if 'enc.key' in all_file:
video_files = [i for i in all_file if i.endswith('ts')]
makedir_video(new_video_name)
print('------ 开始解密视频 ------')
# 读取秘钥
with open(os.path.join(video_name, 'enc.key'), 'rb') as f:
key = f.read()
# 创建协程任务
tasks = []
for video_file in video_files:
tasks.append(asyncio.create_task(parse_video(video_file, video_name, new_video_name, key)))
await asyncio.wait(tasks)
print('------ 视频解密完成 ------')
else:
os.rename(video_name, new_video_name)
print('------ 视频无加密 ------')
if __name__ == '__main__':
url = 'https://www.66s.cc/e/DownSys/play/?classid=4&id=20778&pathid1=0&bf=0' # 66v电影网视频地址
# 获取m3u8地址和电影名称
# get_m3u8_url(url)
m3u8_url, video_name = get_m3u8_url(url)
# # # # 创建电影名称文件夹
makedir_video(video_name)
# # # # 根据m3u8地址,获取所有的视频地址,并判断是否加密
all_videos = get_videos_url(video_name, m3u8_url)
# # # # 根据视频地址下载视频
sem_num = 100 # 用于控制并发量
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(download_all_videos(sem_num, video_name, all_videos))
# # # # 解密所有视频
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(parse_all_videos(video_name))
解密成功,在统计目录下会生成一个parse文件夹

具体视频
视频合并
视频合并可以采用windows或者Linux中自带的命令进行完成。
-
windows自带合成命令:copy /b a.ts+b.ts full.mp4 -
linux/mac命令:cat a.ts b.ts c.ts > xxx.mp4
并且视频的合并应该按照播放顺序进行合并,即m3u8文件的视频顺序。
def merge(video_name):
new_video_name = video_name + '_parse'
# 读取m3u8文件,获取文件正确顺序
m3u8_file = [i for i in os.listdir(video_name) if i.endswith('m3u8')][0] with open(os.path.join(video_name, m3u8_file)) as f:
video_sort = [i.split('/')[-1].strip() for i in f.readlines() if not i.startswith("#") and len(i) > 0]
n = 1
# 切换工作目录
os.chdir(new_video_name)
tmp = []
for i in range(len(video_sort)):
tmp.append(video_sort[i])
if i != 0 and i % 20 == 0:
# 每20个视频合并一次
cmd = f"copy /b {'+'.join(tmp)} {n}_copy.ts"
os.system(cmd)
tmp = [] # 新列表
n = n + 1
# 有剩余时将剩下的也合并完
cmd = f"copy /b {'+'.join(tmp)} {n}_copy.ts"
os.system(cmd)
n = n + 1
# 第二次大合并 1_copy.ts + 2_copy.ts + 3_copy.ts xxx.mp4
last_temp = []
for i in range(1, n):
last_temp.append(f"{i}_copy.ts")
# 最后一次合并
cmd = f"copy /b {'+'.join(last_temp)} {video_name}.mp4"
os.system(cmd)
if __name__ == '__main__':
url = 'https://www.66s.cc/e/DownSys/play/?classid=4&id=20778&pathid1=0&bf=0' # 66v电影网视频地址
# 获取m3u8地址和电影名称
# get_m3u8_url(url)
m3u8_url, video_name = get_m3u8_url(url)
# # # # 创建电影名称文件夹
makedir_video(video_name)
# # # # 根据m3u8地址,获取所有的视频地址,并判断是否加密
all_videos = get_videos_url(video_name, m3u8_url)
# # # # 根据视频地址下载视频
sem_num = 100 # 用于控制并发量
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(download_all_videos(sem_num, video_name, all_videos))
# # # # 解密所有视频
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(parse_all_videos(video_name))
# # # 合并视频
merge(video_name)
打开文件夹可以看到文件夹内有一个MP4文件。即为完整的视频资源。

打开后也可以直接播放

完整代码
"""
由于网吧电影网站已经关闭,经过查询将案例目标修改为6v电影 https://www.66s.cc/
1. 获取m3u8文件地址
2. 根据m3u8文件,获取所有分段视频
3. 观察视频是否经过加密,如果经过加密则需要进行解密
4. 合并所有解密视频
"""
import asyncio
import aiofiles
import aiohttp
import requests
from lxml import etree
import re
import os
from Crypto.Cipher import AES # pip install pycryptodome
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
}
def get_m3u8_url(url: str):
"""
这里m3u8地址有多种情况
1. iframe直接链接到m3u8文件
2. 通过一个中间包
3. 通过两个中间包
"""
res = requests.get(url, headers=headers)
res_html = etree.HTML(res.text)
# 获取电影名称
video_name = res_html.xpath('//title/text()')[0].split('-')[0].strip()
# 获取iframe地址
iframe_url = str(res_html.xpath('//iframe/@src')[0])
# iframe直接链接到m3u8文件
if iframe_url.endswith('m3u8'):
return iframe_url, video_name
# 通过一个中间包,获取m3u8文件地址
iframe_res = requests.get(iframe_url, headers=headers)
m3u8_url = re.findall("url: '(.*?)',", iframe_res.text, re.S)
if len(m3u8_url) == 0:
m3u8_url = iframe_url.rsplit('/', maxsplit=2)[0] + re.findall('"url":"(.*?)"', iframe_res.text, re.S)[0]
else:
m3u8_url = m3u8_url[0]
# print(m3u8_url)
return m3u8_url, video_name
def makedir_video(video_name: str):
if not os.path.exists(video_name):
os.mkdir(video_name)
def get_videos_url(video_name, m3u8_url: str):
res = requests.get(m3u8_url, headers=headers)
# 保存m3u8文件
m3u8_filename = m3u8_url.split(r'/')[-1]
with open(os.path.join(video_name, m3u8_filename), 'w', encoding='GBK') as f:
f.write(res.text)
all_videos_url = []
for i in res.text.strip().split('\n'):
# 判断视频是否加密,如果加密则将秘钥存储下来文件名为:enc.key,如果未加密则不存储任何文件
if 'AES' in i and 'KEY' in i:
key_uri = re.findall('URI="(.*?)"', i)[0]
if "http" not in key_uri:
key_uri = r'/'.join(m3u8_url.split(r'/')[:-1]) + '/' + key_uri
key = requests.get(key_uri, headers=headers).content
with open(os.path.join(video_name, 'enc.key'), 'wb') as f:
f.write(key)
if i.startswith('#') or len(i) == 0:
continue
all_videos_url.append(i)
# print(all_videos_url)
return all_videos_url
async def download_video(filepath, video_url, sem):
async with sem: # 使用信号量控制访问频率
for i in range(10):
try:
video_name = video_url.split(r'/')[-1]
async with aiohttp.ClientSession() as session:
async with session.get(video_url, headers=headers, timeout=10) as res:
content = await res.content.read()
async with aiofiles.open(os.path.join(filepath, video_name), 'wb') as f:
await f.write(content)
break
except Exception as e:
if i == 9:
with open(filepath+'_Error.txt', 'a', encoding='utf-8') as f:
f.write(video_url+'\n')
print(f'----- {video_name}下载失败,请求次数达到上限({i+1}次),已写入文件{filepath+"_Error.txt"} -----')
break
print(f'----- {video_name}下载失败,正在重试{i} -----')
print(e)
async def download_all_videos(sem_num, filepath, all_videos_url):
# 信号量, 用来控制协程的并发量
sem = asyncio.Semaphore(sem_num) # 极个别电影需要控制在5左右
tasks = []
for video_url in all_videos_url:
tasks.append(asyncio.create_task(download_video(filepath, video_url, sem)))
await asyncio.wait(tasks)
async def parse_video(video_file, video_name, new_video_name, key):
print(os.path.join(video_name, video_file))
print(os.path.join(new_video_name, video_file))
async with aiofiles.open(os.path.join(video_name, video_file), 'rb') as f1, aiofiles.open(os.path.join(new_video_name, video_file), 'wb') as f2:
content = await f1.read()
aes = AES.new(key=key, mode=AES.MODE_CBC, IV=b'0000000000000000')
new_content = aes.decrypt(content)
await f2.write(new_content)
print(f'------ {video_file}解密成功 ------')
async def parse_all_videos(video_name):
all_file = os.listdir(video_name)
new_video_name = video_name + '_parse'
if 'enc.key' in all_file:
video_files = [i for i in all_file if i.endswith('ts')]
makedir_video(new_video_name)
print('------ 开始解密视频 ------')
# 读取秘钥
with open(os.path.join(video_name, 'enc.key'), 'rb') as f:
key = f.read()
# 创建协程任务
tasks = []
for video_file in video_files:
tasks.append(asyncio.create_task(parse_video(video_file, video_name, new_video_name, key)))
await asyncio.wait(tasks)
print('------ 视频解密完成 ------')
else:
os.rename(video_name, new_video_name)
print('------ 视频无加密 ------')
def merge(video_name):
new_video_name = video_name + '_parse'
# 读取m3u8文件,获取文件正确顺序
m3u8_file = [i for i in os.listdir(video_name) if i.endswith('m3u8')][0]
with open(os.path.join(video_name, m3u8_file)) as f:
video_sort = [i.split('/')[-1].strip() for i in f.readlines() if not i.startswith("#") and len(i) > 0]
n = 1
# 切换工作目录
os.chdir(new_video_name)
tmp = []
for i in range(len(video_sort)):
tmp.append(video_sort[i])
if i != 0 and i % 20 == 0:
# 每20个视频合并一次
cmd = f"copy /b {'+'.join(tmp)} {n}_copy.ts"
os.system(cmd)
tmp = [] # 新列表
n = n + 1
# 有剩余时将剩下的也合并完
cmd = f"copy /b {'+'.join(tmp)} {n}_copy.ts"
os.system(cmd)
n = n + 1
# 第二次大合并 1_copy.ts + 2_copy.ts + 3_copy.ts xxx.mp4
last_temp = []
for i in range(1, n):
last_temp.append(f"{i}_copy.ts")
# 最后一次合并
cmd = f"copy /b {'+'.join(last_temp)} {video_name}.mp4"
os.system(cmd)
if __name__ == '__main__':
url = 'https://www.66s.cc/e/DownSys/play/?classid=4&id=20778&pathid1=0&bf=0' # 66v电影网视频地址
# 获取m3u8地址和电影名称
# get_m3u8_url(url)
m3u8_url, video_name = get_m3u8_url(url)
# 创建电影名称文件夹
makedir_video(video_name)
# 根据m3u8地址,获取所有的视频地址,并判断是否加密
all_videos = get_videos_url(video_name, m3u8_url)
# 根据视频地址下载视频
sem_num = 1000 # 用于控制并发量
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(download_all_videos(sem_num, video_name, all_videos))
# 解密所有视频
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(parse_all_videos(video_name))
# 合并视频
# windows 自带合成命令: copy /b a.ts+b.ts full.mp4
# linux/mac 命令: cat a.ts b.ts c.ts > xxx.mp4
merge(video_name)