arm neon/fpu/mfloat
neon官网介绍:
Arm Neon technology is an advanced Single Instruction Multiple Data (SIMD) architecture extension for the A-profile and R-profile processors.
Neon technology is a packed SIMD architecture. Neon registers are considered as vectors of elements of the same data type, with Neon instructions operating on multiple elements simultaneously. Multiple data types are supported by the technology, including floating-point and integer operations.
Neon technology is intended to improve the multimedia user experience by accelerating audio and video encoding and decoding, user interface, 2D and 3D graphics, and gaming. Neon can also accelerate signal processing algorithms and functions to speed up applications such as audio and video processing, voice and facial recognition, computer vision, and deep learning.
Armv7-A/Cortex-A7浮点支持介绍:
官网:
https://developer.arm.com/Processors/Cortex-A7
记录一下arm官网,方便日后学习:
SIMD,即 single instruction multiple data,单指令流多数据流,也就是说一次运算指令可以执行多个数据流,从而提高程序的运算速度,实质是通过 数据并行 来提高执行效
- ARM NEON 是 ARM 平台下的 SIMD 指令集,利用好这些指令可以使程序获得很大的速度提升。
- NEON intrinsic 指令,它是底层汇编指令的封装,不需要用户考虑底层寄存器的分配,但同时又可以达到原始汇编指令的性能。
- NEON 是一种 128 位的 SIMD 扩展指令集,由 ARMv7 引入,在 ARMv8 对其功能进行了扩展(支持向量化运算),支持包括加法、乘法、比较、移位、绝对值 、极大极小极值运算、保存和加载指令等运算
- ARM 架构下的下一代 SIMD 指令集为
SVE(Scalable Vector Extension,可扩展矢量指令),支持可变矢量长度编程,SVE 指令集的矢量寄存器的长度最小支持 128 位,最大可以支持 2048 位,以 128 位为增量
- ARM NEON 技术的核心是 NEON 单元,主要由四个模块组成:
NEON 寄存器文件、整型执行流水线、单精度浮点执行流水线和数据加载存储和重排流水线 - ARM 基本数据类型有三种:字节(
Byte,8bit)、半字(Halfword,16bit)、字(Word,32bit) - 新的 Armv8a 架构有
32个 128bit 向量寄存器,老的 ArmV7a 架构有32个 64bit(可当作16个128bit)向量寄存器,被用来存放向量数据,每个向量元素的类型必须相同,根据处理元素的大小可以划分为2/4/8/16个通道
mfloat编译:
在 armv8 aarch64中,这个规范里面规定在函数调用过程中怎么传输入和输出参数,哪些寄存器需要调用者保护,哪些寄存器需要被调用者保护。
在Armv7的AAPCS32规范里,是怎么来传浮点数的函数输入输出参数的呢,我们实际上定义了两种传浮点数的方式:
softfp
hardfp
这两个的区别在于,softfp 是用整形的通用寄存器(r0-r3)来传浮点数参数的,比如
float fadd(float xx, float xxx)
xx和xxx实际上是通过r0,r1传入到被调函数的,结果也是通过r0传出的。
但如果使用hardfp,那么用浮点数寄存器来传参数,以上同样的例子,xx和xxx是通过s0, s1寄存器来传的,结果是通过s0传出的。
在GCC compiler里提供了以下选项来选择你编译的代码是使用哪个方式
-mfloat-abi=softfp/hard
因为使用不同的参数传递方式,所以你不能将一个使用softfp另外一个使用hardfp的库或目标文件链接起来。

neon指令类型:
NEON指令的函数名组成格式:v ,逐元素进行操作
可以在 #include 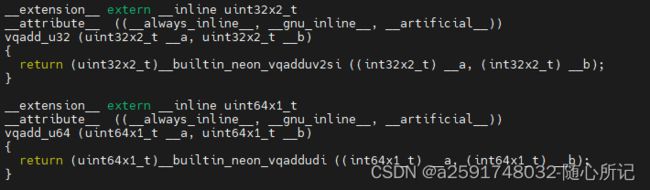
比如如下的乘法指令:
int32x2_t vmul_s32 (int32x2_t __a, int32x2_t __b);// ri = ai * bi, 长指令, 为了防止溢出
int64x2_t vmull_s32 (int32x2_t __a, int32x2_t __b)// ri = ai * b,有标量参与向量运算
int32x2_t vmul_n_s32 (int32x2_t __a, int32_t __b);// ri = ai * b, 长指令, 为了防止溢出 平方根指令:
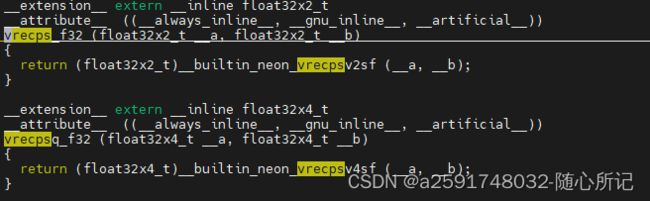
减法指令:
int32x4_t vsubq_s32(int32x4_t __a, int32x4_t __b);加法指令:
int8x8_t vqadd_s8(int8x8_t a, int8x8_t b);
关键词说明:
ABI,application binary interface (ABI),应用程序二进制接口
FPU:(Floating-Point Unit),浮点运算单元
ASE:(Advanced SIMD Extension),“ASE”是“先进SIMD扩展”的英文首字母缩写
SIMD: 的全称是 Single Instruction Multiple Data,中文名“单指令多数据”
NEON:是用于ARMv7和ARMv8 Cortex-A与Cortex-R处理器的先进SIMD功能的产品名称