solr7 简介、安装、使用
一、solr简介
首先Solr是基于Lucene做的,Solr的目标是打造一款企业级的搜索引擎系统,因此它更接近于我们认识到的搜索引擎系统,它是一个搜索引擎服务,通过各种API可以让你的应用使用搜索 服务,而不需要将搜索逻辑耦合在应用中。而且Solr可以根据配置文件定义数据解析的方式,更像是一个搜索框架,它也支持主从、热换库等操作。
solr还是一种开放源码的、基于 Lucene Java 的搜索服务器,易于加入到 Web 应用程序中。Solr 提供了层面搜索(就是统计)、命中醒目显示并且支持多种输出格式(包括XML/XSLT 和JSON等格式)。它易于安装和配置,而且附带了一个基于HTTP 的管理界面。可以使用 Solr 的表现优异的基本搜索功能,也可以对它进行扩展从而满足企业的需要。Solr的特性包括:
- 高级的全文搜索功能
- 专为高通量的网络流量进行的优化
- 基于开放接口(XML和HTTP)的标准
- 综合的HTML管理界面
- 可伸缩性-能够有效地复制到另外一个Solr搜索服务器
- 使用XML配置达到灵活性和适配性
- 可扩展的插件体系
Solr 必须运行在Java1.6 或更高版本的Java 虚拟机中,运行标准Solr 服务只需要安装JRE 即可,但如果需要扩展功能或编译源码则需要下载JDK 来完成。
Solr 是一个开源的企业级搜索服务器,底层使用易于扩展和修改的Java 来实现。服务器通信使用标准的HTTP 和XML,所以如果使用Solr 了解Java 技术会有用却不是必须的要求
文档通过Http利用XML 加到一个搜索集合中。查询该集合也是通过http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
二、Solr缓存
缓存在 Solr 中充当了一个非常重要的角色,Solr 中主要有这三种缓存:
- Filter cache(过滤器缓存),用于保存过滤器(fq 参数)和层面搜索的结果
- Document cache(文档缓存),用于保存 lucene 文档存储的字段
- Query result(查询缓存),用于保存查询的结果
- 还有第四种缓存,lucene 内部的缓存,不过该缓存外部无法控制到。
通过这 3 种缓存,可以对 solr 的搜索实例进行调优。调整这些缓存,需要根据索引库中文档的数量,每次查询结果的条数等。
在调整参数前,需要事先得到 solr 示例中的以下信息: 索引中文档的数量 每秒钟搜索的次数 过滤器的数量 一次查询返回最大的文档数量,不同查询和不同排序的个数,这些数量可以在 solr admin 页面的日志模块找到。
假设以上的值分别为:
索引中文档的数量:1000000
每秒钟搜索的次数:100
过滤器的数量:200
一次查询返回最大的文档数量:100
不同查询和不同排序的个数:500
然后可以开始修改 solrconfig.xml 中缓存的配置了
第一个是过滤器缓存:
第二个是查询结果缓存:
第三个是文档缓存:
这几个配置是基于以上的几个假设 的值进行调优的。
三、solr 安装
shell 安装 (初次使用 建议看完本篇博文 在部署服务器)
链接:https://blog.csdn.net/wakuangyun/article/details/102464583
1.安装背景概要
因为solr7+ 新增了夸核(solr 跨核概念,是建立在,solr存储方式的基础上,因为使用solr前必须创建Core,Core即为solr的核,那不同的业务有可能在不同的核中,之前版本是不支持跨核搜索的)搜索功能,写法如下:
shards=localhost:9095/solr/core0,localhost:9095/solr/core1 ,因为跨核的功能有可能在实际业务场景中应用到,所以本次是对 Solr7.1.0 安装部署。在安装 solr前需要安装jdk1.8或以上版本,这里选用tomcat作为solr的容器,tomcat也建议使用8.0或以上版本
2.下载
关于jdk,tomcat的安装就不在本文复述,见下链接。
jdk1.8 下载与安装: https://blog.csdn.net/yx1214442120/article/details/55098380
tomcat8 下载与安装:http://tomcat.apache.org/download-80.cgi ,注意系统兼容,我这里选择64位Windows,解压后配置环境变量,因为 tomcat默认8080端口容易与oracle 冲突,把端口号改为8888,地址为http://localhost:8888/。(5以后就不需要依赖tomcat了,这里 还采用tomcat 是为了部署linux 时候可以同样套用该步骤)

solr7.1.0 下载 (包含过往版本) :http://archive.apache.org/dist/lucene/solr/
3. solr7.1.0 安装(以下步骤都不可省略,请认真按步骤执行~)
3.1 解压出solr-7.1.0,将 solr 压缩包中 solr-7.1.0\server\solr-webapp\文件夹下有个webapp文件夹,将之复制到Tomcat\webapps\目录下,并改成solr (名称随意,为了后面访问方便,改为solr).
3.2 在E盘(根据实际情况)新建一个文件夹:solrhome ,回到tomcat的webapps目录下,打开tomcat\webapps 下 solr\WEB-INF\web.xml文件。在web-app节点中加入以下代码,env-entry-value 目录可根据实际情况自行更替:
* 把 security-constraint 整个标签注释:
3.3 将 solr-7.1.0\server\lib\ext 所有jar包,以及solr-7.1.0\server\lib 下 metrics 相关的jar ,以及solr-7.1.0\dist 下 solr-dataimporthandler 相关的jar复制到tomcat的webapps\solr\WEB-INF\lib下
3.4 在tomcat-8.5.31\webapps\solr\WEB-INF 下新建 classes文件夹。然后将solr-7.1.0\server\resources 下 log4j.properties 复制到 classes文件夹中。
3.5 回到解压的solr-7.1.0目录,打开文件夹:solr-7.1.0\server\solr,复制所有内容到E:\solrhome,把 solr-7.1.0 下 dist和contrib 文件夹 复制到 E:\solrhome下。 这样solrhome就和tomcat中的solr 完成了加载关联。
3.6 运行 apache-tomcat\bin 下 startup.bat 启动tomcat,看到一下日志说明启动成功了。

3.7 访问solr http://localhost:8888/solr/index.html ,见到如下页面才算真正安装成功。
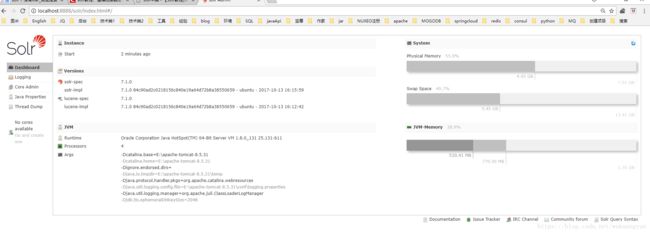
3.8 下面介绍两种新建核心的方法,第一种: 下图新建testCore,这时候可以根据业务,架构创建多个核心,这里就体现了为什么我们要用7+版本的solr ,就是因为 7+版本支持多核心搜索。这里需要注意的是,并不是全自动创建~还需要你先建好文件夹,把solrconfig.xml丢进去才行,所以这里不建议这种方式创建。不过你可以点一下试一试~

第二种 :不通过web页面,直接手动配置。在 E:\solrhome 下新建testCore/conf
将solr-7.1.0\server\solr\configsets\_default\conf 下所有文件放置到 新建的testCore/conf 下
然后修改 solrconfig.xml ,可以用相对路径,或者绝对路径。这里用了绝对路径。
然后在solrhome\testCore下新建data文件见。顾名思义这里放数据的,当然是无法看懂的文件。关于底层的实现方式,见如下链接 ,讲的比较清晰
https://blog.csdn.net/u014209975/article/details/53263642
这时候还需要 在 solrhome\testCore ,新建 core.properties 文件,写入以下内容(注意这里有坑 config=conf/solrconfig.xml后面不能有空格 否则启动会报错):
#Written by CorePropertiesLocator
#Sat May 26 16:41:44 CST 2018
name=testCore
config=conf/solrconfig.xml
schema=conf/managed-schema
dataDir=data
3.9 重启tomcat,再访问首页,就可以选择我们新建的testCore了,后面再建core,可以直接复制这一份改改~我老是把core 打成code~ 真是天生的程序员。这是我的testCode手动创建的。以前用过solr 的朋友可能会发现,conf下面没有schema.xml,1.6以前是schema.xml ,之后版本用的是managed-schema与schema.xml 基本一致,之后所有提到managed-schema都等同于schema.xml。
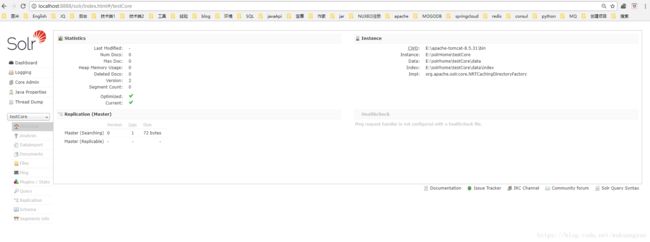
4.solr 的配置文件
solr 最主要的配置文件就是上面提到过的solrconfig.xml 以及managed-schema,要对这两个文件有一定的了解,尤其是managed-schema ,才能真正的把solr应用到业务中。
4.1 solrconfig.xml , solrconfig.xml配置文件主要定义了solr的一些处理规则,包括索引数据的存放位置,更新,删除,查询的一些规则配置。相当于是基础配置文件。值得注意的是,文件中不能有中文。~否则会报错,注释也不行
4.2 managed-schema是在使用solr建立core时的配置(core连接配置和索引库),solr根据它确定如何对文档建立索引到索引库中,每个core在建立前都需要设计好managed-schema。
详细的配置讲解,网上非常多,也非常专业,就不赘述了,提供一个我之前参考的链接,solrconfig.xml 以及 managed-schema 详细介绍见: https://blog.csdn.net/vtopqx/article/details/73224510
5.solr 的使用
5.1数据导入
5.1.1上面已经介绍了core的创建,下面说下怎么导入数据。在solrhome\testCore\conf下 创建文件data-config.xml,写入如下内容:
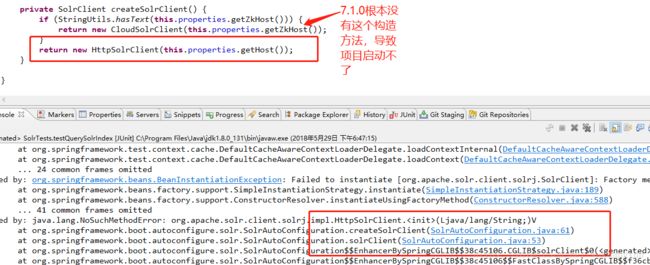
driver="com.mysql.jdbc.Driver" url="jdbc:mysql://123.59.41.168:3306/db_yxj_studio" user="yxj" password="yxj@2015" /> query="SELECT sbtid as id ,master_intro, tags, srpid, department FROM t_subject WHERE sbtid >= ${dataimporter.request.sbtid}"> dataConfig 标签中,子标签,dataSource 配置数据源,上面是以mysql为例,配置了数据源。其中entity 标签 定义了 操作名称,以及sql ,其中${dataimporter.request.id} 中自定义了id字段,值得注意的是必须指定id字段,因为我使用的表中没有ID 所以 我使用了as的写法。另外还有一点,要把sql中用到的字段名,在managed-schema中进行编写fields。以我的sql为例,managed-schema写法如下。 5.1.2接下来把solrhome\testCore\conf 下的 solrconfig.xml,写入如下内容: <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xmlstr> lst> requestHandler> 5.1.3最后 把数据库驱动丢到apache-tomcat\webapps\solr\WEB-INF\lib 中 ,如果你使用的pgSql 就丢对应的jar~ 5.1.4重启tomcat ,导入数据,并检索,见下图 导入成功 5.1.5 检索,见下图,整个solr 安装、配置、使用 就都OK了。最后对查询语法介绍,引用如下: https://blog.csdn.net/zhufenglonglove/article/details/51518846 6.solr 分词器 6.1 K分词器,因为IK是开源的分词器,也支持扩展,网上分词器很多,使用方法也大同小异。首先要下载IK的jar包。solr7.0+要用5.0+的IK分词器。 IKAnalyzer2012FF_u1-6.51.jar 可以私信我,CSDN不能,上传JAR~ 6.2 把IK jar包放到放到apache-tomcat\webapps\solr\WEB-INF\lib 下,配置solrhome\testCore\conf 下的managed-schema 文件 ,分别写入 1.其中useSmart是指分词的细粒度,可以分别制定index索引和query查询的分词细粒度,建议将index的useSmart设置为false,这样就采用最细分词,是索引更精确,查询时尽量能匹配,而将query的useSmart设置为true,采用最大分词,这样能够使查询出来的结果更符合用户的需求。 2.positionIncrementGap 一个doc中的属性有多个值时候,设置每个属性之间的增量值和multiValued属性配合使用(避免错误匹配)。 6.3重启tomcat 这里是未使用分词器的效果。 选用IK分词以后,效果很明显 7.solr 与springboot 的集成(这里有坑) 7.1 通过solrj 来操作solr,maven 引入 。 注意一下 ,JAR冲突的问题,我发现spring-boot-starter-test 包含的 spring-test-4.3.6.RELEASE 包下面 和solr7.1.0有冲突 ,为了解决这个问题,只能放弃最新的solr-solrj jar 的使用,改用5.3之后的版本,切兼容springboot的。 等日后springboot升级在做更替。我试验了 老版本不影响solr的使用。是指在7.1.0版本 有一些方法是弃用的。但还是兼容的。如果你使用的是springMvc可以尝试用最新版本的jar包。 一般,我都会在这里找jar: http://mvnrepository.com/ 7.2 java 实现 增删改查 ,这里我用多线程测试过,100W数据用我的破机器,3分钟就跑完了。 相关参数 #solr #服务器地址 solr.httpSolrClientUrl=http://localhost:8888/solr/ #等待结果超时 这个参数设定的是HTTP连接成功后,等待读取数据或者写数据的最大超时时间,单位为毫秒 如果设置为0,则表示永远不会超时 solr.soTimeOut=5000 #接超时时间 HTTP 超时时间 单位为毫秒 如果设置为0,则表示永远不会超时 solr.connectionTimeout=1000 







package com.ysz.studio.solr.service;
import java.util.List;
import java.util.Map;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
public interface SolrService {
/**
* 按条件查询搜索引擎
*
* @author [email protected]
* @param coreName
* @param query
* @return
* @since
*/
public SolrDocumentList querySolrIndex(String coreName, String query);
/**
* 向solr插入数据
*
* @author [email protected]
* @param coreName
* @param input
* @return
* @since
*/
public boolean pushDataIntoSolr(String coreName, Listpackage com.ysz.studio.solr.service.impl;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import com.ysz.studio.solr.service.SolrService;
@Service
public class SolrServiceImpl implements SolrService {
private Logger logger = LoggerFactory.getLogger(SolrServiceImpl.class);
@Value("${solr.httpSolrClientUrl}")
private String httpSolrClientUrl;
// 这个参数设定的是HTTP连接成功后,等待读取数据或者写数据的最大超时时间,单位为毫秒 如果设置为0,则表示永远不会超时
@Value("${solr.soTimeOut}")
private int soTimeOut;
// HTTP 超时时间 单位为毫秒 如果设置为0,则表示永远不会超时
@Value("${solr.connectionTimeout}")
private int connectionTimeout;
private static HttpSolrClient solr;
private HttpSolrClient connetHttpSolrClientServer(String coreName) {
HttpSolrClient httpSolrClient = new HttpSolrClient(httpSolrClientUrl + coreName);
httpSolrClient.setConnectionTimeout(connectionTimeout);
httpSolrClient.setSoTimeout(soTimeOut);
// solr服务器地址+库 JAR包 冲突 导致 无法使用最新的 方法
// new HttpSolrClient.Builder(httpSolrClientUrl +
// coreName).withConnectionTimeout(connectionTimeout).withSocketTimeout(soTimeOut).build();
return httpSolrClient;
}
@Override
public boolean pushDataIntoSolr(String coreName, List