使用稀疏性(微球)进行色谱图基线估计和去噪(Matlab代码实现)
欢迎来到本博客❤️❤️
博主优势:博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
本文目录如下:
目录
1 概述
2 运行结果
3 参考文献
4 Matlab代码、数据、文章

1 概述
文献来源:

本文共同解决了色谱图基线校正和降噪问题。所提出的方法基于将一系列色谱峰建模为稀疏和稀疏衍生物,并将基线建模为低通信号。提出了一个凸优化问题,以封装这些非参数模型。为了说明色谱峰的阳性性,使用了不对称惩罚函数。开发了一种鲁棒的、计算高效的迭代算法,保证收敛到独特的最优解。该方法称为基线估计和稀疏性降噪(BEADS),使用模拟和真实色谱图数据对两种最先进的方法进行评估和比较。
不确定因素的几个来源会影响气相色谱和液相色谱分析的质量和性能[48],[1]。与许多其他分析化学方法(包括红外或拉曼光谱[6])一样,色谱图测量通常被认为是峰、背景和噪声的组合[35]。后两个术语有时合并为不同的面额:漂移噪声、基线漂移或频谱连续体。例如,在[5]中,基线漂移被表征为“彩色”噪声,在噪声功率谱中具有低频优势。在下文中,我们将术语“基线”限制为指趋势或偏差中最平滑的部分(当只有流动相从色谱柱中出现时记录检测器响应的色谱图部分,[34]),而我们称“噪声”为更随机的部分。峰线形状可能具有多种性质,从高斯模型到不对称经验模型[17,第97页]。同时,它们可以很容易地被描述为短宽度、陡峭的上下颠簸。因此,它们还具有相对宽的频谱,尽管是局部的,并且表现与漂移噪声干扰不同。撇开峰伪影(前部和尾部、共洗脱等)不谈,它们的定量分析(峰面积、宽度、高度定量)会受到准确消除平滑基线和随机噪声的可能性的阻碍[29]。事实上,这些问题通常通过两个不同的步骤独立解决(这反过来又可能“引入大量相关噪声”[5]):基线的一般低阶近似或平滑,以及去除背景的残余色谱图上的噪声过滤形式。
首先,虽然看似简单,但基线减法问题仍然是一个长期存在的问题,可以追溯到[58],[38]。最近的概述见[42],[20],[27]。光谱信息处理[46],[47],[57]一直是一个主要的行动过程。已经提出了基于线性和非线性[36],[26],[41]滤波或具有小波变换[9],[24],[7],[31]的 多尺度滤波形式的方法。峰谱、基线和噪声之间的相对重叠导致了基于各种约束的替代回归模型。基线的低通部分可以通过常规函数建模,例如低次多项式[33],[59]或(立方)样条模型[19],[23],[12],并结合手动识别,多项式拟合或迭代阈值方法[21]。已经设计了基于信号导数[5],[11]的相关算法。在许多方法中,建模和约束都基于基线本身的潜在特征:形状、平滑度和转换后的域属性。因此,研究广义惩罚[13],[3],[33],[59]似乎有益,对信号,背景或噪声的模型不那么严格。这就是本文的动机:联合估计这三种色谱成分,同时避免过于严格的参数模型。具体来说,在这项工作中,基线被建模为低通信号,而感兴趣的色谱峰被认为是稀疏的,直到二阶导数,留下随机噪声作为残差。
在过去的十年中,这种简约或稀疏的概念一直是信号处理和化学领域积极而富有成效的驱动力。它需要使用有限数量的非零参数或分量来描述感兴趣的信号。稀疏性在(描述的)准确性和(分解的)浓度之间进行权衡。已经开发了许多基于稀疏性的算法,用于重建、去噪、检测、反卷积。大多数稀疏建模技术源于“最小绝对收缩和选择运算符”(在套索绰号[50],[40]下更为人所知),基追寻方法[10],总变异[8]和复合正则化[2].虽然后者本质上促进了稀疏性,但不同的问题同时需要其他约束,如信号平滑度或残余随机性。
更具体地说,信号[33],[43],[44],[37]和图像处理[22],[15],[16],[49],[4]的最新工作促进了将潜在复杂测量分解为“足够”不同组件的框架。 这种非线性分解被称为“形态成分分析”、“几何分离”或“聚类稀疏性”[28]。这种方法适用于分析化学问题,依赖于基线和色谱峰的形态特性。图1(a)显示了从二维气相色谱法获得的色谱图x[52]。它由突然的峰值组成,返回到相对平坦的基线,因此表现出一种稀疏性。此外,如图1(b)和(c)所示,x的二阶和三阶导数也是稀疏的;通常比 X 本身更稀疏。因此,我们将色谱图的峰建模为稀疏信号,其前几个导数也是稀疏的。此外,基线有时由多项式或样条近似[32],[33],[59]。然而,在实践中,大多数基线信号并没有在长范围内忠实地遵循多项式定律。因此,我们将缓慢变化的基线漂移建模为低通信号。与多项式或样条近似相比,基线的更通用的低通模型提供了一种方便灵活的方法来指定平滑运算符的行为。
2 运行结果
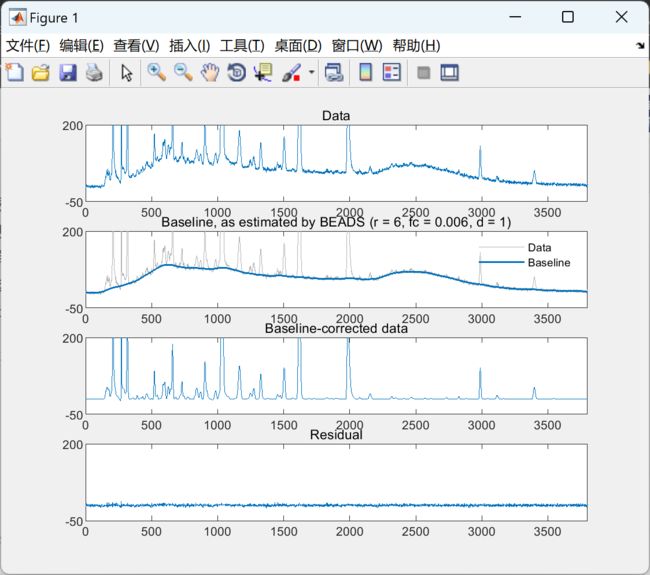

部分代码:
%% Run the BEADS algorithm
% Filter parameters
fc = 0.006; % fc : cut-off frequency (cycles/sample)
d = 1; % d : filter order parameter (d = 1 or 2)
% Positivity bias (peaks are positive)
r = 6; % r : asymmetry parameter
% Regularization parameters
amp = 0.8;
lam0 = 0.5*amp;
lam1 = 5*amp;
lam2 = 4*amp;
tic
[x1, f1, cost] = beads(y, d, fc, r, lam0, lam1, lam2);
toc
%% Display the output of BEADS
ylim1 = [-50 200];
xlim1 = [0 3800];
figure(1)
clf
subplot(4, 1, 1)
plot(y)
title('Data')
xlim(xlim1)
ylim(ylim1)
set(gca,'ytick', ylim1)
subplot(4, 1, 2)
plot(y,'color', [1 1 1]*0.7)
line(1:N, f1, 'LineWidth', 1)
legend('Data', 'Baseline')
legend boxoff
title(['Baseline, as estimated by BEADS', ' (r = ', num2str(r), ', fc = ', num2str(fc), ', d = ', num2str(d),')'])
xlim(xlim1)
ylim(ylim1)
set(gca,'ytick', ylim1)
subplot(4, 1, 3)
plot(x1)
title('Baseline-corrected data')
xlim(xlim1)
ylim(ylim1)
set(gca,'ytick', ylim1)
subplot(4, 1, 4)
plot(y - x1 - f1)
title('Residual')
xlim(xlim1)
ylim(ylim1)
set(gca,'ytick', ylim1)
orient tall
print -dpdf example
%% Display cost function history
figure(2)
clf
plot(cost)
xlabel('iteration number')
ylabel('Cost function value')
title('Cost function history')
3 参考文献
部分理论来源于网络,如有侵权请联系删除。
Xiaoran Ning, Ivan W. Selesnick, Laurent Duval, in Chemometrics and Intelligent Laboratory Systems, December 2014,