深拷贝与浅拷贝、值语义与引用语义对象语义 ——以C++和Python为例
深拷贝与浅拷贝、值语义与引用语义/对象语义 ——以C++和Python为例
值语义与引用语义(对象语义)
本小节参考自:https://www.cnblogs.com/Solstice/archive/2011/08/16/2141515.html
概念
在任何编程语言中,区分深浅拷贝的关键都是要区分值语义和引用语义(对象语义)。
值语义(value sematics)指的是对象的拷贝与原对象是独立的、无关的,就像拷贝 int 一样。C++ 的内置类型(bool/int/double/char)都是值语义,标准库里的 complex<> 、pair<>、vector<>、map<>、string 等等类型也都是值语意,拷贝之后就与原对象脱离关系。Java 语言的 primitive types 也是值语义。
与值语义对应的是“对象语义/object sematics”,或者叫做引用语义(reference sematics)。对象语义指的是面向对象意义下的对象,对象拷贝是禁止的。例如 muduo 里的 Thread 是对象语义,拷贝 Thread 是无意义的,也是被禁止的:因为 Thread 代表线程,拷贝一个 Thread 对象并不能让系统增加一个一模一样的线程。Java 里边的 class 对象都是对象语义/引用语义。
生命期
值语义的一个巨大好处是生命期管理很简单,就跟 int 一样——你不需要操心 int 的生命期。值语义的对象要么是 stack object,或者直接作为其他 object 的成员,因此我们不用担心它的生命期(一个函数使用自己stack上的对象,一个成员函数使用自己的数据成员对象)。
相反,对象语义的 object 由于不能拷贝,我们只能通过指针或引用来使用它。一旦使用指针和引用来操作对象,那么就要担心所指的对象是否已被释放,这一度是 C++ 程序 bug 的一大来源。此外,由于 C++ 只能通过指针或引用来获得多态性,那么在C++里从事基于继承和多态的面向对象编程有其本质的困难——资源管理。
C++与标准库中的值语义
C++ 的 class 本质上是值语义的,这才会出现 object slicing 这种语言独有的问题,也才会需要程序员注意 pass-by-value 和 pass-by-const-reference 的取舍。在其他面向对象编程语言中,这都不需要费脑筋。
值语义是C++语言的三大约束(与C兼容,零开销,值语义)之一,C++ 的设计初衷是让用户定义的类型(class)能像内置类型(int)一样工作,具有同等的地位。为此C++做了以下设计(妥协):
- class 的 layout 与 C struct 一样,没有额外的开销。定义一个“只包含一个 int 成员的 class ”的对象开销和定义一个 int 一样。
- 甚至 class data member 都默认是 uninitialized,因为函数局部的 int 是 uninitialized。
- class 可以在 stack 上创建,也可以在 heap 上创建。因为 int 可以是 stack variable。
- class 的数组就是一个个 class 对象挨着,没有额外的 indirection。因为 int 数组就是这样。
- 编译器会为 class 默认生成 copy constructor 和 assignment operators。其他语言没有 copy constructor 一说,也不允许重载 assignment operator。C++ 的对象默认是可以拷贝的,这是一个尴尬的特性。
- 当 class type 传入函数时,默认是 make a copy (除非参数声明为 reference)。因为把 int 传入函数时是 make a copy。
- 当函数返回一个 class type 时,只能通过 make a copy(C++ 不得不定义 RVO 来解决性能问题)。因为函数返回 int 时是 make a copy。
- 以 class type 为成员时,数据成员是嵌入的。例如 pair
挨着 size_t。
C++ 要求凡是能放入标准容器的类型必须具有值语义。准确地说:type 必须是 SGIAssignable concept 的 model。但是,由 于C++ 编译器会为 class 默认提供 copy constructor 和 assignment operator,因此除非明确禁止,否则 class 总是可以作为标准库的元素类型——尽管程序可以编译通过,但是隐藏了资源管理方面的 bug。
因此,在写一个 class 的时候,先让它继承 boost::noncopyable,几乎总是正确的。
在现代 C++ 中,一般不需要自己编写 copy constructor 或 assignment operator,因为只要每个数据成员都具有值语义的话,编译器自动生成的 member-wise copying&assigning 就能正常工作;如果以 smart ptr 为成员来持有其他对象,那么就能自动启用或禁用 copying&assigning。例外:编写 HashMap 这类底层库时还是需要自己实现 copy control。
这些设计带来了性能上的好处,原因是 memory locality。
个人觉得是这样(在学习,有错误请指出):
| 基本数据类型 | 自定义class | |
|---|---|---|
| C++ | 值语义 | 值语义 |
| Java | 值语义 | 引用语义 |
| Python | 引用语义 | 引用语义 |
当然这都是默认情况下,具体情况具体需求可以用深/浅拷贝来处理。
另外,类的某个成员变量是值语义/引用语义与这个类本身是值语义/引用语义无关。
C++的另一个麻烦之处在于不支持自动垃圾回收,所以要程序员自己小心地处理生命周期问题。
C++中的深浅拷贝
C++中类的拷贝控制
首先我们简单地提一下C++中的拷贝控制这件事情。当我们定义一个类的时候,为了让我们定义的类类型像内置类型(char,int,double等)一样好用,我们通常需要考下面几件事:
Q1:用这个类的对象去初始化另一个同类型的对象。
Q2:将这个类的对象赋值给另一个同类型的对象。
Q3:让这个类的对象有生命周期,比如局部对象在代码部结束的时候,需要销毁这个对象。
因此C++就定义了5种拷贝控制操作,其中2个移动操作是C++11标准新加入的特性:
拷贝构造函数(copy constructor)
移动构造函数(move constructor)(C++11)
拷贝赋值运算符(copy-assignment operator)
移动赋值运算符(move-assignment operator)(C++11)
析构函数 (destructor)
前两个构造函数发生在Q1时,中间两个赋值运算符发生在Q2时,而析构函数则负责类对象的销毁。
但是对初学者来说,既是福音也是灾难的是,如果我们没有在定义的类里面定义这些控制操作符,编译器会自动的为我们提供一个默认的版本。这有时候看起来是好事,但是编译器不是万能的,它的行为在很多时候并不是我们想要的。
所以,在实现拷贝控制操作中,最困难的地方是认识到什么时候需要定义这些操作。
拷贝控制又是一个大的话题,为了弄明白深浅拷贝,这里我们只需要认识到拷贝构造函数和拷贝赋值运算符:它们是一个在类的对象发生将某个对象赋值给另一个同类的对象时会被用到的拷贝控制。编译器提供了它们的默认实现,但是在某些情况下,默认的实现并不能很好地工作。
无指针的类
上面已经介绍过,在C++中主要是值语义。首先考虑这样一个类:
class Foo {
private:
int m_a;
int m_b;
public:
Foo(): m_a(0), m_b(0){ }
Foo(int a, int b): m_a(a), m_b(b){ }
};
在这个类中,只有值语义的成员 m_a 和 m_b。
如果我们要拷贝这个类的一个对象如:
int main(){
Foo obj1(3, 5);
Foo obj2 = obj1;
std::cout << &obj1 << std::endl;
std::cout << &obj2 << std::endl;
return 0;
}
此时会调用编译器默认的拷贝构造函数,即浅拷贝,就是简单地将对象 obj1 内的成员直接照模照样复制一份,放到新的对象 obj2 中。注意,由于默认提供了拷贝构造函数和赋值运算符,C++中的对象都是值语义的。从而,这样的赋值操作是会新建一个对象,而非增加一个指向原对象 obj1 的引用(这与Java和Python中不同)。这可以通过查看两个对象的地址得到验证,输出:
0x7ffffaa2ffa0
0x7ffffaa2ff98
二者地址不同。
OK,so far, so good. 这时深浅拷贝其实是一样的,因为类内没有指针类型的成员。浅拷贝(编译器提供的默认拷贝构造函数)就可以工作的很好,不需要我们做什么调整。但是,如果类内包含指针类型的成员,问题就来了。
含有指针的类
当类成员中含有指针类型时,情况就大不相同了,考虑下面的类:
#include 假设我们现在还没有写上面的重写的拷贝构造函数,也就是说还是执行编译器为我们默认提供的浅拷贝的拷贝构造函数,执行以下测试:
int main(){
int a = 3;
int b = 5;
Bar obj1(a, &b);
Bar obj2 = obj1;
std::cout << &obj1 << std::endl;
std::cout << &obj2 << std::endl;
obj1.print_member();
obj2.print_member();
obj1.change_p(6);
obj1.print_member();
obj2.print_member();
return 0;
}
得到输出:
0x7ffe92762a40
0x7ffe92762a50
3,5
3,5
3,6
3,6
两个对象是在内存地址,是独立的,这仍然没有问题。但是问题来了,当我们改变 obj1 的 m_p 指针所指向的值时。obj2 的值也跟着改变了。这时因为默认的拷贝构造函数(浅拷贝)只会将类内的所有成员都复制一份给到新的对象,至于是指针还是值,他一概不管的。这就导致了指针类型的成员变量 m_p 也被原封不动的给到了新的对象 obj2 ,这样两个对象 obj1 和 obj2 的 m_p 指针的指向的是相同的。从而导致了上面 obj2 的值跟着 obj1变化的情况。这种情况,相当于是值语义的对象中有引用语义的成员。
这种情况下,默认的浅拷贝显然就不能满足我们的需求了,这时我们就要自己重写实现一个拷贝构造函数来完成深拷贝,将指针类型所指向的值重新找一块地址来存放,从而避免与原对象指向了相同的地址。
实现也一并在上面的代码块中了。当我们打开拷贝构造函数的注释,再执行测试,得到结果如下:
0x7fff232ea1e0
0x7fff232ea1f0
3,5
3,5
3,6
3,5
可以看到,现在两个对象的改变是完全独立的了,obj1 的变化并不会影响的 obj2 。程序的行为符合我们的预期。
总结与思考
总结一下,在 C++ 中:
-
由于编译器提供了默认的拷贝构造函数和赋值运算符,所以自定义的类一般都是值语义的。
-
如果类内没有指针类型的成员变量,完全可以使用编译器默认提供的浅拷贝的拷贝构造函数。然而,当类内存在指针类型的成员变量,我们必须重写拷贝构造函数实现深拷贝,从而避免bug的出现。
那么为什么编译器不能智能地在合适的时候执行深拷贝呢?在知乎的一个问题中,有人指出了一些原因:
编译器等…默认的行为都是浅拷贝的原因之一,是深拷贝不一定能够实现。例如指向的对象可能是多态的(C++没有标准的虚构造函数),也可能是数组,也可能有循环引用(如 struct N(N *p;};)。所以只能留待成员变量的类来决定怎样复制。
值得一提的是,除了复制操作,还可以考虑移动和交换操作。它们的性能通常比复制操作更优。自C++11开始也提供了标准的移动操作的实现方法。
Python中的深浅拷贝
在 Python 和 Java 中,变量保存的是对象(值)的引用,也就是说 Python 都是上面提到的 引用语义。我们刚才在C++中提到过,当值语义的对象中有引用语义的成员时,我们需要自己实现深拷贝来保证两个对象所引用内容的独立、分离。那在Python中,全都是引用语义,该怎么处理呢,深浅拷贝的区别更需要仔细辨别,有这三种情况:赋值、浅拷贝和深拷贝。
以下是简要的图文介绍。详细可参考:Python中的深拷贝与浅拷贝。
赋值
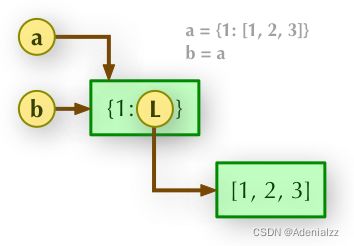
b = a
赋值引用,a 和 b都指向同一个对象,a 与 b 的变化完全同步。
浅拷贝
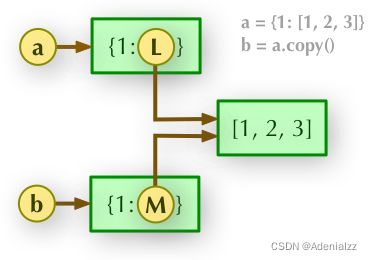
b = a.copy(),也可以 b = copy.copy(a),其中后者可以处理所有类型,前者不能处理内置数据类型如 int 。
浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用),所以它们的子对象变化同步,其他不同步。
实际上,浅拷贝指的是重新分配一块内存,创建一个新的对象,但里面的元素是原对象中各个子对象的引用。
深拷贝
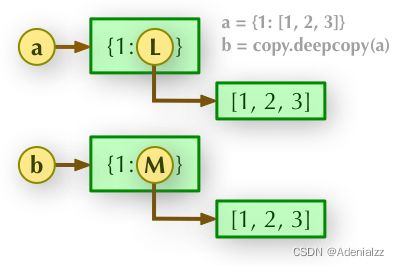
b = copy.deepcopy(a)
深拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的,两者的变化也完全无关。
实际上,浅拷贝是指重新分配一块内存,创建一个新的对象,并且将原对象中的元素,以递归的方式,通过创建新的子对象拷贝到新对象中。
Ref:
https://www.zhihu.com/question/36370072
https://www.cnblogs.com/Solstice/archive/2011/08/16/2141515.html
https://www.cnblogs.com/ronny/p/3734110.html
https://blog.csdn.net/weixin_44966641/article/details/122118289?spm=1001.2014.3001.5501