java基础面试题1
目录
Java语言有哪些特点
Java都有那些开发平台?
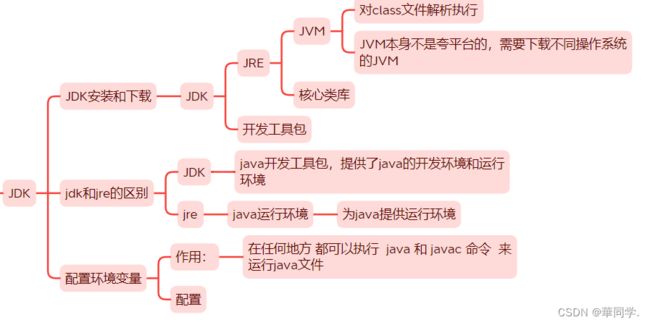
Jdk和Jre和JVM的区别【重要】
面向对象和面向过程的区别
什么是数据结构?Java的数据结构有哪些?
1.数组:
2.队列 Queue
3.链表 Linked List
4.栈Stack
5.树Tree
什么是OOP?
类与对象的关系?
面向对象的特征?【重要】
Java中的基本数据类型?
什么是隐式转换,什么是显式转换 ?【重要】
char类型能不能转成int类型?能不能转化成string类型,能不能转成double类型
float f=3.4;是否正确?
自动拆箱和自动装箱[重要]
Java中的包装类都是那些?
instanceof关键字的作用
一个java类中包含那些内容?
访问修饰符 public,private,protected,以及不写(默认)时的区别?【重要】
局部变量和成员变量的区别?
重载(Overload)和重写(Override)的区别?【重要】
equals与==的区别?【重要】
++i与i++的区别
数组实例化有几种方式?
Java中各种数据默认值
Java常用包有那些?【重要】
Object类常用方法有那些?
java中有没有指针?
构造方法能不能显式调用?
内部类与静态内部类的区别?
Static关键字有什么作用?【****】
final在java中的作用,有哪些用法?【****】
StringString StringBuffer 和 StringBuilder 的区别是什么?【重要】
讲下java中的math类有那些常用方法?
String类的常用方法有那些?
什么是接口?为什么需要接口?接口特点?
抽象类和接口的区别?【重要】
Java语言有哪些特点
1.简单易学,有丰富的类库
2.面向对象(Java最重要的特性,让程序耦合度更低)
3.跨平台(JVM实现)
4.支持多线程
Java都有那些开发平台?

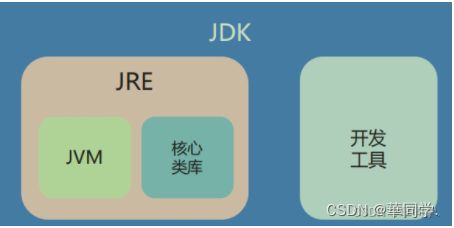
Jdk和Jre和JVM的区别【重要】
1、JDK是java开发工具包,是整个java的核心,包含了java运行环境JRE,java开发工具(是开发人员所需要安装的环境)
2.JRE是运行Java程序所必须的环境集合,包含了JVM和核心类库(java的运行环境,java程序运行所需要安装的环境)
3.JVM是Java虚拟机的缩写,是整个Java实现跨平台的最核心部分
面向对象和面向过程的区别
1.面向过程
一种较早的编程思想,顾名思义就是该思想是站着过程的思想强调的就是功能行为,功能的执行过程,即先后顺序,而每 一个功能我们都使用函数(类似于方法)把这些步骤一步一步实现。使用的时候依次调用函数就可以了。
2.面向对象
什么是数据结构?Java的数据结构有哪些?
1.数据结构,简单的就是计算机存储,组织数据的集合
(精心选择的数据结构可以带来更高的运行或者存储效率)
2.
1.数组:
数组是最简单,使用最频繁的数据结构。它是一种线性表 数据结构,用一组连续的内存空间来储存一组相同类型的数据
(数据是按照顺序储存在内存的连续空间内,由于数据是储存在连续空间内的,所以每个数据的内存地址都可以通过数组下标计算出来,从而直接访问数据)

优点:按照索引查询元素速度快,按照索引遍历方便
缺点:
1.数组储存空间的大小固定后无法扩容了,
2.数组只能存一种类型的数据,
3.添加,删除的操作慢,因为要移动其他元素
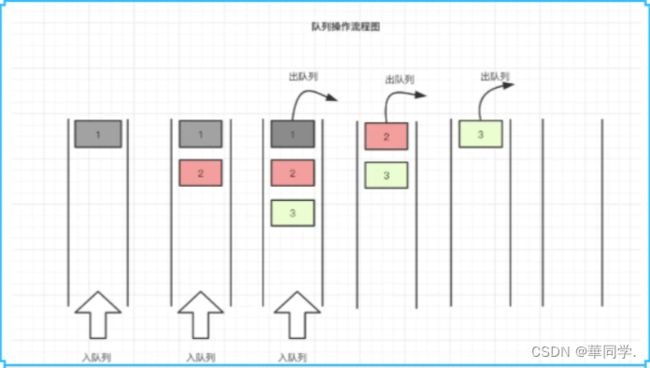
2.队列 Queue
特点是,先入先出,操作是两段进行的(相当于排队做核酸)
3.链表 Linked List
链表是 一种物理储存单元上非连续,非顺序的储存结构,链表有一系类节点组成,节点就是指链表中的每一个元素,每个节点包含两个数据(一个是存储元素的数据域(值) 另一个存储下一个节点地址的指针域)
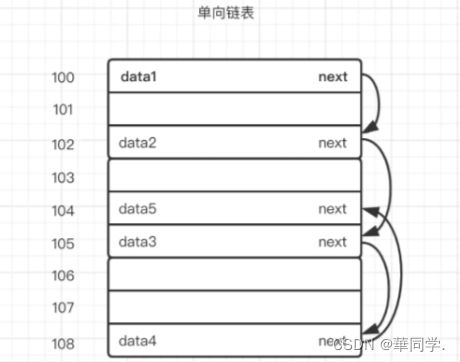
假设上图中100-108是一块内存中连续地址的内存分布,假设101、103、106、107这几个内存地址都已经存储数据了,那剩下的100、102、104、105、108是不是就浪费呢,答案是否定的,我们可以使用链表的方式存储数据。
优点:
添加或者删除元素只需要改变前后两个元素节点的指针域指向地址即可,添加,删除比数组快
缺点:
因为有大量的指针域,占用空间大
查找时,要遍历,比数组慢
4.栈Stack
栈是一种数据程线性排列的数据结构,和上边的队列相反,特点是 先进后出 常说LIFO (Last in First Out)
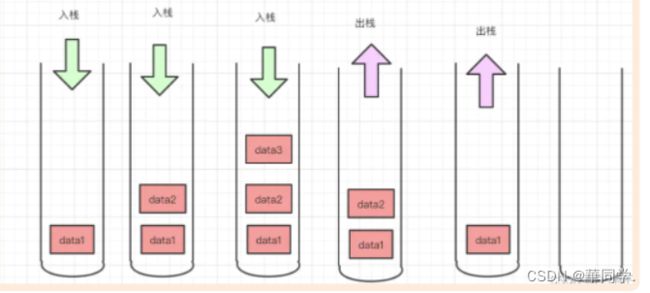
栈的结构就像一个集装箱,越先放进去的东西越晚才能拿出来,所以,栈常应用于实现递归功能方面的场景,例如斐波那契数列。
5.树Tree
树形结构是一种层级的数据结构,由顶点(节点) 和 连接他们的边组成
1.二叉树 (如果是顺序插入的,则会形成一个单向链表)
缺点:顺序插入时,会形成一个链表,查询性能大大降低(大数据也慢)
2.红黑树(平衡二叉树)
特点:

缺点:
大数据量情况下,层级较深,检索速度慢
3.B-Tree(是一种多叉路衡查找树,相对于二叉树)
以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key,5个指针
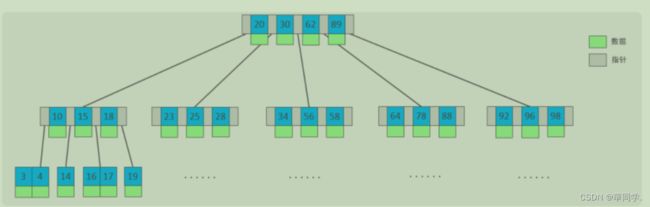
特点:
5阶的B树,每一个节点最多4个Key,5个指针
一旦节点存储的key数量到达5,就会裂变,中间元素向上分裂。
非叶子节点和叶子节点都会存放数据。
4.B+Tree
B+Tree是B-Tree的变种,我们以一颗最大度数(max-degree)为4(4阶)的b+tree为例,
绿色框框起来的部分,是索引部分,仅仅起到索引数据的作用,不存储数据。
红色框框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据。
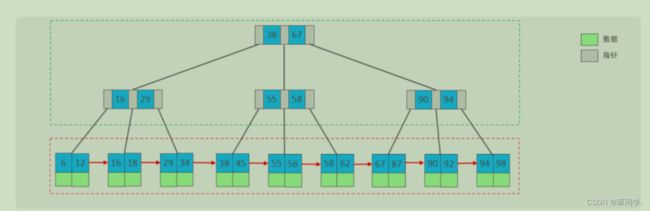
特点:
1.所有节点都会出现在叶子节点
2.叶子结点形成一个单向链表
3.非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的
数据结构还有好多。。
什么是OOP?
面向对象编程
类与对象的关系?
面向对象的特征?【重要】
多态产生条件:1.有继承或者实现的关系2.有方法的重写3.父类的引用指向子类对象多态下成员变量 和 方法:
*******成员变量: 编译看左边 执行看左边****** *******成员方法: 编译看左边 执行看右边******多态的好处 和 弊端:
好处:
1.作为形参 : 扩大了形参 接收 范围。
2.作为返回值:扩大了接收返回值类型的范围。
弊端:
不能使用子类特有特征;
多态转型:
1.向上转型:zi 》fu
举例:Father f = new Son(); 多态
2.向下转型:
需要强转:
Son s = (Son)f;
强转有风险
有类型转换异常可能 ClassCastExeption
dog 无法转换 cat
引用关键字 instanceof 判断 是XXX 类型的吗
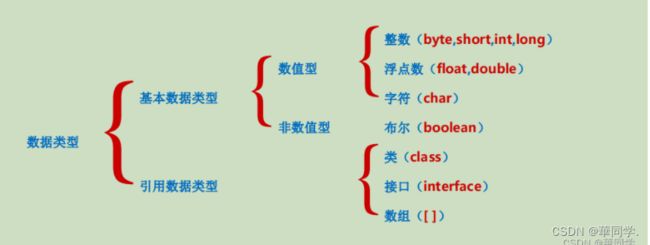
Java中的基本数据类型?
Java语言是强类型语言,对于每一种数据都给出了明确的数据类型,不同的 数据类型 也分配了不同的 内存空间 ,
所以它们表示的 数据大小 也是不一样的。
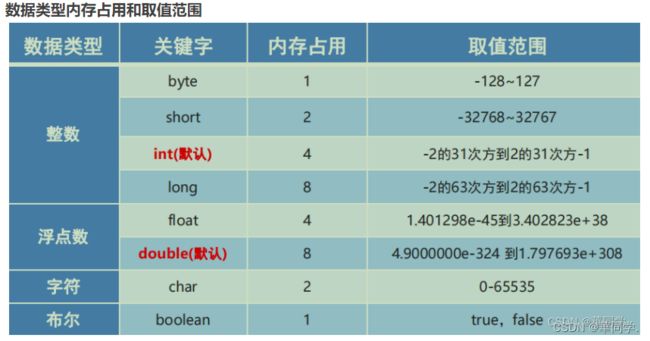
什么是隐式转换,什么是显式转换 ?【重要】
基本数据类型之间的运算
* 1.自动数据类型的提升(不包含boolean)
* byte . char . short --> int --> long --> float --> double2.强制数据类型的转换(格式:(目标类型) 数据)
* double d1 = 12.9;
* int i1 = (int)d1;
强制类型转换 (范围大的 转 范围小的)
举例:int a = (int)1.5;
将 double 类型的1.5 强转为1;
在 赋值给 a
char类型能不能转成int类型?能不能转化成string类型,能不能转成double类型
float f=3.4;是否正确?
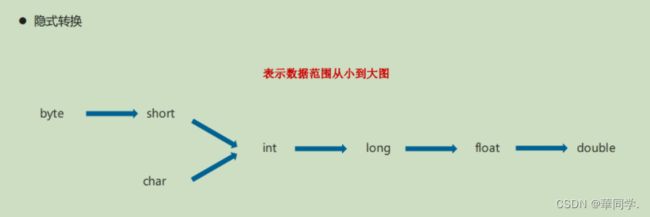
自动拆箱和自动装箱[重要]
自动装箱: 将 基本数据类型 自动转换 为 对应的包装类型(valueof)
/*
* 自动 装箱:
* 将 基本数据类型 自动转换 为 对应的包装类型
* 比如: Integer i = 123;
* 底层: 将基本数据类型 的123 自动转换(valueOf) 为 包装类型
* 叫自动装箱
*
*
* */
Integer i = 123;
Integer integer = Integer.valueOf(122);自动拆箱: 包装类 类型 转换 为对应的 基本数据类型(XXX.intValue())
/*
* 自动拆箱 : 包装类 类型 转换 为对应的 基本数据类型
*
* 比如说: int a = 1;
* 将引用类型i 自动转换 (i.intValue()) 成基本数据类型
*
*
*
* */Java中的包装类都是那些?
instanceof关键字的作用
instanceof关键字是判断instanceof左边的对象是否属于右边的类型(用于引用类型的判断结果为true或false)
instanceof前面的对象所属的类是后面类型的类或者是其子类的话,判断结果为true,否则为false
一个java类中包含那些内容?
属性、方法、内部类、构造方法、代码块。
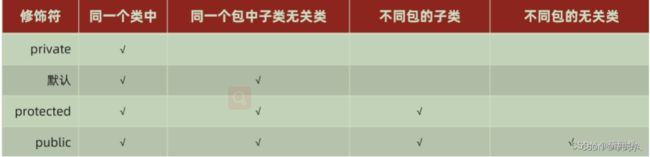
访问修饰符 public,private,protected,以及不写(默认)时的区别?【重要】
局部变量和成员变量的区别?
1.局部变量:方法内,没有默认值(使用前必须赋值),栈中,方法调用
2.成员变量:类中方法外,有默认值,堆中,对象创建而创建
重载(Overload)和重写(Override)的区别?【重要】
重载(Overload)发生在同一个类中,同一方法名,不同的形参列表(个数,顺序,参数类型)
(与返回值和访问修饰符无关)
重写(Override)父子类中,子类对父类方法进行重写,方法体不同,方法声明一样
equals与==的区别?【重要】
== 作用:
基本数据类型:比较的是值是否相同
引用数据类型:比较的是地址值是否相同
equals作用:
引用类型:默认情况下,比较的是地址值
特:String,Integer,Date这些类库中equels被重写,比较的是内容而不是地址值
++i与i++的区别
数组实例化有几种方式?
Java中各种数据默认值
Byte,short,int,long 默认是都是 0Boolean 默认值是 falseChar 类型的默认值是 ’’Float 与 double 类型的默认是 0.0对象类型的默认值是 null
Java常用包有那些?【重要】
Java . langJava . ioJava . sqlJava . utilJava . awtJava . netJava . math
Object类常用方法有那些?
Java中所有的类都有一个共同的祖先。这个祖先就是Object类
EqualsHashcodetoStringwaitnotifyclonegetClass
java中有没有指针?
有指针,但是隐藏了,开发人员无法直接操作指针,由jvm来操作指针
构造方法能不能显式调用?
内部类与静态内部类的区别?
定义在一个类内部的类叫内部类,包含内部类的类称为外部类。内部类可以声明public、protected、private等访问限制,可以声明 为abstract的供其他内部类或外部类继承与扩展,或者声明为static、final的,也可以实现特定的接口。外部类按常规的类访问方式使用内部 类,唯一的差别是外部类可以访问内部类的所有方法与属性,包括私有方法与属性。
1.静态内部类可以有静态成员(方法,属性),而非静态内部类则不能有静态成员(方法,属性)。
* 2.静态内部类只能够访问外部类的静态成员,而非静态内部类则可以访问外部类的所有成员(方法,属性)。
Static关键字有什么作用?【****】
Static可以修饰内部类、方法、变量、代码块
Static修饰的类是静态内部类Static修饰的方法是静态方法,表示该方法属于当前类的,而不属于某个对象的,静态方法也不能被重写,可以直接使用类名来调用。在 static方法中不能使用this或者super关键字。Static修饰变量是静态变量或者叫类变量,静态变量被所有实例所共享,不会依赖于对象。静态变量在内存中只有一份拷贝,在JVM加载类 的时候,只为静态分配一次内存。Static 修饰的代码块叫静态代码块,通常用来做程序优化的。静态代码块中的代码在整个类加载的时候只会执行一次。静态代码块可以有多 个,如果有多个,按照先后顺序依次执行。
final在java中的作用,有哪些用法?【****】
final 也是很多面试喜欢问的地方 , 但我觉得这个问题很无聊 , 通常能回答下以下 5 点就不错了 :1. 被final修饰的类不可以被继承2. 被final修饰的方法不可以被重写3. 被final修饰的变量不可以被改变【常量】 . 如果修饰引用 , 那么表示引用不可变 , 引用指向的内容可变 .4. 被 final 修饰的方法 ,JVM 会尝试将其内联 , 以提高运行效率5. 被final修饰的常量,在编译阶段会存入常量池中 .除此之外 ,编译器对 final 域要遵守的两个重排序规则更好 :在构造函数内对一个 final 域的写入 , 与随后把这个被构造对象的引用赋值给一个引用变量 , 这两个操作之间不能重排序初次读一个包含 final 域的对象的引用 , 与随后初次读这个 final 域 , 这两个操作之间不能重排序
StringString StringBuffer 和 StringBuilder 的区别是什么?【重要】
String是字符串常量,用final修饰,不能继承(少量操作)
StringBuffer字符串变量(线程安全)(多线程大量操作) synchronized关键字
StringBuilder字符串变量(非线程安全)
讲下java中的math类有那些常用方法?
。。。。
String类的常用方法有那些?
什么是接口?为什么需要接口?接口特点?
接口就是某个事物对外提供的一些功能的声明,是一种特殊的java类,接口弥补了java单继承的缺点
接口中声明全是 public static fifinal 修饰的常量接口中所有方法都是抽象方法接口是没有构造方法的接口也不能直接实例化接口可以多继承
抽象类和接口的区别?【重要】
不断更新
java集合面试题
1.集合体系
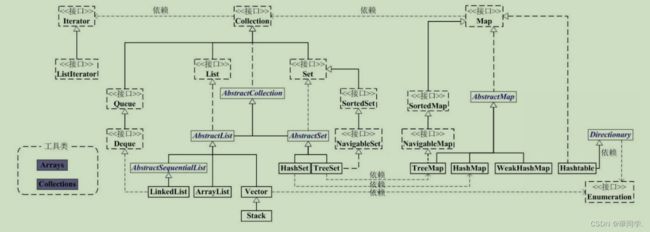
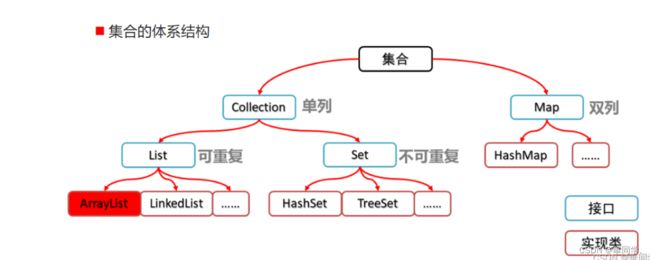
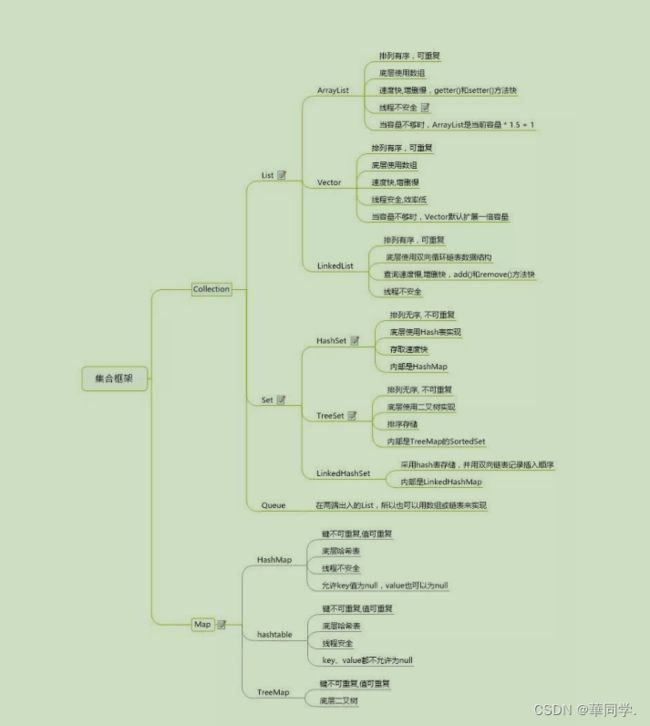
2.list
java的list是非常常用的数据类型,list是有序的Collection
List一共三个实现类:ArrayList,Vector和LinkedList
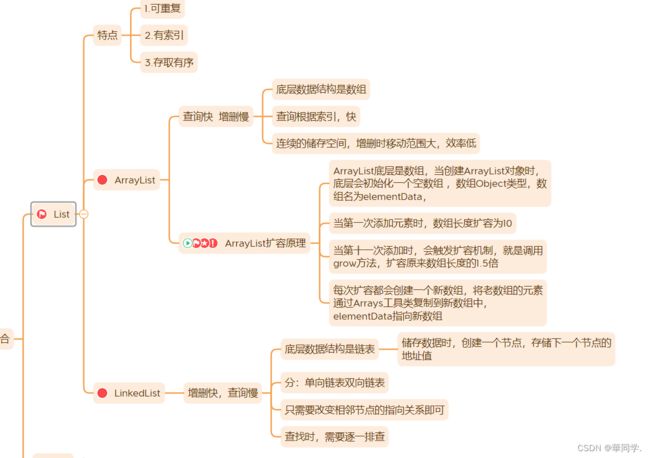
Vector(数组实现、线程同步)
Vector 与 ArrayList 一样,也是通过数组实现的,不同的是 它支持线程的同步,即某一时刻只有一 个线程能够写 Vector ,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此, 访问它比访问 ArrayList 慢
3.Set(无序不可重复)
Set 注重独一无二的性质,该体系集合用于存储无序(存入和取出的顺序不一定相同)元素, 值不能重 复 。对象的相等性本质是对象 hashCode 值(java 是依据对象的内存地址计算出的此序号)判断 的, 如果想要让两个不同的对象视为相等的,就必须覆盖 Object 的 hashCode 方法和 equals 方 法
HashSet如何去重的
TreeSet(二叉树)*****
4.Map(双列集合)
HashMap底层原理******
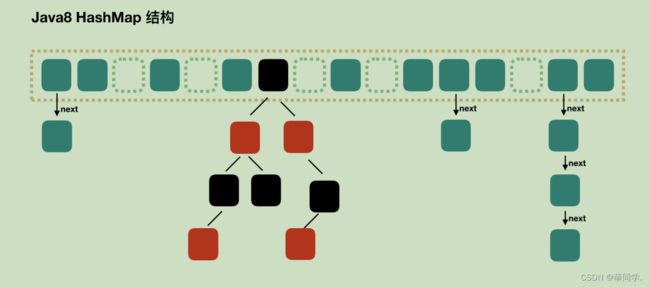
1.HashMap底层数据结构是 数组 + 链表 在1.8优化了数据结构引入了红黑树,目前结构 数组 + 链表 + 红黑树
2.当创建HashMap对象,底层首先初始化了一个Node类型的数组,加载因子是 0.75 数组名table
3.第一次 put (k,v)元素时,触发扩容机制,调用resize() 方法 数组长度初始为16,阈值为12(16*0.75)
4.第二次第三次。。。都不会扩容,当添加元素个数超过阈值12时,触发扩容机制 再次调用 resize() 数组长度和阈值都扩容原来的2倍
5.如果 储存的key 值相同 (key 的 hash 和内容 都相同),则新添加的节点的值覆盖旧值。
6.如果要添加的节点存入的下标相同,但key 的内容不同,则形成链表结构 新添加的节点会挂载到旧结点下
7.当挂载的节点个数大于等于8个,并且数组长度大于64时,形成红黑树
8.当挂载的结点个数大于等于8个,但是数组长度不足64时,不会形参红黑树,会先执行扩容机制 ,重新离散(计算每个结点要存入的新下标)
9.如果计算结点要存入的数组下标呢?通过key的哈希值和数组的长度进行运算
具体:key的哈希 & (数组长度-1) 得出要存入的下标
map.get(k)实现原理
1.先调用k的hashCode()算出哈希值,并通过哈希算法转换成数组的下标
2.在通过数组下标快速定位到某个位置上,如果这个位置什么都没有,则返回null,如果这个位置上有单向链表,那么他会拿着k和单向链表上的每一个节点的k进行equals,如果equals方法都返回false,则get方法返回null,如果其中一个返回true,那么就是我们要找的value
ConcurrentHashMap
HashTable使用的是Synchronized关键字,ConcurrentHashMap是JDK1.7使用了锁分段式来保证线程安全,JDK1.8取消了分段式,锁采用CAS和Synchronized来保证安全,数据结构跟HashMap1.8结构类似(数组+链表+红黑树)
Synchronized只锁住了当前链表或者红黑二叉树的首节点,这样hash不冲突,就不会产生并发,效率提高