JavaEE——文件操作和IO
文章目录
- 一、认识什么是文件
- 二、Java对文件的操作
- 三、文件内容读写——数据流
-
- 1. 对字节流中的读操作解释
- 2.对字节流中写操作解释
- 3.解释 input 、output 和 closs() 方法
- 4. Scanner 在文件中的使用
- 四、简单使用代码操作文件
一、认识什么是文件
狭义的文件: 指的是硬盘上的文件和目录。
广义的文件: 泛指计算机中很多的软硬件资源,将这些资源抽象成文件,以文件的形式统一管理。
注:在本篇文章中讨论的是狭义的文件。
- 文件路径
对于每个文件,在硬盘上都有一个具体的 “路径” 。
如图所示,这个图片的路径是:D:/picture/下载.jpg
对于路径表示,有下面两种表示形式:
- 绝对路径: 以 c,d 盘符开头的路径。
- 相对路径: 以当前所在的目录为基准,以 . 或者 … 开头,找到执行路径。
假设有一个文件名称是 111 ,在 tmp 目录下,有下面的不同情况:

- 文件类型
根据不同的文件,大体上可以归为两类:
- 文本文件: 存的是文本,字符串。这个文本中的数据一定是合法的字符,都是在指定字符编码表之中的。
- 二进制文件: 存的是二进制数据,不一定是字符串。没有任何限制,可以存储任何想存的数据。
两种文件类型的判断:直接用记事本打开,如果是乱码,就说明是二进制,否则就是文本文件。
二、Java对文件的操作
操作分为下面两类:
- 针对文件系统操作。(文件的创建,删除,重命名等)
- 针对文件内容操作。(文件的读和写)
在这里,Java标准库中提供了 File 类对一个文件进行描述。要注意的是,有 File 对象不一定就真实存在该文件。
如图:

文件位置示例:D:/cat.jpg
parent: D:/ (表示当前文件所在的目录)
child: cat.jpg (表示文件的自身名称)
File 类中含有的方法签名(了解)
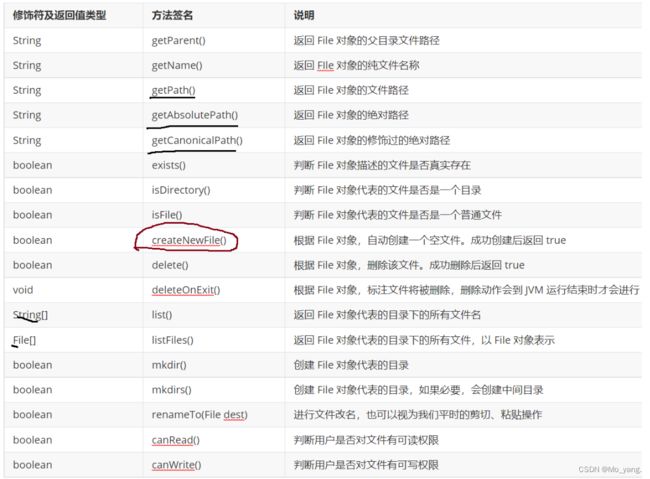
对其中划线的简单解释:
黑色划线方法展示:
绝对路径形式:
import java.io.File;
import java.io.IOException;
public class IOTest {
public static void main(String[] args) throws IOException {
//这里不要求真的有一个 text.txt
File file = new File("D:/text.txt");
//返回 file 对象的纯文件名
System.out.println(file.getName());
//返回 file 对象的父目录文件
System.out.println(file.getParent());
//返回 file 对象的文件路径
System.out.println(file.getPath());
//返回 file 对象的绝对路径
System.out.println(file.getAbsolutePath());
//返回 file 对象的修饰过的绝对路径
System.out.println(file.getCanonicalPath());
}
}
结果如图:

相对路径形式:
import java.io.File;
import java.io.IOException;
public class IOTest {
public static void main(String[] args) throws IOException {
//这里不要求真的有一个 text.txt
File file = new File("./text.txt");
//返回 file 对象的纯文件名
System.out.println(file.getName());
//返回 file 对象的父目录文件
System.out.println(file.getParent());
//返回 file 对象的文件路径
System.out.println(file.getPath());
//返回 file 对象的绝对路径
System.out.println(file.getAbsolutePath());
//返回 file 对象的修饰过的绝对路径
System.out.println(file.getCanonicalPath());
}
}
运行结果:
createNewFile() 根据 File 对象,自动创建一个空文件。成功创建后返回 true
deleteOnExit() 根据 File 对象,标注文件将被删除,删除动作会到 JVM 运行结束时才会进行
这个方法简单来讲就是,程序退出的时候自动删除文件。
这个方法大多数情况下是程序中需要使用到 “临时文件” 的时候需要用到。
如图:
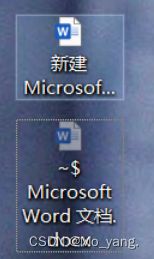
下面颜色较浅的就是临时文件,这个保存了当前实时编辑的内容(尤其是没有保存的)。
三、文件内容读写——数据流
假设,这里有一个 100 字节的文件,我们可以有很多种读取方法(写操作亦然):
- 一次读取 100 字节文件,一次读完
- 一次读取 50 个字节,两次读完
- 一次读取 10 个字节,十次读完…
将上面的文件内容想象成水流,这样看来将读写操作描述成 数据流 其实也没有什么问题。
Java 标准库中对流对象从类型上分为两大类:
-
字节流: 操作二进制数据,以字节为单位
InputStream、FileInputStream
OutPutStream、FileOutputStream -
字符流: 操作文本数据,以字符为单位
Reader、FileReader
Writer、FileWriter
从上面看,可能感觉这些方法非常多,有些复杂。但是,这些类的使用很固定,核心是四个操作:
- 打开文件
- 关闭文件
- 读文件 --> 针对 InputStream / Reader
- 写文件 --> 针对 OutPutStream / Writer
1. 对字节流中的读操作解释
InputStream 读文件概述
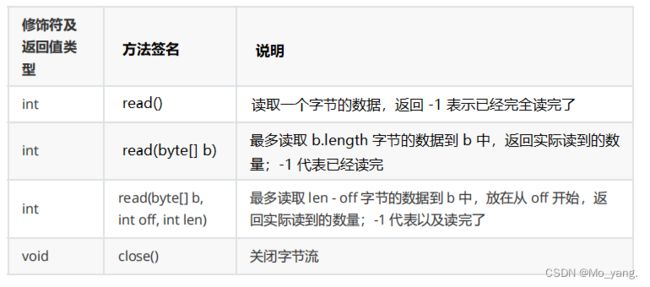
InputStream 是一个抽象类,要使用还要具体的类进行实现。上面的方法在这里了解知晓即可,现在我们只关心读取文件,所以主要使用 FileInputStream。
FileInputStream 读文件概述

在这里将文件完全读取的方式有两种,如下:
第一种:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class IOTest {
public static void main(String[] args) throws IOException {
//创建一个 txt 文件,并在外面写入 hello 单词
File file = new File("./hello.txt");
file.createNewFile();
try(InputStream is = new FileInputStream("hello.txt")){
while(true){
//这里的 read 操作就是每次读取一个字节数据,当返回 -1 时表示读取完毕
int b = is.read();
if(b == -1){
break;
}
System.out.printf("%c",b);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行展示:
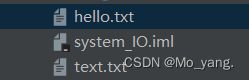
生成了一个 hello.txt 这样的文档,已经提前在里面写入 hello
读取截图:
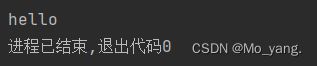
第二种:
import java.io.*;
public class IOTest {
public static void main(String[] args){
try(InputStream is = new FileInputStream("hello.txt")){
while(true){
//这里使用数组来接受读取到的元素
byte[] buf = new byte[1024];
int len;
len = is.read(buf);
if(len == -1){
break;
}
for (int i = 0; i < len; i++) {
System.out.printf("%c",buf[i]);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
运行结果:
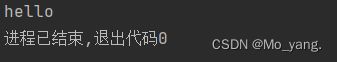
解释两个代码之间的区别
第一种读取时的操作

读取并打印的方式是读一个打印一个,进行了多次 IO 操作
第二种读取时的操作

我们知道,IO 操作就是访问硬盘,是需要消耗时间的,频繁的进行 IO 操作,无疑更加消耗时间
通过上面两个的对比不难发现:
第一个版本,每次读取一个字节,循环次数很多,read 的次数也就多 IO 操作花费的时间也就变多了。
第二个版本,一次读取 1024 个字节,循环的次数明显的降低了很多,read 的此处减少 IO 操作花费的时间也就少多了。
这里解释一下为什么一次读取 1024 个字节,以及如何返回 -1 结束读取
对代码进行简单的修改:
import java.io.*;
public class IOTest {
public static void main(String[] args){
//这里尝试读取的是一个图片
try(InputStream is = new FileInputStream("D:/picture/下载.jpg")){
while(true){
//这里使用数组来接受读取到的元素
byte[] buf = new byte[1024];
int len;
len = is.read(buf);
//打印每次获取元素的长度
System.out.println("len:" + len);
if(len == -1){
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}
运行截图:

如上图所示,每次读取都会读 1024 个元素长度,直到最后读取到的字节数不足 1024 就显示读到的数量。
读取结束后就返回出了 -1 结束了循环。
2.对字节流中写操作解释
字符流和字节流中的操作相差不大,这里就只介绍字节流的问题
OutputStream 写文件概述

同样的 OutputStream 也是一个抽象类,要使用还需要的具体的实现类,现在还是只关心写入文件,所以使用 FileOutputStream。
简单实现两种写入方式
这两种方式没有什么太大差别
第一种:
import java.io.*;
public class IOTest {
//写入字符
public static void main(String[] args) throws IOException {
File file = new File("./output.txt");
//创建一个 txt 文件
file.createNewFile();
OutputStream os = new FileOutputStream("output.txt");
os.write(10);
os.write(20);
os.write(30);
os.write(40);
//刷新操作
os.flush();
os.close();
//读取写入的内容
InputStream is = new FileInputStream("output.txt");
while(true){
byte[] buf = new byte[1024];
int len;
len = is.read(buf);
if(len == -1){
break;
}
for (int i = 0; i < len; i++) {
System.out.println(buf[i]);
}
}
is.close();
}
}
运行结果

第二种:
import java.io.*;
public class IOTest {
public static void main(String[] args) throws FileNotFoundException {
OutputStream os2 = new FileOutputStream("output.txt");
//以数组的形式存储元素
byte[] a = new byte[]{1,2,3,4};
try {
os2.write(a);
//冲刷缓冲区(重要)
os2.flush();
} catch (IOException e) {
e.printStackTrace();
}
//读取存入的元素
InputStream is2 = new FileInputStream("output.txt");
while(true){
byte[] b = new byte[1024];
int len;
try {
len = is2.read(b);
if(len == -1){
break;
}
for (int i = 0; i < len; i++) {
System.out.println(b[i]);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果

通过上面的两次写入,我们会发现一个问题,在第二次写入后读取发现,第一次写入的元素消失不见了。
这里 OutputStream 在默认情况下,在打开一个文件时,会先清空文件原有的内容。
3.解释 input 、output 和 closs() 方法
- input 和 output
要知道的是 input 和 output 的方向是以 CPU 为中心来看待的。
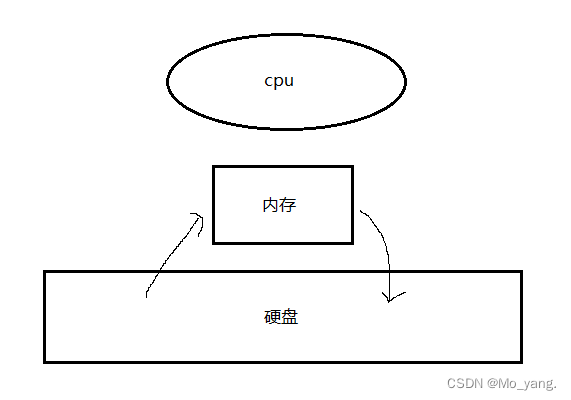
以CPU为中心
- 数据朝着 CPU 的方向流入,就是输入。所以将,数据从硬盘到内存,称之为读 input。
- 数据远离 CPU 的方向流出,就是输出。所以将,数据从内存到硬盘,称之为写 output
- close() 方法
close 方法不难理解,在这里就是关闭文件。
要更加清楚 close 方法的重要性,我们就需要了解到 PCB 中的一个重要属性 文件描述附表。
文件描述符表: 相当与一个数组,记录了打开了那些文件。(即使 一个进程中的多个线程 有多个PCB,这里都共用一个文件描述符表) 如图:
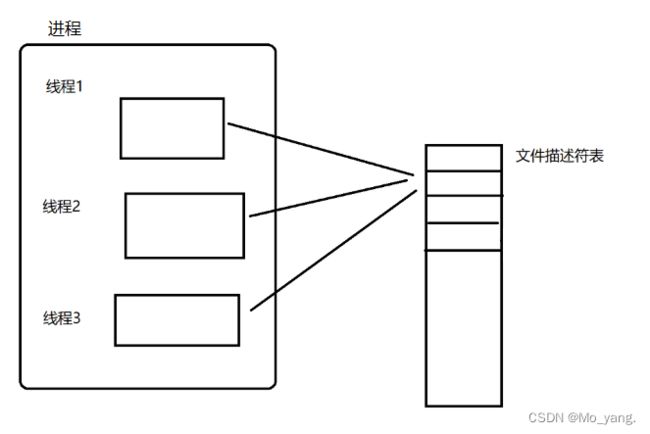
每次打开文件操作时,就会在文件描述符表中申请一个位置将信息存储。
此时,如果没有及时将文件描述符表进行 close 操作,这就意味着,文件描述符表就有可能会被占满,在这之后如果要打开文件就会打开失败!
要注意的是,Java 中虽然有 GC 回收机制,但是并不能确保回收及时,不手动关闭仍然存在风险。
flush 和 close 方法同样有着举足轻重的地位。
4. Scanner 在文件中的使用
Scanner 是搭配流对象进行使用的。如图:

代码展示:
import java.io.*;
import java.util.Scanner;
public class IOTest {
public static void main(String[] args){
try(InputStream is = new FileInputStream("text.txt")){
Scanner sc = new Scanner(is);
//此时获取对象的输入流就是从文件中获取了
System.out.println(sc.next());
} catch (IOException e) {
e.printStackTrace();
}
}
}
这里已经提前在 text.txt 文档中存入 hello 元素

这就说明了这里的流对象从键盘输入变为了从文档中获取。
四、简单使用代码操作文件
要求1:扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要删除该文件。
- 删除操作前准备
import java.io.*;
import java.util.Scanner;
public class IOTest7 {
private static Scanner scanner = new Scanner(System.in);
public static void main(String[] args) {
//让用户输入一个要删除的目录
System.out.println("请输入要删除的文件目录");
String Pass = scanner.next();
//针对用户的输入进行简单判定,将输入元素传递给 File
File root = new File(Pass);
//判断是不是文件目录
if(!root.isDirectory()){
//路径有误,或者只是一个普通文件,此时无法搜索
System.out.println("输入的目录有误");
return;
}
//再让用户输入一个要删除的文件名
System.out.println("请输入要删除的文件名:");
String Delete = scanner.next();
//对指定的路径进行扫描
//使用到递归操作,从根目录出发
//将要删除的文件目录,和文件名称 传递给删除操作函数
scanDir(root,Delete);
}
- 实现删除操作
private static void scanDir(File root, String delete) {
//这里用来更直观的看到代码如何寻找相应的目录
System.out.println("[scanDir]"+ root.getAbsolutePath());
//1.先列出当前目录下的内容
//获取当前根目录下的所有文件
File[] files = root.listFiles();
if(files == null){
//判断当前目录下是否为空
return;
}
//2.遍历当前的结果
for (File f: files) {
if(f.isDirectory()){
//如果是要删除的文件目录,就进行递归
scanDir(f,delete);
}else{
//除了文件夹,也要对普通文件检查
if(f.getName().contains(delete)){
System.out.println("确定要删除吗?");
String s = scanner.next();
if (s.equals("y") || s.equals("Y")){
f.delete();
System.out.println("删除成功");
}else{
System.out.println("删除失败");
}
}
}
}
}
}
代码解释

此处的操作是将整个当前根目录中的所有内容罗列出来。形如下图:
遍历操作在这里的作用就是,进入到一个文件目录后进行一次扫描,直到最深层的目录中,类似于多叉树的删除
运行展示:
这里提前已经在文件中放入一个 1.txt 文档

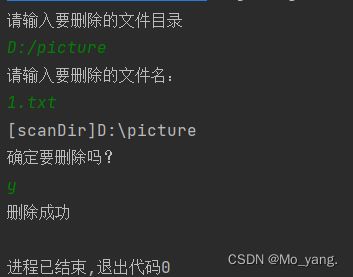

这样就成功删除了。
要求2: 进行普通文件的复制
import java.io.*;
import java.util.Scanner;
public class IOTest {
//实现复制粘贴
//输入两个路径
//源 和 目标 (从哪里拷贝到哪里)
public static void main(String[] args){
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要拷贝的文件");
String srcPath = scanner.next();
System.out.println("请输入要被拷贝的地方");
String desPath = scanner.next();
//将要拷贝的元素传递过来
File srcFile = new File(srcPath);
if(!srcFile.isFile()){
//如果源不是一个文件(或者目标不存在)就不做操作
System.out.println("当前输入的路径有误");
return;
}
File desFile = new File(desPath);
if (desFile.isFile()){
//如果当前已经存在也就不能拷贝
System.out.println("您当前输入的目标已经存在");
return;
}
//进行拷贝操作
//这里 try 支持包含多个对象,之间使用 ; 分割开来
try(InputStream inputStream = new FileInputStream(srcFile);
OutputStream outputStream = new FileOutputStream(desFile)){
//实现思路是一边进行读操作,一边写操作
//进行读操作
while(true){
int b =inputStream.read();
if(b == -1){
break;
}
//进行写操作
outputStream.write(b);
}
} catch (IOException e) {
e.printStackTrace();
}