PyTorch - GPU入门教程1
1. 安装GPU版本的PyTorch
登录PyTorch官网https://pytorch.org/,下载对应CUDA版本的PyTorch【不能直接pip install,否则安装上的是CPU版本的】

2. 查看GPU信息
(1)重要信息
!nvidia-smi
我的GPU版本很垃圾,本blog仅为阐述使用方法

(2)详细信息
!nvidia-smi -i 0 -q
==============NVSMI LOG==============
Timestamp : Sun Jul 30 19:59:38 2023
Driver Version : 527.37
CUDA Version : 12.0
Attached GPUs : 1
GPU 00000000:01:00.0
Product Name : NVIDIA GeForce GTX 1650
Product Brand : GeForce
Product Architecture : Turing
Display Mode : Disabled
Display Active : Disabled
Persistence Mode : N/A
MIG Mode
Current : N/A
Pending : N/A
Accounting Mode : Disabled
Accounting Mode Buffer Size : 4000
Driver Model
Current : WDDM
Pending : WDDM
Serial Number : N/A
GPU UUID : GPU-fc8d7cba-de6b-c3b4-f29a-1554c1aa0ba0
Minor Number : N/A
VBIOS Version : 90.17.46.00.ab
MultiGPU Board : No
Board ID : 0x100
Board Part Number : N/A
GPU Part Number : 1F99-753-A1
Module ID : 1
Inforom Version
Image Version : G001.0000.02.04
OEM Object : 1.1
ECC Object : N/A
Power Management Object : N/A
GPU Operation Mode
Current : N/A
Pending : N/A
GSP Firmware Version : N/A
GPU Virtualization Mode
Virtualization Mode : None
Host VGPU Mode : N/A
IBMNPU
Relaxed Ordering Mode : N/A
PCI
Bus : 0x01
Device : 0x00
Domain : 0x0000
Device Id : 0x1F9910DE
Bus Id : 00000000:01:00.0
Sub System Id : 0x09EF1028
GPU Link Info
PCIe Generation
Max : 3
Current : 3
Device Current : 3
Device Max : 3
Host Max : 3
Link Width
Max : 16x
Current : 8x
Bridge Chip
Type : N/A
Firmware : N/A
Replays Since Reset : 0
Replay Number Rollovers : 0
Tx Throughput : 0 KB/s
Rx Throughput : 0 KB/s
Atomic Caps Inbound : N/A
Atomic Caps Outbound : N/A
Fan Speed : N/A
Performance State : P8
Clocks Throttle Reasons
Idle : Active
Applications Clocks Setting : Not Active
SW Power Cap : Not Active
HW Slowdown : Not Active
HW Thermal Slowdown : Not Active
HW Power Brake Slowdown : Not Active
Sync Boost : Not Active
SW Thermal Slowdown : Not Active
Display Clock Setting : Not Active
FB Memory Usage
Total : 4096 MiB
Reserved : 146 MiB
Used : 710 MiB
Free : 3239 MiB
BAR1 Memory Usage
Total : 256 MiB
Used : 2 MiB
Free : 254 MiB
Compute Mode : Default
Utilization
Gpu : 0 %
Memory : 0 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
FBC Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
Ecc Mode
Current : N/A
Pending : N/A
ECC Errors
Volatile
SRAM Correctable : N/A
SRAM Uncorrectable : N/A
DRAM Correctable : N/A
DRAM Uncorrectable : N/A
Aggregate
SRAM Correctable : N/A
SRAM Uncorrectable : N/A
DRAM Correctable : N/A
DRAM Uncorrectable : N/A
Retired Pages
Single Bit ECC : N/A
Double Bit ECC : N/A
Pending Page Blacklist : N/A
Remapped Rows : N/A
Temperature
GPU Current Temp : 56 C
GPU Shutdown Temp : 99 C
GPU Slowdown Temp : 94 C
GPU Max Operating Temp : 75 C
GPU Target Temperature : N/A
Memory Current Temp : N/A
Memory Max Operating Temp : N/A
Power Readings
Power Management : N/A
Power Draw : 3.65 W
Power Limit : N/A
Default Power Limit : N/A
Enforced Power Limit : N/A
Min Power Limit : N/A
Max Power Limit : N/A
Clocks
Graphics : 300 MHz
SM : 300 MHz
Memory : 405 MHz
Video : 540 MHz
Applications Clocks
Graphics : N/A
Memory : N/A
Default Applications Clocks
Graphics : N/A
Memory : N/A
Deferred Clocks
Memory : N/A
Max Clocks
Graphics : 1785 MHz
SM : 1785 MHz
Memory : 6001 MHz
Video : 1650 MHz
Max Customer Boost Clocks
Graphics : 1785 MHz
Clock Policy
Auto Boost : N/A
Auto Boost Default : N/A
Voltage
Graphics : N/A
Fabric
State : N/A
Status : N/A
Processes
GPU instance ID : N/A
Compute instance ID : N/A
Process ID : 8260
Type : C
Name : D:\PYTHON\Anaconda\envs\basic_torch\python.exe
Used GPU Memory : Not available in WDDM driver model
GPU instance ID : N/A
Compute instance ID : N/A
Process ID : 14084
Type : C+G
Name :
Used GPU Memory : Not available in WDDM driver model
3. 查看可用GPU数量
torch.cuda.device_count()

4. 这两个函数允许我们在请求的GPU不存在的情况下运行代码
def try_gpu(i=0):
"""如果存在,则返回gpu(i),否则返回cpu()。"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus():
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]。"""
devices = [
torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()

5. 在GPU上定义tensor
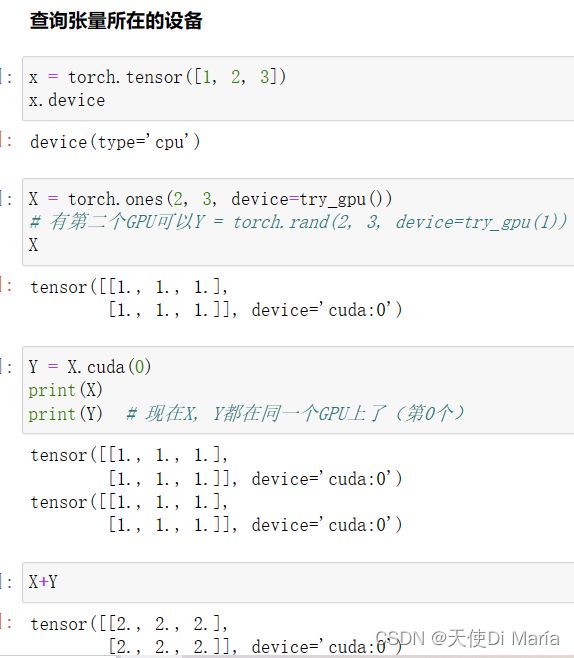
6. 在GPU上定义网络

7. 再次查看GPU信息
!nvidia-smi

如果发现仅仅定义了几个很小的tensor,GPU显存就占用了好几百兆,这是正常现象,GPU初始化需要占用的显存,根据测试,不同GPU初始化需要的显存大小不同,1060 Ti需要583M左右,而服务器上的V100需要1449M左右,这部分无法优化。初始化显存的意思是,即使只是执行a = torch.randn((1, 1)).to(‘cuda’)命令,显存的占用可能达到几百M,这其中只有极少是张量a占用的,绝大部分都是GPU初始化的占用。不必担心~
为了验证上面的说法,可以定义XX = torch.ones(2000, 3000, device=try_gpu()) ,然后发现,显存占用从710M增加到734M,600W数据量大小的tensor只占用了很少的显存。
8. 重启显存归0(CPU运行内存和GPU显存本质都是RAM,断电即无)
!nvidia-smi
