大数据学习笔记-Yarn(一)
1、yarn产生和发展历史
背景:
数据、程序、运算资源三者组合在一起,才能完成数据的处理,单机不存在问题,但是分布式环境如何协调是一个问题。
Hadoop早期用户使用Hadoop与众多主机上运行的桌面程序类似:
在少了几个节点上建立一个集群、将数据载入HDFS、运行mapreduce
Hadoop演进阶段:
Ad hoc集群以单用户的方式建立,随着私人集群的使用实现了HDFS集群的共享,不同于HDFS,共享mapreduce非常困难。HOD集群解决;额集群条件下多租户的问题yahoo发展部署了Hadoop on Demand平台。在节点分配上实现了多个用户使用mapreduce集群。缺点无法支持数据本地化、资源回收效率低、无法动态扩容能力,多租户共享延迟高,阶段2共享计算集群JobTracker:中央守护进程(压力大、可靠性欠缺、计算模型单一),TaskTracker
阶段3:Yarn集群,拆分mapreduce,剥离出资源管理成为单独框架成为Yarn,mapreduce专注于数据处理,两者解耦。
YARN被设计用以解决以往架构的需求和缺陷的资源管理和调度软件
对Yarn的需求(特性):可扩展性(平滑的扩展至数万个节点)、可维护性(软件和应用程序完全解耦)、多租户(同一集群中多个租户并存,细粒度共享单个节点)、位置感知(将计算移至数据所在位置)、可靠性和可用性(高可用)、对编程模型多样化的支持(支持多样化的编程模型,不仅仅以Mapreduce为中心)、灵活的资源模型(动态分配)、向后兼容。
Apache Hadoop Yarn(Yet Another Resource Negotiator,另一种资源协调者 ):资源管理系统和调度平台。
资源管理系统:集群的硬件资源,和程序运行相关,比如内存、CPU
调度平台:多个程序同时申请资源,如何分配
通用:不仅仅支持Mapreduce,理论上支持各种计算程序。
2、yarn和MRv1区别
Hadoop1中,Mapreduce负责数据计算、资源管理,运行时环境(JobTracker--资源管理和任务管理调度,TaskTracker--单个节点的资源管理和任务执行)、编程模型(Mapreduce)、数据处理引擎(Map Task和Reduce Task)。
Hadoop2中,编程模型和数据处理引擎没有变化,但运行时环境(resourceManager,nodemanager)完全被重写,有Yarn来专管资源管理和任务调度。Yarn将程序内部具体管理职责交给一个叫做ApplicationMaster
3、yarn集群安装部署
标准的主从架构模式,主角色ResourceManager(RM)是Yarn的主角色,决定应用程序之间资源分配的最终权限,RM接受用户作业提交,通过NodeManager(NM)管理本机器上的计算资源,根据RM命令,启动Container容器、监视容器资源使用情况。并向主角色汇报。
通常把NodeManager和DataNode部署咋同一台机器上(有数据的地方就有可能产生计算,移动程序的成本比移动数据的成本低)。
| 服务器 | 运行角色 |
| node1 | namenode、datanode 、resourcemanager、nodemanager |
| node2 | secondarynamenode、datanode、nodenamager |
| node3 | datanode、nodenamager |
安装部署可参考Hadoop集群搭建安装教程(详细完整)_天码村的博客-CSDN博客_hadoop集群搭建方法
hosts配置、防火墙关闭、免密登录、时间同步、配置文件修改等
# 启动yarn、启动MapReduce历史服务:MRJobHistoryServer
start-yarn.sh
mapred --daemon start historyserverYarn初体验,示例程序运行
cd /export/server/hadoop-3.1.4/share/hadoop/mapreduce/计算圆周率测试
yarn jar hadoop-mapreduce-examples-3.1.4.jar pi 2 2第一步就是链接resourcemanager

web页面查看
还可以进入查看程序运行的日志信息

yarn HA集群
在Hadoop2.4之前,ResourceManager 是yarn集群中的单点故障(SPOF)
为了解决RM的单点故障问题,yarn设计了Activte/Standy模式的HA
Hadoop官方推荐的方案:基于Zookeeper集群实现
实现HA的关键:主备之间状态数据同步、主备之间顺利切换,
针对数据同步,zk来存储共享集群的状态数据,本质也是一个小的文件系统
针对主备之前切换:手动故障转移和自动故障转移
RM可以选择嵌入基于zk的ActiveStandbyElector来实现自动故障转移
创建锁节点-->注册watcher监听-->准备切换
4、HA YARN搭建(根据黑马教程配置)
安装前需要安装好jdk
##
检测集群时间是否同步
检测防火墙是否关闭
检测主机 ip映射有没有配置
##下载安装包、解压tar -zxvf zookeeper-3.4.6.tar.gz
mv zookeeper-3.4.6 zookeeper##修改环境变量(注意:3台zookeeper都需要修改)
vi /etc/profile
export ZOOKEEPER_HOME=/export/server/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile##修改Zookeeper配置文件
cd zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
添加内容:
dataDir=/export/data/zookeeper/zkdata
## (心跳端口、选举端口)
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
创建文件夹:
cd export/server/zookeeper
mkdir zkdata
在data文件夹下新建myid文件,myid的文件内容为:
cd zkdata
echo 1 > myid##分发安装包到其他机器
scp -r /export/data/zookeeper root@node2:$PWD
scp -r /export/data/zookeeper root@node3:$PWD##修改其他机器的配置文件
修改myid文件
到mini2上:修改myid为:2
到mini3上:修改myid为:3##启动(每台机器)
zkServer.sh start
或者编写一个脚本来批量启动所有机器:
for host in node1 node2 node3
do
ssh $host "source /etc/profile;/export/server/zookeeper/bin/zkServer.sh start"
done##查看集群状态
jps(查看进程)
zkServer.sh status(查看集群状态,主从信息)如果启动不成功,可以观察zookeeper.out日志,查看错误信息进行排查
-----------------------------
配置文件中参数说明:tickTime这个时间是作为zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是说每个tickTime时间就会发送一个心跳。
initLimit这个配置项是用来配置zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过10个心跳的时间(也就是tickTime)长度后 zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20秒。
syncLimit这个配置项标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。
dataDir顾名思义就是zookeeper保存数据的目录,默认情况下zookeeper将写数据的日志文件也保存在这个目录里;
clientPort这个端口就是客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求;
server.A=B:C:D中的A是一个数字,表示这个是第几号服务器,B是这个服务器的IP地址,C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的leader服务器交换信息的端口,D是在leader挂掉时专门用来进行选举leader所用的端口。
----------------------------------------------------------------
export JAVA_HOME=/root/apps/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
yarn配置文件修改
fs.defaultFS
hdfs://node1.itcast.cn:8020
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster1
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
node1.btks.cn
yarn.resourcemanager.hostname.rm2
node2.btks.cn
yarn.resourcemanager.webapp.address.rm1
node1.btks.cn:8088
yarn.resourcemanager.webapp.address.rm2
node2.btks.cn:8088
yarn.resourcemanager.ha.automatic-failover.enabled
true
hadoop.zk.address
node1.btks.cn:2181,node2.btks.cn:2181,node3.btks.cn:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
将配置拷贝到其他节点
测试故障转移
yarn rmadmin -getAllServiceState
访问node1:8088,自动跳转到node2主节点
杀死主节点,自动切换到备份节点

手动启动被杀死的节点
yarn --daemon start resourcemanager查看结果

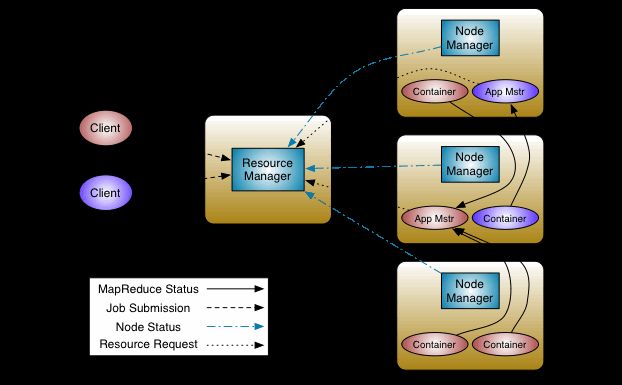
5、Yarn架构体系
集群物理层面
ResourceManager:决定系统中所有应用程序之间资源分布的最终权限,级最终仲裁者
主要有两个组件构成,调度器(Scheduler)和应用程序管理器(Application Manager,ASM)
NodeManager每个节点上的资源和任务管理器。
一方面,会定时向RM汇报本届点的使用情况和哥哥Container的运行状态
另一方面,他接收AM的container的启动和关闭
App层面
ApplicationMaster(APP mstr):与RM调度器协商以获取资源(用container表示);将得到的任务进一步分配给内部任务,与NM通讯启动、停止任务,监控任务状态,并在任务运行失败时重新为任务申请资源以重启任务
当前YARN自带了两个AM实现,一个用于显示AM编写方法的示例程序distributedshell,另一个是运行Mapreduce应用程序的AM-MRAppMaster
以上三个共同构成Yarn的3大组件
其他组件
client
container容器(资源的抽象):封装了某个节点上的多维度资源,当下仅支持CPU和内存两种资源,底层使用了轻量级资源隔离机制Cgroups
核心交互流程

通讯协议,涉及跨机器跨网络通讯,yarn底层使用RPC协议实现通讯
RPC协议组成,JOBClient(作业提交客户端)、Admin(管理员)

yarn交互流程

应用类型:短应用程序,比如Mapreduce作业、Spark作业
长应用程序:不出意外永不终止
MR交互流程:
第一阶段启动ApplicationMaster
第二个阶段由Application创建应用程序,为他申请资源,并监控整个运行过程
