flink-DataStreamAPI常用算子
1、Environment
1.1 getExecutionEnvironment
创建一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,也就是说,getExecutionEnvironment会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment()
在创建环境的时候如果没有设置并行度,会以flink-conf.yaml配置文件中的配置为准,默认为1

1.2 createLocalEnvironment
返回本地执行环境,需要在调用时指定默认的并行度
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(1);
1.3 createRemoteEnvironment
返回集群执行环境,将jar提交到远程服务器。需要在调用时指定JobManager的IP和端口号,并指定要在集群中运行的jar包。
StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment("jobmangaer-hostname",6123,"YOURPATH//WordCount.jar");
2、Source
source是flink实时计算的起点,也就是数据的来源。
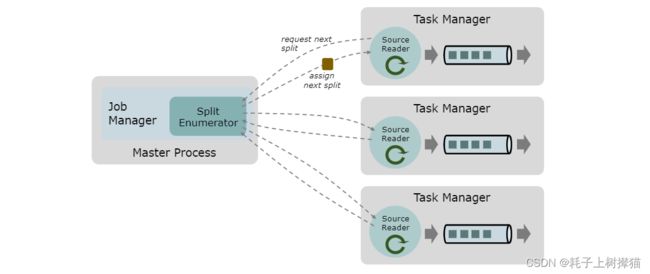
一个数据Source是由分片(split)、分片枚举器(SplitEnumerator)、源阅读器(SourceReader)组成:
- 分片(Split) 是对一部分 source 数据的包装,如一个文件或者日志分区。分片是 source 进行任务分配和数据并行读取的基本粒度。
- 源阅读器(SourceReader) 会请求分片并进行处理,例如读取分片所表示的文件或日志分区。SourceReader 在 TaskManagers 上的
SourceOperators并行运行,并产生并行的事件流/记录流。 - 分片枚举器(SplitEnumerator) 会生成分片并将它们分配给 SourceReader。该组件在 JobManager 上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给 reader。
2.1 从集合中获取数据源
env.fromCollection( List )
env.fromElements()
List<SensorReading> list = Arrays.asList(
new SensorReading("Sensor_1",System.currentTimeMillis(),36.1),
new SensorReading("Sensor_2",System.currentTimeMillis(),35.1),
new SensorReading("Sensor_3",System.currentTimeMillis(),36.7),
new SensorReading("Sensor_4",System.currentTimeMillis(),34.3),
new SensorReading("Sensor_5",System.currentTimeMillis(),37.2),
new SensorReading("Sensor_6",System.currentTimeMillis(),36.9),
new SensorReading("Sensor_7",System.currentTimeMillis(),38.6)
);
//从集合中获取数据源
DataStreamSource<SensorReading> dataStreamSource = env.fromCollection(list);
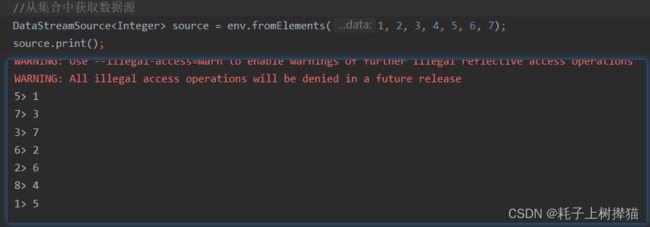
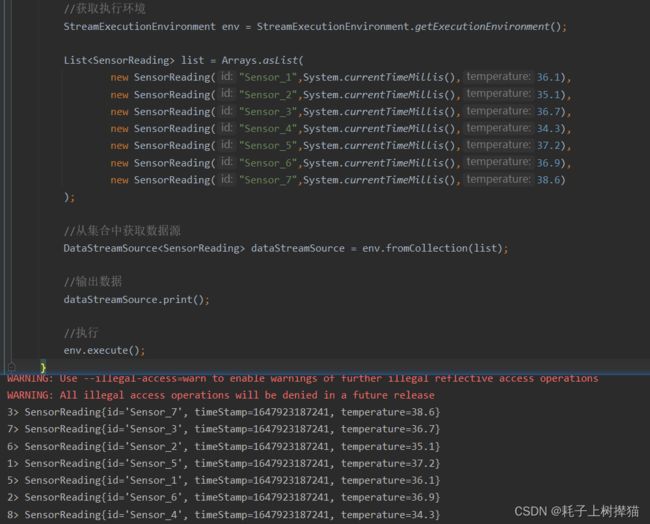
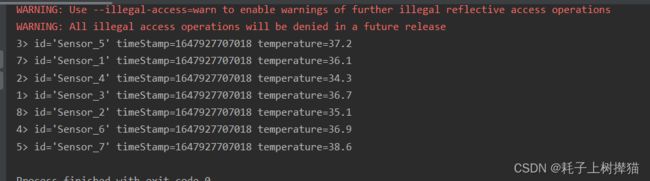
从输出结果可以看到,并没有按照我们输入的顺序进行输出,原因是输出任务在执行的时候是并行执行的,所以会导致输出的顺序不一致
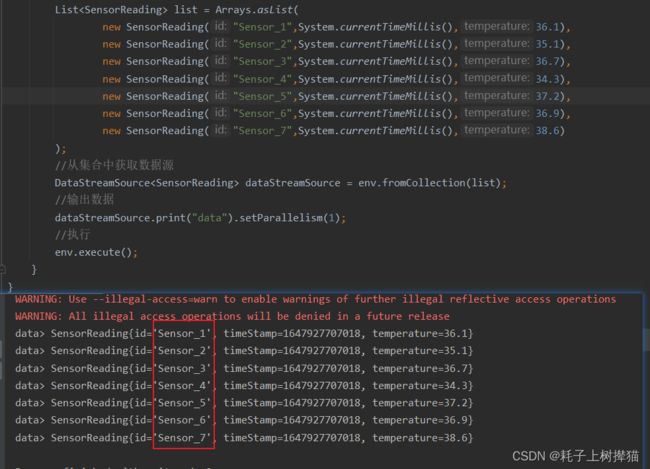
假如我们把输出的并行设为1 ,则输出就会按照顺序进行输出:
dataStreamSource.print("data").setParallelism(1);
2.2 从文件读取数据
readTextFile(path) :读取path 里所有的text文件,line-by-line and returns them as strings
readFile(fileInputFormat, path):根据fileInputFormat格式读取一次文件
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo):这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和path读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
测试数据(sourcetest.text):
id='Sensor_1' timeStamp=1647927707018 temperature=36.1
id='Sensor_2' timeStamp=1647927707018 temperature=35.1
id='Sensor_3' timeStamp=1647927707018 temperature=36.7
id='Sensor_4' timeStamp=1647927707018 temperature=34.3
id='Sensor_5' timeStamp=1647927707018 temperature=37.2
id='Sensor_6' timeStamp=1647927707018 temperature=36.9
id='Sensor_7' timeStamp=1647927707018 temperature=38.6
javaCode:
public class FlinkModelText {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
String filePath = "D:\\JAVA\\code\\flink\\flink-practice\\flink-model-one\\src\\main\\resources\\sourcetest.text";
DataStream<String> dataStream = env.readTextFile(filePath);
dataStream.print();
env.execute();
}
}
输出结果:
2.3 从socket中获取数据
安装netcat工具
下载地址:https://eternallybored.org/misc/netcat/
安装方式:解压即可用(配置全局变量)
常用命令:
想要连接到某处: nc [-options] hostname port[s] [ports] …
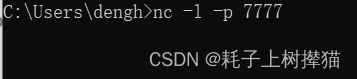
绑定端口等待连接: nc -l -p port [-options] [hostname] [port]
参数:
-g gateway source-routing hop point[s], up to 8
-G num source-routing pointer: 4, 8, 12, …
-h 帮助信息
-i secs 延时的间隔
-l 监听模式,用于入站连接
-n 指定数字的IP地址,不能用hostname
-o file 记录16进制的传输
-p port 本地端口号
-r 任意指定本地及远程端口
-s addr 本地源地址
-u UDP模式
-v 详细输出——用两个
-v可得到更详细的内容
-w secs timeout的时间
-z 将输入输出关掉——用于扫描时,其中端口号可以指定一个或者用lo-hi式的指定范围。
启动nc
启动flink服务
public class FlinkModelSocket {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataStream = env.socketTextStream("localhost", 7777);
dataStream.print();
env.execute();
}
}
显示结果
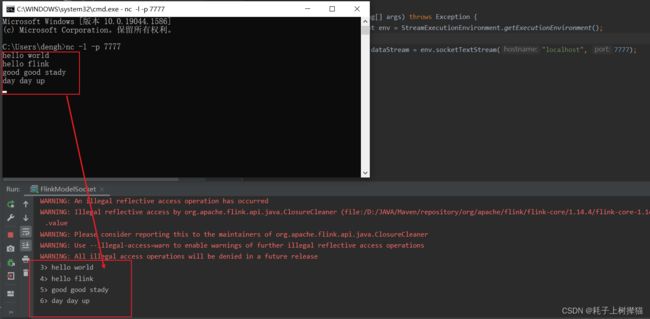
socket源的方式是接收到一条数据,就处理一条数据,没有数据发过来时就一直处于等待状态。
2.4 自定义数据源
addSource()
除了以上的source数据来源,我们还可以使用addsource()来自定义source。而addsource中只是传入一个SourceFunction就可以
public class FlinkModelUPF {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<SensorReading> dataStream = env.addSource( new MySensor());
dataStream.print();
env.execute();
}
public static class MySensor implements SourceFunction<SensorReading> {
//定位一个标识符,来控制数据的产生
private boolean running = true;
@Override
public void run(SourceContext<SensorReading> sourceContext) throws Exception {
Random random = new Random();
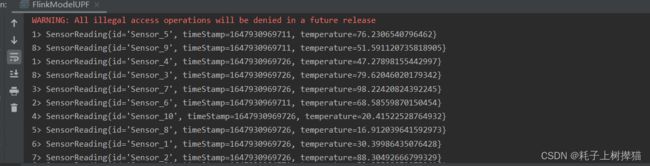
//设置十个Sensor的初始温度
HashMap<String, Double> sensorTempMap = new HashMap<>();
for (int i = 0; i < 10; i++) {
sensorTempMap.put("Sensor_" + (i + 1), random.nextGaussian() * 20 + 60);
}
while (running) {
for (String sensorKey : sensorTempMap.keySet()) {
Double newTemp = sensorTempMap.get(sensorKey) + random.nextGaussian();
sensorTempMap.put(sensorKey, newTemp);
sourceContext.collect(new SensorReading(sensorKey, System.currentTimeMillis(), newTemp));
}
Thread.sleep(5000);
}
}
@Override
public void cancel() {
running = false;
}
}
}
输出结果:
2.5 从kafka中获取数据
在flink官网是看到,flink本身是对kafka做了集成的,这样以便于我们更加方便快捷的使用kafka作为Source进行使用:

需要注意的是我们在使用一种连接器时,通常需要额外的第三方组件
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.14.4version>
dependency>
在flink中使用kafka,kafka本身提供了一个builder类来构建KafkaSource的实例。
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("flink-test")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
Bootstrap servers,通过 setBootstrapServers(String)来配置
Kafka 源码提供了 3 种 topic-partition 订阅方式:
- 主题列表,订阅主题列表中所有分区的消息。例如:
KafkaSource.builder().setTopics("topic-a", "topic-b")
- 主题模式,从名称与提供的正则表达式匹配的所有主题订阅消息。例如:
KafkaSource.builder().setTopicPattern("topic.*")
- 分区集,订阅提供的分区集中的分区。例如:
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(
new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a"
new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b"
KafkaSource.builder().setPartitions(partitionSet)
Deserializer
解析 Kafka 消息需要一个反序列化器。Deserializer(反序列化模式)可以通过配置setDeserializer(KafkaRecordDeserializationSchema),其中KafkaRecordDeserializationSchema定义了如何反序列化一个 Kafka ConsumerRecord。
如果只需要 Kafka ConsumerRecord的值,可以使用 setValueOnlyDeserializer(DeserializationSchema)在 builder 中使用,其中DeserializationSchema定义了如何反序列化 Kafka 消息值的二进制文件。
你还可以使用 Kafka Deserializer 来反序列化 Kafka 消息值. 例如使用 StringDeserializer 将 Kafka 消息值反序列化为字符串:
import org.apache.kafka.common.serialization.StringDeserializer;
KafkaSource.<String>builder()
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringSerializer.class));
2.6 使用http请求获取数据
在一些特定情况下,数据需要使用通过http请求进行获取,但是flink自身并没有像整合kafka那样对http进行整合,所以这就需要我们去手动实现。在上面我们有提到过,kafka提供了自定义数据源的方式,即继承RichSourceFunction类就可以,示例如下
public class HttpSource extends RichSourceFunction<String> {
private volatile boolean isRunning = true;
private String url;
private long requestInterval;
public HttpSource(String url, long requestInterval) {
this.url = url;
this.requestInterval = requestInterval;
}
@Override
public void run(SourceContext ctx) throws Exception {
while (isRunning) {
try {
Map<String, String> headers = new HashMap<>();
headers.put("Content-Type", "application/x-www-form-urlencoded");
HttpResult httpResult = HttpUtil.exec(HttpUtil.GET, url, headers, null);
if (httpResult.getStatusCode() == 200) {
String result = httpResult.getResult();
ctx.collect(sceneSources);
}
Thread.sleep(requestInterval);
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Override
public void cancel() {
isRunning = false;
}
}
main方法使用该source
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> dataStreamSource = env.addSource(new HttpSource("http://localhost:8080/test", 10l));
dataStreamSource.print();
env.execute();
}
}
可以看到,我们通过继承RichSourceFunction类,实现其run方法,就可以达到自定义源的一个效果。
但是需要说明的是,RichSourceFunction中的run方法是在主程序启动时才会进行执行,当run方法执行完成,splitEnumerator会使用 NoMoreSplits 来响应sourceReader,表示数据已经获取完毕,那么后续这个run方法将不会再执行,除非主程序重新启动。
所以为了达到间隔获取的目的,我们在run方法中添加了while循环,使run方法一直不会结束,那这样就达到了我们的目的,可以通过线程睡眠降低http请求的频率。
http工具可以使用httpClient或者OKHttp
附加:对自定义源做定时
以上面的示例为例,将调http请求的方式由频率调用改为定点调用
public class TimerHttpSource extends RichSourceFunction<CameraSource> {
private Boolean isRunning = false;
private static final Logger logger = LoggerFactory.getLogger(TimerHttpSource.class);
private static final long PERIOD_DAY = 24 * 60 * 60 * 1000;
private static final String url = "http://localhost:7798/msg/camera";
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
Calendar calendar = Calendar.getInstance();
calendar.set(Calendar.HOUR_OF_DAY, 1); //凌晨1点
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
Date date = calendar.getTime(); //第一次执行定时任务的时间
//如果第一次执行定时任务的时间 小于当前的时间
//此时要在 第一次执行定时任务的时间加一天,以便此任务在下个时间点执行。如果不加一天,任务会立即执行。
if (date.before(new Date())) {
date = this.addDay(date, 1);
}
Timer timer = new Timer();
//安排指定的任务在指定的时间开始进行重复的固定延迟执行。
// timer.schedule(new TimerTask() {
// @Override
// public void run() {
// isRunning = true;
// logger.info("定时任务执行了。。。。。");
// }
// }, date, PERIOD_DAY);
timer.schedule(new TimerTask() {
@Override
public void run() {
isRunning = true;
logger.info("---->>>> 定时任务执行了。。。。。");
}
}, 0l, 60000l);
}
@Override
public void run(SourceContext<CameraSource> ctx) throws Exception {
while (true) {
if (isRunning) {
try {
Map<String, String> headers = new HashMap<>();
headers.put("Content-Type", "application/x-www-form-urlencoded");
HttpResult httpResult = HttpUtil.exec(HttpUtil.GET, url, headers, null);
if (httpResult.getStatusCode() == 200) {
String result = httpResult.getResult();
ctx.collect(result);
}
isRunning = false;
} catch (Exception e) {
e.printStackTrace();
}
}
Thread.sleep(1000l);
}
}
@Override
public void cancel() {
}
// 增加或减少天数
public Date addDay(Date date, int num) {
Calendar startDT = Calendar.getInstance();
startDT.setTime(date);
startDT.add(Calendar.DAY_OF_MONTH, num);
return startDT.getTime();
}
}
这里我们实现了RichSourceFunction的open方法,在程序启动时会先执行open方法,那么我们就可以在open方法中去书写定时逻辑,通过isRunning字段去控制请求方法的执行。
3、transformation
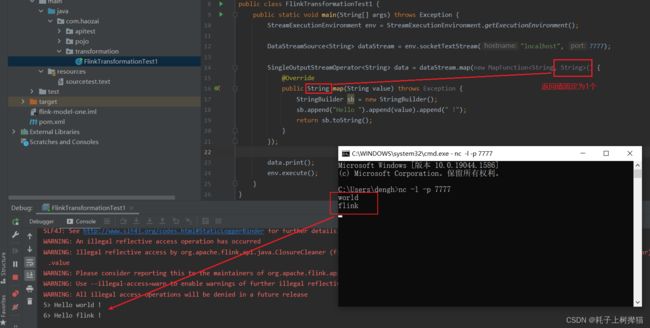
map()
接收一个元素并返回一个元素。就是接收一个元素,然后将这个元素做中间操作后,返回的元素个数也为一个
SingleOutputStreamOperator<String> data = dataStream.map(new MapFunction<String, Object>() {
@Override
public Object map(String value) throws Exception {
return null;
}
});
//简易写法
SingleOutputStreamOperator<String> data = dataStream.map((value)->{return null;})
测试:
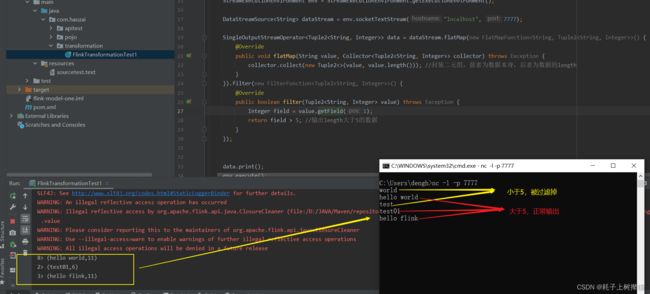
flatMap()
接收一个元素并生成零个,一个或多个元素。接收一个元素,然后将这个元素做中间操作后,返回的元素个数为一个或者多个,他是使用collect()来收集中间操作产生的元素,中间操作结束后将collect()收集到的元素集做返回
SingleOutputStreamOperator<Object> data = dataStream.flatMap(new FlatMapFunction<String, Object>() {
@Override
public void flatMap(String s, Collector<Object> collector) throws Exception {
}
});
测试:

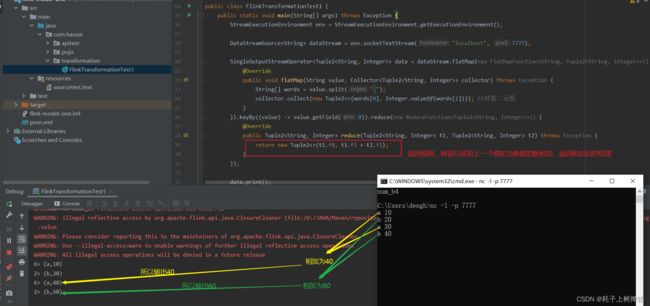
keyBy()
keyby是根据key的hashcode对分区数取模,用于流处理,就是说,在一个算子中如果使用了keyBy,那么在并行执行时,会根据keyBy设定的Key进行分区,假设1分区分配的是名为test的key,那么后续来以test为key的数据,都会被分配到1分区进行处理

Filter()
该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出,将不符合条件的数据过滤掉.
reduce()
该算子和MapReduce中Reduce原理基本一致,主要目的是将输入的KeyedStream通过传入的用户自定义地ReduceFunction 滚动地进行数据聚合处理,其中定义ReduceFunction必须满足运算结合律和交换律,
aggregations()
aggregations 只能操作元组
Aggregations是KeyedDataStream接口提供的聚合算子,根据指定的字段进行聚合操作,滚动地产生一系列数据聚合结果.其实是将Reduce算子中的函数进行了封装,封装的聚合操作有sum、min、minBy、max、maxBy等,这样就不需要用户自己定义
sum : 求和

min 和 max
min 其作用是返回当前数据选定的某个字段中的最小值
max 其作用是返回当前数据选定的某个字段中的最大值

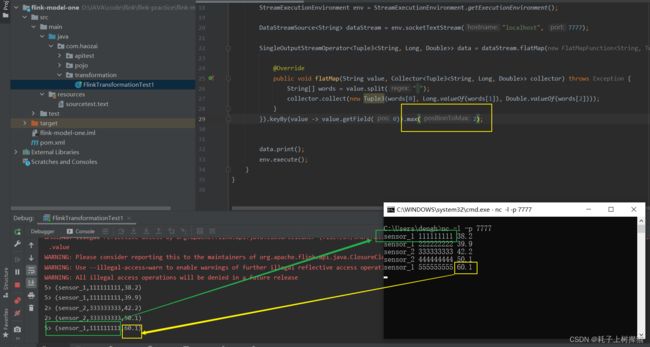
可以看到,我们无论是使用min还是使用max返回数据中的最小(大)值时,他返回的数据只是修改了判断值的那个字段,其他字段并没有进行修改,假设第二个值是时间,那么我们永远只会得到一个固定时间值,而无法判断最小(大)值是在哪个时间产生的。
minBy 和 maxBy
minBy 其作用是以数据中某个字段为依据,返回该字段值最小的整条数据
maxBy 其作用是以数据中某个字段为依据,返回该字段值最大的整条数据
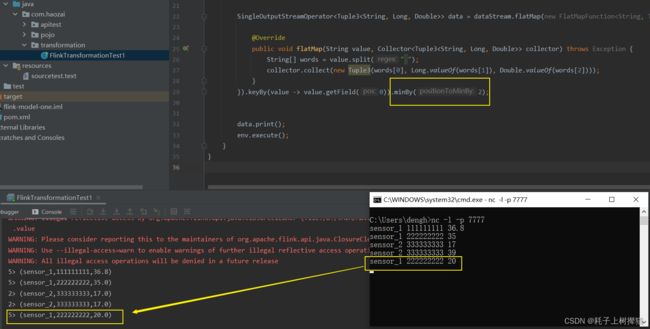
和min、max的区别在与,使用minBy/maxBy返回的数据是整条数据,而不是只是其中的某一个字段值修改后的数据。
connect() 和 coMap()
connect :连接两个保持他们类型的数据流,两个数据流被connect之后,只是被放在了同一个流中,内部依然保持各自的数据和形式,不发生任何改变,两个流相互独立
coMap :作用于ConnectedStreams上,功能于map和flatMap一样,对ConnectedStream中的每一个Stream分别进行map和flatMap处理
JavaCode
public class FlinkTransformationTest1 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataStream = env.socketTextStream("localhost", 7777);
SingleOutputStreamOperator<Tuple3<String, Long, Double>> data1 = dataStream.flatMap(new FlatMapFunction<String, Tuple3<String, Long, Double>>() {
@Override
public void flatMap(String s, Collector<Tuple3<String, Long, Double>> collector) throws Exception {
String[] words = s.split(" ");
collector.collect(new Tuple3<>(words[0], Long.valueOf(words[1]), Double.valueOf(words[2])));
}
});
DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<Tuple2<String, Double>> data2 = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Double>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Double>> collector) throws Exception {
String[] words = s.split(" ");
collector.collect(new Tuple2<>(words[0], Double.valueOf(words[1])));
}
});
ConnectedStreams<Tuple3<String, Long, Double>, Tuple2<String, Double>> connect1 = data1.connect(data2);
SingleOutputStreamOperator<Object> data3 = connect1.flatMap(new CoFlatMapFunction<Tuple3<String, Long, Double>, Tuple2<String, Double>, Object>() {
@Override
public void flatMap1(Tuple3<String, Long, Double> data, Collector<Object> collector) throws Exception {
collector.collect(new Tuple3<>("流1" + data.f0, data.f1, data.f2));
}
@Override
public void flatMap2(Tuple2<String, Double> data, Collector<Object> collector) throws Exception {
collector.collect(new Tuple2<>("流2" + data.f0, data.f1));
}
});
data3.print();
env.execute();
}
}
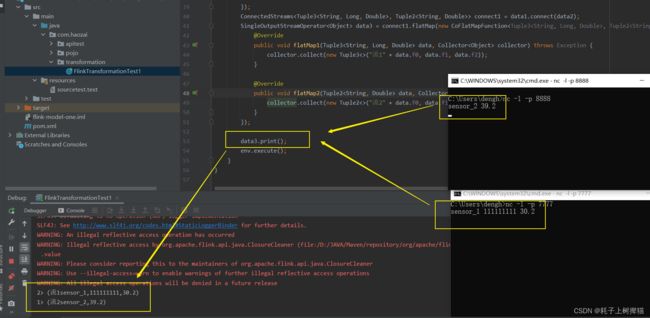
可以看到,两个数据类型不一样的数据,被connect放到同一个流里以后,是可以正常输出的,并且任然保持被connect之前的数据格式
4、sink
Flink对外输出的操作都需要利用Sink完成。最后通过类似如下方式完成整个任务最终输出操作。
stream.addSink( new MySink(xxxxx) )
官方提供了一部分的框架的sink,初次之外用户也可以自定义实现sink

