复盘《网络IO到多路复用 》之路
复盘《网络IO到多路复用 》之路
- 一、什么是BIO和NIO?
-
- 1.1 BIO
- 1.2 NIO
- 二、内核空间与用户空间
-
- 概念
- 进程缓冲区
- 内核缓冲区
- 三、IO多路复用
-
- 3.1 select
- 3.2 poll
- 四、实践 Socket / IO
-
- 4.1 当我们建立一个文件时,我们如何来操作一个已经打开文件呢?
- 4.2 nc
-
- 安装 nc
- Chat Server 建立监听
- Client
- 4.3 strace
-
- 4.3.1 追踪nc
- 4.3.2 socket
- 4.3.3 select()
- 4.3.4 close()
- 4.3.5 accept ()
- 4.4 程序通过内核完成通信时发什么啥事?
-
- 4.4.1 hello world
- 4.4.2 socket 案例
- 4.4.3 小结
- 4.5 epoll 应用场景
- 五、参考
一、什么是BIO和NIO?
首先阐述同步与异步,阻塞与非阻塞的区别
- 同步:一个任务的完成之前不能做其他操作,必须等待(等于在打电话)
- 异步:一个任务的完成之前,可以进行其他操作(等于在聊QQ)
- 阻塞:是相对于CPU来说的, 挂起当前线程,不能做其他操作只能等待
- 非阻塞: 无须挂起当前线程,可以去执行其他操作
1.1 BIO
BIO:同步阻塞式IO,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。
先看一段Java代码~
ServerSocket server = new ServerSocket(8199);
System.out.println("step1: new ServerSocket(80) ");
while (true) {
Socket client = server.accept();
System.out.println("step2:client\t" + client.getPort());
new Thread(() -> {
try {
InputStream in = client.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
while (true) {
System.out.println(reader.readLine());
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
while循环中服务端会调用accept方法等待接收客户端的连接请求,一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成。
为了BIO能同时处理多个客户端请求,为每一个链接请求都创建一个新的线程去执行 (new Thread()),即每次accept阻塞等待来自客户端请求,一旦受到连接请求就建立通信套接字同时开启一个新的线程来处理这个套接字的数据读写请求,然后立刻又继续accept等待其他客户端连接请求,如下图。
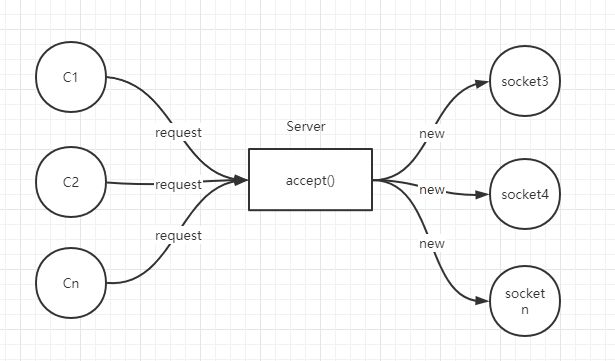
思考一样这样会出现什么问题?
每个请求都要开启一个线程,好比外卖,为每一个下单的用户配一个外卖小哥~这显然开销太大了,初期内存就是金钱呀(当请求过多的时候,线程越来越多,jvm内存被大量占用,线程是Java虚拟机宝贵资源,线程数膨胀后,系统性能下降,线程并发访问量继续增大,会导致进程宕机或僵死),当然线程池也能改善那么一丢丢哈; 知道了多线程的问题就好办了,随之而来就是NIO。

1.2 NIO
NIO:同步非阻塞,服务器实现一个连接一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理,利用单线程轮询事件,高效定位就绪的Channel来决定做什么,只是Select阶段是阻塞式的,能有效避免大量连接数时,频繁线程的切换带来的性能或各种问题。
一段NIO的代码,大概就可以写成这个样子。
struct timespec sleep_interval{.tv_sec = 0, .tv_nsec = 1000};
ssize_t nbytes;
while (1) {
/* 尝试读取 */
if ((nbytes = read(fd, buf, sizeof(buf))) < 0) {
if (errno == EAGAIN) { // 没数据到
perror("nothing can be read");
} else {
perror("fatal error");
exit(EXIT_FAILURE);
}
} else { // 有数据
process_data(buf, nbytes);
}
// 处理其他事情,做完了就等一会,再尝试
nanosleep(sleep_interval, NULL);
}
这段代码就是轮询,不断的尝试有无数据到达,有则处理,没有(得到EWOULDBLOCK或者EAGAIN)就等一小会再试。如下图

图片来源小杰要吃蛋
但这样会带来两个新问题:
- 如果有大量文件描述符都要等,那么就得一个一个的read。这会带来大量的Context Switch(
read是系统调用,每调用一次就得在用户态和核心态切换一次) - 休息一会的时间不好把握。这里是要猜多久之后数据才能到。等待时间设的太长,程序响应延迟就过大;设的太短,就会造成过于频繁的重试,干耗CPU而已。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4之后开始支持。
要是操作系统能一口气告诉程序,哪些数据到了就好了。于是IO多路复用被搞出来解决这个问题。
二、内核空间与用户空间
上文提到了用户空间和内核空间,阐述下概念
概念
内核空间是Linux内核运行的空间,而用户空间是用户程序的运行空间,为了保证内核安全,它们之间是隔离的,即使用户的程序崩溃了,内核也不受影响。
内核空间可以执行任意命令,调用系统的一切资源,用户空间只能执行简单运算,不能直接调用系统资源(I/O,进程资源,内存分配,外设,计时器,网络通信等),必须通过系统接口(又称 system call),才能向内核发出指令。

用户进程通过系统调用访问系统资源的时候,需要切换到内核态,而这对应一些特殊的堆栈和内存环境,必须在系统调用前建立好。而在系统调用结束后,cpu会从内核态切回到用户态,而堆栈又必须恢复成用户进程的上下文。而这种切换就会有大量的耗时。
进程缓冲区
一般程序在读取文件的时候先申请一块内存数组,称为buffer,然后每次调用read,读取设定字节长度的数据,写入buffer。(用较小的次数填满buffer)。之后的程序都是从buffer中获取数据,当buffer使用完后,在进行下一次调用,填充buffer。这里的buffer我们称为用户缓冲区,它的目的是为了减少频繁I/O操作而引起频繁的系统调用,从而降低操作系统在用户态与核心态切换所耗费的时间。
内核缓冲区
除了在进程中设计缓冲区,内核也有自己的缓冲区。
当一个用户进程要从磁盘读取数据时,内核一般不直接读磁盘,而是将内核缓冲区中的数据复制到进程缓冲区中。
但若是内核缓冲区中没有数据,内核会把对数据块的请求,加入到请求队列,然后把进程挂起,为其它进程提供服务。
等到数据已经读取到内核缓冲区时,把内核缓冲区中的数据读取到用户进程中,才会通知进程,当然不同的io模型,在调度和使用内核缓冲区的方式上有所不同。
你可以认为,read是把数据从内核缓冲区复制到进程缓冲区。write是把进程缓冲区复制到内核缓冲区。
当然,write并不一定导致内核的写动作,比如os可能会把内核缓冲区的数据积累到一定量后,再一次写入。这也就是为什么断电有时会导致数据丢失。
所以,我们进行IO操作的请求过程如下:用户进程发起请求(调用系统函数),内核接收到请求后(进程会从用户态切换到内核态),从I/O设备中获取数据到内核buffer中,再将内核buffer中的数据copy到用户进程的地址空间,该用户进程获取到数据后再响应客户端。
三、IO多路复用
IO多路复用(IO Multiplexing) 是这么一种机制:程序注册一组socket文件描述符给操作系统,表示“我要监视这些fd是否有IO事件发生,有了就告诉程序处理”。
IO多路复用是要和NIO一起使用的。尽管在操作系统级别,NIO和IO多路复用是两个相对独立的事情。NIO仅仅是指IO API总是能立刻返回,不会被Blocking;而IO多路复用仅仅是操作系统提供的一种便利的通知机制。操作系统并不会强制这俩必须得一起用——你可以用NIO,但不用IO多路复用,就像上一节中的代码;也可以只用IO多路复用 + BIO,这时效果还是当前线程被卡住。但是,IO多路复用和NIO是要配合一起使用才有实际意义。因此,在使用IO多路复用之前,请总是先把fd设为O_NONBLOCK。
对IO多路复用,还存在一些常见的误解,比如:
-
❌IO多路复用是指多个数据流共享同一个Socket。其实IO多路复用说的是多个Socket,只不过操作系统是一起监听他们的事件而已。
多个数据流共享同一个TCP连接的场景的确是有,比如Http2 Multiplexing就是指Http2通讯中中多个逻辑的数据流共享同一个TCP连接。但这与IO多路复用是完全不同的问题。
-
❌IO多路复用是NIO,所以总是不Block的。其实IO多路复用的关键API调用(
select,poll,epoll_wait)总是Block的,正如下文的例子所讲。 -
❌IO多路复用和NIO一起减少了IO。实际上,IO本身(网络数据的收发)无论用不用IO多路复用和NIO,都没有变化。请求的数据该是多少还是多少;网络上该传输多少数据还是多少数据。IO多路复用和NIO一起仅仅是解决了调度的问题,避免CPU在这个过程中的浪费,使系统的瓶颈更容易触达到网络带宽,而非CPU或者内存。要提高IO吞吐,还是提高硬件的容量(例如,用支持更大带宽的网线、网卡和交换机)和依靠并发传输(例如HDFS的数据多副本并发传输)。
与多进程和多线程技术相比,
I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
3.1 select
select长这样:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
它接受3个文件描述符的数组,分别监听读取(readfds),写入(writefds)和异常(expectfds)事件。那么一个 IO多路复用的代码大概是这样:
struct timeval tv = {.tv_sec = 1, .tv_usec = 0};
ssize_t nbytes;
while(1) {
FD_ZERO(&read_fds);
setnonblocking(fd1);
setnonblocking(fd2);
FD_SET(fd1, &read_fds);
FD_SET(fd2, &read_fds);
// 把要监听的fd拼到一个数组里,而且每次循环都得重来一次...
if (select(FD_SETSIZE, &read_fds, NULL, NULL, &tv) < 0) { // block住,直到有事件到达
perror("select出错了");
exit(EXIT_FAILURE);
}
for (int i = 0; i < FD_SETSIZE; i++) {
if (FD_ISSET(i, &read_fds)) {
/* 检测到第[i]个读取fd已经收到了,这里假设buf总是大于到达的数据,所以可以一次read完 */
if ((nbytes = read(i, buf, sizeof(buf))) >= 0) {
process_data(nbytes, buf);
} else {
perror("读取出错了");
exit(EXIT_FAILURE);
}
}
}
}
首先,为了select需要构造一个fd数组(这里为了简化,没有构造要监听写入和异常事件的fd数组)。之后,用select监听了read_fds中的多个socket的读取时间。调用select后,程序会Block住,直到一个事件发生了,或者等到最大1秒钟(tv定义了这个时间长度)就返回。之后,需要遍历所有注册的fd,挨个检查哪个fd有事件到达(FD_ISSET返回true)。如果是,就说明数据已经到达了,可以读取fd了。读取后就可以进行数据的处理。
select有一些发指的缺点:
select能够支持的最大的fd数组的长度是1024。这对要处理高并发的web服务器是不可接受的。- fd数组按照监听的事件分为了3个数组,为了这3个数组要分配3段内存去构造,而且每次调用
select前都要重设它们(因为select会改这3个数组);调用select后,这3数组要从用户态复制一份到内核态;事件到达后,要遍历这3数组。很不爽。 select返回后要挨个遍历fd,找到被“SET”的那些进行处理。这样比较低效。select是无状态的,即每次调用select,内核都要重新检查所有被注册的fd的状态。select返回后,这些状态就被返回了,内核不会记住它们;到了下一次调用,内核依然要重新检查一遍。于是查询的效率很低。
3.2 poll
poll与select类似于。它大概长这样:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
poll的代码例子和select差不多,因此也就不赘述了。有意思的是poll这个单词的意思是“轮询”,所以很多中文资料都会提到对IO进行“轮询”。
上面说的select和下文说的epoll本质上都是轮询。
poll优化了select的一些问题。比如不再有3个数组,而是1个polldfd结构的数组了,并且也不需要每次重设了。数组的个数也没有了1024的限制。但其他的问题依旧:
- 依然是无状态的,性能的问题与
select差不多一样; - 应用程序仍然无法很方便的拿到那些“有事件发生的fd“,还是需要遍历所有注册的fd。
目前来看,高性能的web服务器都不会使用select和poll。他们俩存在的意义仅仅是“兼容性”,因为很多操作系统都实现了这两个系统调用。
如果是追求性能的话,在BSD/macOS上提供了kqueue api;在Salorias中提供了/dev/poll(可惜该操作系统已经凉凉);而在Linux上提供了epoll api。它们的出现彻底解决了select和poll的问题。Java NIO,nginx等在对应的平台的上都是使用这些api实现。
因为大部分情况下我会用Linux做服务器,所以下文以Linux epoll为例子来解释多路复用是怎么工作的。
四、实践 Socket / IO
在linux开发过程中,相信大家都听过一句话叫作“limux下,一切皆文件”, “文件”不仅仅是我们通常所指的文件,在linux和unix中它代表的更为宽泛。目录、字符设备、块设备、 套接字、进程、线程、管道等都被视为是一个“文件”。
4.1 当我们建立一个文件时,我们如何来操作一个已经打开文件呢?
通过文件描述符(file descriptor),简称fd,它是一个对应某个已经打开的文件的索引(非负整数)
案例1: 重定向到百度首页
exec 8<> /dev/tcp/www.baidu.com/80
cd /proc/$$/fd
//指向百度,开启一个socket
8<> : 重定向 ,8 为文件描述符(java对象的引用) <>: 输入输出两个六流
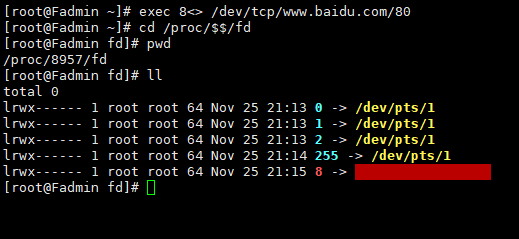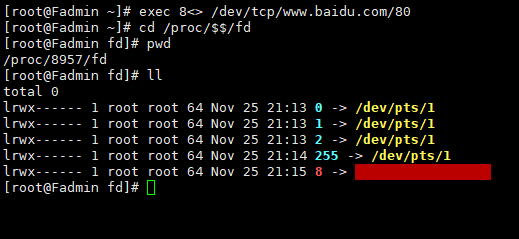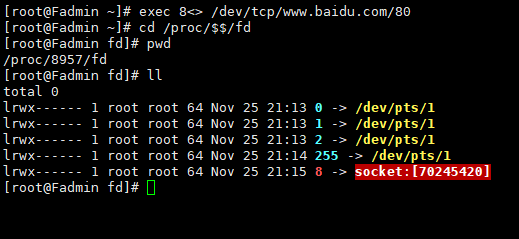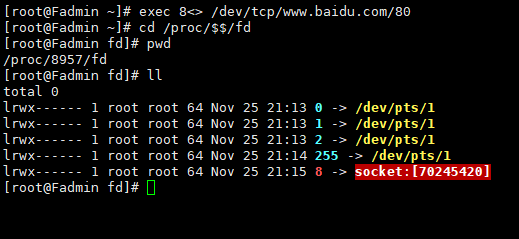
其中 0 1 2是程序标准的输入、标准输出、和错误输出, 8就是一个socket。
文件描述符: 0,1,2
进程id: $$ 20220
/proc/ / f d 文 件 描 述 符 ( f d 目 录 下 的 进 程 ( /fd 文件描述符(fd目录下的进程( /fd文件描述符(fd目录下的进程()存在哪些描述符)
建立TCP Socket连接
exec 6<> /dev/tcp/www.baidu.com/80
1重定向到 6,指向的是一个文件描述符而不是一个文件的话, 加一个符号&, 就是让echo的标准输出重定向到8的变量指定的socket而不是屏幕,执行后查看输出
echo -e 'GET / HTTP/1.0\n' 1>& 6
cat 0<& 6
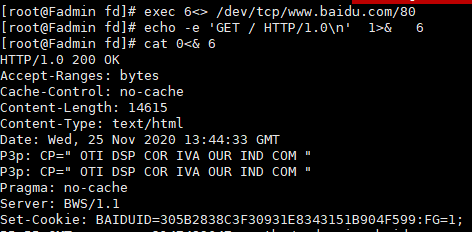
┏ (゜ω゜)=☞
*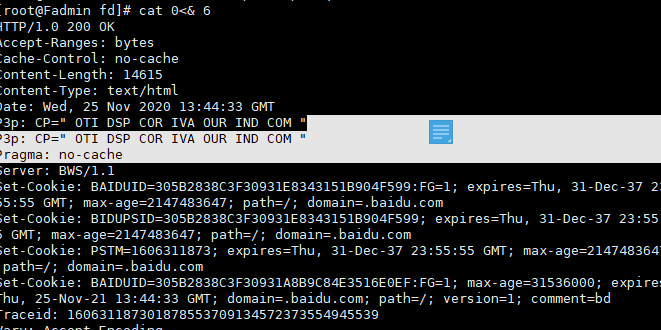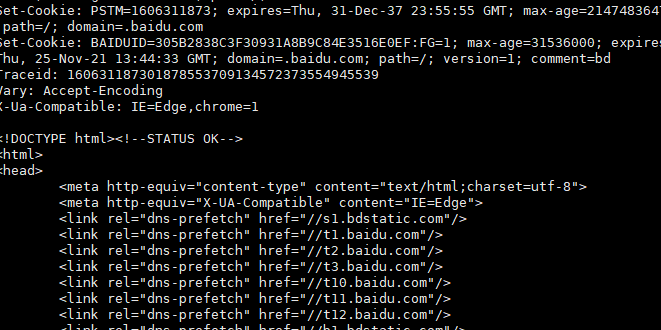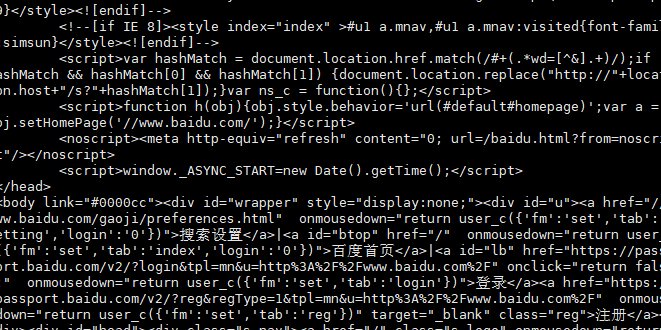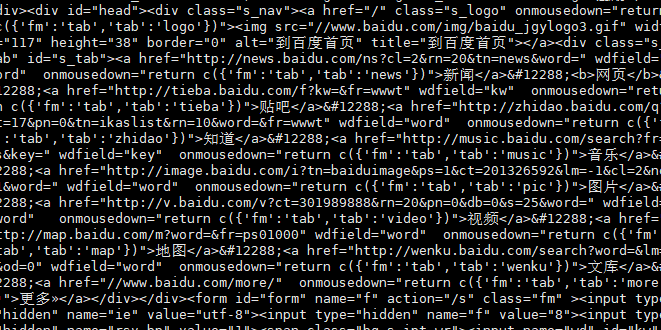
之前先建立了8, 这此又建立了6, 下图可以看到已经建立了两个socket连接
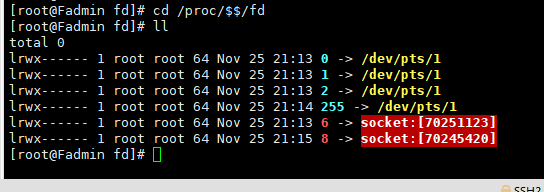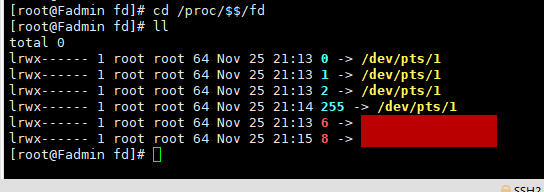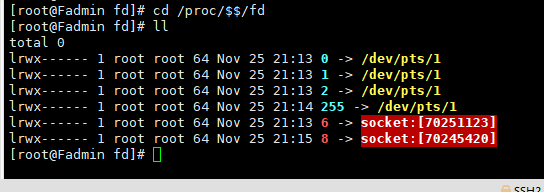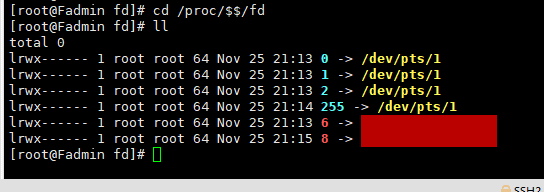
这边scoket又扯到老生常谈的TCP了☞ 面试官求你不要再问我TCP的3次握手和4次分手了好吗
4.2 nc
nc 不是脑残 而是☞ NetCat, 网络工具中的瑞士军刀。
NetCat: 它能通过TCP和UDP在网络中读写数据。通过与其他工具结合和重定向,你可以在脚本中以多种方式使用它。使用netcat命令所能完成的事情令人惊讶。
netcat所做的就是在两台电脑之间建立链接并返回两个数据流(自由传输数据),在这之后所能做的事就看你的想像力了。你能建立一个服务器,传输文件,与朋友聊天,传输流媒体或者用它作为其它协议的独立客户端。
-
安装 nc
yum install nc
-
Chat Server 建立监听
假如你想和你的朋友聊聊,有很多的软件和信息服务可以供你使用。但是,如果你没有这么奢侈的配置,比如你在计算机实验室,所有的对外的连接都是被限制的,你怎样和整天坐在隔壁房间的朋友沟通那?不要郁闷了,netcat提供了这样一种方法,你只需要创建一个Chat服务器,一个预先确定好的端口,这样子他就可以联系到你了。
Server
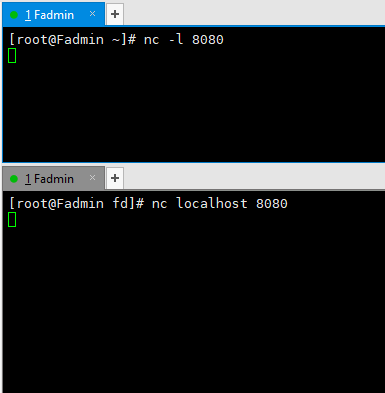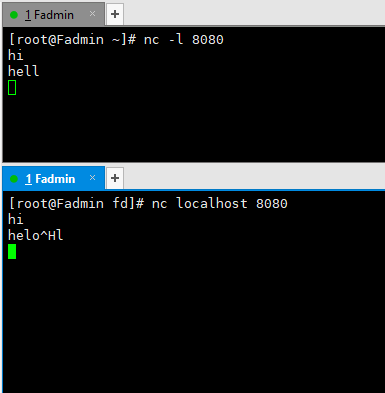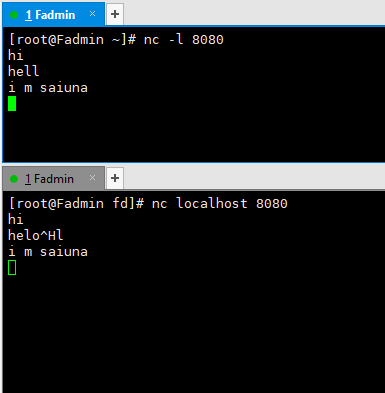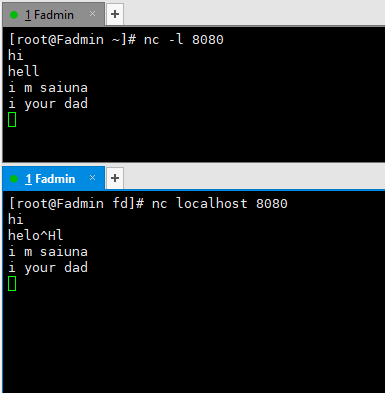
nc -l 8080
netcat 命令在8080端口启动了一个tcp 服务器,所有的标准输出和输入会输出到该端口。输出和输入都在此shell中展示。
-
Client
nc localhost 8080
不管你在机器B上键入什么都会出现在机器A上。
//查看nc 进程
ps -fe | grep nc
结果, 进程编号为 15352

回顾 /proc/$$/fd
根据上文15352 进入进程的命令 ,此时换成进程即可查看nc的文件描述符 如下
cd /proc/$$/fd >> cd /proc/15352/fd
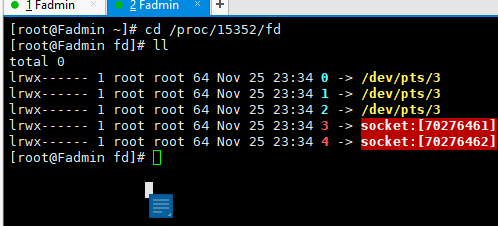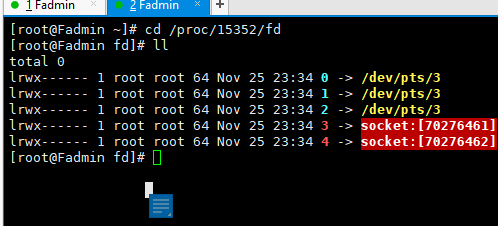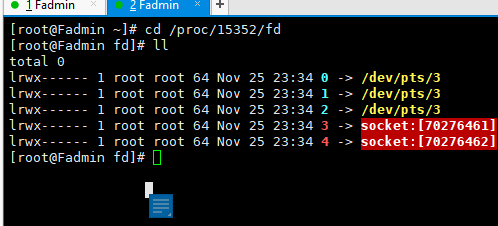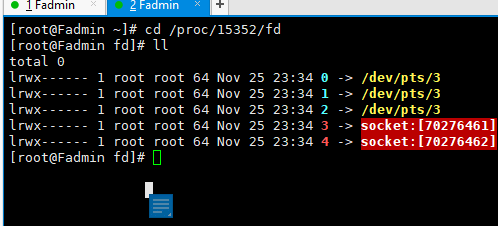
疑问点? 为何此时还有 两个socket(3,4, 之前聊天玩的,但是未关掉);
关闭即可 : exec 3<&- exec 4<&-
4.3 strace
//安装
yum install strace
strace :跟踪进程执行时的系统调用和所接收的信号。 在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通 过系统调用访问硬件设备。
strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
4.3.1 追踪nc
//ff 抓取后续命令所有的进程/线程的 对内核的调用 -o out 输出的东西 记录到一个文件里
strace -ff -o out nc -l 8080

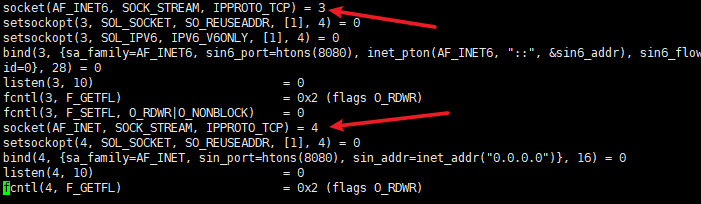
4.3.2 socket
man socket
RETURN VALUE
On success, a file descriptor for the new socket is returned. On error, -1 is returned, and errno
is set appropriately.
此时 文件描述符为: 3 , 4 ,对应上文图片 , 感jio打通了任督二脉

此刻strace 生成的out.进程编号 的文件不再生成数据,因为此前nc只是开启了,并未进行连接(nc localhost 8080),所以没有发生额外的系统调用。
看一哈简单的案例 > man socket
#include 建立连接并通话
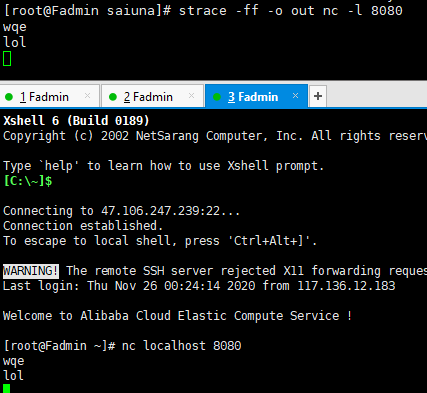
tail -f out.17363 让我看看你们在偷偷的交流什么

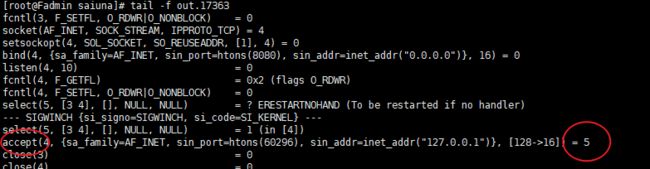
4.3.3 select()
DESCRIPTION
select() and pselect() allow a program to monitor multiple file descriptors, waiting until one or more of the
file descriptors become “ready” for some class of I/O operation (e.g., input possible).
一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作
4.3.4 close()
图中最后两行 close(3) =0, close(4) =0
RETURN VALUE
close() returns zero on success. On error, -1 is returned, and errno is set appropriately.
嗯哼,这不成功关闭了变量3,4的socket的文件描述符嘛
4.3.5 accept ()
man accept 查看accept的手册
RETURN VALUE
On success, these system calls return a nonnegative integer that is a descriptor for the accepted socket. On error, -1 is returned, and errno is set appropriately成功后,这些系统调用将返回非负整数,该整数是已接受套接字的描述符。 错误时,返回-1,并正确设置errno
再回头看看nc的文件描述符,发现3,4 没了,取而代之的则是5,


4.4 程序通过内核完成通信时发什么啥事?
计算机中nc 或tomcat,或其他程序, 被动中我们接受到了一些知识, ☞ system call (系统调用)而这些方法来则于kernel,系统调用由内核完成
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-16qkLyRs-1607245756703)(C:\Users\adminstraor\AppData\Roaming\Typora\typora-user-images\image-20201126204828919.png)]
API : application interface
4.4.1 hello world
-
先编写hellow world程序

-
追踪程序
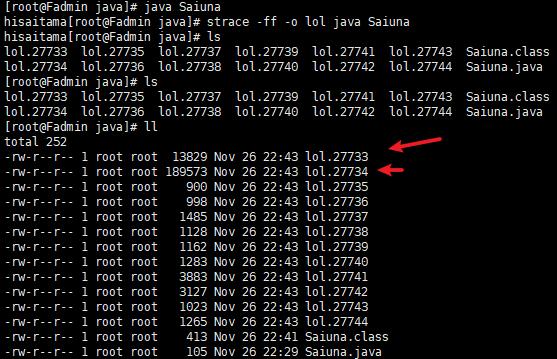
、
查看第一个vi lol.27733

-
clone
克隆创建了一个子线程, 为27734.
-
搜输出
rep "saitama" ./* // 搜索当前文件下的所有内容
-
线程的是调用
内核的clone()方法涉及(JVM 的堆栈, 线程栈:私有, 堆:共享…)
4.4.2 socket 案例
回到最初的起点,追踪下文中最开头的案例
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
public class TestSocket {
public static void main(String[] args) throws Exception {
ServerSocket server = new ServerSocket(8199);
System.out.println("step1: new ServerSocket(80) ");
while (true) {
Socket client = server.accept();
System.out.println("step2:client\t" + client.getPort());
new Thread(() -> {
try {
InputStream in = client.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
while (true) {
System.out.println(reader.readLine());
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
}
- 跑程序
[root@Fadmin test]# javac TestSocket.java
[root@Fadmin test]# strace -ff -o ./outFile java TestSocket
- 获取进程 jps
[root@Fadmin fd]# jps
29251 Jps
29016 TestSocket
用于查看当前服务器中的java进程,类似于ps -ef | grep java,不同之处是它是由jdk提供的,可以输出JVM中运行的进程状态信息,因此它也可以用于jvm的监控和调优,参考JVM性能调优监控工具jps、jstack、jmap、jhat、jstat、hprof使用详解,使用时需保证一正确配置java环境变量,常用参数有:
-q:仅输出VM标识符,不包括classname,jar name,arguments in main method
-m:输出main method的参数
-l:输出完全的包名,应用主类名,jar的完全路径名
-v:输出jvm参数
-V:输出通过flag文件传递到JVM中的参数(.hotspotrc文件或-XX:Flags=所指定的文件
-Joption:传递参数到vm,例如:-J-Xms512m

- 查看strace 追踪生成的文件
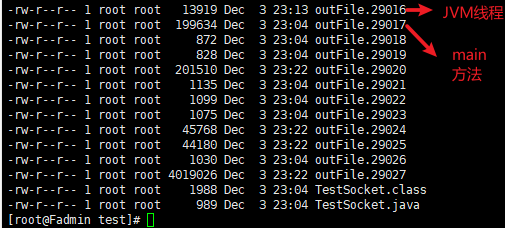
- 查看 outFile.29017
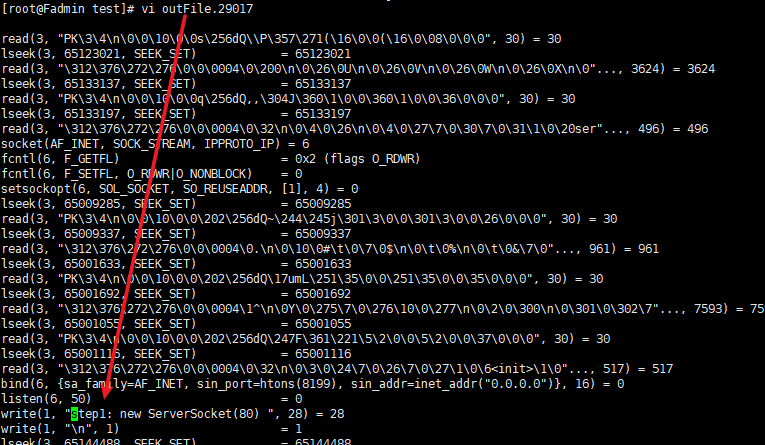
可以看到 打印数据:
socket(AF_UNIX, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3
write(1, "step1: new ServerSocket(80) ", 28) = 28
-
回头看 29016 jvm线程 都做了啥

调用了clone(), 老 sc了

- 再回头看看主线程
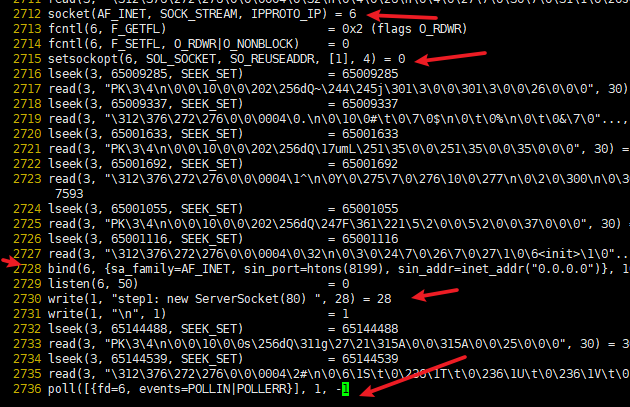
2712 socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 6
2715 setsockopt(6, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
2728 bind(6, {sa_family=AF_INET, sin_port=htons(8199), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
2729 listen(6, 50)
2736 poll([{fd=6, events=POLLIN|POLLERR}], 1, -1
- 万事俱备, 只欠客户端链接
[root@Fadmin ~]# nc localhost 8199
- 看输出:

监听到了输出,同时该进程也多了一个socket链接

同时追踪打印也不在阻塞,输出accept等…
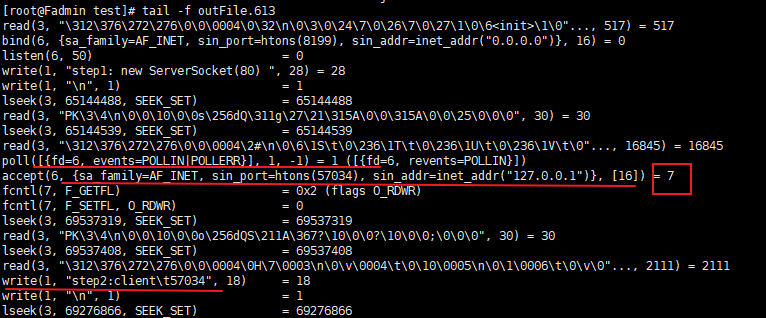

此处accept返回了一个fd = 7, 也就是 Socket client = server.accept(); ,对于java 是一个对象及属性,对于操作系统只是一个fd
到最后,clone了一个新线程732, 并进入等待 (732线程一开始并不存在,循环创建出来的(sc > clone() > strace -f -o 输出))
看下新成员732:
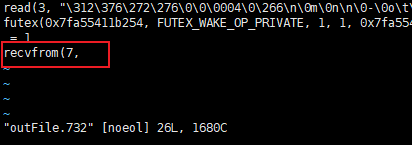
recvfrom(7,
接受来自fd:7 的请求
来自7,此时阻塞在7了,等待(监听)客户端发送请求, 此时客户端来给服务端发点东西,别人家干等了
- 服务端 收到并打印

- strace也追踪到了相关信息
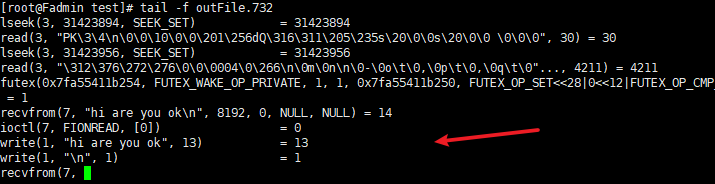
- 回顾哈 write(1, “hi are you ok”, 13) 这里的
1代表啥意思?

- 最后一个select的流程大致如下,敲完上面的再看一下流程图,一目了然。
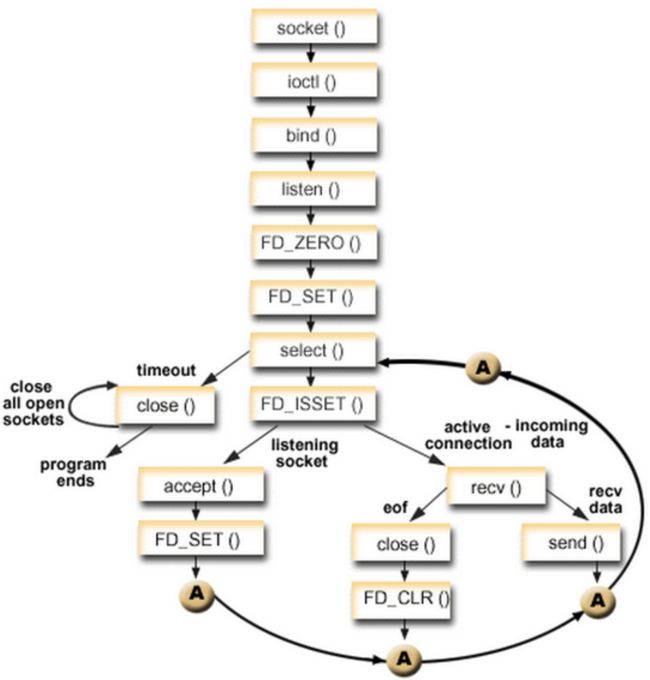
4.4.3 小结

早期, 抛多线程解决多客户端访问一台服务器的事情

存在的问题:
多线程: 容易造成堵塞
循环: 假设有1000个客户端连接, 旧的循环1000次,复杂度O(n), read ,recvfrom 999
若是只有一个,则浪费999次sc, 若这一个位置在fd1000,那么得等到999次巡查后才到fd1000,就特别拉闸
如何解决: 减少不必要的sc >> 多路复用…
4.5 epoll 应用场景
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
应用场景:
- Redis通信采用非阻塞IO,内部实现采用epoll+自己实现简单的事件框架。
- kafka,( epoll > 零拷贝 > mmap)
- Netty
- …
五、参考
BIO和NIO详解