基于Cyclone V SoC利用HLS实现卷积手写体数字识别设计
本文是基于英特尔 Cyclone V SoC 开发板,利用 HLS 技术实现三层卷积两层池化两层全连接推理运算的手写体数字识别设计
硬件环境:
Cyclone V SoC开发板
SD卡
电脑
软件环境:
Windows 11
Quartus prime 18
Eclipse DS-5
MobaXterm
i++编译环境
HLS工具
语言:
C
Verilog HDL
卷积神经网络
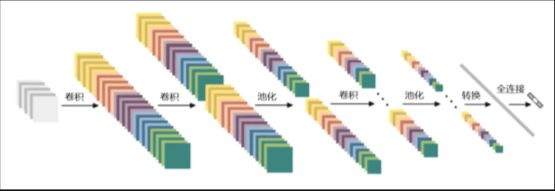
卷积神经网络(Convolutional Neural Network,CNN)是一种常用的深度学习算法,主要应用于图像处理和计算机视觉领域。CNN 在处理图像时,能够自动提取图像中的特征,并将其转化为对应的抽象表示,从而实现图像分类、物体检测、目标识别等任务


CNN 的基本结构包括卷积层、池化层和全连接层。其中,卷积层是 CNN 的核心,通过卷积操作对输入图像进行特征提取。卷积层包括多个卷积核,每个卷积核负责检测图像中的一个特定特征,如边缘、纹理等。通过卷积操作,卷积核能够对输入图像进行卷积运算,得到一个新的特征图,从而实现对输入图像的特征提取

池化层用于减小特征图的尺寸,从而降低后续层的计算量。通常采用最大池化或平均池化操作,将每个小区域内的最大值或平均值作为输出,从而实现对特征图的下采样操作
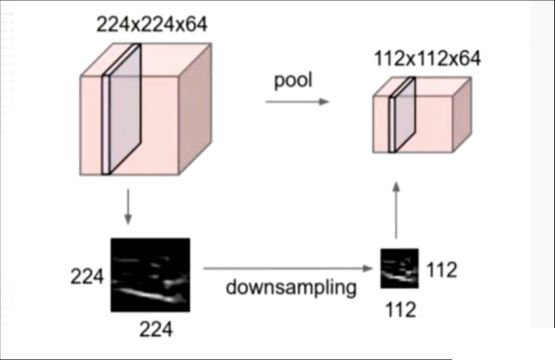
全连接层用于对特征进行分类或回归。它将卷积层和池化层输出的特征向量拉直成一个一维向量,然后通过一个全连接层进行分类或回归操作

CNN 的训练过程通常采用反向传播算法。该算法基于梯度下降优化策略,通过计算预测值和实际值之间的误差,并反向传播误差,更新模型的参数,从而提高模型的精度
总之,卷积神经网络具有自动提取特征、处理图像和计算机视觉任务等优点,已经成为图像处理和计算机视觉领域的核心技术之一
全连接神经网络
全连接神经网络是一种最基本的人工神经网络模型,也被称为多层感知机(Multilayer Perceptron,MLP)。它由多层神经元组成,每层神经元与前一层的所有神经元相连,形成完全连接的网络结构。每个神经元接收上一层的所有神经元的输出,并产生自己的输出,同时将输出传递给下一层的所有神经元。这种全连接的结构使得神经网络能够学习输入数据中的复杂关系,并输出相应的结果

全连接神经网络通常包括输入层、隐藏层和输出层三个部分。其中输入层接受原始的输入数据,隐藏层则通过一系列线性和非线性的变换将输入数据进行特征提取和变换,输出层将变换后的特征映射到对应的目标结果上
全连接神经网络的训练过程通常使用反向传播算法(Backpropagation,BP)进行,该算法能够有效地调整网络的权重和偏置,从而最小化输出结果与实际结果之间的误差。在训练过程中,通过不断地将输入数据和目标输出数据传递给网络,神经网络能够自适应地调整自身的权重和偏置,从而使得输出结果更加接近目标结果,提高了预测的准确率

全连接神经网络在许多领域都有广泛的应用,包括图像识别、语音识别、自然语言处理、游戏AI等。同时,由于全连接神经网络的计算量较大,也在一定程度上限制了其在实际应用中的发展
HLS(高层次综合)
HLS(High-Level Synthesis)这项技术。它是一种自动化的硬件设计工具,可以将高级语言(例如 C、C++ 等)转化为 FPGA(Field-Programmable Gate Array)硬件描述语言,从而实现高效的硬件设计。HLS 技术可以大大提高硬件设计的效率和可重用性,减少了传统硬件设计所需的时间和成本。同时,HLS技术也可以提供更高的设计灵活性和可扩展性,使硬件设计更加容易


在数字图像处理和机器学习领域,HLS 技术可以用于加速卷积神经网络(CNN)等复杂算法的计算过程,从而实现更快速和高效的图像识别和处理。HLS 技术可以将卷积操作等计算密集型部分移植到FPGA中实现硬件加速,同时保持系统的高准确率。这种软硬件协同设计的方式可以有效地利用 FPGA 的并行计算能力和高度可编程性,加速数字图像处理和识别的过程
SoC FPGA
SoC FPGA(System on Chip Field Programmable Gate Array)是将 FPGA 和 SoC(System on Chip)功能集成在同一芯片上的一种集成电路。它既有 FPGA 的可编程性和灵活性,又有 SoC 的集成度和可靠性

SoC FPGA 通常由 FPGA 硬件逻辑单元、ARM 处理器、内存、高速串行接口、外设接口等部分组成。FPGA 逻辑单元可以根据应用需求进行灵活的配置和实现,可以实现不同类型的处理和计算;ARM 处理器可以提供更高的计算性能和运行多种软件应用程序的能力,同时也可以在处理器和 FPGA 之间进行数据交换和协同处理,实现软硬件协同设计;高速串行接口和外设接口可以方便地与其他外部设备进行通信和控制
项目介绍
项目框架以及数据流向

基于 SoCFPGA 的手写体识别项目,包括 FPGA 和 HPS 两大板块。
模块介绍
手写体识别算法控制模块:负责控制PL端的ACCsystem推理算法模块的操作,并向DDR3模块写入图像数据和相应的控制命令。该模块可能包括卷积神经网络(CNN)和全连接神经网络(FCN)等手写体识别算法的实现,并根据输入图像进行推理和分类,生成识别结果
由于条件有限,这里仅实现编译运行
项目文件结构
handwriting # 项目名称
└── C5MB_GHRD_Mnist/ # 黄金工程
├── C5MB_top.qpf # 用于启动quartus的GUI界面
├── C5MB_top.v # 黄金工程.v设计文件
├── hps_0.h # 封装IP生成的头文件,用来保持寄存器地址
├── soc_system.dtb # 用于烧入sd卡执行的文件
├── app/ # ps端c代码设计源文件
│ ├── MNIST_mb/ # 项目主文件
│ │ └── *.c
│ └── ...
│
├── ip/ # IP目录
│ ├── pll/ # 调用的pll源文件存放目录
│ │ └── ...
│ ├── hls/ # hls高层次综合文件
│ │ └── ...
│ ├── DVP_CAPTURE/ # HDMI输入输出IP文件
│ │ └── ...
│ └── AccSystem/ # 自己封装的算法源文件存放目录
│ └── ...
│
├── src/ # PL端的.v源文件
│ ├── i2c_master/ # I2C接口时序源文件设计
│ │ └── *.v
│ ├── *.v
│ └── ...
│
├── output_files/
│ ├── soc_system.rbf # 用于烧入sd卡执行的文件
│ └── ...
│
└── ...代码示例
全连接神经网络推理算法设计C代码示例
#include
#include "HLS/hls.h"
#include "HLS/stdio.h"
#include "HLS/hls_internal.h"
#include "HLS/math.h"
#include"input_0.h"
#include"input_1.h"
#include"input_2.h"
#include"input_3.h"
#include"input_4.h"
#include"input_5.h"
#include"input_6.h"
#include"input_7.h"
#include"input_8.h"
#include"input_9.h"
#include"layer1_bais.h"
#include"layer1_weight.h"
#include"layer2_bais.h"
#include"layer2_weight.h"
hls_avalon_slave_component
component int handwriting(hls_avalon_slave_memory_argument(784*sizeof(float))float *img,
hls_avalon_slave_memory_argument(784*64*sizeof(float))float *w1,
hls_avalon_slave_memory_argument(64*sizeof(float))float *b1,
hls_avalon_slave_memory_argument(64*10*sizeof(float))float *w2,
hls_avalon_slave_memory_argument(10*sizeof(float))float *b2)
{
//输入层第一层
int ret1;
int i,j;
float a1[64]={0.0},a2[10]={0.0};
for ( i = 0; i < 64; i++)//从什么时候开始跳
{
for ( j = 0; j < 784; j++)//跳64为拮据的次数
{
a1[i] += img[j]*w1[j*64+i];
}
a1[i] += b1[i];
//加激活函数
a1[i] = (a1[i]>0)? a1[i] : 0 ;
}
//第二层
for ( i = 0; i < 10; i++)//从什么时候开始跳
{
for ( j = 0; j < 64; j++)//跳10为拮据的次数
{
a2[i] += a1[j]*w2[j*10+i];
}
a2[i] += b2[i];
//加激活函数
//a2[i] = (a2[i]>0)? a2[i] : 0 ;
}
//判断输出识别数字
float temp=0;
for ( i = 0; i < 10; i++)
{
if (a2[i]>temp)
{
temp = a2[i];
ret1 = i;
}
}
return ret1;
}
int main()
{
int i;
float *a3[10]={input_0,input_1,input_2,input_3,input_4,input_5,input_6,input_7,input_8,input_9};
for ( i = 0; i < 10; i++)
{
int ret0 = handwriting(a3[i],layer1_weight,layer1_bais,layer2_weight,layer2_bais);
printf("input_%d.h检测结果为:%d\n",i,ret0);
}
return 0;
} 手写体数字识别设计具体实现步骤
环境搭建
进入到 quartus 的 hls 文件夹下,运行 init_hls.bat
这里如果运行失败,可以手动将以下四个路径添加到系统环境变量中:
HLSVSTOOLS:
C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin\amd64\vcvars64.bat
INTELFPGAOCLSDKROOT:
D:\quartus\18\hld
D:\quartus\18\hls\bin
D:\quartus\18\hls\windows64\bin软件部分
编译:
这里首先需要进入到我们的代码路径下
i++ -march=CycloneV text.cpp -v -ghdl添加 ip:
当我们编译成功后会生成一个名为 full_test 的文件夹

我们将这个文件夹全部放入我们的黄金工程指定里即可

打开黄金工程添加编辑 IP:

生成如下:

连线如下:

分配基地址:

最后我们点击编译生成,生成成功之后编译整个项目即可
编译时间有点长,当我们编译成功之后,我们就需要打开 EDS 工具,切换到我们黄金工程的目录下,生成设备树文件:



命令如下:
make dtb然后我们将开发板系统烧录到 SD 卡上,并替换如下两个文件:


然后我们就需要开始处理开发板部分了
手写体识别工程部分
首先我们需要打开 eclipse 打开我们已有的 c++ 工程

成功创建工程并导入代码后如下:

然后我们需要导入头文件引用路径:
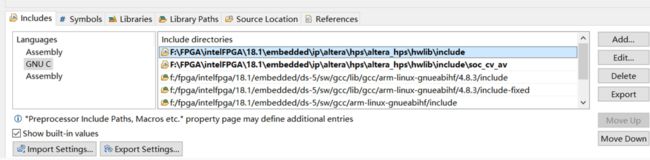
最后我们编译调试即可
开发板调试
这里我们使用 MobaXterm 连接开发板,修改网络和 SSH 设置

修改 IP:

修改 SSH 权限:

同样电脑端也需要进行 ip 修改:

我们配置好之后我们就可以 ssh 连接开发板了


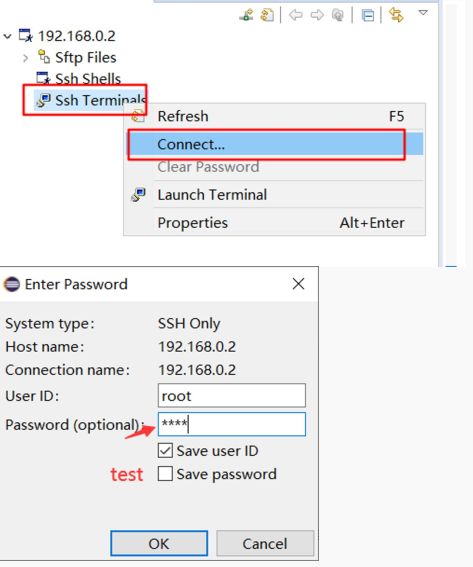
这里我们需要将我们编译成功的二进制文件传输到开发板上就可以运行了

