Just Mask and Sum 手搓 自然语言模型
背景
在这个每天都能看到,各种新LLM论文,出现的今天,大家讨论的都是如何将transformer ,或者说是将attention 进行线性化。
很少有人讨论,注意力机制是必要的吗(attention is must)? 但是证明attention 的必要性,可能超出了个人算力。
如果我们拿的出一个小的反例,是不是能证明,attention(只针对当前的LLM的实现方式的attention),是非必要的。
正文
首先明确主要任务是拿出一个反例,证明实现LLM,attention 不是唯一的途径(这里不谈rnn,lstm,或者rwkv)。
那么,开始推演:
1,要预测一个字符串【ABC】后面接的是哪个字符,且这个字符的唯一确定性,或者说是某个字符的概率大小,绝对不会是N-Gram那样的假设,只和前一个字符有关。而是和前n个字符有关,n越长是某个字符的概率越大(这里指的是前n个字符都是利好是某个字符的)。
2,实现1 的假设并不难,但是太长绝对是算力爆炸,而N-Gram为的就是省算力,而我们暂时假设,这个能够确定是某个字符的概率的序列是有限长的。
3,基于上面的两个假设,那么假设ABC 如何计算后面的字符出现的概率:实现方法
上面的实现方法已经简单的证明了假设有一定的能力,预测下一个字符,但是,基于统计的模型,无论是从模型大小还是算力上都是更大的问题。
故而要转为一个函数的形式
可以任务转化为函数的形式就是信息压缩或者,不想不断地记录,就如同已知y=ax+b 就能知道 x是任意值的时候y
的值。只要记住,少量信息,就能知道y的所有值。可是说变为函数,是一种信息压缩。而建模,则是实现信息压缩(函数化)的主要方法。
而传统的建模方法是人为的根据信息,设定几个函数方程,不断地去测试实现。
而今天人们用神经网络替代任何的函数,不断地去调整参数得到函数。
可以将神经网络看做是一个万能函数。
接下来要实现,将上面统计模型,变为万能函数,神经网络(LLM自然语言模型)。
当然我们不使用当前的任何自然语言模型,那么有以下几种方法
1,直接输入voct 预测voc 而后根据概率模型推理方法进行预测。
经过验证或者说根本没有达到验证的地步,基本就凉了,或者说,本人不太喜欢,或者是选择语言模型是当前的任何语言模型,或者说是后期推理更消耗算力,但是有一个最大的问题是这样做,同样面临的问题是大的数据量,导致算力需求爆炸。没错被发现了,个人算力的确实现不了。
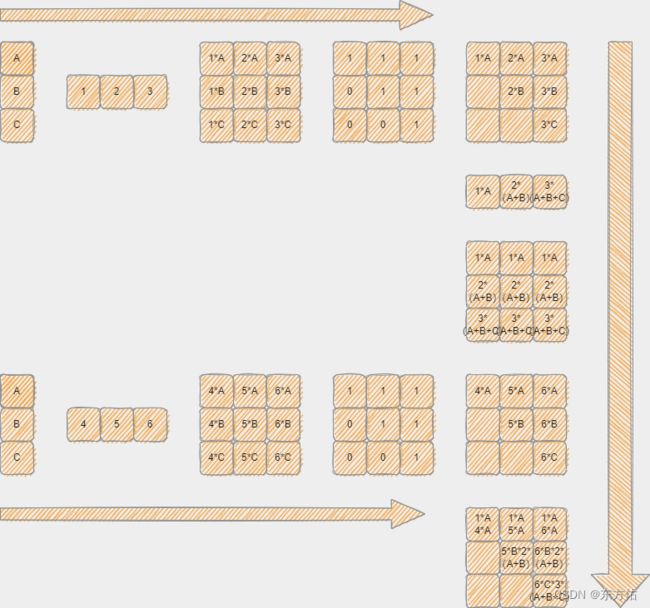
2,采取mask and sum 的方法 实现并行,具体大致如图。
import paddle
class EmMask(paddle.nn.Layer):
def __init__(self, voc_size=19, hidden_size=256, max_len=48):
super(EmMask, self).__init__()
# 定义输入序列和标签序列
self.embedding_layer = paddle.nn.Embedding(voc_size, hidden_size)
self.pos_em_layer = paddle.nn.Embedding(max_len, hidden_size)
self.pos_to_down = paddle.nn.Linear(hidden_size, 1)
self.sample_buffer_data=paddle.zeros([1])
# 定义模型计算过程
def forward(self, x):
# 将输入序列嵌入为向量表示
embedded_x = self.embedding_layer(x) # bs--->bsh
# embedded_x += paddle.fft.fft(embedded_x, axis=1).real()
# embedded_p 有权重 后期预测的时候就要参与 这样会造成计算量增加 如果使用 1 代替 减少多样性
# 但是使用pos 是 对于任何输入是固定的可以事先弄好的可以事先计算,一个固定的w 而已
# 而当前的attention 这个参数是动态的,要通过其他方法来实现动态的 比如scale 多头等
# 当前这种方式全靠 开头和结尾 中间固定参数哦 如果使用多个 加上softmax 那么就能完成多头scale 的操作了
embedded_p = self.pos_em_layer(paddle.arange(1, x.shape[1] + 1).astype("int64"))
embedded_p = self.pos_to_down(embedded_p)
xp = embedded_x.transpose([0, 2, 1]).unsqueeze(3) @ embedded_p.transpose([1, 0])
# mask
mask = paddle.triu(paddle.ones([xp.shape[-1], xp.shape[-1]]))
x = xp * mask
return x
class JustMaskEm(paddle.nn.Layer):
def __init__(self, voc_size=19, hidden_size=256, max_len=1024):
super(JustMaskEm, self).__init__()
# 定义输入序列和标签序列
self.em_mask_one = EmMask(voc_size, hidden_size, max_len)
self.em_mask_two = EmMask(voc_size, hidden_size, max_len)
self.head_layer = paddle.nn.Linear(hidden_size, voc_size,bias_attr=False)
self.layer_nor = paddle.nn.LayerNorm(hidden_size)
# 定义模型计算过程
def forward(self, x):
one = self.em_mask_one(x)
two = self.em_mask_two(x)
x = one* paddle.sum(two, -2).unsqueeze(3)
x = paddle.sum(x, -2)
x=x.transpose([0, 2, 1])
x = self.head_layer(self.layer_nor(x))
return x
# 进行模型训练和预测
if __name__ == '__main__':
net = JustMaskEm()
X = paddle.to_tensor([
[1, 2, 3, 4],
[5, 6, 7, 8]
], dtype='int64')
print(net(X).shape)
print(net.sample_buffer(X).shape)
#
# def train_data():
# net = JustMaskEm(voc_size=len(voc_id))
# net.load_dict(paddle.load("long_attention_model"))
# print("加载成功")
# opt = paddle.optimizer.Adam(parameters=net.parameters(), learning_rate=0.0003)
# loss_f = paddle.nn.CrossEntropyLoss()
# loss_avg = []
# acc_avg = []
# batch_size = 1000*3
# for epoch in range(1, 3 * 600):
# np.random.shuffle(data_set)
# for i, j in [[i, i + batch_size] for i in range(0, len(data_set), batch_size)]:
# one_data = data_set[i:j]
# if (len(acc_avg) + 1) % 1000 == 0:
# print(np.mean(loss_avg), "____", np.mean(acc_avg))
# paddle.save(net.state_dict(), "long_attention_model")
# paddle.save({"data": loss_avg}, "loss_avg")
# paddle.save({"data": acc_avg}, "acc_avg")
#
# one_data = paddle.to_tensor(one_data)
# in_put = one_data[:, :-1]
# label = one_data[:, 1:]
# # label = one_data[:, 1:]
#
# out = net(in_put)
# loss = loss_f(out.reshape([-1, out.shape[-1]]), label.reshape([-1]).astype("int64"))
# acc = np.mean((paddle.argmax(out, -1)[:, :].reshape([-1]) == label[:, :].reshape([-1])).numpy())
# # loss = loss_f(out, label.reshape([-1]).astype("int64"))
# # acc = np.mean((paddle.argmax(out, -1) == label.reshape([-1])).numpy())
# loss_data = loss.numpy()[0]
# acc_avg.append(acc)
# loss_avg.append(loss_data)
# print(epoch, "____", np.mean(loss_avg), "____", np.mean(acc_avg))
# opt.clear_grad()
# loss.backward()
# opt.step()
# if np.mean(acc_avg) > 0.80:
# opt.set_lr(opt.get_lr() / (np.mean(acc_avg) * 100 + 1))
# print(np.mean(loss_avg), "____", np.mean(acc_avg))
# paddle.save(net.state_dict(), "long_attention_model")
# paddle.save({"data": loss_avg}, "loss_avg")
# paddle.save({"data": acc_avg}, "acc_avg")
#
# if __name__ == "__main__":
# with open("poetrySong.txt", "r", encoding="utf-8") as f:
# data1 = f.readlines()
# data1 = [i.strip().split("::")[-1] for i in data1 if len(i.strip().split("::")[-1]) == 32]
# voc_id = ["sos"] + sorted(set(np.hstack([list(set(list("".join(i.split())))) for i in data1]))) + ["pad"]
# data_set = [[voc_id.index(j) for j in i] for i in data1]
# train_data()
后期
完善网络结构
模型参数量与数据参数量的讨论
使用just mask and sum 验证模型参数量和数据量的 关系
几种just mask and sum 网络结构的讨论
应用在其任务上。。。。。。。。。。。