Elasticsearch搜索引擎系统入门
目录
【认识Elasticsearch】
Elasticsearch主要应用场景
Elasticsearch的版本与升级
【Elastic Stack全家桶】
Logstash
Kibana
Beats
Elasticsearch在日志场景的应用
Elasticsearch与数据库的集成
【安装Elasticsearch】
安装插件
安装Kibana
安装Logstash
【认识Elasticsearch】
Elasticsearch是一个分布式搜索引擎系统,可以实现大数据近实时分析。官网:https://www.elastic.co/cn/
Elasticsearch起源于Lucene,Lucene是基于Java语言开发的搜索引擎库类,创建于1999 年,2005年成为Apache顶级开源项目。Lucene 具有高性能、 易扩展的优点,但也有一些局限性:只能基于 Java语言开发,原生并不支持水平扩展。
2004 年Shay Banon基于Lucene 开发了Compass,2010年Shay Banon重写了Compass, 取名Elasticsearch。相比于原生的Lucene,Elasticsearch支持分布式,可水平扩展,降低全文检索的学习曲线,可以被任何编程语言调用。

Elasticsearch支持多种方式集成接入,官网提供了多种编程语言的类库,包括 Java、JavaScript、Ruby、Go、.NET、PHP、Perl、Python、Eland、Rust 等,可以查看:https://www.elastic.co/guide/en/elasticsearch/client/index.html

Elasticsearch主要应用场景
- 海量数据的分户式存储以及集群管理,服务与数据的高可用,水平扩展
- 近实时搜索,性能卓越,结构化/全文/地理位置/自动完成
- 海量数据的近实时分析,聚合功能
Elasticsearch的版本与升级
0.4版本: 2010年2月第一次发布
1.0版本: 2014年1月发布
2.0版本: 2015年10月发布
5.0版本: 2016年10月发布
新特性5.x:
● Lucene 6.x, 性能提升,默认打分机制从TF-IDF改为BM 25
● 支持Ingest节点/ Painless Scripting / Completion suggested支持/原生的Java REST客户端
● Type标记成deprecated, 支持了Keyword的类型
● 性能优化:内部引擎移除 了避免同一文档并发更新的竞争锁,带来15% - 20%的性能提升;Instant aggregation,支持分片上聚合的缓存;新增了Profile API。
6.0版本: 2017年10月发布
新特性6.x
● Lucene 7.x● 新功能:跨集群复制(CCR);索引生命周期管理;SQL的支持
● 更友好的的升级及数据迁移:在主要版本之间的迁移更为简化;全新的基于操作的数据复制框架,可加快恢复数据;
● 性能优化:有效存储稀疏字段的新方法,降低了存储成本;在索引时进行排序,可加快排序的查询性能
7.0版本: 2019年4月发布
新特性7.x
● Lucene 8.0
● 重大改进-正式废除单个索引下多Type的支持
● 7.1 开始,Security 功能免费使用
● ECK - Elasticseach Operator on Kubernetes
● 新功能:New Cluster coordination;Feature-Complete High Level REST Client;Script Score Query
● 性能优化:默认的 Primary Shard数从5改为1,避免Over Sharding;性能优化,更快的Top K
更多信息,查看:https://www.elastic.co/cn/support/eol
【Elastic Stack全家桶】
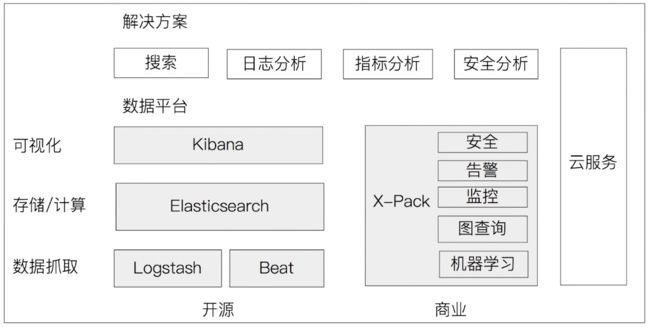
Elasticsearch公司的核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack),如下图所示:
Logstash
Logstash诞生于2009年,最初用来做日志的采集与处理,于2013年被Elasticsearch公司收购。现在已经成为了一个开源的服务器端数据处理管道,支持从不同来源采集数据和转换数据,并将数据发送到不同的存储库中。https://www.elastic.co/cn/logstash
Logstash有如下特性:
- 实时解析和转换数据:从IP地址破译出地理坐标;将PII数据匿名化,完全排除敏感字段
- 可扩展:支持200多个插件(日志/数据库/Arcsigh/Netflow)
- 可靠性安全性:Logstash会通过持久化队列来保证至少将运行中的事件送达一次;数据传输加密
- 数据监控

Kibana
Kibana是一个数据可视化工具, 能够方便的查看和分析数据。https://www.elastic.co/cn/kibana
Kibana 名字的含义:Kiwifruit + Banana,是一个基于 Logstash的工具,2013 年加入Elastic公司。
Beats
Beats是一个轻量型数据采集器,免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。https://www.elastic.co/cn/beats

Elasticsearch在日志场景的应用
一个项目的日志部分的重要性不言而喻,通过日志可以排查到各类问题,如果日志分散在不同的机器上,那么就可以使用Elasticsearch来收集各个机器的日志,然后合并处理,方便查询。 主要实现如下功能:日志收集、格式化分析、全文检索、风险告警。
Elasticsearch与数据库的集成
虽然可以直接使用Elasticsearch作为数据库存储数据,但是很多时候会需要和传统的数据库(比如MySQL、Oracle、MongoDB等)结合使用,可以通过消息队列(比如RabbitMQ、Kafka等)将数据库的数据同步到Elasticsearch中再进行分析处理。

【安装Elasticsearch】
前往官网 https://www.elastic.co/cn/downloads/elasticsearch 下载适合自己操作系统的安装包,然后解压。
目录结构:

| 目录 | 配置文件 | 描述 |
| bin | 可执行的脚本文件,包括启动elasticsearch,安装插件。运行统计数据等 | |
| config | elasticsearch.yml | 集群配置文件,user, role based相关配置 |
| jdk | Java运行坏境 | |
| data | path.data | 数据文件,保存 ES 运行过程中需要保存的数据。 |
| lib | Java类库 | |
| logs | path.log | 日志文件 |
| modules | 包含所有ES功能模块的存放目录,如aggs、reindex、geoip、xpack、eval | |
| plugins | 包含所有已安装插件 |
启动:./bin/elasticsearch(直接启动) 或 ./bin/elasticsearch -d(后台启动)

浏览器输入:http://localhost:9200/

使用下面的命令启动集群:
#启动单节点
bin/elasticsearch -E node.name=node0 -E cluster.name=geektime -E path.data=node0_data -d
#启动集群(启动几个实例,就运行几次)
bin/elasticsearch -E node.name=node0 -E cluster.name=geektime -E path.data=node0_data -d
bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -d
bin/elasticsearch -E node.name=node2 -E cluster.name=geektime -E path.data=node2_data -d
bin/elasticsearch -E node.name=node3 -E cluster.name=geektime -E path.data=node3_data -d
#查看集群
GET http://localhost:9200
#查看nodes
GET _cat/nodes
GET _cluster/health
#退出
ps -ef | grep elasticsearch,然后kill 对应的pid安装插件
#查看已安装的插件
./bin/elasticsearch-plugin list
#安装国际化分析插件 analysis-icu
./bin/elasticsearch-plugin install analysis-icu
#重新启动
./bin/elasticsearch在浏览器打开:http://localhost:9200/_cat/plugins?v

进入 https://www.elastic.co/guide/en/elasticsearch/plugins/7.10/intro.html 可以查看指定版本的插件列表

安装Kibana
进入 https://www.elastic.co/cn/downloads/kibana 下载对应版本的Kibana安装包(需要个ES版本一致),然后解压,执行 ./bin/kibana(需要先启动Elasticsearch)
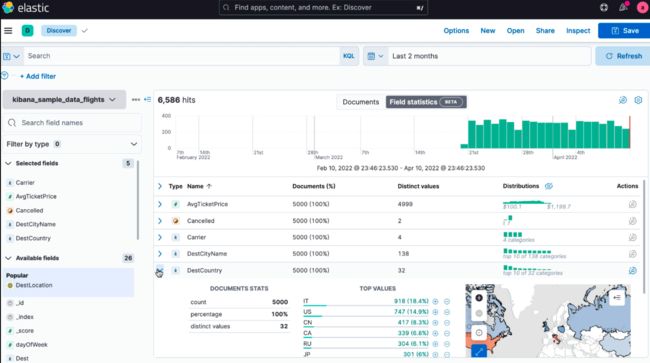
访问 http://localhost:5601/app/kibana 打开Kibana控制台:
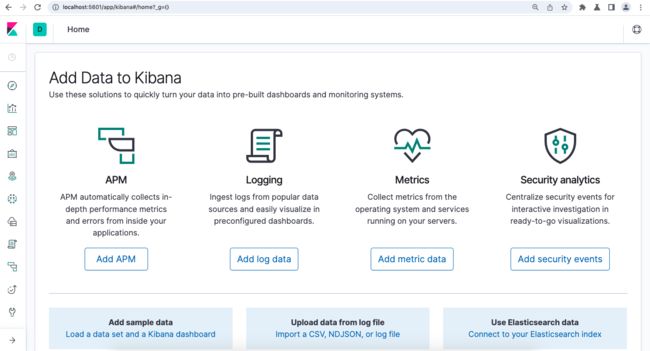
可以添加一些测试数据,点上面的“Add sample data”,然后选择“Sample data”:
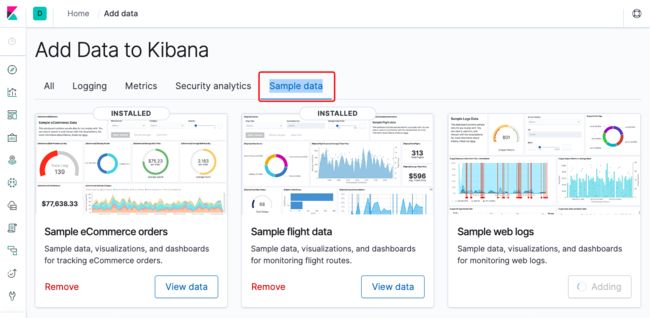
然后从Dashboard中可以看到刚才添加的数据:
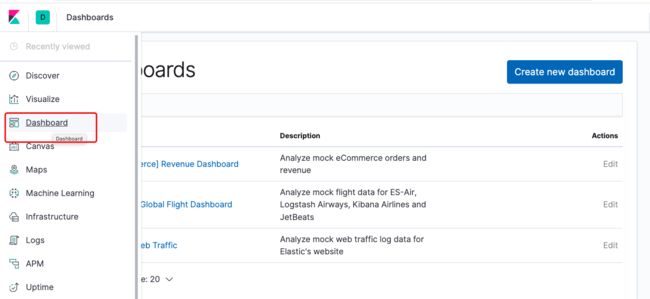
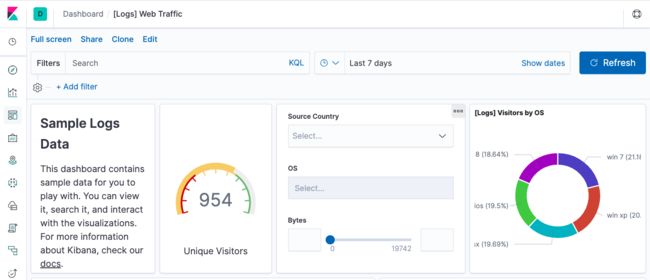 安装Kibana的插件和ES类似:
安装Kibana的插件和ES类似:
#查看已安装的Kibana插件
./bin/kibana-plugin list
#安装Kibana插件
./bin/kibana-plugin install plugin_location
#移除Kibana插件
./bin/kibana-plugin remove安装Logstash
进入 https://www.elastic.co/cn/downloads/past-releases#logstash 下载和ES相同版本的Logstash安装包,这里我下载7.1版本的。
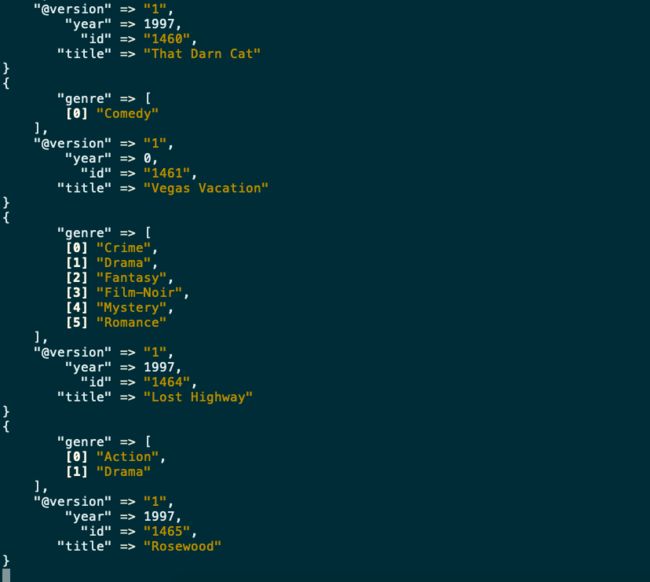
 下载MovieLens最小测试数据集:https://grouplens.org/datasets/movielens/ ,解压Logstash安装包,并且导入Movielens的测试数据集。
下载MovieLens最小测试数据集:https://grouplens.org/datasets/movielens/ ,解压Logstash安装包,并且导入Movielens的测试数据集。
也可以从这里下载:https://gitee.com/rxbook/elasticsearch-demo/tree/master
#下载与ES相同版本号的logstash,(7.1.0),并解压到相应目录
#修改movielens目录下的logstash.conf文件
#path修改为,你实际的movies.csv路径
input {
file {
path => "YOUR_FULL_PATH_OF_movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
#启动Elasticsearch实例,然后启动 logstash,并指定配置文件导入数据(操作比较耗时,耐心等待)
sudo bin/logstash -f /YOUR_PATH_of_logstash.conf 数据导入中...
数据导入中...