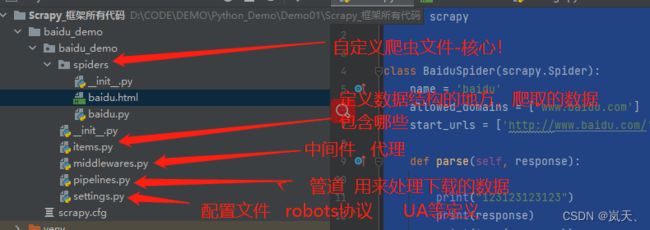
Python Scrapy 框架的入门-基本使用+案例下载
安装:
命令:(使用阿里云镜像下载)
pip install scrapy -i http://mirrors.aliyun.com/pypi/simple/
如果安装过程出错有以下几种问题:
1.缺少twisted 解决方法:pip install twisted 或者去官网下载,(大部分都是这个原因)
2.升级pip 命令: python -m pip install --upgrade pip
3.实在不行 就去下载 Anaconda 下载地址: https://anaconda.org/
检查Scrapy是否安装成功: 在cmd窗口输入scrapy如果有版本提示就是安装成功了

简介:(来自百度百科)
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。 [1]
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。 [2]
架构
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。 [1] [2]
Scrapy基本使用
可以创建一个空项目先,用CMD也行,或者是IDE工具的Teminal也行,用cmd得手动切换目录,自带的Teminal控制台就不需要了。首先进入到项目的目录就可以开始创建咱们的第一个scrapy 爬虫了。
第一步: 创建爬虫项目
在控制台输入:
scrapy startproject 项目名字 (不能数字开头也不能包含中文)
例如: scrapy startproject baidu_demo
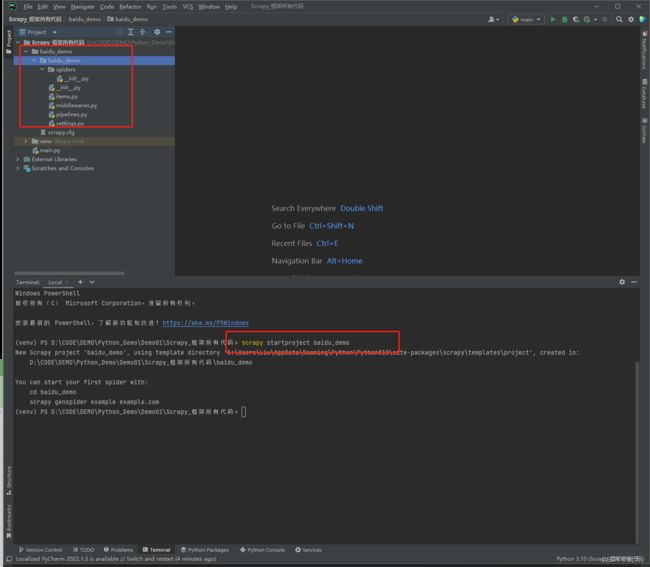 输入完之后就会自动生产这么多文件夹, 先别慌,咱们主要看到:项目的名字\项目的名字\spiders中的东西,这里面是主要的,其他的之后会讲到。我这里是baidu_demo/baidu_demo/spiders
输入完之后就会自动生产这么多文件夹, 先别慌,咱们主要看到:项目的名字\项目的名字\spiders中的东西,这里面是主要的,其他的之后会讲到。我这里是baidu_demo/baidu_demo/spiders
第二步:创建爬虫文件 先进入spiders文件夹 创建爬虫文件
进入文件夹命令: cd 项目的名字\项目的名字\spiders
我这里的命令是 cd .\baidu_demo\baidu_demo\spiders\

创建爬虫文件命令: scrapy genspider 爬虫文件的名字 要爬取的网页 我这里拿百度举例子
scrapy genspider baidu http://www.baidu.com
就会生成一个你命名.py的文件,
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['www.baidu.com']
# 起始的url地址 指的是第一次要访问的域名
start_urls = ['http://www.baidu.com/']
pass
name:这里表示的是爬虫的名字,在控制台给他以后运行都是靠这个名字来运行的
allowed_domains:是允许访问的域名
start_urls :是第一次要访问的域名
parse()方法中有一个response属性,这个属性是直接获取到了响应的请求连接数据,咱们上面的www.baidu.com响应数据,通过这个数据我们可以获取到网页的源码,和解析网页数据,进行爬虫。
爬虫命令帮助可以通过这个命令查看:scrapy --help

第三步:执行爬虫文件 命令: scrapy -crawl 爬虫名字 (上面有写到,我这里是baidu)
首先我们在生成的py文件的parse方法中写一些内容,看看能不能执行出来

可以看到我的打印语句是没有出来的,这是什么原因呢?
这是因为很多公司都有一个“君子协议”,叫做robots协议,只要我们不遵守就可以了,找到文件夹中的setting.py文件,将ROBOTSTXT_OBEY=True 注释掉或者改为False 即可
ROBOTSTXT_OBEY = False
robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,
哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个robots协
议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。 [5] 如果想单独
定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用
robots元数据(Metadata,又称元数据)。
robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。

我们在重新运行一次即可看到我们打印的数据了!
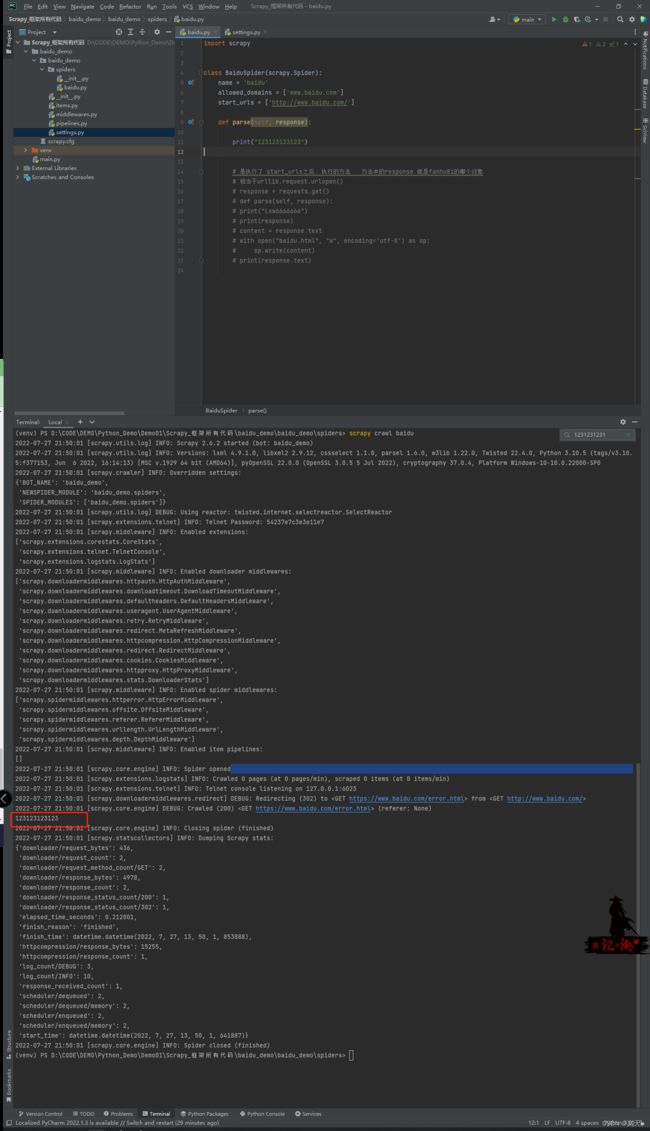
以上就是scrapy的基本使用,安装和创建基本的爬虫程序。下面我们讲解一下他的parse()中的response吧!
def parse(self, response):
print("123123123123")
这里的response,如果用过urllib.request 或者是 requests的小伙伴可能知道这个response是什么了,他类似于urllib.request.urlopen()和requests.get()的返回值
我们可以打印一下看到他是个什么类型和值:

可以看到打印出来的是一个HtmlResponse类型-, 通过源码可以看到他这里面有个text属性,还有Xpath方法说明他这个可以直接解析网页源码并不需要我们再去导入xpath包,这就是scrapy的优势,text属性中写的是网页的字符串源码,我们打印看看。
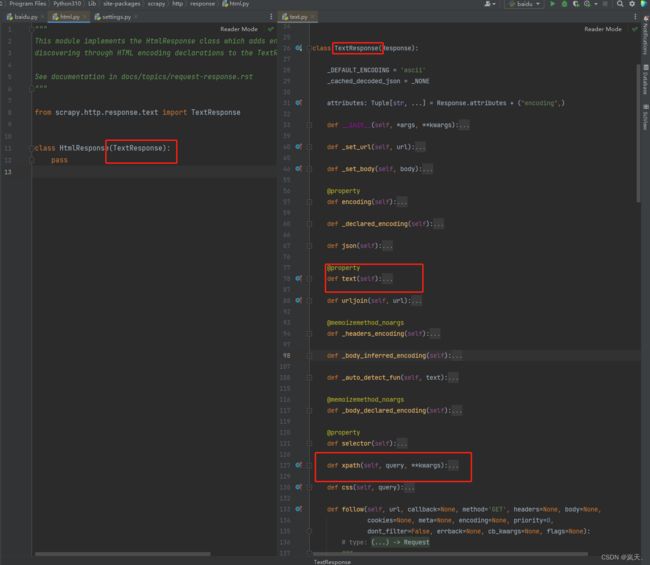
我这直接写到html文件中了,可以看到可以是字符串源码
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
print("123123123123")
print(response)
print(type(response))
content = response.text
print(content)
# 输出到html文件,方便查看
with open("baidu.html", "w", encoding='utf-8') as op:
op.write(content)
最后说一下这个目录吧: