海量数据存储组件Hbase
hdfs
hbase
NoSQL数据库 支持海量数据的增删改查 基于Rowkey查询效率特别高
kudu
介于hdfs和hbase之间
hbase依赖hadoop+zookeeper,同时整合框架phoenix(擅长读写),hive(分析数据)
k,v 储存结构
稀疏的(为空的不存储)、分布式的、持久地、多维排序map-》映射:行键、列键、时间戳,未解释的(序列化的,存储效率高)
数据存储整体有序 列 、 列族 、 rowkey按字典序排序,然后将一个“表格”切分出一个Region,对应有rowkey的范围,每个Region的rowkey范围都不重叠。竖行切分store,按列族为单位进行。
使用timestamp实现数据修改,version确认版本,操作类型type
namespace=database
cell唯一确定的单元
架构
master通过zookeeper管理region server,region server向zookeeper注册自己的信息
操作表格的命令是有master进行的,修改和删除
loadBalancer均衡负载器
预写日志处理器:容错机制
master backup server 高可用信息
hbase shell 常用命令: list_namespace
DDL:
create_namespace 'bigdata'
create 't1', {NAME=>'F1',VERSION=>5}
表名 列族 名 指定维护的时间戳版本数,例子中的版本数为5
describe 't1'
alter 't1' ,'delete'=>'info1' 删除列族
删除表: disable 't1' drop 't1'
DML:
插入数据: put 'bigdata:t1' ,'r1' ,'c1' ,'value' ts1
'库名 :表名' rowkey 列族:列名 列值 时间戳
读取数据:
get 一行数据 和scan 多行数据
scan 'bigdata:t1' {startrow=>'',stoprow=>''}
前开后闭
删除数据:
delete 删除一行数据,一个cell。 默认是删除给定时间戳之前的第一个遇到的时间戳的数据。实际是在插入一条delete记录。
delete all 删除所有版本的数据,即多个cell。
API
涉及java建造者 Builder模式: 命名空间建造者=》设计师
集成phoenix 针对hbase上面还没有数据,需要写入数据 不适合复杂SQL查询
开源hbase的sql皮肤 标准jdbc API 自带sql优化器 如谓词下推
phoenix的primarykey对应hbase的rowkey 官网查询语法,与sql类似
!table


已经存在于hbase的表,phoenix需要进行视图映射或表映射才能使用。
create view drop view 只能看,无法操作数据
表映射可以修改删除数据

phoenix二级索引-将 全表扫描优化为范围扫描
默认 全局索引:专门创建一张索引表,给非rowkey列去做rowkey排序(如字典序)。写的时候需要写两张表,故适合多读少写的场景。

explain 查看执行计划

全局索引的局限,不能包含非索引字段
全局索引的补充:包含索引

本地索引

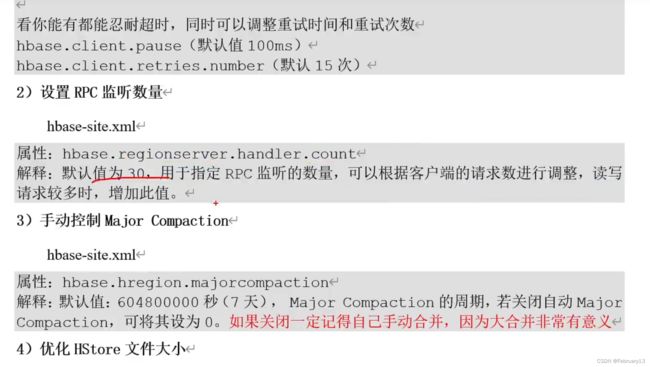
hbase参数优化:
zookeeper timeout优化
rpc监听数量 :put、get
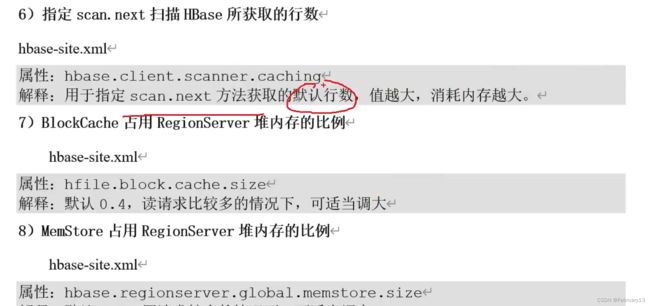
多个写缓存加起来大小大于40%
JVM调优
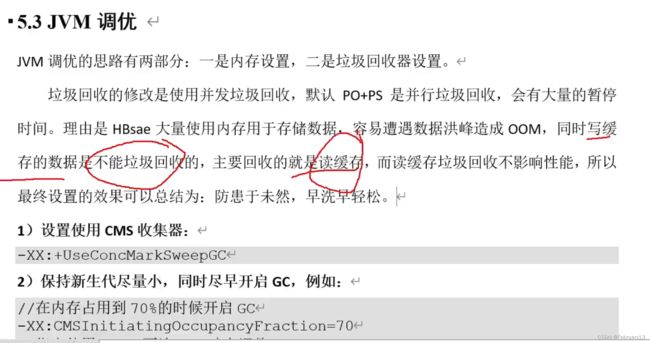
并发垃圾回收:一边读写一边垃圾回收


集成hive 针对hbase上面已经存好数据,需要分析数据
hbase的数据其实也是存储在hdfs上面的
HQL创建hbase表

load data 只是将数据上传到文件系统指定目录中,而insert into 才能把格式对应上,因为它要跑商计算程序(如mr);

rowkey设计原则
TSDB 将时间戳加入rowkey中,增量抽取数据变化的部分
目的是让数据均匀地分布在region中,3中方法:
