redis线程模型
文章目录
- 一、redis单线程模型
-
- 1.1 为什么redis命令处理是单线程,而不采用多线程
- 1.2 单线程的局限及redis的优化方式
- 二、redis单线程为什么这么快
-
- 2.1 采用的机制
- 2.2 优化的措施
- 三、redis的IO多线程模型
-
- 3.1 redis 为什么引入IO多线程模型
- 3.2 配置io-threads-do-reads
- 3.3 流程
一、redis单线程模型
首先需要注意的是,redis整体而言并不是单线程。
 redis-server是主线程,所说的redis是单线程主要指redis-server这个线程,用于处理命令。
redis-server是主线程,所说的redis是单线程主要指redis-server这个线程,用于处理命令。
所谓的redis单线程,指的是命令处理、逻辑处理在一个单线程中。即【接收客户端请求–>解析请求 -->进行数据读写等操作–>发送数据给客户端】这个过程是由一个线程(主线程)来完成的。
redis 6.0 版本之前的单线模式
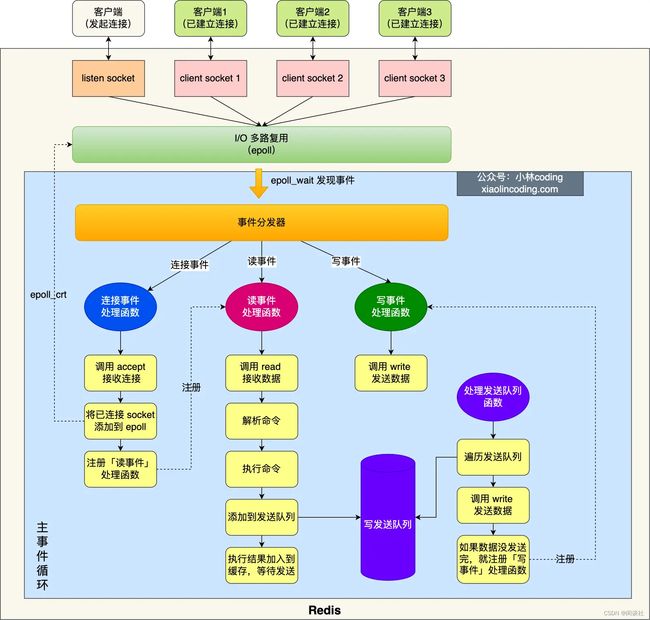
图中的蓝色部分是一个事件循环,是由主线程负责的,可以看到网络 I/O 和命令处理都是单线程。
1.1 为什么redis命令处理是单线程,而不采用多线程
- redis支持多种数据结构(如string、list、hash、set、zset等),每个对象类型都是由多个数据结构实现的。因此多线程环境下,加锁复杂、锁粒度不好控制。
- 频繁的上下文切换,会带来更多的时间和性能上的开销,从而抵消多线程的优势。redis作为数据库,并不是每时每刻都有密集访问。在多线程环境下,访问少时需要将一些线程休眠,访问多时又需要唤醒,这就存在频繁的线程调度问题。
1.2 单线程的局限及redis的优化方式
单线程最大的局限,在于不能有耗时操作,即阻塞IO、CPU运算时间比较长的任务等。这会影响redis的响应性能。
redis的耗时操作以及其解决优化方式:
1)IO密集型 —— 磁盘IO : redis提供了类似于日志备份的 aof(Append-Only File)方式以支持持久化,也就是对数据的更改操作需要刷新落到磁盘里。针对这个耗时操作,redis有两种优化方法:1、rdb(Redis Database)文件:redis会fork一个子进程,在子进程中进行持久化,不占用主线程的资源。2、aof持久化策略:redis会创建bio_aof_fsync线程进程异步刷盘。
2)IO密集型 —— 网络IO :当redis服务多个客户端时,如果数据请求或返回数据量比较大时,造成了IO密集型的情况,也是比较耗时的操作。对比,redis通过开启IO多线程(io_thd_*线程)来处理网络IO。
3)CPU密集型:redis支持丰富的数据结构,而有些数据结构操作的事件复杂度比较高,就可能会导致CPU花费大量的时间去计算。对比,redis采用分治的方式。
二、redis单线程为什么这么快
2.1 采用的机制
redis采用了以下机制
- redis是内存数据库,数据存储在内存中,可以高效地访问。
- redis使用hash table的数据组织方式,查询数据的时间复杂度为 O ( 1 ) O(1) O(1),能快速查找数据。
- redis采用了高效的数据结构,可以根据性能进行数据结构切换,使得执行效率与空间占用保持平衡。
- redis使用高效的reactor网络模型。
2.2 优化的措施
- redis采用分治的思想,把rehash分摊到之后的每步增删查改的操作当中。同时,在定时器中最大执行1毫秒的rehash,每次步长100个数组槽位。
- redis将耗时阻塞的操作,放在其他线程处理。
- redis针对不同的对象类型采用不同的数据结构实现。比如string对象针对不同的数据长度,有int、raw、embstr三种编码方式。
127.0.0.1:6379> set name jack
OK
127.0.0.1:6379> OBJECT encoding name
"embstr"
127.0.0.1:6379> set name "1001"
OK
127.0.0.1:6379> OBJECT encoding name
"int"
127.0.0.1:6379> set name 123456789012345678901234567890123456789012345678901234567890
OK
127.0.0.1:6379> OBJECT encoding name
"raw"
三、redis的IO多线程模型
3.1 redis 为什么引入IO多线程模型
在 redis 6.0 版本之后,也采用了多个 I/O 线程来处理网络请求,这是因为随着网络硬件的性能提升,redis 的性能瓶颈有时会出现在网络 I/O 的处理上。所以为了提高网络 I/O 的并行度,Redis 6.0 对于网络 I/O 采用多线程来处理。但是对于命令的执行,Redis 仍然使用单线程来处理。
即多线程处理网络IO(read、decode和encode、send阶段)。主线程使用单线程,执行命令处理业务逻辑(因为 redis 采用高效的数据结构,其业务逻辑处理较快,所以用单线程即可)。

3.2 配置io-threads-do-reads
io-threads-do-reads是 redis.conf 文件中的一个配置选项,用于控制 I/O 线程是否执行读取操作。
默认情况下 I/O 多线程只针对发送响应数据( encode, send),并不会以多线程的方式处理读请求( read, decode)。要想开启多线程处理客户端读请求,就需要把 Redis.conf 配置文件中的 io-threads-do-reads 配置项设为 yes。
//读请求也使用io多线程
io-threads-do-reads yes
// io-threads N,表示启用 N-1 个 I/O 多线程(主线程也算一个 I/O 线程)
io-threads 4
当将 io-threads-do-reads 设置为 “yes” 时,I/O 线程将负责处理客户端请求的读取操作。这意味着 I/O 线程可以直接从套接字中读取数据,并进行相应的处理,而无需等待主线程来分发任务。
使用 io-threads-do-reads 的好处是能够减轻主线程的负担,提高系统的并发性能和响应速度。通过将读取操作分配给专门的 I/O 线程,可以使主线程更专注于处理其他的任务,如写入操作、协议解析和业务逻辑等。
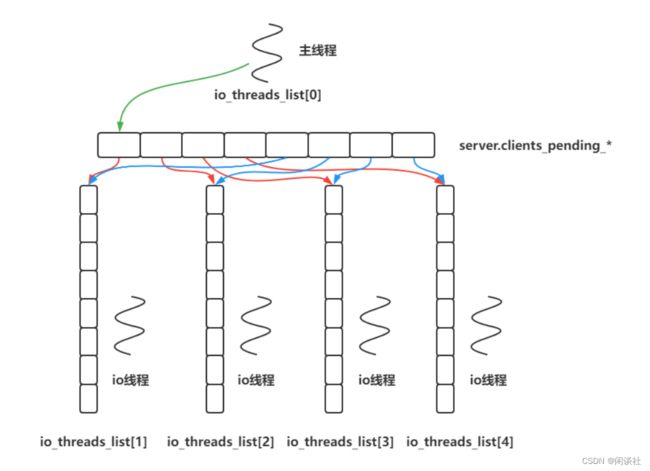
3.3 流程
对于 redis 来说,它采用的是 I/O 多路复用技术而不是真正的多线程模型。其基本流程:
- redis-server主线程作为生产者:
∙ \bullet ∙ 当有新的客户端连接请求到达时,主线程会将对应的客户端套接字加入到clients_pending_read 队列中。这表示该连接上有数据可读,需要被处理。
∙ \bullet ∙ 当有客户端数据写入请求到达时,主线程会将对应的客户端套接字加入到 clients_pending_write 队列中。这表示该连接上可以进行写操作。 - redis-server主线程作为消费者:
∙ \bullet ∙ 主线程通过循环遍历 clients_pending_read 队列中的客户端套接字,并将其分配给合适的 I/O 线程处理。主线程会根据负载均衡策略(如轮询或哈希)来决定将客户端套接字分发给哪个 I/O 线程的专属队列。
∙ \bullet ∙ 类似地,主线程也会从 clients_pending_write 队列中获取客户端套接字,并将其分配给适当的 I/O 线程处理。 - I/O 线程执行任务:
∙ \bullet ∙ 每个 I/O 线程拥有一个专属队列(如 io_threads_list[id]),主线程将客户端套接字分配给指定的 I/O 线程,并将其加入到对应的队列中。
∙ \bullet ∙ I/O 线程通过从自己的队列中获取客户端套接字,进行实际的读写操作和请求处理。一旦完成操作,也可以将结果返回给主线程。
通过这种队列模型和任务调度方式,主线程在兼顾生产者和消费者角色的同时,能够高效地将任务分发给对应的 I/O 线程进行处理,以提高并发性能和系统的吞吐量。同时,这种设计还能避免多线程并发带来的同步问题和竞争条件,保证了系统的稳定性和可靠性。