Datawhale AI夏令营 - NLP实践:基于论文摘要的文本分类与关键词抽取挑战赛——五天冲A榜
Author: 净好
阅前必读:
看完一、二,你应该会清楚该比赛要完成两个任务:1.文本分类 2.关键词总结,足够了解NLP的任务其实也可以不看这两部分,建议直接跳到三。
看完三,你应该会清楚该比赛数据的各个方面以及后续操作应该采取的策略及细节把控
看完四,你应该会清楚三个Baseline对应着三种NLP领域不同发展时期的比赛解决方案:1.传统的文本特征提取+机器学习方法 2.预训练微调 3.微调大语言模型
看完五、六,你应该会清楚该比赛的提分细节,以及该比赛的难点究竟在哪
目录
一、赛题介绍
二、比赛数据及评估结果
1.数据说明
2.评估指标
三、比赛数据集分析
1.比赛须知
2.数据集分析
四、Baseline介绍及其代码
Baseline1:词袋/TF-IDF表征文本 + 逻辑回归模型
Baseline2:Bert微调分类 + 余弦相似度选择关键词
Baseline3:ChatGLM2微调
五、我的打榜过程
A榜 - 0.37775 → 0.97655
A榜 - 0.97655 → 0.99208
A榜 - 0.99208 → 0.99720
A榜 - 0.99720 → 0.99772
A榜 - 0.99772 → 0.99877
六、注意事项及答疑学习
注意事项
答疑学习
一、赛题介绍

比赛链接:https://challenge.xfyun.cn/topic/info?type=abstract-of-the-pape
选手们需要完成以下两个子任务:
-
机器通过对论文摘要等信息的理解,判断该论文是否属于医学领域的文献。
-
提取出该论文关键词。
任务1示例:
输入:
论文信息,格式如下:
Inflammatory Breast Cancer: What to Know About This Unique, Aggressive Breast Cancer.,
[Arjun Menta, Tamer M Fouad, Anthony Lucci, Huong Le-Petross, Michael C Stauder, Wendy A Woodward, Naoto T Ueno, Bora Lim],
Inflammatory breast cancer (IBC) is a rare form of breast cancer that accounts for only 2% to 4% of all breast cancer cases. Despite its low incidence, IBC contributes to 7% to 10% of breast cancer caused mortality. Despite ongoing international efforts to formulate better diagnosis, treatment, and research, the survival of patients with IBC has not been significantly improved, and there are no therapeutic agents that specifically target IBC to date. The authors present a comprehensive overview that aims to assess the present and new management strategies of IBC.,
Breast changes; Clinical trials; Inflammatory breast cancer; Trimodality care.
输出:
是
任务2示例:
输入:
Inflammatory Breast Cancer: What to Know About This Unique, Aggressive Breast Cancer.,
[Arjun Menta, Tamer M Fouad, Anthony Lucci, Huong Le-Petross, Michael C Stauder, Wendy A Woodward, Naoto T Ueno, Bora Lim],
Inflammatory breast cancer (IBC) is a rare form of breast cancer that accounts for only 2% to 4% of all breast cancer cases. Despite its low incidence, IBC contributes to 7% to 10% of breast cancer caused mortality. Despite ongoing international efforts to formulate better diagnosis, treatment, and research, the survival of patients with IBC has not been significantly improved, and there are no therapeutic agents that specifically target IBC to date. The authors present a comprehensive overview that aims to assess the present and new management strategies of IBC.
输出:
[Breast changes,Clinical trials, Inflammatory breast cancer,Trimodality care]
二、比赛数据及评估结果
1.数据说明
训练集与测试集数据为CSV格式文件,各字段分别是标题、作者、摘要、关键词。
2.评估指标
任务一采用F1-score进行评价:
![]()
任务二采用文献关键词抽取准确率Acc进行评价:

其中N为文献总数。
最终分数 = 0.4*任务一分数+0.6*任务二分数
三、比赛数据集分析
1.比赛须知
由于比赛官方提供的测试集包含了Keywords,所以A榜提交文件里面的Keywords可以直接copy测试集里面的Keywords。那么就相当于A榜只需要完成文本的二分类任务即可,也就是通过论文标题、摘要、作者这三个信息来判断该文献是否属于医学领域的文献,是则标签为1,不是则标签为2.
2.数据集分析
通过给自己提出问题的方式去回答,并根据以往经验去规划细节。
问题一:数据集中的样本数目是多少?
答:训练集有6000条样本,测试集有2358条样本。
以往经验:这个训练集大小对于分类任务来说已经足够大了,再加上判断医学文献的这个二分类任务较为简单,所以推测传统方法和预训练微调的方法都能取得很高的分数,追求鲁棒性的时候完全可以同时将这两种方法集成起来。
规划细节:动手的时候,打算先测试一下Baseline,再将机器学习的方法和深度学习的方法集成起来,看看效果是否足够好,如果效果很好的话,就可以放心拥抱机器学习了:)
问题二:数据集中是否存在缺值、缺内容的问题?
答:存在缺内容的问题,但还好测试集当只有uuid为538的文献缺失了摘要部分的内容。
以往经验:补上去就得了呗:p
规划细节直接上手:点击"谷粉学术"→搜索文献标题"xxx"→复制摘要"abstract:xxx"→黏贴于test.csv→Ctrl+S+ESC一气呵成
问题三:训练集中的样本数量是否均衡?
答:正样本共2921条,负样本共3079条。
以往经验:这个比例还算是均衡的,不需要做什么处理。
规划细节:先跑模型,后续如果发现模型预测明显偏向于负样本的时候,可以再进行数据增广或数据剪裁或调整预测权重。
问题四:比较训练集每个样本的文本内容(标题+作者+摘要),最小长度、最大长度、平均长度分别是多少?
答:最小长度是21个单词,最大长度是1458个单词,平均长度约209个单词。
以往经验:分词的时候,max_len肯定不能设置小于21,但太长可能也并不好,初步考虑256~768
规划细节:打算使用Bert的时候尝试以640作为max_len
问题五:数据集中的关键词是否都能在文本内容(标题+作者+摘要)中找到?
答:不能,并且很多都是没有在文本内容中出现的。
以往经验:若目标词没出现在赛事所提供的数据里面,则说明要么涉及到文本生成,要么就是需要我们主动去爬取、整理完整的关键词词表,然后再去进行语义匹配。
规划细节:吐槽一下:P,这次任务2不应该叫做“关键词提取”,而应该叫做“关键词总结”(文本生成角度)或“关键词匹配”(词表角度)。先用传统方法试一下,再尝试用大语言模型看看效果怎么样,如果不行只能花时间去爬医学领域的文献关键词了。(不能用外部数据!)

四、Baseline介绍及其代码
Datawhale提供了三个Baseline,其中第一个Baseline为线上Baseline,部署在飞桨的Aistudio里面,可以一键运行。第二个Baseline为bert模型微调,第三个Baseline为大语言模型微调。(Baseline直达链接:AI夏令营 - NLP实践教程 )
Baseline1:词袋/TF-IDF表征文本 + 逻辑回归模型
该Baseline运行后的A榜分数为:0.97655
Task1(文本分类)代码:
# 导入pandas用于读取表格数据
import pandas as pd
# 导入BOW(词袋模型),可以选择将CountVectorizer替换为TfidfVectorizer(TF-IDF(词频-逆文档频率)),注意上下文要同时修改,亲测后者效果更佳
from sklearn.feature_extraction.text import CountVectorizer
# 导入LogisticRegression回归模型
from sklearn.linear_model import LogisticRegression
# 过滤警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)
# 读取数据集
train = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/train.csv')
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')
test = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/test.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
# 提取文本特征,生成训练集与测试集
train['text'] = train['title'].fillna('') + ' ' + train['author'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['author'].fillna('') + ' ' + test['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])
# 引入模型
model = LogisticRegression()
# 开始训练,这里可以考虑修改默认的batch_size与epoch来取得更好的效果
model.fit(train_vector, train['label'])
# 利用模型对测试集label标签进行预测
test['label'] = model.predict(test_vector)
# 生成任务一推测结果
test[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)Task2(关键词总结)代码:
# 引入分词器
from nltk import word_tokenize, ngrams
# 定义停用词,去掉出现较多,但对文章不关键的词语
stops = [
'will', 'can', "couldn't", 'same', 'own', "needn't", 'between', "shan't", 'very',
'so', 'over', 'in', 'have', 'the', 's', 'didn', 'few', 'should', 'of', 'that',
'don', 'weren', 'into', "mustn't", 'other', 'from', "she's", 'hasn', "you're",
'ain', 'ours', 'them', 'he', 'hers', 'up', 'below', 'won', 'out', 'through',
'than', 'this', 'who', "you've", 'on', 'how', 'more', 'being', 'any', 'no',
'mightn', 'for', 'again', 'nor', 'there', 'him', 'was', 'y', 'too', 'now',
'whom', 'an', 've', 'or', 'itself', 'is', 'all', "hasn't", 'been', 'themselves',
'wouldn', 'its', 'had', "should've", 'it', "you'll", 'are', 'be', 'when', "hadn't",
"that'll", 'what', 'while', 'above', 'such', 'we', 't', 'my', 'd', 'i', 'me',
'at', 'after', 'am', 'against', 'further', 'just', 'isn', 'haven', 'down',
"isn't", "wouldn't", 'some', "didn't", 'ourselves', 'their', 'theirs', 'both',
're', 'her', 'ma', 'before', "don't", 'having', 'where', 'shouldn', 'under',
'if', 'as', 'myself', 'needn', 'these', 'you', 'with', 'yourself', 'those',
'each', 'herself', 'off', 'to', 'not', 'm', "it's", 'does', "weren't", "aren't",
'were', 'aren', 'by', 'doesn', 'himself', 'wasn', "you'd", 'once', 'because', 'yours',
'has', "mightn't", 'they', 'll', "haven't", 'but', 'couldn', 'a', 'do', 'hadn',
"doesn't", 'your', 'she', 'yourselves', 'o', 'our', 'here', 'and', 'his', 'most',
'about', 'shan', "wasn't", 'then', 'only', 'mustn', 'doing', 'during', 'why',
"won't", 'until', 'did', "shouldn't", 'which'
]
# 定义方法按照词频筛选关键词
def extract_keywords_by_freq(title, abstract):
ngrams_count = list(ngrams(word_tokenize(title.lower()), 2)) + list(ngrams(word_tokenize(abstract.lower()), 2))
ngrams_count = pd.DataFrame(ngrams_count)
ngrams_count = ngrams_count[~ngrams_count[0].isin(stops)]
ngrams_count = ngrams_count[~ngrams_count[1].isin(stops)]
ngrams_count = ngrams_count[ngrams_count[0].apply(len) > 3]
ngrams_count = ngrams_count[ngrams_count[1].apply(len) > 3]
ngrams_count['phrase'] = ngrams_count[0] + ' ' + ngrams_count[1]
ngrams_count = ngrams_count['phrase'].value_counts()
ngrams_count = ngrams_count[ngrams_count > 1]
return list(ngrams_count.index)[:5]
## 对测试集提取关键词
test_words = []
for row in test.iterrows():
# 读取第每一行数据的标题与摘要并提取关键词
prediction_keywords = extract_keywords_by_freq(row[1].title, row[1].abstract)
# 利用文章标题进一步提取关键词
prediction_keywords = [x.title() for x in prediction_keywords]
# 如果未能提取到关键词
if len(prediction_keywords) == 0:
prediction_keywords = ['A', 'B']
test_words.append('; '.join(prediction_keywords))
test['Keywords'] = test_words
test[['uuid', 'Keywords', 'label']].to_csv('submit_task2.csv', index=None)除了逻辑回归以外,还可以尝试以下的机器学习模型:KNN、SVM、Xgboost、Lightgbm
Baseline2:Bert微调分类 + 余弦相似度选择关键词
该Baseline运行后的A榜分数为:0.996
Task1(文本分类)代码:
思路:用Bert将文本转换为表征向量,再输入两层全连接网络,使用BCE损失函数进行训练。
#导入前置依赖
import os
import pandas as pd
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
# 用于加载bert模型的分词器
from transformers import AutoTokenizer
# 用于加载bert模型
from transformers import BertModel
from pathlib import Path
batch_size = 16
# 文本的最大长度
text_max_length = 128
# 总训练的epochs数,我只是随便定义了个数
epochs = 100
# 学习率
lr = 3e-5
# 取多少训练集的数据作为验证集
validation_ratio = 0.1
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 每多少步,打印一次loss
log_per_step = 50
# 数据集所在位置
dataset_dir = Path("./基于论文摘要的文本分类与关键词抽取挑战赛公开数据")
os.makedirs(dataset_dir) if not os.path.exists(dataset_dir) else ''
# 模型存储路径
model_dir = Path("./model/bert_checkpoints")
# 如果模型目录不存在,则创建一个
os.makedirs(model_dir) if not os.path.exists(model_dir) else ''
print("Device:", device)
# 读取数据集,进行数据处理
pd_train_data = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/train.csv')
pd_train_data['title'] = pd_train_data['title'].fillna('')
pd_train_data['abstract'] = pd_train_data['abstract'].fillna('')
test_data = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/test.csv')
test_data['title'] = test_data['title'].fillna('')
test_data['abstract'] = test_data['abstract'].fillna('')
pd_train_data['text'] = pd_train_data['title'].fillna('') + ' ' + pd_train_data['author'].fillna('') + ' ' + pd_train_data['abstract'].fillna('')+ ' ' + pd_train_data['Keywords'].fillna('')
test_data['text'] = test_data['title'].fillna('') + ' ' + test_data['author'].fillna('') + ' ' + test_data['abstract'].fillna('')+ ' ' + pd_train_data['Keywords'].fillna('')
# 从训练集中随机采样测试集
validation_data = pd_train_data.sample(frac=validation_ratio)
train_data = pd_train_data[~pd_train_data.index.isin(validation_data.index)]
# 构建Dataset
class MyDataset(Dataset):
def __init__(self, mode='train'):
super(MyDataset, self).__init__()
self.mode = mode
# 拿到对应的数据
if mode == 'train':
self.dataset = train_data
elif mode == 'validation':
self.dataset = validation_data
elif mode == 'test':
# 如果是测试模式,则返回内容和uuid。拿uuid做target主要是方便后面写入结果。
self.dataset = test_data
else:
raise Exception("Unknown mode {}".format(mode))
def __getitem__(self, index):
# 取第index条
data = self.dataset.iloc[index]
# 取其内容
text = data['text']
# 根据状态返回内容
if self.mode == 'test':
# 如果是test,将uuid做为target
label = data['uuid']
else:
label = data['label']
# 返回内容和label
return text, label
def __len__(self):
return len(self.dataset)
train_dataset = MyDataset('train')
validation_dataset = MyDataset('validation')
train_dataset.__getitem__(0)
#获取Bert预训练模型
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
#接着构造我们的Dataloader。
#我们需要定义一下collate_fn,在其中完成对句子进行编码、填充、组装batch等动作:
def collate_fn(batch):
"""
将一个batch的文本句子转成tensor,并组成batch。
:param batch: 一个batch的句子,例如: [('推文', target), ('推文', target), ...]
:return: 处理后的结果,例如:
src: {'input_ids': tensor([[ 101, ..., 102, 0, 0, ...], ...]), 'attention_mask': tensor([[1, ..., 1, 0, ...], ...])}
target:[1, 1, 0, ...]
"""
text, label = zip(*batch)
text, label = list(text), list(label)
# src是要送给bert的,所以不需要特殊处理,直接用tokenizer的结果即可
# padding='max_length' 不够长度的进行填充
# truncation=True 长度过长的进行裁剪
src = tokenizer(text, padding='max_length', max_length=text_max_length, return_tensors='pt', truncation=True)
return src, torch.LongTensor(label)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
validation_loader = DataLoader(validation_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
inputs, targets = next(iter(train_loader))
print("inputs:", inputs)
print("targets:", targets)
#定义预测模型,该模型由bert模型加上最后的预测层组成
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 加载bert模型
self.bert = BertModel.from_pretrained('bert-base-uncased', mirror='tuna')
# 最后的预测层
self.predictor = nn.Sequential(
nn.Linear(768, 256),
nn.ReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, src):
"""
:param src: 分词后的推文数据
"""
# 将src直接序列解包传入bert,因为bert和tokenizer是一套的,所以可以这么做。
# 得到encoder的输出,用最前面[CLS]的输出作为最终线性层的输入
outputs = self.bert(**src).last_hidden_state[:, 0, :]
# 使用线性层来做最终的预测
return self.predictor(outputs)
#定义出损失函数和优化器。这里使用Binary Cross Entropy:
criteria = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 由于inputs是字典类型的,定义一个辅助函数帮助to(device)
def to_device(dict_tensors):
result_tensors = {}
for key, value in dict_tensors.items():
result_tensors[key] = value.to(device)
return result_tensors
#定义一个验证方法,获取到验证集的精准率和loss
def validate():
model.eval()
total_loss = 0.
total_correct = 0
for inputs, targets in validation_loader:
inputs, targets = to_device(inputs), targets.to(device)
outputs = model(inputs)
loss = criteria(outputs.view(-1), targets.float())
total_loss += float(loss)
correct_num = (((outputs >= 0.5).float() * 1).flatten() == targets).sum()
total_correct += correct_num
return total_correct / len(validation_dataset), total_loss / len(validation_dataset)
# 首先将模型调成训练模式
model.train()
# 清空一下cuda缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
# 定义几个变量,帮助打印loss
total_loss = 0.
# 记录步数
step = 0
# 记录在验证集上最好的准确率
best_accuracy = 0
# 开始训练
for epoch in range(epochs):
model.train()
for i, (inputs, targets) in enumerate(train_loader):
# 从batch中拿到训练数据
inputs, targets = to_device(inputs), targets.to(device)
# 传入模型进行前向传递
outputs = model(inputs)
# 计算损失
loss = criteria(outputs.view(-1), targets.float())
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += float(loss)
step += 1
if step % log_per_step == 0:
print("Epoch {}/{}, Step: {}/{}, total loss:{:.4f}".format(epoch+1, epochs, i, len(train_loader), total_loss))
total_loss = 0
del inputs, targets
# 一个epoch后,使用过验证集进行验证
accuracy, validation_loss = validate()
print("Epoch {}, accuracy: {:.4f}, validation loss: {:.4f}".format(epoch+1, accuracy, validation_loss))
torch.save(model, model_dir / f"model_{epoch}.pt")
# 保存最好的模型
if accuracy > best_accuracy:
torch.save(model, model_dir / f"model_best.pt")
best_accuracy = accuracy
#加载最好的模型,然后进行测试集的预测
model = torch.load(model_dir / f"model_best.pt")
model = model.eval()
test_dataset = MyDataset('test')
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
results = []
for inputs, ids in test_loader:
outputs = model(inputs.to(device))
outputs = (outputs >= 0.5).int().flatten().tolist()
ids = ids.tolist()
results = results + [(id, result) for result, id in zip(outputs, ids)]
test_label = [pair[1] for pair in results]
test_data['label'] = test_label
test_data[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)Task2(关键词总结)代码:
思路:先用TF-IDF算法来挑选出一堆候选词,然后再将它们用Bert的embedding来表示,最后将它们逐个与文章摘要和标题embedding比较余弦相似度,选取前top_n个词作为关键词。
# 数据输出和上面一样
# 核心代码如下:
test_words = []
for row in test.iterrows():
# 读取第每一行数据的标题与摘要并提取关键词
# 修改n_gram_range来改变结果候选词的词长大小。例如,如果我们将它设置为(3,3),那么产生的候选词将是包含3个关键词的短语。
n_gram_range = (2,2)
# 这里我们使用TF-IDF算法来获取候选关键词
count = TfidfVectorizer(ngram_range=n_gram_range, stop_words=stops).fit([row[1].text])
candidates = count.get_feature_names_out()
# 将文本标题以及候选关键词/关键短语转换为数值型数据(numerical data)。我们使用BERT来实现这一目的
title_embedding = model.encode([row[1].title])
candidate_embeddings = model.encode(candidates)
# 通过修改这个参数来更改关键词数量
top_n = 15
# 利用文章标题进一步提取关键词
distances = cosine_similarity(title_embedding, candidate_embeddings)
keywords = [candidates[index] for index in distances.argsort()[0][-top_n:]]
if len( keywords) == 0:
keywords = ['A', 'B']
test_words.append('; '.join( keywords))
test['Keywords'] = test_words
test[['uuid', 'Keywords']].to_csv('submit_task2.csv', index=None)Baseline3:ChatGLM2微调
# 导入数据
import pandas as pd
train_df = pd.read_csv('./csv_data/train.csv')
test_df = pd.read_csv('./csv_data/test.csv')
# 制作数据集
res = []
for i in range(len(train_df)):
paper_item = train_df.loc[i]
tmp = {
"instruction": "Please judge whether it is a medical field paper according to the given paper title and abstract, output 1 or 0, the following is the paper title, author and abstract -->",
"input": f"title:{paper_item[1]},abstract:{paper_item[3]}",
"output": str(paper_item[5])
}
res.append(tmp)
import json
with open('paper_label.json', mode='w', encoding='utf-8') as f:
json.dump(res, f, ensure_ascii=False, indent=4)
# 加载训练好的LoRA权重,进行预测
from peft import PeftModel
from transformers import AutoTokenizer, AutoModel, GenerationConfig, AutoModelForCausalLM
model_path = "chatglm2-6b"
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 加载lora权重
# 训练好的LoRA来源于:https://github.com/KMnO4-zx/huanhuan-chat.git
model = PeftModel.from_pretrained(model, 'huanhuan-chat/output/label_xfg').half()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
response
# 预测函数
def predict(text):
response, history = model.chat(tokenizer, f"Please judge whether it is a medical field paper according to the given paper title and abstract, output 1 or 0, the following is the paper title, author and abstract -->{text}", history=[],
temperature=0.01)
return response
# 制作submit
# 预测测试集
from tqdm import tqdm
label = []
for i in tqdm(range(len(test_df))):
test_item = test_df.loc[i]
test_input = f"title:{test_item[1]},author:{test_item[2]},abstract:{test_item[3]}"
label.append(int(predict(test_input)))
test_df['label'] = label
submit = test_df[['uuid', 'Keywords', 'label']]
submit.to_csv('submit.csv', index=False)五、我的打榜过程

如上图所示:(从2023年7月20号参加比赛并开始提交第一次文件,但比赛从6月9号开始,报名得有点儿晚)
A榜 - 0.37775 → 0.97655
1.第一天提交:将Baseline1运行所得的结果文件1和2进行提交,所得到的分数分别为0.37775和0.97655。
结果:A榜分数从0.37775提升到0.97655。
最大的感受:由于0.97655的分数里面包含了官方赠送的0.6分,所以通过Baseline1的方法在提取关键词上的得分只有0.0012分(计算方式:0.37775+0.6-0.97655)。换个说法,测试集共2358条样本,Baseline1在每个样本上提取的所有关键词,将提取正确的关键词全加起来只对了2~3个(计算方式:(0.37775+0.6-0.97655)*2358)。所以严格来说,这次比赛的关键在于子任务2,正如“三、比赛训练集及A榜测试集分析”里面所提到的,这次任务2里面的关键词不能是“提取”,应当是“总结”。
A榜 - 0.97655 → 0.99208
2.第二天提交:基于Bert和BiLSTM,将文本内容使用Bert的embedding进行表示,再接一层BiLSTM对语义进行学习,最后再接一层全连接层作为分类器进行分类。
结果:A榜分数从0.97655提升到0.99208。
最大的感受:BiLSTM在这个数据集上过拟合得有点严重,可能不如LSTM,果断跳船。(也可能是我微调有问题:P)
A榜 - 0.99208 → 0.99720
3.第三天提交(上):考虑到BiLSTM相较于LSTM而言,更容易过拟合从而导致模型性能变差,所以又再基于Bert的embedding基础之上,接入了单层LSTM进行训练,最后再接一层全连接层作为分类器进行分类。
结果:A榜分数从0.99208提升到0.99720。
最大的感受:LSTM
A榜 - 0.99720 → 0.99772
4.第三天提交(下):考虑到Kaggle大佬们霸榜的时候都是用的模型集成,所以我也直接无脑选择三个模型进行集成,而这三个模型分别为:①Bert+LSTM ②Bert+LSTM+KNN ③Longformer+LSTM。使用前者的表征向量,再接一个LSTM或LSTM+KNN进行训练,最后3个模型对每个样本的预测概率进行等权贡献。得分出来的时候,有点喜人(提的分有点少)但也确实能提分hh。
结果:A榜分数从0.9972提升到0.99772。
最大的感受:开始初步信任集成学习
A榜 - 0.99772 → 0.99877
5.第四天提交:延续模型集成的思路,不过这次不再考虑KNN了,稳健性有点差。这次使用7个模型进行集成,所选取的模型为:Bert-base-uncase+LSTM,Bert-large-base+LSTM,Roberta-base+LSTM,Roberta-large+LSTM,Deberta-v3-base+LSTM,Deberta-v3-large+LSTM,Longformer+LSTM。具体模型结构和4.差不多,不一样的地方在于不再接入KNN。使用前者的表征向量,再接一个LSTM与全连接层进行训练,最后7个模型对每个样本的预测概率进行等权贡献。
结果:A榜分数从0.99772提升到0.99877。
最大的感受:集成学习,拿高分的利器。如果不出意外,我下一步应该会去堆更猛的料:P
-截止2023年7月22号晚上22:30,我的A榜排名暂为:31名

-截止2023年7月23号凌晨00:01,我的A榜排名暂为:12名

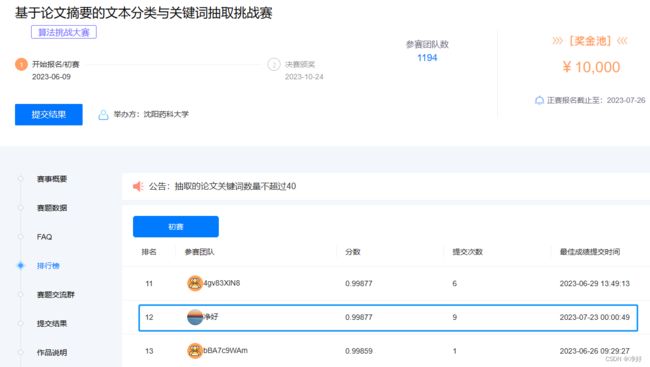
六、注意事项及答疑学习
注意事项
-
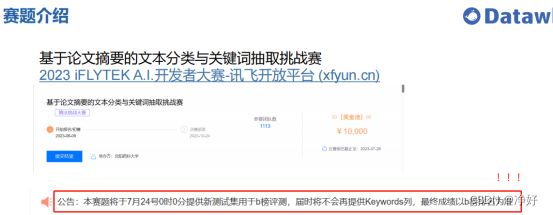
A榜相当于是前置的比赛,来自测试集文件test.csv有每个样本的Keywords,相当于A榜只需要完成分类任务即可。
-
B榜在24日开启,相当于是正式开始比赛,需要完成两个任务:分类+关键词提取。
-
在Paddle的AI Studio上部署的线上Baseline版本使用传统的NLP方法,对文本的表征方法为BOW/TF-IDF(相当于是提取特征),算法上使用逻辑回归模型对特征进行拟合。
-
运行线上版本的Baseline会产生两个提交文件,由于提交文件1的Keywords来源于test.csv,所以直接提交会有0.976555的分数,而提交文件2的Keywords由Baseline直接提取,分数提交后会有0.37775的分数。
-
除了在Paddle的AI Studio上部署的线上Baseline版本,还有两个Baseline版本:1.预训练微调 2.大语言模型微调。而由于平台限制,Pytorch版本的Bert和大语言模型ChatGLM2-6b微调的代码要么需要比较麻烦地部署在AI Studio,要么就需要使用本机来运行。建议使用本机来运行。
-
而在运行本地Baseline的时候import nltk可能会遇到punkt还没存放在示例目录的问题。在参考博客的链接当中可寻找到解决方案:https://blog.csdn.net/qq_41297934/article/details/111310009

7.在Task2(关键词总结)里面,由于关键词的不一定出现在文本内容里面,所以可能还涉及到文本生成的领域。
8.在Task2(关键词总结)里面,线上baseline的思路是,先去除停用词,再使用2-gram针标题+摘要的文本内容来挑选关键词,最后再进一步统计摘要出现的高频次关键词并结合标题文本来加入最后需要确定的关键词。
9.在Task2(关键词总结)里面,本机Bert的baseline算法是先通过TF-IDF来挑选候选词,再通过将它们转换为transformer的表征向量来计算余弦相似度,最后选取余弦相似度最高的前N个词作为关键词。
(所使用到的模型为xlm-r-distilroberta-base-paraphrase-v1,这个可以输入更大的分词长度,而bert-base-uncase最多只有512的分词长度)。
答疑学习
1.如何评估模型?
答:将训练集分割为两部分(训练集:验证集),这两部分都需要较多的样本数量,使用分割后的训练集来训练模型,再使用验证集来验证模型性能,我们可以对比二者loss的变化趋势以便于更好的评估模型和调参。
2.训练模型是要将官方提供的所有训练数据都拿去训练吗?
答:大可不必,虽然训练模型的时候当然是越多数据越好,但是我们需要拿出相当一部分样本来验证已训练好的模型,而少一部份训练数据其实对模型的性能影响不会太大。也有其它更好的方法来应对这个问题,如:K折交叉验证。
3.训练bert的时候,由于输入的文本是固定长度的,并且这次比赛的数据集文本内容最小长度是20左右,最大长度是1400左右,平均长度是240左右,那么确定多大的长度可以取得更好的效果呢?
答:看电脑性能,长度越大,考虑到的语义信息就越丰富,而根据这次比赛的文本长度可以考虑640这个数字。
->以上内容修改源于我在Datawhale夏令营的笔记:Datawhale AI夏令营 - NLP实践:基于论文摘要的文本分类与关键词抽取挑战赛——五天冲A榜 - 飞书云文档 (feishu.cn)
至此、
谢谢你能阅读到它的结尾。
