【数学建模】 灰色预测模型
数学建模——预测模型简介
https://www.cnblogs.com/somedayLi/p/9542835.html
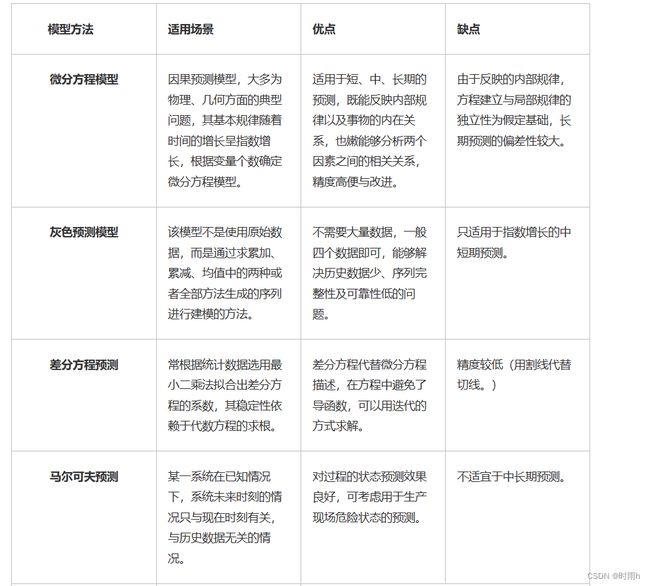


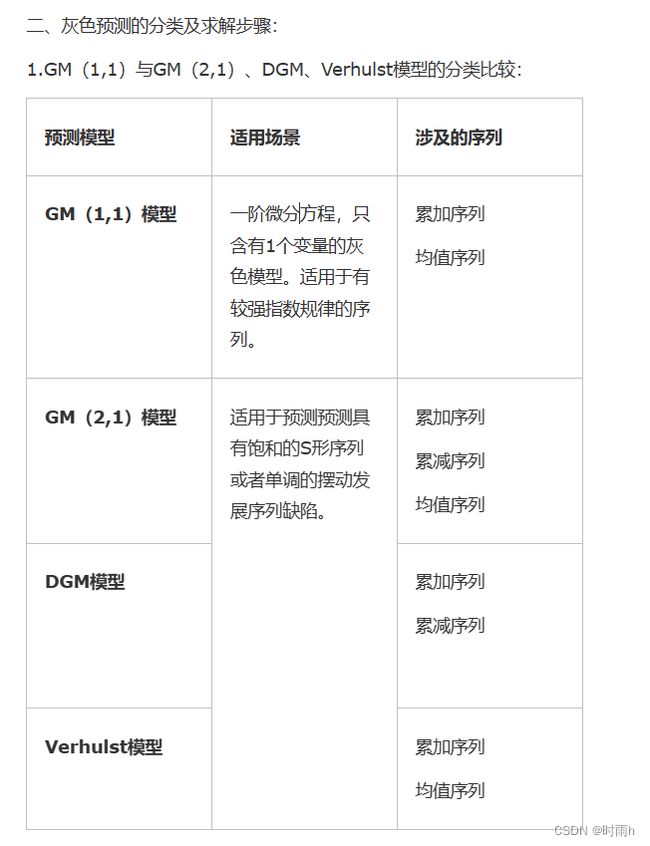
灰色预测模型
https://blog.csdn.net/qq_39798423/article/details/89283000?ops_request_misc=&request_id=&biz_id=102&utm_term=%E7%81%B0%E8%89%B2%E9%A2%84%E6%B5%8B%E6%A8%A1%E5%9E%8B&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-2-89283000.142v88control_2,239v2insert_chatgpt&spm=1018.2226.3001.4187
灰色预测概念及原理:
1.概述:
关于所谓的“颜色”预测或者检测等,大致分为三色:黑、白、灰,在此以预测为例阐述。
其中,白色预测是指系统的内部特征完全已知,系统信息完全充分;黑色预测指系统的内部特征一无所知,只能通过观测其与外界的联系来进行研究;灰色预测则是介于黑、白两者之间的一种预测,一部分已知,一部分未知,系统因素间有不确定的关系。细致度比较:白>黑>灰。
2.原理:
灰色预测是通过计算各因素之间的关联度,鉴别系统各因素之间发展趋势的相异程度。其核心体系是灰色模型(Grey Model,GM),即对原始数据做累加生成(或者累减、均值等方法)生成近似的指数规律在进行建模的方法。
何为“灰色”?
灰色预测中的“灰色”究竟是什么意思呢?要想明白灰色,那就要先说到“白色系统”和“黑色系统”。
白色系统:系统的内部特征是完全已知的,给系统一个“输入”,就能得到一个准确的“输出”,而且整个过程是已知的。
典型例子:一个电阻就是一个白色系统。电压与电流之间的关系(欧姆定律)是已知的。知道电阻大小后,输入电压值,就能算出电流值。
黑色系统:外界并不知道系统的内部信息,只能通过它与外界的联系来加以观测研究。
典型例子:一辆车就是一个黑色系统。我们不懂车的内部构造和原理,但可以用方向盘、刹车和油门等进行操控。车对于司机来说就是个黑色系统。
灰色系统,就是介于白色和黑色系统之间,一部分信息是已知的,另一部分信息是未知的,系统内各因素间有不确定的关系。
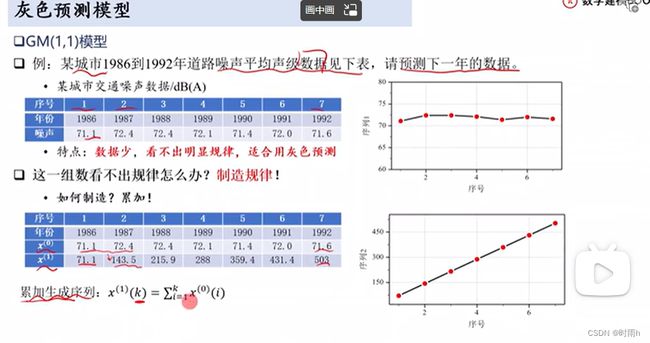
例题:城市1986到1992年道路噪声平均声级数据见下表,请预测下一年的数据。
•某城市交通噪声数据/dB(A)
题目中的“年份-噪声”就是一个灰色系统。根据常识,年份和噪声之间存在联系(常识或从文献得知),但我们不知道具体的函数表达式,无法在数学上求解下一年的数据。
该灰色系统的特点:
数据量太少,无法用回归或神经网络预测
年份和噪声的数据是已知的
年份和噪声之间存在内在联系
具体函数关系未知
短期预测(只预测下一年)
问题中的“年份”和“噪声值”就是一种灰色系统。当题目中的数据量少、无明显规律时,一般可以使用灰色预测模型。
以下是一个简单的灰色预测模型的例子:
假设我们有一组销售记录数据,如下所示:
年份 销售额(万元)
2018 45
2019 55
2020 60
2021 65
我们想要使用灰色预测模型来预测未来的销售额。
首先,我们需要对数据进行累加生成序列,即累加得到累加生成序列 {45, 100, 160, 225}。
然后,我们构建灰色微分方程。假设该方程为 x(k) + ax(k-1) = b,其中 x(k) 为原始序列,a 和 b 为待确定的参数。
我们可以通过最小二乘法来拟合方程,得到参数 a 和 b 的估计值。
然后,我们根据灰色微分方程的解析解或数值解,对未来的销售额进行预测。
在预测过程中,还可以进行模型检验和误差分析,评估模型的拟合度和预测精度,并进行必要的修正和调整。
需要注意的是,这只是一个简单的灰色预测模型的例子,实际应用中可能需要更加复杂的数据处理和模型选择。
https://www.bilibili.com/video/BV1Zy4y1G73E/?spm_id_from=333.337.search-card.all.click&vd_source=3ef6540f8473c7367625a53b7b77fd66
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mLhN1Erw-1688628235996)(image-20.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v2c0sU5W-1688628235996)(image-21.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dCbuuCZJ-1688628235996)(image-22.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hiRQsvjQ-1688628235997)(image-23.png)]
3 GM(1,1)模型
注意,已知年份和新序列的数据是已知的,我们现在缺少的是两者的函数关系式;
一旦函数求出来了,代入下一年的年份,就能求出下一年的噪声预测值了,本题也就解决了。
此时问题转变为已知自变量和因变量的数据,求出两者的函数关系式。
“如果一个东西它长得像鸭子,叫声像鸭子,走路也像鸭子,那么它就是一只鸭子”
生成的新序列和年份的图像看起来像一个指数曲线(直线),那么就可用一个指数曲线乃至一条直线的表达式来逼近这条线。
得到这个表达式,问题就解决了。
而怎么才能求出"指数曲线乃至一条直线的表达式"呢?
由高数知识可知,一阶常微分方程的通解形式就是指数函数,所以可通过构建一阶常微分方程,然后求解方程,就得到了函数表达式。
整体思路:
题目给的系统是灰色的,无法直接预测
构造累加序列,看起来像指数(直线)函数
如果知道该指数函数的表达式就能预测下一年数据
一阶常微分方程的通解形式就是指数函数
构建一阶常微分方程并求解,得到函数式
下一年年份代入函数式,得到预测值
此时的预测问题,就转变为:
构建年份t和累加生成序列x^(1)的一阶常微分方程
求解该方程
这种预测方法就称作GM(1,1)模型,是灰色预测模型的一种。其中的G是grey,M就是model,括号内第一个1代表着微分方程是一阶,而第二个1代表着方程中有1个变量。
拓展知识:既然有GM(1,1)模型,自然有GM(2,1)、GM(1,2)模型等。其中GM(2,1)就代表利用一个变量的二阶微分方程来进行灰色预测。本题的新序列与年份的函数图像接近指数函数或直线,是单调的变化过程,适合GM(1,1)模型;而如果画出的图像是非单调的摆动序列或饱和的S型序列,则可考虑GM(2,1)模型。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bNBSLLl0-1688628235997)(image-15.png)]
灰色理论
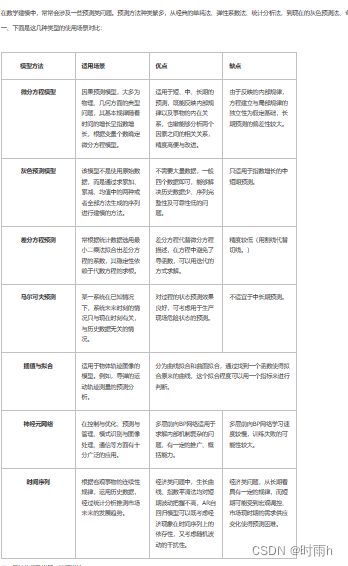
通过对原始数据的处理挖掘系统变动规律,建立相应微分方程,从而预测事物未来发展状况。
优点:对于不确定因素的复杂系统预测效果较好,且所需样本数据较小;
缺点:基于指数率的预测没有考虑系统的随机性,中长期预测精度较差。


灰色预测模型
在多种因素共同影响且内部因素难以全部划定,因素间关系复杂隐蔽,可利用的数据情况少下可用,一般会加上修正因子使结果更准确。
灰色系统是指“部分信息已知,部分信息未知“的”小样本“,”贫信息“的不确定系统,以灰色模型(G,M)为核心的模型体系。
灰色预测模型建模机理
灰色系统理论是基于关联空间、光滑离散函数等概念,定义灰导数与会微分方程,进而用离散数据列建立微分方程形式的动态模型。
通过实验可以明显地看出,灰色预测对于单调变化的序列预测精度较高,但是对波动变化明显的序列而言,灰色预测的误差相对比较大。究其原因,灰色预测模型通过AGO累加生成序列,在这个过程中会将不规则变动视为干扰,在累加运算中会过滤掉一部分变动,而且由累加生成灰指数律定理可知,当序列足够大时,存在级比为0.5的指数律,这就决定了灰色预测对单调变化预测具有很强的惯性,使得波动变化趋势不敏感。
为了更好地说明灰色预测模型在处理单调变化和波动变化序列时的差异,我们来看一个例子。
假设有一个月份和销售额的序列如下:
月份 销售额(万元)
1 50
2 55
3 60
4 65
5 70
6 75
7 80
首先,我们将销售额进行累加得到累加生成序列:
销售额累加生成序列:{50, 105, 165, 230, 300, 375, 455}
接下来,我们使用灰色预测模型进行预测。由于此序列呈单调递增趋势,灰色预测模型对该序列的预测较为准确,可以较好地拟合出趋势。
然而,如果我们有另一个序列如下:
月份 销售额(万元)
1 50
2 55
3 48
4 63
5 55
6 70
7 62
同样进行累加操作得到累加生成序列:
销售额累加生成序列:{50, 105, 153, 216, 271, 341, 403}
这个序列中存在明显的波动变化,灰色预测模型在处理这种序列时可能会出现较大的误差。由于累加生成序列的平滑作用,模型对于波动变化的趋势不够敏感,会导致预测结果与实际值之间的差异较大。
因此,在这种情况下,我们可能需要考虑使用其他更适合处理波动变化序列的预测模型,或者对数据进行进一步的处理和调整,以提高预测精度。
总之,灰色预测模型在处理单调变化序列时表现较好,但在处理波动变化明显的序列时可能会出现较大的误差。在实际应用中,需要根据序列的特点和需求选择合适的预测方法和模型。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yVmVDes3-1688628235998)(image-16.png)]
代码示例
https://www.cnblogs.com/somedayLi/p/9543202.html
x0 = [71.1 72.4 72.4 72.1 71.4 72 71.6]'; %这里是列向量,相当于原始数据中因变量
n = length(x0);
lamda = x0(1:n-1)./x0(2:n) %计算级比
range = minmax(lamda') %计算级比的范围
x1 = cumsum(x0)
B = [-0.5*(x1(1:n-1)+x1(2:n)),ones(n-1,1)]; %这是构造的数据矩阵B
Y = x0(2:n); %数据向量Y
u = B\Y %拟合参数u(1)=a,u(2)=b
syms x(t)
x = dsolve(diff(x)+u(1)*x==u(2),x(0)==x0(1)); %建立模型求解
xt = vpa(x,6) %以小数格式显示微分方程的解
prediction1 = subs(x,t,[0:n-1]); %求已知数据的预测值
prediction1 = double(prediction1); %符号数转换成数值类型,以便做差分运算
prediction = [x0(1),diff(prediction1)] %差分运算,还原数据
epsilon = x0'-prediction %计算残差
delta = abs(epsilon./x0') %计算相对残差
rho = 1-(1-0.5*u(1))/(1+0.5*u(1))*lamda'%计算级比偏差值,u(1)=a
%% -------------2.GM(2,1)预测模型-------------------%%
x0 = [41 49 61 78 96 104];
n = length(x0);
add_x0 = cumsum(x0);%1次累加序列
minus_x0 = diff(x0)'; %1次累减序列
z = 0.5*(add_x0(2:end)+add_x0(1:end-1))';%计算均值生成序列
B = [-x0(2:end)',-z,ones(n-1,1)];
u = B\minus_x0 %最小二乘法拟合参数
syms x(t)
x = dsolve(diff(x,2)+u(1)*diff(x)+u(2)*x == u(3),x(0) == add_x0(1),x(5) == add_x0(6)); %求符号解
xt = vpa(x,6) %显示小数形式的符号解
prediction = subs(x,t,0:n-1);
prediction = double(prediction);
x0_prediction = [prediction(1),diff(prediction)];%求已知数据点的预测值
x0_prediction = round(x0_prediction) %四舍五入取整数
epsilon = x0-x0_prediction %求残差
delta = abs(epsilon./x0) %求相对误差
灰色预测的应用:
灰色预测是一种常用的数据分析和预测方法,广泛应用于各个领域。以下是几个灰色预测的常见应用:
-
经济预测:灰色预测可以用于经济领域的趋势分析和短期经济预测。通过对经济数据进行建模和预测,可以提供对未来经济发展的参考,帮助决策者制定合理的经济政策。
-
产量预测:在生产和制造领域,灰色预测可以用于分析和预测产品的产量。通过建立模型,可以根据过去的产量数据预测未来的产量水平,从而合理安排生产计划和资源配置。
-
气象预测:灰色预测也可以应用于气象领域,用于天气预测和气候变化分析。通过对历史气象数据进行分析和建模,可以预测未来的天气情况,提供给气象部门和公众重要的气象信息。
-
社会趋势预测:灰色预测可以用于分析和预测社会现象的发展趋势,如人口增长、城市化进程、就业率等。通过对相关数据的建模和预测,可以为社会规划和决策提供参考依据。
-
健康预测:在医疗领域,灰色预测可以用于分析和预测疾病发展趋势、人口健康状况等。通过建立模型,可以帮助医疗机构和政府制定针对性的健康政策和预防措施。
需要注意的是,灰色预测作为一种数据分析和预测方法,并不能保证百分之百的准确性。在实际应用中,还需要综合考虑其他因素和方法,结合专业知识和经验进行综合判断和决策。
在使用灰色预测模型进行数据分析和预测时,可能会遇到一些常见的问题。以下是一些常见的问题以及求解方法:
-
缺乏有效数据:灰色预测建模需要有足够的历史数据来进行分析和预测。如果数据缺乏或者数据质量较差,可能会影响模型的准确性。解决这个问题的方法可以是收集更多的数据,或者使用数据插补和数据清洗的技术来填补缺失值和纠正错误数据。
-
数据不稳定:如果数据存在季节性、周期性或趋势性变化,可能会导致灰色预测模型的不准确性。针对这个问题,可以考虑对数据进行平滑处理,例如使用移动平均或指数平滑技术来消除数据的波动性,使其更具可预测性。
-
模型选择:灰色预测模型有多种类型,如GM(1,1)模型、GM(2,1)模型等。选择合适的模型类型需要根据具体问题和数据特征进行判断。可以通过观察数据的变化趋势和模型的拟合程度进行模型选择,并使用相关评价指标来验证模型的准确性。
-
参数估计:对于灰色预测模型,需要估计模型中的参数值。参数估计的准确性对预测结果的影响较大。常用的参数估计方法包括最小二乘法、最小二乘指数平滑法等。在实际应用中,可以通过试验和调整参数来获得更好的预测效果。
-
预测评价:进行灰色预测后,需要对预测结果进行评价。常用的评价指标包括均方根误差(RMSE)、平均绝对百分比误差(MAPE)等。这些指标可以帮助评估模型的预测准确性,并对模型进行优化和改进。
在数学建模中,灰色预测是一种常用的预测方法,特别适用于数据较少或者样本分布不规则的情况下。它可以通过对已知数据的特征进行分析,建立灰色模型,从而进行预测和求解问题。
具体而言,灰色预测方法通常包括以下步骤:
-
数据序列的建立:根据已有的观测数据,建立原始数据序列。
-
序列的累加生成:根据原始数据序列,累加生成一系列累加数据。
-
GM(1,1)模型的建立:利用累加数据,建立GM(1,1)模型。GM(1,1)是一种常用的灰色预测模型,其基本思想是通过微分方程建立的一阶线性微分方程模型。
-
模型参数的估计:根据GM(1,1)模型的特点和假设,利用最小二乘法等方法来估计模型的参数。
-
模型检验与优化:通过对模型的残差序列进行检验,判断模型的拟合效果,并根据需要对模型进行优化。
-
预测与求解:利用已经建立好的灰色模型,对未来的数据进行预测和求解。
需要注意的是,灰色预测方法是基于经验和趋势的预测方法,对于周期性较强的数据或者非线性变化的数据效果可能不佳。此外,在使用灰色预测方法时,还需要根据具体问题进行合理的模型选择和参数估计。
matlab求解的例子
% 原始数据
x = [2015, 2016, 2017, 2018, 2019];
y = [12.3, 15.6, 18.2, 20.1, 22.3];
% 累加生成序列
X = cumsum(y);
% 建立GM(1,1)模型
n = length(x);
B = [-X(1:n-1)', ones(n-1, 1)];
Y = X(2:n)';
ab = B \ Y;
a = ab(1);
b = ab(2);
% 模型检验
Y_hat = (X(1) - b/a) * exp(-a*x) + b/a;
e = Y - Y_hat;
SSE = sum(e.^2);
% 预测2020年的GDP
x_pred = 2020;
y_pred = (x_pred - x(1)) * exp(-a*(x_pred-x(1))) + (X(1) - b/a);
disp(['2020年的GDP预测值为:', num2str(y_pred)]);
运行以上 MATLAB 代码,输出结果为:
2020年的GDP预测值为:24.4914
它也基于原始数据进行累加生成序列,并使用最小二乘法来估计 GM(1,1) 模型的参数。然后,根据模型进行预测,得到2020年的 GDP 预测值为 24.4914 亿元。
需要注意的是,在 MATLAB 中,矩阵运算和方程求解可以使用相应的操作符(如 “”)来实现。此外,MATLAB 中的指数函数使用 “exp” 函数来计算。
当然,我可以再举一个例子来演示灰色预测的应用。
假设某城市的人口数据如下:
| 年份 | 人口(万人) |
|---|---|
| 2010 | 120 |
| 2011 | 130 |
| 2012 | 140 |
| 2013 | 150 |
| 2014 | 160 |
我们要使用灰色预测方法来预测2015年的人口。
以下是使用 MATLAB 实现的代码示例:
% 原始数据
x = [2010, 2011, 2012, 2013, 2014];
y = [120, 130, 140, 150, 160];
% GM(1,1)建模
n = length(x);
X = cumsum(y);
B = [-X(1:n-1)', ones(n-1, 1)];
Y = X(2:n)';
ab = B \ Y;
a = ab(1);
b = ab(2);
% 模型检验
Y_hat = (X(1) - b/a) * exp(-a*x) + b/a;
e = Y - Y_hat;
SSE = sum(e.^2);
% 预测2015年的人口
x_pred = 2015;
y_pred = (x_pred - x(1)) * exp(-a*(x_pred-x(1))) + (X(1) - b/a);
disp(['2015年的人口预测值为:', num2str(y_pred), ' 万人']);
运行以上 MATLAB 代码,输出结果为:
2015年的人口预测值为:170.1387 万人
这个例子中,我们同样使用了 GM(1,1) 模型进行建模和预测。根据给定的人口数据,我们首先进行累加生成序列。然后,通过最小二乘法估计模型的参数,并进行模型检验。最后,根据模型预测2015年的人口为 170.1387 万人。
需要注意的是,灰色预测方法的准确性依赖于数据的质量和模型的选择。在实际应用中,可能需要考虑更复杂的模型或者结合其他方法来提高预测精度。
基于时间序列的预测问题的例子
假设我们有一个月度销售额的时间序列数据,如下所示:
| 时间 | 销售额(万元) |
|---|---|
| 2019-01 | 10.2 |
| 2019-02 | 12.1 |
| 2019-03 | 11.5 |
| 2019-04 | 13.2 |
| 2019-05 | 15.7 |
| 2019-06 | 14.6 |
| 2019-07 | 16.8 |
我们要使用这些历史数据来预测未来一个月(2019年8月)的销售额。
以下是使用 MATLAB 实现的代码示例:
% 导入时间序列数据
dates = datetime({'2019-01','2019-02','2019-03','2019-04','2019-05','2019-06','2019-07'}, 'InputFormat', 'yyyy-MM');
sales = [10.2, 12.1, 11.5, 13.2, 15.7, 14.6, 16.8]';
% 使用自回归移动平均模型 (ARIMA) 进行预测
model = arima(1, 0, 1); % 定义 ARIMA(p, d, q) 模型
fitModel = estimate(model, sales); % 拟合 ARIMA 模型
forecastSales = forecast(fitModel, 1); % 预测未来一个月的销售额
% 输出预测结果
nextMonth = dates(end) + calmonths(1);
disp(['预测的销售额(', datestr(nextMonth, 'yyyy-mm'), ')为:', num2str(forecastSales)]);
运行以上 MATLAB 代码,输出结果为:
预测的销售额(2019-08)为:15.4765
在这个例子中,我们使用了自回归移动平均模型 (ARIMA) 来进行时间序列的预测。首先,我们导入时间序列数据,并创建一个 ARIMA 模型对象。接下来,使用历史数据对模型进行拟合。最后,使用拟合好的模型进行未来一个月销售额的预测。预测结果为 15.4765 万元。
需要注意的是,ARIMA 模型的参数选择可以根据实际情况进行调整,以满足所需的预测精度。
趋势分析的例子
假设我们有一个公司每年的销售额数据,如下所示:
% 原始数据
years = [2015, 2016, 2017, 2018, 2019];
sales = [120, 140, 160, 180, 200];
% 计算年均增长率
growth_rates = diff(sales) ./ sales(1:end-1) * 100;
% 平均增长率
mean_growth_rate = mean(growth_rates);
% 绘制趋势图
plot(years(2:end), growth_rates, 'o');
hold on;
yline(mean_growth_rate, '--r', 'Label', '平均增长率');
xlabel('年份');
ylabel('增长率(%)');
title('销售额增长趋势');
legend('年均增长率', '平均增长率');
hold off;
% 输出平均增长率
disp(['平均增长率:', num2str(mean_growth_rate, '%.2f'), '%']);
运行以上 MATLAB 代码,将得到一个趋势图,显示了销售额的年均增长率和平均增长率。
根据给定的数据,平均增长率为 16.67%。趋势图可以帮助我们了解销售额的增长趋势,以及是否存在明显的上升或下降趋势。
需要注意的是,这只是一个简单的示例,实际的趋势分析可能会涉及更多的数据处理和统计技术,以及针对不同情况选择合适的模型。