【C语言学习】变量和数据类型
基本介绍
数据是放在内存中的,在内存中存取数据要明确三件事情:数据存储在哪里(内存地址)、数据的长度以及数据的处理方式(数据类型)。
变量名不仅仅是为数据起了一个好记的名字,还告诉我们数据存储在哪里,使用数据时,只要提供变量名即可;而数据类型则指明了数据的长度和处理方式。所以诸如int n;、char c;、float money;这样的形式就确定了数据在内存中的所有要素。
变量可以理解为内存地址的别名
输出各种类型的数据
printf("Hello,C!");
int abc=999;
printf("%d", abc);
int abc=999;
printf("The value of abc is %d !", abc);
int a = 100;
int b = 200;
int c = 300;
printf("a=%d, b=%d, c=%d", a, b, c);
#include
int main()
{
int n = 100;
char c = '@'; //字符用单引号包围,字符串用双引号包围
float money = 93.96;
printf("n=%d, c=%c, money=%f\n", n, c, money);
return 0;
}
%d称为格式控制符,它指明了以何种形式输出数据。格式控制符均以%开头,后跟其他字符。%d 表示以十进制形式输出一个整数。除了 %d,printf 支持更多的格式控制,例如:
-
%c:输出一个字符。c 是 character 的简写。
-
%s:输出一个字符串。s 是 string 的简写。
-
%f:输出一个小数。f 是 float 的简写。
如何在字符串中书写长文本
puts(
"C语言中文网,一个学习C语言和C++的网站,他们坚持用工匠的精神来打磨每一套教程。"
"坚持做好一件事情,做到极致,让自己感动,让用户心动,这就是足以传世的作品!"
"C语言中文网的网址是:http://c.biancheng.net"
);
整数(short,int,long)
short、int、long 是C语言中常见的整数类型,其中 int 称为整型,short 称为短整型,long 称为长整型。
整型的长度
C语言并没有严格规定 short、int、long 的长度,只做了宽泛的限制:
-
short 至少占用 2 个字节。
-
int 建议为一个机器字长。32 位环境下机器字长为 4 字节,64 位环境下机器字长为 8 字节。
-
short 的长度不能大于 int,long 的长度不能小于 int。
总结起来,它们的长度(所占字节数)关系为:
2 ≤ short ≤ int ≤ long
这就意味着,short 并不一定真的”短“,long 也并不一定真的”长“,它们有可能和 int 占用相同的字节数。
在 64 位环境下,不同的操作系统会有不同的结果,如下所示:
| 操作系统 | short | int | long |
|---|---|---|---|
| Win64(64位 Windows) | 2 | 4 | 4 |
| 类Unix系统(包括 Unix、Linux、Mac OS、BSD、Solaris 等) | 2 | 4 | 8 |
sizeof 操作符
获取某个数据类型的长度可以使用 sizeof 操作符
#include
int main() {
short a = 1;
int b = 10;
int short_length = sizeof a;
int int_length = sizeof(b);
int long_length = sizeof(long);
int char_length = sizeof(char);
printf("short=%d,int=%d,long=%d,char=%d", short_length, int_length, long_length, char_length);
return 0;
/*
short=2,int=4,long=4,char=1
*/
}
sizeof 用来获取某个数据类型或变量所占用的字节数,如果后面跟的是变量名称,那么可以省略( ),如果跟的是数据类型,就必须带上( )。
sizeof 是C语言中的操作符,不是函数,所以可以不带( )
不同整型的输出
使用不同的格式控制符可以输出不同类型的整数,它们分别是:
-
%hd用来输出 short int 类型,hd 是 short decimal 的简写; -
%d用来输出 int 类型,d 是 decimal 的简写; -
%ld用来输出 long int 类型,ld 是 long decimal 的简写。
为什么short decimal的简写不是%sd而是%hd?
因为%s表示的是string,此时跟在后面的d会被视为普通字符串,所以选用%hd作为简写。
#include
int main() {
short a = 10;
int b = 100;
long c = 65536;
printf("a=%hd,b=%d,c=%ld", a, b, c);
return 0;
}
当使用%d输出 short,或者使用%ld输出 short、int 时,不管值有多大,都不会发生错误,因为格式控制符足够容纳这些值。
当使用%hd输出 int、long,或者使用%d输出 long 时,如果要输出的值比较小(就像上面的情况),一般也不会发生错误,如果要输出的值比较大,就很有可能发生错误(溢出)。
#include
int main()
{
int m = 306587;
long n = 28166459852;
printf("m=%hd, n=%hd\n", m, n);
printf("n=%d\n", n);
return 0;
}
二进制数、八进制数和十六进制数
表示
二进制
二进制由 0 和 1 两个数字组成,使用时必须以0b或0B(不区分大小写)开头,例如:
//合法的二进制
int a = 0b101; //换算成十进制为 5
int b = -0b110010; //换算成十进制为 -50
int c = 0B100001; //换算成十进制为 33
//非法的二进制
int m = 101010; //无前缀 0B,相当于十进制
// int n = 0B410; //4不是有效的二进制数字
标准的C语言并不支持上面的二进制写法,只是有些编译器自己进行了扩展,才支持二进制数字。换句话说,并不是所有的编译器都支持二进制数字,只有一部分编译器支持,并且跟编译器的版本有关系。
八进制
八进制由 0~7 八个数字组成,使用时必须以0开头(注意是数字 0,不是字母 o),例如:
//合法的八进制数
int a = 015; //换算成十进制为 13
int b = -0101; //换算成十进制为 -65
int c = 0177777; //换算成十进制为 65535
//非法的八进制
int m = 256; //无前缀 0,相当于十进制
//int n = 03A2; //A不是有效的八进制数字
十六进制
十六进制由数字 0~9、字母 A~F 或 a~f(不区分大小写)组成,使用时必须以0x或0X(不区分大小写)开头,例如:
//合法的十六进制
int a = 0X2A; //换算成十进制为 42
int b = -0XA0; //换算成十进制为 -160
int c = 0xffff; //换算成十进制为 65535
//非法的十六进制
//int m = 5A; //没有前缀 0X,是一个无效数字
//int n = 0X3H; //H不是有效的十六进制数字
输出
| short | int | long | |
|---|---|---|---|
| 八进制 | %ho | %o | %lo |
| 十进制 | %hd | %d | %ld |
| 十六进制 | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
十六进制数字的表示用到了英文字母,有大小写之分,要在格式控制符中体现出来:
-
%hx、%x 和 %lx 中的
x小写,表明以小写字母的形式输出十六进制数; -
%hX、%X 和 %lX 中的
X大写,表明以大写字母的形式输出十六进制数。
八进制数字和十进制数字不区分大小写,所以格式控制符都用小写形式。如果想使用大写形式,那么行为是未定义的:
-
有些编译器支持大写形式,只不过行为和小写形式一样;
-
有些编译器不支持大写形式,可能会报错,也可能会导致奇怪的输出。
虽然部分编译器支持二进制数字的表示,但是却不能使用 printf 函数输出二进制。
输出时加上前缀
区分不同进制数字的一个简单办法就是,在输出时带上特定的前缀。在格式控制符中加上#即可输出前缀,例如 %#x、%#o、%#lX、%#ho 等
#include
int main() {
short a = 0b1010110; //二进制数字
int b = 02713; //八进制数字
long c = 0X1DAB83; //十六进制数字
printf("a=%#ho, b=%#o, c=%#lo\n", a, b, c); //以八进制形似输出
printf("a=%hd, b=%d, c=%ld\n", a, b, c); //以十进制形式输出
printf("a=%#hx, b=%#x, c=%#lx\n", a, b, c); //以十六进制形式输出(字母小写)
printf("a=%#hX, b=%#X, c=%#lX\n", a, b, c); //以十六进制形式输出(字母大写)
return 0;
/*
a=0126, b=02713, c=07325603
a=86, b=1483, c=1944451
a=0x56, b=0x5cb, c=0x1dab83
a=0X56, b=0X5CB, c=0X1DAB83
*/
}
正负数及其输出
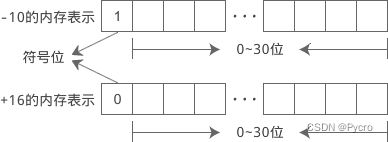
符号也是数字的一部分,也要在内存中体现出来。符号只有正负两种情况,用1位(Bit)就足以表示;C语言规定,把内存的最高位作为符号位。以 int 为例,它占用 32 位的内存,0~30 位表示数值,31 位表示正负号。如下图所示:

C语言规定,在符号位中,用 0 表示正数,用 1 表示负数。例如 int 类型的 -10 和 +16 在内存中的表示如下:
如果不希望设置符号位,可以在数据类型前面加上 unsigned 关键字,例如:
unsigned short a = 12;
unsigned int b = 1002; // 可以省略int,简写成unsigned b = 1002;
unsigned long c = 9892320;
这样,short、int、long 中就没有符号位了,所有的位都用来表示数值,正数的取值范围更大了。这也意味着,使用了 unsigned 后只能表示正数,不能再表示负数了。
如果将一个数字分为符号和数值两部分,那么不加 unsigned 的数字称为有符号数,能表示正数和负数,加了 unsigned 的数字称为无符号数,只能表示正数。
unsigned int 可以简写成unsigned
无符号数的输出
| unsigned short | unsigned int | unsigned long | |
|---|---|---|---|
| 八进制 | %ho | %o | %lo |
| 十进制 | %hu | %u | %lu |
| 十六进制 | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
严格来说,格式控制符和整数的符号是紧密相关的,具体就是:
-
%d 以十进制形式输出有符号数;
-
%u 以十进制形式输出无符号数;
-
%o 以八进制形式输出无符号数;
-
%x 以十六进制形式输出无符号数。
下表全面地总结了不同类型的整数,以不同进制的形式输出时对应的格式控制符(--表示没有对应的格式控制符)。
| short | int | long | unsigned short | unsigned int | unsigned long | |
|---|---|---|---|---|---|---|
| 八进制 | – | – | – | %ho | %o | %lo |
| 十进制 | %hd | %d | %ld | %hu | %u | %lu |
| 十六进制 | – | – | – | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
对于一个有符号的正数,它的符号位是 0,当按照无符号数的形式读取时,符号位就变成了数值位,但是该位恰好是 0 而不是 1,所以对数值不会产生影响,这就好比在一个数字前面加 0,有多少个 0 都不会影响数字的值。
可以说,“有符号正数的最高位是 0”这个巧合才使得 %o 和 %x 输出有符号数时不会出错。
%后接一个字母时,表示的是进制或符号,接两个字母时,前一个表示整形范围(短中长),后一个表示进制或符号
小数(float,double)
小数分为整数部分和小数部分,它们由点号.分隔,例如 0.0、75.0、4.023、0.27、-937.198 -0.27 等都是合法的小数,这是最常见的小数形式,我们将它称为十进制形式。
此外,小数也可以采用指数形式,例如 7.25×102、0.0368×105、100.22×10-2、-27.36×10-3 等。任何小数都可以用指数形式来表示。
C语言中小数的指数形式为:
aEn 或 aen
a 为尾数部分,是一个十进制数;n 为指数部分,是一个十进制整数;E或e是固定的字符,用于分割尾数部分和指数部分。整个表达式等价于 a×10n。
指数形式的小数举例:
-
2.1E5 = 2.1×105,其中 2.1 是尾数,5 是指数。
-
3.7E-2 = 3.7×10-2,其中 3.7 是尾数,-2 是指数。
-
0.5E7 = 0.5×107,其中 0.5 是尾数,7 是指数。
C语言中常用的小数有两种类型,分别是 float 或 double;float 称为单精度浮点型,double 称为双精度浮点型。小数的长度是固定的,float 始终占用4个字节,double 始终占用8个字节。
输出
小数也可以使用 printf 函数输出,包括十进制形式和指数形式,它们对应的格式控制符分别是:
-
%f 以十进制形式输出 float 类型;
-
%lf 以十进制形式输出 double 类型;
-
%e 以指数形式输出 float 类型,输出结果中的 e 小写;
-
%E 以指数形式输出 float 类型,输出结果中的 E 大写;
-
%le 以指数形式输出 double 类型,输出结果中的 e 小写;
-
%lE 以指数形式输出 double 类型,输出结果中的 E 大写。
由于%d被十进制数decimal占用了,double类型用%lf表示,即double类型可以理解为long float类型
#include
#include
int main()
{
float a = 0.302;
float b = 128.101;
double c = 123;
float d = 112.64E3;
double e = 0.7623e-2;
float f = 1.23002398;
printf("a=%e \nb=%f \nc=%lf \nd=%lE \ne=%lf \nf=%f\n", a, b, c, d, e, f);
return 0;
}
/*
a=3.020000e-001
b=128.100998
c=123.000000
d=1.126400E+005
e=0.007623
f=1.230024
*/
对代码的说明:
- %f 和 %lf 默认保留六位小数,不足六位以 0 补齐,超过六位按四舍五入截断。
- 将整数赋值给 float 变量时会变成小数。
- 以指数形式输出小数时,输出结果为科学计数法;也就是说,尾数部分的取值为:0 ≤ 尾数 < 10。
另外,小数还有一种更加智能的输出方式,就是使用%g。%g 会对比小数的十进制形式和指数形式,以最短的方式来输出小数,让输出结果更加简练。所谓最短,就是输出结果占用最少的字符。
#include
#include
int main()
{
float a = 0.00001;
float b = 30000000;
float c = 12.84;
float d = 1.229338455;
printf("a=%g \nb=%g \nc=%g \nd=%g\n", a, b, c, d);
return 0;
}
/*
a=1e-005
b=3e+007
c=12.84
d=1.22934
*/
对各个小数的分析:
-
a 的十进制形式是 0.00001,占用七个字符的位置,a 的指数形式是 1e-05,占用五个字符的位置,指数形式较短,所以以指数的形式输出。
-
b 的十进制形式是 30000000,占用八个字符的位置,b 的指数形式是 3e+07,占用五个字符的位置,指数形式较短,所以以指数的形式输出。
-
c 的十进制形式是 12.84,占用五个字符的位置,c 的指数形式是 1.284e+01,占用九个字符的位置,十进制形式较短,所以以十进制的形式输出。
-
d 的十进制形式是 1.22934,占用七个字符的位置,d 的指数形式是 1.22934e+00,占用十一个字符的位置,十进制形式较短,所以以十进制的形式输出。
需要注意的两点是:
-
%g 默认最多保留六位有效数字,包括整数部分和小数部分;%f 和 %e 默认保留六位小数,只包括小数部分。
-
%g 不会在最后强加 0 来凑够有效数字的位数,而 %f 和 %e 会在最后强加 0 来凑够小数部分的位数。
总之,%g 要以最短的方式来输出小数,并且小数部分表现很自然,不会强加零,比 %f 和 %e 更有弹性,这在大部分情况下是符合用户习惯的。
除了 %g,还有 %lg、%G、%lG:
-
%g 和 %lg 分别用来输出 float 类型和 double 类型,并且当以指数形式输出时,
e小写。 -
%G 和 %lG 也分别用来输出 float 类型和 double 类型,只是当以指数形式输出时,
E大写。
数字的后缀
一个数字,是有默认类型的:对于整数,默认是 int 类型;对于小数,默认是 double 类型。
整型中int使用最多,所以整数默认是int,而浮点数中double使用较多,所以小数默认是double
如果不想让数字使用默认的类型,那么可以给数字加上后缀,手动指明类型:
-
在整数后面紧跟 l 或者 L(不区分大小写)表明该数字是 long 类型;
-
在小数后面紧跟 f 或者 F(不区分大小写)表明该数字是 float 类型。
long a = 100l;
int b = 294;
short c = 32L;
float x = 52.55f;
double y = 18.6F;
float z = 0.02;
小数和整数相互赋值
在C语言中,整数和小数之间可以相互赋值:
-
将一个整数赋值给小数类型,在小数点后面加 0 就可以,加几个都无所谓。
-
将一个小数赋值给整数类型,就得把小数部分丢掉,只能取整数部分,这会改变数字本来的值。注意是直接丢掉小数部分,而不是按照四舍五入取近似值。
英文字符
字符的表示
字符类型由单引号' '包围,字符串由双引号" "包围。
//正确的写法
char a = '1';
char b = '$';
char c = 'X';
char d = ' '; // 空格也是一个字符
//错误的写法
char x = '中'; //char 类型不能包含 ASCII 编码之外的字符
char y = 'A'; //A 是一个全角字符
char z = "t"; //字符类型应该由单引号包围
说明:在字符集中,全角字符和半角字符对应的编号(或者说编码值)不同,是两个字符;ASCII 编码只定义了半角字符,没有定义全角字符。
字符的输出
输出 char 类型的字符有两种方法,分别是:
-
使用专门的字符输出函数 putchar;
-
使用通用的格式化输出函数 printf,char 对应的格式控制符是
%c。
#include
int main() {
char a = '1';
char b = '$';
char c = 'X';
char d = ' ';
//使用 putchar 输出
putchar(a); putchar(d);
putchar(b); putchar(d);
putchar(c); putchar('\n');
//使用 printf 输出
printf("%c %c %c\n", a, b, c);
return 0;
}
字符与整数
计算机在存储字符时并不是真的要存储字符实体,而是存储该字符在字符集中的编号(也可以叫编码值)。对于 char 类型来说,它实际上存储的就是字符的 ASCII 码。
无论在哪个字符集中,字符编号都是一个整数;从这个角度考虑,字符类型和整数类型本质上没有什么区别。
我们可以给字符类型赋值一个整数,或者以整数的形式输出字符类型。反过来,也可以给整数类型赋值一个字符,或者以字符的形式输出整数类型。
#include
int main()
{
char a = 'E';
char b = 70;
int c = 71;
int d = 'H';
printf("a: %c, %d\n", a, a);
printf("b: %c, %d\n", b, b);
printf("c: %c, %d\n", c, c);
printf("d: %c, %d\n", d, d);
return 0;
}
/*
a: E, 69
b: F, 70
c: G, 71
d: H, 72
*/
a、b、c、d 实际上存储的都是整数:
-
当给 a、d 赋值一个字符时,字符会先转换成 ASCII 码再存储;
-
当给 b、c 赋值一个整数时,不需要任何转换,直接存储就可以;
-
当以 %c 输出 a、b、c、d 时,会根据 ASCII 码表将整数转换成对应的字符;
-
当以 %d 输出 a、b、c、d 时,不需要任何转换,直接输出就可以。
可以说,是 ASCII 码表将英文字符和整数关联了起来。
在几乎所有语言中,字符和整数都是相通的。
再谈字符串
C语言中没有专门的字符串类型,只能使用数组或者指针来间接地存储字符串。
字符串的两种表示形式:
char str1[] = "http://c.biancheng.net";
char *str2 = "C语言中文网";
str1 和 str2 是字符串的名字,后边的[ ]和前边的*是固定的写法。
#include
int main() {
char str1[] = "http://c.biancheng.net";
char *str2 = "C语言中文网";
printf("%s\n", str1);
printf("%s\n", str2);
return 0;
}
转义字符
字符集(Character Set)为每个字符分配了唯一的编号,我们不妨将它称为编码值。在C语言中,一个字符除了可以用它的实体(也就是真正的字符)表示,还可以用编码值表示。这种使用编码值来间接地表示字符的方式称为转义字符(Escape Character)。
转义字符以\或者\x开头,以\开头表示后跟八进制形式的编码值,以\x开头表示后跟十六进制形式的编码值。对于转义字符来说,只能使用八进制或者十六进制。
char a = '\61'; //字符1
char b = '\141'; //字符a
char c = '\x31'; //字符1
char d = '\x61'; //字符a
char *str1 = "\x31\x32\x33\x61\x62\x63"; //字符串"123abc"
char *str2 = "\61\62\63\141\142\143"; //字符串"123abc"
char *str3 = "The string is: \61\62\63\x61\x62\x63" //混用八进制和十六进制形式
转义字符既可以用于单个字符,也可以用于字符串,并且一个字符串中可以同时使用八进制形式和十六进制形式。
#include
int main() {
char x = '\x61';
printf("%c\n",x);
puts("\x68\164\164\x70://c.biancheng.\x6e\145\x74");
return 0;
}
/*
http://c.biancheng.net
*/
转义字符的初衷是用于 ASCII 编码,所以它的取值范围有限:
-
八进制形式的转义字符最多后跟三个数字,也即
\ddd,最大取值是\177; -
十六进制形式的转义字符最多后跟两个数字,也即
\xdd,最大取值是\x7f。
超出范围的转义字符的行为是未定义的,有的编译器会将编码值直接输出,有的编译器会报错。
针对常用的控制字符,C语言又定义了简写方式:
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) | 009 |
| \v | 垂直制表(VT) | 011 |
| ’ | 单引号 | 039 |
| " | 双引号 | 034 |
| |反斜杠 | 092 |
#include
int main(){
puts("C\tC++\tJava\n\"C\" first appeared!");
return 0;
}
/*
C C++ Java
"C" first appeared!
*/
几个基本概念
标识符
C语言规定,标识符只能由字母(A~Z, az)、数字(09)和下划线(_)组成,并且第一个字符必须是字母或下划线,不能是数字。
在使用标识符时还必须注意以下几点:
-
C语言虽然不限制标识符的长度,但是它受到不同编译器的限制,同时也受到操作系统的限制。例如在某个编译器中规定标识符前128位有效,当两个标识符前128位相同时,则被认为是同一个标识符。
-
在标识符中,大小写是有区别的,例如 BOOK 和 book 是两个不同的标识符。
-
标识符虽然可由程序员随意定义,但标识符是用于标识某个量的符号,因此,命名应尽量有相应的意义,以便于阅读和理解,作到“顾名思义”。
关键字
关键字(Keywords)是由C语言规定的具有特定意义的字符串,通常也称为保留字,例如 int、char、long、float、unsigned 等。我们定义的标识符不能与关键字相同,否则会出现错误。
注释
注释(Comments)可以出现在代码中的任何位置,用来向用户提示或解释代码的含义。程序编译时,会忽略注释,不做任何处理,就好像它不存在一样。
C语言支持单行注释和多行注释:
-
单行注释以
//开头,直到本行末尾(不能换行); -
多行注释以
/*开头,以*/结尾,注释内容可以有一行或多行。
#include
int main() {
/* puts 会在末尾自动添加换行符 */
puts("http://c.biancheng.net");
printf("C语言中文网\n"); //printf要手动添加换行符
return 0;
}
表达式(Expression)和语句(Statement)
表达式(Expression)和语句(Statement)的概念在C语言中并没有明确的定义:
-
表达式可以看做一个计算的公式,往往由数据、变量、运算符等组成,例如
3*4+5、a=c=d等,表达式的结果必定是一个值; -
语句的范围更加广泛,不一定是计算,不一定有值,可以是某个操作、某个函数、选择结构、循环等。
-
表达式必须有一个执行结果,这个结果必须是一个值,例如
3*4+5的结果 17,a=c=d=10的结果是 10,printf("hello")的结果是 5(printf 的返回值是成功打印的字符的个数)。 -
以分号
;结束的往往称为语句,而不是表达式,例如3*4+5;、a=c=d;等。
加减乘除运算
C语言中的运算符号与数学中的略有不同
| 加法 | 减法 | 乘法 | 除法 | 求余数(取余) | |
|---|---|---|---|---|---|
| 数学 | + | - | × | ÷ | 无 |
| C语言 | + | - | * | / | % |
对除法的说明
C语言中的除法运算有点奇怪,不同类型的除数和被除数会导致不同类型的运算结果:
-
当除数和被除数都是整数时,运算结果也是整数;如果不能整除,那么就直接丢掉小数部分,只保留整数部分,这跟将小数赋值给整数类型是一个道理。
-
一旦除数和被除数中有一个是小数,那么运算结果也是小数,并且是 double 类型的小数。
除数和被除数同为整数时,结果也是整数,除不尽的情况下就取整。
除数和被除数中有一个为小数时,会发生类型转换,整形自动转换为浮点型。
#include
int main()
{
int a = 100;
int b = 12;
float c = 12.0;
double p = a / b;
double q = a / c;
printf("p=%lf, q=%lf\n", p, q);
return 0;
}
/*
p=8.000000, q=8.333333
*/
注意的一点是除数不能为 0,因为任何一个数字除以 0 都没有意义。
然而,编译器对这个错误一般无能为力,很多情况下,编译器在编译阶段根本无法计算出除数的值,不能进行有效预测,“除数为 0”这个错误只能等到程序运行后才能发现,而程序一旦在运行阶段出现任何错误,只能有一个结果,那就是崩溃,并被操作系统终止运行。
#include
int main()
{
int a, b;
scanf("%d %d", &a, &b); //从控制台读取数据并分别赋值给a和b
printf("result=%d\n", a / b);
return 0;
}
这段代码用到了一个新的函数,就是 scanf。scanf 和 printf 的功能相反,printf 用来输出数据,scanf 用来读取数据。此处,scanf 会从控制台读取两个整数,并分别赋值给 a 和 b。
程序开头定义了两个 int 类型的变量 a 和 b,程序运行后,从控制台读取用户输入的整数,并分别赋值给 a 和 b,这个时候才能知道 a 和 b 的具体值,才能知道除数 b 是不是 0。像这种情况,b 的值在程序运行期间会改变,跟用户输入的数据有关,编译器根本无法预测,所以就没法及时发现“除数为 0”这个错误。
对取余运算的说明
取余,也就是求余数,使用的运算符是 %。C语言中的取余运算只能针对整数,也就是说,% 的两边都必须是整数,不能出现小数,否则编译器会报错。
另外,余数可以是正数也可以是负数,由 % 左边的整数决定:
-
如果 % 左边是正数,那么余数也是正数;
-
如果 % 左边是负数,那么余数也是负数。
负数相当于对取余的结果乘了-1
#include
int main() {
printf(
"100%%12=%d \n100%%-12=%d \n-100%%12=%d \n-100%%-12=%d \n",
100 % 12, 100 % -12, -100 % 12, -100 % -12
);
return 0;
}
/*
100%12=4
100%-12=4
-100%12=-4
-100%-12=-4
*/
在 printf 中,% 是格式控制符的开头,是一个特殊的字符,不能直接输出;要想输出 %,必须在它的前面再加一个 %(即用%%表示无格式化的%),这个时候 % 就变成了普通的字符,而不是用来表示格式控制符了。
加减乘除运算的简写
在C语言中,对变量本身进行运算可以有简写形式。假设用 # 来表示某种运算符,那么
a = a # b
可以简写为:
a #= b
表示 +、-、*、/、% 中的任何一种运算符。
int a = 10, b = 20;
a += 10; //相当于 a = a + 10;
a *= (b-10); //相当于 a = a * (b-10);
a -= (a+20); //相当于 a = a - (a+20);
自增(++)和自减(–)
++和--分别称为自增运算符和自减运算符,它们在循环结构中使用很频繁。
#include
int main()
{
int a = 10, b = 20;
printf("a=%d, b=%d\n", a, b);
++a;
--b;
printf("a=%d, b=%d\n", a, b);
a++;
b--;
printf("a=%d, b=%d\n", a, b);
return 0;
}
/*
a=10, b=20
a=11, b=19
a=12, b=18
*/
++ 在变量前面和后面是有区别的:
-
++ 在前面叫做前自增(例如 ++a)。前自增先进行自增运算,再进行其他操作。
-
++ 在后面叫做后自增(例如 a++)。后自增先进行其他操作,再进行自增运算。
自减(–)也一样,有前自减和后自减之分。
#include
int main() {
int a = 12, b = 1;
int c = a - (b--); // ① a=12,c=12-1,b=0
int d = (++a) - (--b); // ② a=13,b=-1,d=13-(-1)
printf("c=%d, d=%d\n", c, d);
return 0;
}/*
c=11,d=14
*/
运算符的优先级和结合性
#include
int main(){
int a = 16, b = 4, c = 2;
int d = a + b * c;
int e = a / b * c;
printf( "d=%d, e=%d\n", d, e);
return 0;
}
/*
d=24,e=8
*/
所谓优先级,就是当多个运算符出现在同一个表达式中时,先执行哪个运算符。
当乘法和除法的优先级相同时,编译器很明显知道先执行除法,再执行乘法,这是根据运算符的结合性来判定的。所谓结合性,就是当一个表达式中出现多个优先级相同的运算符时,先执行哪个运算符:先执行左边的叫左结合性,先执行右边的叫右结合性。
当一个表达式中出现多个运算符时,C语言会先比较各个运算符的优先级,按照优先级从高到低的顺序依次执行;当遇到优先级相同的运算符时,再根据结合性决定先执行哪个运算符:如果是左结合性就先执行左边的运算符,如果是右结合性就先执行右边的运算符。
数据类型转换
数据类型转换就是将数据(变量、数值、表达式的结果等)从一种类型转换为另一种类型。
自动类型转换
自动类型转换就是编译器默默地、隐式地、偷偷地进行的数据类型转换,这种转换不需要程序员干预,会自动发生。
- 将一种类型的数据赋值给另外一种类型的变量时就会发生自动类型转换:
float f = 100;
100 是 int 类型的数据,需要先转换为 float 类型才能赋值给变量 f。
在赋值运算中,赋值号两边的数据类型不同时,需要把右边表达式的类型转换为左边变量的类型,这可能会导致数据失真,或者精度降低;所以说,自动类型转换并不一定是安全的。对于不安全的类型转换,编译器一般会给出警告。
- 在不同类型的混合运算中,编译器也会自动地转换数据类型,将参与运算的所有数据先转换为同一种类型,然后再进行计算。转换的规则如下:
-
转换按数据长度增加的方向进行,以保证数值不失真,或者精度不降低。例如,int 和 long 参与运算时,先把 int 类型的数据转成 long 类型后再进行运算。
-
所有的浮点运算都是以双精度进行的,即使运算中只有 float 类型,也要先转换为 double 类型,才能进行运算。
-
char 和 short 参与运算时,必须先转换成 int 类型。

unsigned 也即 unsigned int,此时可以省略 int,只写 unsigned。
自动类型转换可以比喻成将小容器里的水倒入大容器中,即数据长度小的数据类型可以自动转换到数据长度大的数据类型。
#include
int main(){
float PI = 3.14159;
int s1, r = 5;
double s2;
s1 = r * r * PI;
s2 = r * r * PI;
printf("s1=%d, s2=%f\n", s1, s2);
return 0;
}
/*
s1=0.000000, s2=78.539749
*/
强制类型转换
自动类型转换是编译器根据代码的上下文环境自行判断的结果,有时候并不是那么“智能”,不能满足所有的需求。如果需要,程序员也可以自己在代码中明确地提出要进行类型转换,这称为强制类型转换。
强制类型转换的格式为:
(type_name) expression
type_name为新类型名称,expression为表达式,例如:
(float) a; //将变量 a 转换为 float 类型
(int)(x+y); //把表达式 x+y 的结果转换为 int 整型
(float) 100; //将数值 100(默认为int类型)转换为 float 类型
#include
int main(){
int sum = 103; //总数
int count = 7; //数目
double average; //平均数
average = (double) sum / count;//此处一定要用double强转
printf("Average is %lf!\n", average);
return 0;
}
/*
Average is 14.714286!
*/
在这段代码中,有两点需要注意:
-
对于除法运算,如果除数和被除数都是整数,那么运算结果也是整数,小数部分将被直接丢弃;如果除数和被除数其中有一个是小数,那么运算结果也是小数。
-
( )的优先级高于/,对于表达式(double) sum / count,会先执行(double) sum,将 sum 转换为 double 类型,然后再进行除法运算,这样运算结果也是 double 类型,能够保留小数部分。注意不要写作(double) (sum / count),这样写运算结果将是 3.000000,仍然不能保留小数部分。
类型转换只是临时性的
无论是自动类型转换还是强制类型转换,都只是为了本次运算而进行的临时性转换,转换的结果也会保存到临时的内存空间,不会改变数据本来的类型或者值。
#include
int main(){
double total = 400.8; //总价
int count = 5; //数目
double unit; //单价
int total_int = (int)total;
unit = total / count;
printf("total=%lf, total_int=%d, unit=%lf\n", total, total_int, unit);
return 0;
}
/*
total=400.800000, total_int=400, unit=80.160000
total的类型仍然是double,未发生变化
*/
自动类型转换 VS 强制类型转换
在C语言中,有些类型既可以自动转换,也可以强制转换,例如 int 到 double,float 到 int 等;而有些类型只能强制转换,不能自动转换,例如以后将要学到的 void * 到 int *,int 到 char * 等。
可以自动转换的类型一定能够强制转换,但是,需要强制转换的类型不一定能够自动转换。现在我们学到的数据类型,既可以自动转换,又可以强制转换,以后我们还会学到一些只能强制转换而不能自动转换的类型。
可以自动进行的类型转换一般风险较低,不会对程序带来严重的后果,例如,int 到 double 没有什么缺点,float 到 int 顶多是数值失真。只能强制进行的类型转换一般风险较高,或者行为匪夷所思,例如,char * 到 int * 就是很奇怪的一种转换,这会导致取得的值也很奇怪,再如,int 到 char * 就是风险极高的一种转换,一般会导致程序崩溃。
附:运算符优先级和结合性一览表
| 优先级 | 运算符 | 名称或含义 | 使用形式 | 结合方向 | 说明 |
|---|---|---|---|---|---|
| 1 | [] | 数组下标 | 数组名[常量表达式] | 左到右 | |
| () | 圆括号 | (表达式) 函数名(形参表) | |||
| . | 成员选择(对象) | 对象.成员名 | |||
| -> | 成员选择(指针) | 对象指针->成员名 | |||
| 2 | - | 负号运算符 | -表达式 | 右到左 | 单目运算符 |
| (类型) | 强制类型转换 | (数据类型)表达式 | |||
| ++ | 自增运算符 | ++变量名 变量名++ | 单目运算符 | ||
| – | 自减运算符 | –变量名 变量名– | 单目运算符 | ||
| * | 取值运算符 | *指针变量 | 单目运算符 | ||
| & | 取地址运算符 | &变量名 | 单目运算符 | ||
| ! | 逻辑非运算符 | !表达式 | 单目运算符 | ||
| ~ | 按位取反运算符 | ~表达式 | 单目运算符 | ||
| sizeof | 长度运算符 | sizeof(表达式) | |||
| 3 | / | 除 | 表达式 / 表达式 | 左到右 | 双目运算符 |
| * | 乘 | 表达式*表达式 | 双目运算符 | ||
| % | 余数(取模) | 整型表达式%整型表达式 | 双目运算符 | ||
| 4 | + | 加 | 表达式+表达式 | 左到右 | 双目运算符 |
| - | 减 | 表达式-表达式 | 双目运算符 | ||
| 5 | << | 左移 | 变量<<表达式 | 左到右 | 双目运算符 |
| >> | 右移 | 变量>>表达式 | 双目运算符 | ||
| 6 | > | 大于 | 表达式>表达式 | 左到右 | 双目运算符 |
| >= | 大于等于 | 表达式>=表达式 | 双目运算符 | ||
| < | 小于 | 表达式<表达式 | 双目运算符 | ||
| <= | 小于等于 | 表达式<=表达式 | 双目运算符 | ||
| 7 | == | 等于 | 表达式==表达式 | 左到右 | 双目运算符 |
| != | 不等于 | 表达式!= 表达式 | 双目运算符 | ||
| 8 | & | 按位与 | 表达式&表达式 | 左到右 | 双目运算符 |
| 9 | ^ | 按位异或 | 表达式^表达式 | 左到右 | 双目运算符 |
| 10 | 按位或 | 表达式 | 表达式 | ||
| 11 | && | 逻辑与 | 表达式&&表达式 | 左到右 | 双目运算符 |
| 12 | 逻辑或 | 表达式 | |||
| 13 | ?: | 条件运算符 | 表达式1? 表达式2: 表达式3 | 右到左 | 三目运算符 |
| 14 | = | 赋值运算符 | 变量=表达式 | 右到左 | |
| /= | 除后赋值 | 变量/=表达式 | |||
| *= | 乘后赋值 | 变量*=表达式 | |||
| %= | 取模后赋值 | 变量%=表达式 | |||
| += | 加后赋值 | 变量+=表达式 | |||
| -= | 减后赋值 | 变量-=表达式 | |||
| <<= | 左移后赋值 | 变量<<=表达式 | |||
| >>= | 右移后赋值 | 变量>>=表达式 | |||
| &= | 按位与后赋值 | 变量&=表达式 | |||
| ^= | 按位异或后赋值 | 变量^=表达式 | |||
| = | 按位或后赋值 | 变量 | =表达式 | ||
| 15 | , | 逗号运算符 | 表达式,表达式,… | 左到右 |
上表中可以总结出如下规律:
-
结合方向只有三个是从右往左,其余都是从左往右。
-
所有双目运算符中只有赋值运算符的结合方向是从右往左。
-
另外两个从右往左结合的运算符也很好记,因为它们很特殊:一个是单目运算符,一个是三目运算符。
-
C语言中有且只有一个三目运算符。
-
逗号运算符的优先级最低,要记住。
-
此外要记住,对于优先级:算术运算符 > 关系运算符 > 逻辑运算符 > 赋值运算符。逻辑运算符中“逻辑非 !”除外。