MySQL 索引
目录
- 前言
- 一、MySQL 索引
-
- 1、索引优缺点
- 2、存储引擎功能概述
- 二、MySQL 索引分类
-
- 1、B+树
-
- 1.1、聚簇索引(clustered index)
-
- ⑴、主键索引(primary key)
- 1.2、辅助索引 又称 二级索引(secondary key)
-
- ⑴、唯一索引(unique index)
- ⑵、普通索引(normal index)
- ⑶、组合索引(composite index)
- ⑷、前缀索引(prefix index)
- 2、FullText【倒排索引(inverted index)】
-
-
- ⑴、全文索引(full text)
-
- 3、Hash
-
-
- ⑴、哈希索引(hash index)
-
- ①、优点
- ②、缺点
- ③、内存表与临时表区别
- ⑵、InnoDB的自适应哈希
-
- 4、R-树
-
-
- ⑴、空间索引(spatial index)
-
- 三、索引使用注意事项
-
- 1、建立索引的原则
- 2、常用索引
- 3、使用索引的注意事项
- 4、思考:InnoDB主键索引的B+tree高度为多高呢?
前言
从上一篇文章 MySQL 简单了解B+树 中知道 MySQL 为何选择B+树来做索引,树结构是为了磁盘或其它存储设备而设计的一种平衡多路查找树,树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成,而CPU的速度非常快,所以B树的操作效率取决于访问磁盘的次数,关键字总数相同的情况下B树的高度越小,磁盘I/O所花的时间越少。
而B+树的高度比B树低,所以磁盘IO次数会更少;并且B+树叶子节点通过双向指针链接,可以很方便的进行范围查询;由于B+树的数据只存储在叶子节点上,所以对于任意关键字的查找都必须从根节点走到叶子节点,所有关键字查询路径长度相同,每个数据查询效率相当,因此B+树的稳定性比B树好。
一、MySQL 索引
索引是一种特殊的数据库结构,有数据表中的一列或者多列组合而成,可以快速查询数据表中的值,相当于图书的目录,根据目录的页码快速找到所需内容。
1、索引优缺点
优点:
- 创建索引可以大幅提高系统性能,帮助用户提高查询的速度;
- 可以加速表与表之间的链接;
- 降低查询中分组和排序的时间。
缺点:
- 索引的存储需要占用磁盘空间;
- 当数据的量非常巨大时,索引的创建和维护所耗费的时间也是相当大的;
- 当每次执行create、update、delete操作时,索引也需要动态维护,降低了数据的维护速度。
2、存储引擎功能概述
MySQL 官方文档:: MySQL 5.7 Reference Manual :: 15 Alternative Storage Engines。
| 功能 | MyISAM | Memory | InnoDB | Archive | NDB |
|---|---|---|---|---|---|
| B树索引 | Yes | Yes | Yes | No | No |
| T树索引 | No | No | No | No | Yes |
| 哈希索引 | No | Yes(默认使用哈希索引) | No(InnoDB在内部利用哈希索引实现其自适应哈希索引功能) | No | Yes |
| 全文索引 | Yes | No | Yes(MySQL 5.6及更高版本支持FULLTEXT索引) | No | No |
| 索引缓存 | Yes | N/A | Yes | No | Yes |
| 聚簇索引 | No | No | Yes | No | No |
| 地理空间索引支持 | Yes | No | Yes | No | No |
| 地理空间数据类型支持 | Yes | No | Yes | Yes | Yes |
| 备份/时间点恢复 | Yes | Yes | Yes | Yes | Yes |
| 数据库集群 | No | No | No | No | Yes |
| 数据压缩 | Yes | No | Yes | Yes | No |
| 数据缓存 | No | N/A | Yes | No | Yes |
| 数据加密 | Yes | Yes | Yes | Yes | Yes |
| 主从复制 | Yes | Limited | Yes | Yes | Yes |
| 支持外键 | No | No | Yes | No | Yes |
| 锁定粒度 | Table | Table | Row | Row | Row |
| MVCC | No | No | Yes | No | No |
| 事务 | No | No | Yes | No | Yes |
| 更新数据字典的统计信息 | Yes | Yes | Yes | Yes | Yes |
| 最大存储 | 256TB | RAM | 64TB | None | 384EB |
二、MySQL 索引分类
由上面官方提供的表格可以看出常用的存储引擎对于各种索引的支持,我们常用的索引有:主键索引、唯一索引、普通索引、组合索引、前缀索引 等,如果没有特别指明,默认都是使用B+树结构的索引。而其他的索引如:全文索引 使用的是倒排索引、空间索引 则使用R-树结构。
B+树索引应该是 MySQL 里最广泛的索引的了,除了archive基本所有的存储引擎都支持它。
主要的索引结构有: B-tree、T-tree、R-tree、hash、fulltext;
假设现在有一个user表,表内数据如下:
| id(int) | age(tinyint) | name(varchar) | hobby(varchar) | id_card(char) | profile(text) |
|---|---|---|---|---|---|
| 1 | 21 | 刘一 | LOL | 1111111111111111 | 刘一。。。此处省略数百字。 |
| 2 | 22 | 陈二 | 魔兽世界 | 22222222222222 | 陈二。。。此处省略数百字。 |
| 3 | 23 | 张三 | 讲道理 | 33333333333333 | 张三。。。此处省略数百字。 |
| 4 | 24 | 李四 | 篮球 | 44444444444444 | 李四。。。此处省略数百字。 |
| 5 | 25 | 王五 | 足球 | 55555555555555 | 王五。。。此处省略数百字。 |
| 6 | 25 | 赵六 | 橄榄球 | 66666666666666 | 赵六。。。此处省略数百字。 |
| 7 | 27 | 孙七 | 足球 | 77777777777777 | 孙七。。。此处省略数百字。 |
| 8 | 28 | 周八 | 跑步 | 88888888888888 | 周八。。。此处省略数百字。 |
| 9 | 29 | 吴九 | 羽毛球 | 99999999999999 | 吴九。。。此处省略数百字。 |
| 10 | 30 | 郑十 | 钓鱼 | 10101010101010 | 郑十。。。此处省略数百字。 |
1、B+树
以下示例以InnoDB 为例,根据索引结构分类:
1.1、聚簇索引(clustered index)
聚簇索引只有 InnoDB 支持,InnoDB 中的主键索引就是一种聚簇索引。
聚簇索引就是一个正常的B+树结构,其叶子节点中的data存放数据表中所有每一行的完整数据。
非聚簇索引其叶子节点的 data 中存的不是完整的数据,而是主键值。
因索引结构会产生两个情况:索引覆盖 和 回表。
索引覆盖:创建一个索引,该索引包含查询中用到的所有字段,只需要通过索引就可以查找和返回查询所需要的数据。- 可以一次性完成查询工作,有效减少IO,提高查询效率。
- 可以一次性完成查询工作,有效减少IO,提高查询效率。
回表:顾名思义就是回到表中重新查询一次,也就是先通过二级索引查找到主键ID,然后在通过主键ID去查询聚簇索引找到一行的完整数据。- 所以回表的产生也是需要一定条件的,如果一次索引查询就能获得所有的select 记录就不需要回表,如果select 所需获得列中有其他的非索引列,就会发生回表动作。即基于非主键索引的查询需要多扫描一棵索引树。
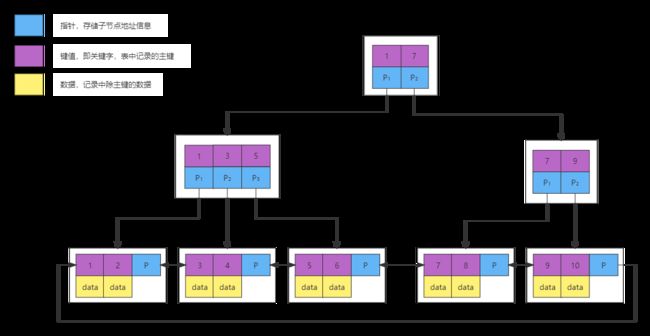
⑴、主键索引(primary key)
InnoDB 通过主键聚集数据,如果没有定义主键,InnoDB 会自己选择 非空的唯一索引 或 隐式字段 DB_ROW_ID (可以去了解一下 MVCC 中的隐式字段)去定义主键。
- 主键存在:以主键作为聚簇索引。
- 主键不存在,存在非空的唯一索引:以非空的唯一索引作为聚簇索引。
- 主键和唯一索引都不存在:选择 隐式字段
DB_ROW_ID定义为主键作为聚簇索引。
添加主键索引:
alter table 表名 add primary key(列名);
alter table user add primary key(`id`);
1.2、辅助索引 又称 二级索引(secondary key)
非聚簇索引都是 辅助索引 又称 二级索引,像复合索引、前缀索引、唯一索引。非聚簇索引其叶子节点的 data 中存的不是完整的数据,而是主键值,如果没有 索引覆盖 则通过 回表 查询聚簇索引找到数据。
以上面user表中age字段添加普通索引为例,参考下面普通索引的B+树结构图:
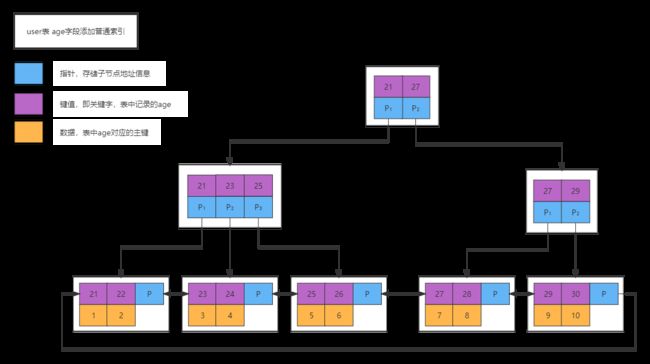
⑴、唯一索引(unique index)
索引列的值必须是唯一的,允许空值。唯一索引不允许表中任何两行的值具有相同的索引值。
添加唯一索引:
alter table 表名 add unique index 索引名(列名);
alter table user add unique index index_id_card(`id_card`);
⑵、普通索引(normal index)
基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值。
下面的 组合索引 和 前缀索引 都可以看成普通索引的变种,组合索引是在普通索引的基础上单列变成多列,前缀索引是在单列的基础上截取字段部分内容用于索引,不过前缀索引只支持文本类型。
添加普通索引:
alter table 表名 add index 索引名(列名);
alter table user add index index_name(`name`);
⑶、组合索引(composite index)
组合索引又称为复合索引,使用时需要遵循 最左前缀匹配原则 。如果条件允许的情况下使用组合索引替代多个单列索引使用,所以创建多列索引时,要根据业务场景,将where子句中使用最频繁的一列放在最左边。
最左前缀匹配原则 :顾名思义是最左优先,以最左边的为起点任何连续的索引都能匹配上。
- 如果第一个字段是范围查询需要单独建一个索引;
- 在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边;
当创建(a,b,c)复合索引时,想要索引生效的话,只能使用 a和ab、ac和abc三种组合!
添加组合索引:
alter table 表名 add index 索引名(列名1,列名2.......);
alter table user add index index_age_name(`age`,`name`);
⑷、前缀索引(prefix index)
在文本类型如 char、varchar、text 类列上创建索引时,可以指定索引列的长度,但是数值类型不能指定。
什么情况下需要用到前缀索引呢?
- 现在在上面的user表中 加上一个字段
address,一个地址的长度基本都在10以上,如果以全部长度来创建索引,索引文件就会非常大,所以此时可以创建前缀索引。
怎样去选择前缀索引的长度?
- 不断地调整 length 的值,直到和全列计算出区分度相近,最相近的那个值,就是我们想要的值。
select count(distinct left(`address`, length) ) / count(*) from `user`;
添加前缀索引:
alter table 表名 add index 索引名(列名(长度));
alter table user add index index_address(address(2));
2、FullText【倒排索引(inverted index)】
倒排索引可参考这两篇博客:
InnoDB & MySQL 全文索引
MySQL(InnoDB剖析):29—全文检索(倒排索引、全文索引/全文检索)
全文索引 通常使用 倒排索引 来实现。倒排索引(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构,同B+树索引一样,也是一种索引结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
在之前的 MySQL 数据库中,InnoDB 不支持全文检索技术,只有 MyISAM 存储引擎支持。大多数的用户转向 MyISAM 存储引擎,还可能需要进行表的拆分,并将需要进行全文检索的数据存储为 MyISAM 表。这样的确能够解决需求,但是却丧失了 InnoDB 存储引擎的事务性,于是从 InnoDB 1.2.x版本开始,InnoDB 开始支持全文检索,其支持 MyISAM 存储引擎的全部功能,并且还支持其他一些特性。
- 倒排索引它在辅助表中存储了单词与单词自身在一个或多个文档中所在的位置之间的映射。这通常利用关联数组实现,其拥有两种表现形式。
inverted file index, 其表现形式为【单词, 单词所在文档的ID】。
full inverted index,其表现形式为【单词,(单词所在文档的ID, 再具体文档中的位置)】。
- 单词:words
- 单词所在文档的ID:documentid
- 文档中的位置:position
InnoDB从1.2.x开始支持全文检索的技术,其采用
full inverted index的方式。在InnoDB存储引擎中,将(documentid,position)视为一个
ilist。因此在全文检索的表(辅助表,见下)中,有两个列:
- 一个是word字段。在word字段上有设有索引
- 另一个是ilist字段
此外,由于InnoDB存储引擎ilist字段中存放了position信息,故可以进行proximity search,而MyISAM存储引擎不支持该特性
当前InnoDB的全文索引还存在以下的限制:
- 每张表只能有一个全文检索的索引。
- 由多列组合而成的全文检索的索引列必须使用相同的字符集与排序规则。
- 不支持没有单词界定符(delimiter)的语言,如中文、日语、韩语等,但从 MySQL 5.7 开始内置了ngram 全文检索插件,用来支持中文分词。
⑴、全文索引(full text)
MySQL5.6版本以后MyISAM和InnoDB中都支持使用全文索引,只能在文本类型char、varchar、text 类型字段上创建全文索引。字段长度比较大时,如果创建普通索引,在进行like模糊查询时效率比较低,这时可以创建全文索引。
添加全文索引:
alter table 表名 add fulltext index 索引名(列名);
alter table user add fulltext index index_profile(`profile`);
3、Hash
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
哈希表 是 数组 + 链表 的形式,通过哈希函数计算每个节点数据中键所对应的哈希桶位置,如果出现哈希冲突,就使用拉链法来解决。
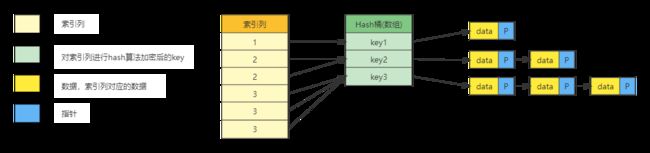
⑴、哈希索引(hash index)
MySQL 中的存储引擎只有Memory 和 NDB 支持哈希索引,其中 Memory默认使用哈希索引。
NDB存储引擎是MYSQL的集群存储引擎。对于这个存储引擎,MySQL服务器实际上变成了一个其他进程的集群客户端。
Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
- Memory类型的存储引擎主要用于那些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果。对存储引擎为memory的表进行更新操作要谨慎,因为数据并没有实际写入到磁盘中,所以一定要对下次重新启动服务后如何获得这些修改后的数据有所考虑。
①、优点
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
使用的场景: 一些读操作密集的表建议使用hash索引,因为hash索引的查找速度是很快的。但是也有一些局限。
②、缺点
- 1、hash索引只包含哈希码和行指针,不能使用索引的值避免读取行,也就是要回表,不能像覆盖索引那样避免回表。
- 2、hash索引不能进行排序以及范围查找,只支持 = 、in 、<=>的比较,因为它们不会按照顺序保存行数据。
- 3、有可能产生hash碰撞,那么就必须要访问链表的每一个行指针,然后逐行进行比较得出正确数据。
- 4、因为hash算法是基于等值计算的,不支持部分键匹配,例如有个组合索引a_b,那么此时即使我们的where子句中使用到了a,也不会使用索引,like 等范围查找同理。
③、内存表与临时表区别
临时表和内存表比较像,但是这两个概念可是完全不同的。
内存表:指的是使用Memory引擎的表,建表语法是create table … engine=memory。这种表的数据都保存在内存里,系统重启的时候会被清空,但是表结构还在。除了这两个特性看上去比较“奇怪”外,从其他的特征上看,它就是一个正常的表。
临时表:可以使用各种引擎类型 。如果是使用InnoDB引擎或者MyISAM引擎的临时表,写数据的时候是写到磁盘上的。当然,临时表也可以使用Memory引擎。
⑵、InnoDB的自适应哈希
从以上可以知道,哈希表查找最优情况下是查找一次。而InnoDB使用的是B+树,最优情况下的查找次数根据层数决定。因此为了提高查询效率,InnoDB便允许使用 自适应哈希 来提高性能。
与其说这是一种索引不如称其为是一种 机制。自适应哈希索引的由来就是:当Innodb注意到一些索引值被频繁的访问时,内部会在b-tree索引的顶端为其创建索引保存在内存之中,使其具有快速哈希查找的特性,这个过程是它自动完成的。
可以通过参数 innodb_adaptive_hash_index 来决定是否开启。默认是打开的。
mysql> show variables like "innodb_adaptive_hash_index";
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_adaptive_hash_index | ON |
+----------------------------+-------+
1 row in set (0.16 sec)
存储引擎会自动对个索引页上的查询进行监控,如果能够通过使用自适应哈希索引来提高查询效率,其便会自动创建自适应哈希索引,不需要开发人员或运维人员进行任何设置操作。
自适应哈希索引是对innodb的缓冲池的B+树页进行创建,不是对整张表创建,因此速度很快。
可以通过查看innodb的 status 命令来查看自适应哈希索引的使用情况。
mysql> show engine innodb status;
+--------+------+---------+
| Type | Name | Status
+--------+------+---------+
| InnoDB | |
=====================================
2022-12-13 15:06:03 0x62f0 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 6 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 191 srv_active, 0 srv_shutdown, 708026 srv_idle
srv_master_thread log flush and writes: 708217
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 4025
OS WAIT ARRAY INFO: signal count 4057
RW-shared spins 0, rounds 40132, OS waits 3309
RW-excl spins 0, rounds 4589, OS waits 141
RW-sx spins 54, rounds 1573, OS waits 50
Spin rounds per wait: 40132.00 RW-shared, 4589.00 RW-excl, 29.13 RW-sx
------------
TRANSACTIONS
------------
Trx id counter 3233592
Purge done for trx's n:o < 3233410 undo n:o < 0 state: running but idle
History list length 90
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 283413858068272, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
--------
FILE I/O
--------
I/O thread 0 state: wait Windows aio (insert buffer thread)
I/O thread 1 state: wait Windows aio (log thread)
I/O thread 2 state: wait Windows aio (read thread)
I/O thread 3 state: wait Windows aio (read thread)
I/O thread 4 state: wait Windows aio (read thread)
I/O thread 5 state: wait Windows aio (read thread)
I/O thread 6 state: wait Windows aio (write thread)
I/O thread 7 state: wait Windows aio (write thread)
I/O thread 8 state: wait Windows aio (write thread)
I/O thread 9 state: wait Windows aio (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
198289 OS file reads, 27374 OS file writes, 1469 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 552, seg size 554, 552 merges
merged operations:
insert 13450, delete mark 1, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 17393, node heap has 1 buffer(s)
Hash table size 17393, node heap has 18 buffer(s)
Hash table size 17393, node heap has 1 buffer(s)
Hash table size 17393, node heap has 189 buffer(s)
Hash table size 17393, node heap has 2 buffer(s)
Hash table size 17393, node heap has 1 buffer(s)
Hash table size 17393, node heap has 0 buffer(s)
Hash table size 17393, node heap has 1 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
LOG
---
Log sequence number 30110810223
Log flushed up to 30110810223
Pages flushed up to 30110810223
Last checkpoint at 30110810214
0 pending log flushes, 0 pending chkp writes
509 log i/o's done, 0.00 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 68648960
Dictionary memory allocated 685290
Buffer pool size 4096
Free buffers 1024
Database pages 2859
Old database pages 1035
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 53454, not young 2806497
0.00 youngs/s, 0.00 non-youngs/s
Pages read 197570, created 18349, written 25879
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 2859, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=1864, Main thread ID=1912, state: sleeping
Number of rows inserted 505838, updated 2, deleted 0, read 6824874
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
|
+--------+------+---------+
1 row in set (0.17 sec)
mysql>
可以看到自适应哈希索引大小,每秒的使用情况。
注意从哈希表的特性来看,自适应哈希索引只能用于等值查询,范围或者大小是不允许的。
等值查询: select * from xx where name = "xxx";
4、R-树
R-树(Rectangle-tree)是B树在高维空间的扩展,是一棵平衡树。每个R树的叶子结点包含了多个指向不同数据的指针,这些数据可以是存放在硬盘中的,也可以是存在内存中。
结构参考下图:根节点的A、B对一个的子节点就是一个矩形(Rectangle)结构,根节点包含子节点,叶子节点是最小的矩形,根节点就是最大的矩形。
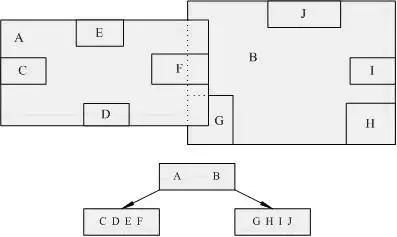
R树是用来做空间数据存储的树状数据结构。例如给地理位置,矩形和多边形这类多维数据建立索引。在现实生活中,R树可以用来存储地图上的空间信息,例如餐馆地址,或者地图上用来构造街道,建筑,湖泊边缘和海岸线的多边形。
然后可以用它来回答“查找距离我2千米以内的博物馆”,“检索距离我2千米以内的所有路段”(然后显示在导航系统中)或者“查找(直线距离)最近的加油站”这类问题。R树还可以用来加速使用包括大圆距离在内的各种距离度量方式的最邻近搜索。
再看看你下面这张图是不是就更容易理解:
根据R树的这种数据结构,当我们需要进行一个高维空间查询时,我们只需要遍历少数几个叶子结点所包含的指针,查看这些指针指向的数据是否满足要求即可。
⑴、空间索引(spatial index)
MySQL在5.7版本以后 MyISAM 和 InnoDB 中都支持了空间索引,对空间数据类型的字段建立的索引,底层可通过 R树 实现,R树索引 用于多维信息的空间索引,使用较少。
添加空间索引(空间类型的字段必须为非空 字段的数字类型必须是geometry):
alter table 表名 add 列 geometry;
alter table 表名 add spatial index 索引名 (列名);
三、索引使用注意事项
1、建立索引的原则
查询更快,占用空间小。
- 1、定义主键的数据列一定要建立索引;
- 2、定义有外键的数据列一点要建立索引;
- 3、对于经常查询的数据列建立索引;
- 4、对于需要在指定范围内的快速或频繁查询的数据列;
- 5、经常用where字句中的数据列;
- 6、经常出现在关键字order by、group by、distinct后面的字段,建立索引。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用;
- 7、查询中很少涉及的列,重复值比较多的列不要建立索引;
- 8、对于定义为text、image和bit、的数据类型的列不要建立索引;
- 9、经常存取的列不要建立;
- 10、限制索引数目,索引数一般不超过3个,最多不超过5个。索引提高了访问速度,但太多索引会影响数据的更新;
2、常用索引
- 1、普通索引:普通索引是最基本的索引,它没有任何限制,值可以为空,仅加速查询
- 2、唯一性索引:唯一索引与普通索引类似,不同:索引列的值必须唯一,允许有空值。如果是组合索引,则列值得组合必须唯一
- 3、全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配
- 4、单列索引(主键):是一种特殊的唯一索引,一个表只能有一个主键,不允许有空置。
- 5、多列索引(组合):在多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
3、使用索引的注意事项
- 1、不要再列上使用函数和进行运算,引起该列索引失效;
- 2、尽量避免使用or来连接条件,导致索引失效进行全表扫描;
- 3、in走索引,not in索引失效;
- 4、单列索引和复合索引。尽量使用复合索引,而少使用单列索引;
- 5、如果mysql评估使用索引比全表更慢。则不使用索引;
- 6、范围查询右边的列,不能使用索引;
- 7、尽量使用覆盖索引,避免select * 尽量使用覆盖索引(只访问索引的查询(引列完全包含查询列)),减少select *。查询列超过索引列也会降低效率;
- 8、最左前缀法则如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始,并且不跳过索引中的列;
- 9、IS NULL,IS NOT NULL有时索引失效;
- 10、以%开头的Like模糊查询,索引失效。如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,引失效;
- 11、全值匹配,对索引中所有列都指定具体值。改情况下,索引生效,执行效率高。
4、思考:InnoDB主键索引的B+tree高度为多高呢?
我们知道 InnoDB存储引擎最小储存单元是 页,一页大小就是16k。B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据;
现在有这么一张表:主键bigint类型;
- 主键ID为bigint类型,长度为8Byte(int类型的话,一个int就是32位,4Byte),而指针大小是固定的在InnoDB源码中设置为6Byte
那么一页所能存放的主键个数是
14B × n = 16 × 1024B, 得出n约等于 1170。因为B+树的所有数据都存放在叶子节点上,所以叶子节点的占用内存比根节点多的,假设一行记录的数据大小为1k,那么单个叶子节点可以存16条记录;
- 如果树的高度是2,那么所存储的数据最多有:
1170 × 16 = 18720- 如果树的高度是3,那么所存储的数据最多有:
1170 × 1170 × 16 = 21902400,2千多万- 如果树的高度是4,那么所存储的数据最多有:
1170 × 1170 × 16 = 25625808000,约25亿6千万
所以B+树高度一般为1-3层,已经满足千万级别的数据存储。