Kubernetes系列
文章目录
- 1 详解docker,踏入容器大门
-
- 1.1 引言
- 1.2 初始docker
- 1.3 docker安装
- 1.4 docker 卸载
- 1.5 docker 核心概念和底层原理
-
- 1.5.1 核心概念
- 1.5.2 docker底层原理
- 1.6 细说docker镜像
-
- 1.6.1 镜像的常用命令
- 1.7 docker 容器
- 1.8 docker 容器数据卷
-
- 1.8.1 直接命令添加
- 1.8.2 Dockerfile添加
- 1.8.3 数据卷容器的继承
- 1.9 dockerfile 解析
-
- 1.9.1 dockerfile 基础知识
- 1.9.2 docker 执行 dockerfile 的大致流程
- 1.9.3 dockerfile、docker 镜像、docker 容器
- 1.9.4 dockerfile 体系结构(保留字指令)
- 1.9.5 自定义镜像 my_centos2
- 1.9.6 CMD/ENTRYPOINT 镜像案例
- 1.9.7 onbuild 镜像案例
- 1.9.8 自定义 tomcat
- 1.9.9 docker 安装 mysql
- 1.10 docker 网络
-
- 1.10.1 host 模式
- 1.10.2 container模式
- 1.10.2 none 模式
- 1.10.3 bridge 模式
- 1.10.4 相关命令
- 1.11 小结
- 2 云原生和分布式系统的存储基石etcd的介绍、架构和概念解析
-
- 2.1 引言
- 2.2 初识 etcd
- 2.3 etcd 架构简介
- 2.4 etcd 典型应用场景
-
- 2.4.1 服务注册与发现
- 2.4.2 消息发布和订阅
- 2.4.3 负载均衡
- 2.4.4 分布式锁
- 2.4.5 分布式队列
- 2.4.6 集群监控与 Leader 竞选
- 2.5 etcd 与其它键值存储系统的对比
- 2.7 etcd 相关概念
- 2.8 etcd 发展里程碑
1 详解docker,踏入容器大门
1.1 引言
准备开一个新系列来介绍 k8s,关于 k8s 的重要性不言而喻,在云原生时代它就是分布式架构的操作系统。但介绍 k8s 之前我想先聊一聊 docker,我们知道 docker 是容器化引擎(负责创建容器),而 k8s 负责容器编排,可以在成百上千个节点上自动管理 docker 创建出来的容器。因此以 docker 为代表的容器化引擎相当于是 k8s 的地基,而 k8s 作为上层建筑主要是对容器进行统筹和管理的。
你也许听说过 1.20 版本的 k8s 要弃用 docker,这是什么原因呢?
首先容器化引擎并不只有 docker 一种,k8s 的容器运行时支持对接多种容器,只要容器实现了 k8s 规定的 CRI(容器运行时接口),就可以被 k8s 调度。但 docker 比 k8s 出现的早,不支持 k8s 规定的 CRI,而且 docker 官方后续也没打算实现。因为 docker 官方觉得,明明是我先出现的,凭啥按照你的标准。
于是无奈之下,k8s 官方搞出来一个桥接服务(dockershim),如果 k8s 想和 docker 通信,那么必须通过 dockershim 将请求进行转发。

容器引擎有多种,比如 docker、containerd、CRI-O、podman 等等,只要实现了 k8s 规定的 CRI,就可以被 k8s 集群调度和管理。虽然 docker 不支持 CRI,但 k8s 出来的时候 docker 正处于火热,所以不得不通过 dockershim 来兼容 docker。但现在 k8s 已经统治了云原生市场,所以是否支持 docker 已经不重要了,关键是 dockershim 这个桥接服务的维护成本太高了。而且 k8s 的容器运行时也不需要 docker 那么复杂的功能,k8s 需要的只是 CRI 中定义的那些接口。
所以 k8s 1.20 版本,不再支持 docker,但 dockershim 这个组件还得到了保留。而从 k8s 1.24 版本时,dockershim 组件也被移除了,至此 k8s 彻底完成了 docker 的移除。
k8s 1.24 开始,容器化引擎的新选择是 podman。
相信到此你已经了解了 docker 被抛弃的原因,既然如此我们为什么还要学习它呢?因为 docker 目前还是被大量使用的,大部分公司用的 k8s 也是 1.15 之前的版本。而且 docker 作为最流行的容器引擎,有很多优秀的设计,也是值得我们学习的。另外在设计和使用上,podman 和 docker 也是兼容的。
好啦,废话不多说,下面就来介绍学习一下 docker。
1.2 初始docker
为什么会有 docker 出现?
一款产品开发完毕之后想要上线会经历很多步骤,从操作系统到运行环境、再到应用配置等等,都是开发团队和运维团队所需要关心的。同时这也是很多互联网公司都不得不面对的问题,特别是各种版本的迭代,不同版本环境的兼容,对运维人员都是考验。
环境配置如此麻烦,换一台机器,就要重来一次,费力费时。很多人想到,能不能从根本上解决问题,软件可以带环境安装?也就是说,安装的时候,把原始环境一模一样地复制过来。所以 docker 便出现了,它给出了一个标准化的解决方案,开发人员利用 docker 可以消除 “明明在我的机器上运行的好好的” 这样的问题。
之前在服务器配置一个应用的运行环境,要安装各种软件,安装和配置这些东西有多麻烦就不说了,它还不能跨平台。假如我们是在 Windows 上安装的这些环境,到了 Linux 又得重新装。况且就算不跨操作系统,换另一台同样操作系统的服务器,要移植应用也是非常麻烦的。
传统上认为,软件开发 / 测试结束后,所产出的成果即是程序,或者是能够编译执行的二进制字节码等。而为了让这些程序可以顺利执行,开发团队也得准备完整的部署文件,让运维团队得以部署应用程序,开发需要清楚地告诉运维部署团队,用的全部配置文件+所有软件环境。不过即便如此,仍然常常发生部署失败的状况。docker 镜像的设计,使得 docker 得以打破过去「程序即应用」的观念。透过镜像(images)将运行程序所需要的系统环境,由下而上打包,达到跨平台间的无缝接轨运作。
docker 理念
docker 是基于 Go 语言实现的云开源项目,主要目标是 “Build,Ship and Run Any App,Anywhere”,也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的 APP(可以是一个 Web 应用或数据库应用等等)及其运行环境能够做到 “一次封装,到处运行”。
Linux 容器技术的出现就解决了这样一个问题,而 docker 则是在它的基础上发展过来的。将应用运行在 docker 容器上面,而 docker 容器在任何操作系统上都是一致的,这就实现了跨平台、跨服务器。只需要一次配置好环境,换到别的机子上就可以一键部署好,大大简化了操作。
之前的虚拟机技术
提到容器,你肯定会想到虚拟机(virtual machine),它也是带环境安装的一种解决方案。可以在一个操作系统里面运行另一个操作系统,比如在 Windows 系统里面运行 Linux 系统,而应用程序对此毫无感知。因为虚拟机看上去跟真实机器一模一样,但对于底层系统来说,虚拟机就是一个普通文件,不需要了就删掉,对其他部分毫无影响。这类虚拟机完美的运行了另一套系统,能够使应用程序,操作系统和硬件三者之间的逻辑不变。 但是它有如下缺点:
资源占用多
冗余步骤多
启动慢
容器虚拟化技术
由于前面虚拟机存在这些缺点,Linux 发展出了另一种虚拟化技术:Linux 容器(Linux Containers,缩写为 LXC)。Linux 容器不是模拟一个完整的操作系统,而是对进程进行隔离。有了容器,就可以将软件运行所需的所有资源打包到一个隔离的容器中。容器与虚拟机不同,不需要捆绑一整套操作系统,只需要软件工作所需的库资源。系统因此而变得高效轻量,并保证部署在任何环境中的软件都能始终如一地运行。
所以 传统虚拟机 和 容器 的区别就很明显了:
传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整的操作系统,在该系统上再运行所需的应用进程。
而容器内的应用进程直接运行于宿主机的内核,容器没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便;每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。
docker 特点
1)更快速的应用交付和部署
传统的应用开发完成后,需要提供一堆安装程序和配置说明文档,安装部署后需根据配置文档进行繁杂的配置才能正常运行。docker 化之后只需要交付少量容器镜像文件,在正式生产环境加载镜像并运行即可,应用安装配置在镜像里已经内置好,大大节省部署配置和测试验证时间。
2)更便捷的升级和扩缩容
随着微服务架构和 docker 的发展,大量的应用会通过微服务方式架构,应用的开发构建将变得像搭积木一样,每个 docker 容器将变成一块“积木”,应用的升级将变得非常容易。当现有的容器不足以支撑业务处理时,可通过镜像运行新的容器进行快速扩容,使应用系统的扩容从原先的天级变成分钟级甚至秒级。
3)更简单的系统运维
应用容器化运行后,生产环境运行的应用可与开发、测试环境的应用高度一致,容器会将应用程序相关的环境和状态完全封装起来,不会因为底层基础架构和操作系统的不一致性给应用带来影响,产生新的 BUG。当出现程序异常时,也可以通过测试环境的相同容器进行快速定位和修复。
4)更高效的计算资源利用
docker 是内核级虚拟化,其不像传统的虚拟化技术一样需要额外的 Hypervisor 支持,所以在一台物理机上可以运行很多个容器实例,可大大提升物理服务器的 CPU 和内存的利用率。
1.3 docker安装
认识完 docker 之后,我们来安装 docker。操作系统毫无疑问是 Linux,这里我以 CentOS7 为例,直接通过 yum install docker -y 即可。安装完毕之后,通过 systemctl start docker 命令启动 docker。
如果后续操作 docker 的时候发现报错:Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?,那么说明说明 docker 没有启动。
然后通过 docker --version 或者 docker version 命令即可查看版本信息。
我们看到版本是 1.13.1,然后里面还有一个 Go version,它表示编译 docker 的 Go 语言版本,因为 docker 是使用 Go 语言编写的。
当然你也可以通过 docker info 命令查看 docker 的整体信息:

返回的信息非常多,包括镜像的数量,容器的数量,正在运行、暂停、中止的容器数量,还有操作系统的相关信息等等。
然后我们来配置一下镜像加速,因为后面要不停地拉取镜像,而默认是从国外的网站进行拉取,所以速度会很慢。我们需要编辑 /etc/docker/daemon.json 文件,在里面配置国内的镜像源:
{
"registry-mirrors": [""]
}
配置完之后别忘记重启 docker,systemctl restart docker。
1.4 docker 卸载
docker 安装之后如果不用了,那么要如何卸载呢?
- systemctl stop docker:停止 docker 服务
- yum remove -y docker:卸载 docker
- rm -rf /var/lib/docker:删除 docker 相关的残留文件
1.5 docker 核心概念和底层原理
1.5.1 核心概念
docker 主要有三个核心概念,分别是镜像、容器、仓库。
镜像(image)
docker 镜像(image)就是一个只读的模板,镜像可以用来创建 docker 容器,并且一个镜像可以创建很多容器。
容器(container)
docker 利用容器(container)独立运行一个或一组应用,容器是用镜像创建的运行实例。它可以被启动、开始、停止、删除,每个容器都是相互隔离的、保证安全的平台。可以把容器看做是一个简易版的 Linux 环境(包括 root 用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。容器的定义和镜像几乎一模一样,也是一堆层的统一视角,唯一区别在于容器的最上面那一层是可读可写的(后面说)。
仓库(repository)
仓库(repository)是集中存放镜像文件的场所,每个仓库中包含了多个镜像,每个镜像有不同的标签(tag)。
仓库分为公开仓库(public)和私有仓库(private)两种形式,最大的公开仓库是 Docker Hub ,存放了数量庞大的镜像供用户下载。而国内的公开仓库则包括阿里云 、网易云等。
总结:需要正确地理解 镜像 / 容器 / 仓库 这几个概念,docker 本身是一个容器运行载体或称之为管理引擎。我们把应用程序和配置依赖打包好形成一个可交付的运行环境,这个打包好的运行环境就叫做 image镜像文件。只有通过这个镜像文件才能生成 docker 容器。image 文件可以看作是容器的模板,docker 根据 image 文件生成容器的实例,同一个 image 文件,可以生成多个同时运行的容器实例。
而 image 文件生成的容器实例,本身也是一个文件。一个容器运行一种服务,当我们需要的时候,就可以通过 docker 客户端创建一个对应的运行实例,也就是我们的容器。
至于仓库,就是放了一堆镜像的地方,我们可以把镜像发布到仓库中,需要的时候从仓库中拉下来就可以了。
1.5.2 docker底层原理
docker 是怎么工作的?
docker 是一个 client-server 结构的系统,docker 守护进程运行在主机上,然后我们通过 socket 连接从客户端访问,守护进程从客户端接受命令并管理运行在主机上的容器。我们输入命令,docker 通过 client 将我们的命令传给 server,然后守护进程来管理 docker 所创建的容器,比如删除、重启等等。
所以 docker 的 logo 很形象,一个鲸鱼飘在大海里,上面背着很多的集装箱。这个大海就是我们的宿主机,直接使用宿主机的资源,大鲸鱼就相当于是 docker,鲸鱼上面的集装箱就是一个个的容器,里面运行着各种服务,而且每个集装箱都是相互隔离的,不会对其他的集装箱造成污染。
为什么 docker 比虚拟机快?
1)docker 有着比虚拟机更少的抽象层。由于 docker 不需要 Hypervisor 实现硬件资源虚拟化,运行在 docker 容器上的程序使用的都是实际物理机的硬件资源。因此在 CPU、内存利用率上 docker 会有明显优势。
2)docker 利用的是宿主机的内核,而不需要 Guest OS。因此当新建一个容器时,docker 不需要和虚拟机一样重新加载一个操作系统内核,从而避免了引导、加载操作系统内核这个比较费时费资源的过程。当新建一个虚拟机时,虚拟机软件需要加载 Guest OS,这个新建过程是分钟级别的。而 docker 由于直接利用宿主机的操作系统,则省略了这个过程,因此新建一个 docker 容器只需要几秒钟。
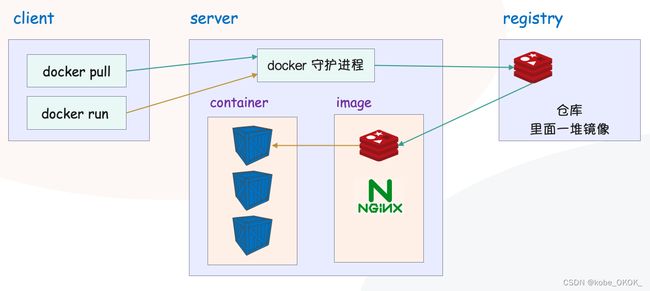
以上是 docker 的整体架构图,我们看到它和 redis 是类似的,都是 CS 架构。docker 内部有一个守护进程,我们通过 client 发送命令,服务端的守护进程来执行。
比如:docker pull 镜像名 是拉取镜像,守护进程在接收到命令之后就会去指定的仓库中拉取指定的镜像,下载到本地;而 docker run 镜像名则是根据镜像创建一个容器,该容器就可以提供相应的服务。
1.6 细说docker镜像
下面我们来看看 docker 的核心之一:镜像。
镜像是什么?
镜像是一种轻量级、可执行的独立软件包,用来打包和其依赖的运行环境,它包含运行某个软件所需的所有内容,包括代码、运行时、库、环境变量和配置文件。
UnionFS(联合文件系统)是什么?
UnionFS 是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。Union 文件系统是 docker 镜像的基础,镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
特性:一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录。
docker 镜像加载原理
docker 的镜像实际上由一层一层的文件系统组成,bootfs(boot file system)主要包含 bootloader 和 kernel,bootloader 负责引导加载 kernel,Linux 刚启动时会加载 bootfs 文件系统,在 docker镜像的最底层是 bootfs。这一层与我们典型的 Linux 系统是一样的,包含 boot 加载器和内核。当 boot 加载完成之后整个内核就都在内存中了,此时内存的使用权已由 bootfs 转交给内核,系统也会卸载 bootfs。
rootfs(root file system),在 bootfs 之上,包含的就是典型 Linux 系统中的 /dev、/proc、/bin、/etc 等标准目录和文件。rootfs 就是各种不同的操作系统发行版,比如 Ubuntu,CentOS等等。
后面我们会拉取 CentOS 镜像,你会发现才两百多兆,可平时我们安装进虚拟机的 CentOS 都是好几个 G 才对啊?因为对于一个精简的 OS 来说 rootfs 可以很小,只需要包括最基本的命令、工具和程序库就可以了,底层会直接用 Host(宿主机)的 kernel,自己只需要提供 rootfs 就行了。由此可见对于不同的 Linux 发行版,bootfs 基本是一致的,rootfs 会有差别,因此不同的发行版可以共用 bootfs。
为什么 docker 镜像采用分层结构?
我们说 docker 的镜像实际上是由一层一层的文件系统组成,那为什么要采用这种分层的结构呢?其实最大的好处就是共享资源,比如:有多个镜像都从相同的 base 镜像构建而来,那么宿主机只需在磁盘上保存一份 base 镜像;同时内存中也只需加载一份 base 镜像,就可以为所有容器服务了,因为镜像的每一层都可以被共享。
镜像的特点
docker 镜像都是只读的,当容器启动时,一个新的可写层被加载到镜像的顶部,这一层通常被称作 “容器层”,“容器层” 之下的都叫 “镜像层”。
1.6.1 镜像的常用命令
下面我们来看看和镜像相关的命令都有哪些,docker 和 redis 一样,都需要我们时刻和命令打交道。
搜索镜像
docker search [options] 镜像名

里面的 STARTS 就类似于 GitHub 上的 star,越多表示越受欢迎。而且这个命令是有一些可选参数的:
- –no-trunc: 显示完整的镜像描述, 我们看到图中的 DESCRIPTION 那一列, 后面有的是 …
- –filter=stars=n: 列出 star 数不小于 n 的镜像

下载镜像
docker pull 镜像名[:TAG]

我们看到镜像是分层的,所以下载也是一层一层下载。另外要注意:拉取镜像的时候可以指定版本,不指定则默认拉取最新的。
查看镜像
docker images [options]

解释一下里面的每一列:
- REPOSITORY:表示镜像的仓库源
- TAG:镜像的标签
- IMAGE ID:镜像 ID
- CREATED:镜像创建时间
- SIZE:镜像大小
同一仓库源可以有多个 TAG,代表这个仓库源的不同个版本,我们使用 REPOSITORY:TAG 来定义不同的镜像。下载镜像的时候可以指定版本标签,比如 docker pull mysql:5.7 表示安装 5.7 版本的 mysql。如果不指定,则默认安装最新的 mysql,也就是 TAG 为 latest。
然后我们看到查看镜像的时候还可以指定可选参数:
- -a:列出本地所有的镜像(含中间镜像层)
- -q:只显示镜像的id
- –digests:显示镜像的摘要信息
- –no-trunc:显示完整的镜像信息

删除镜像
docker rmi -f 镜像id / 镜像名称[:TAG]
删除镜像的时候可以指定镜像 id 进行删除,因为 id 是唯一的,通过 docker images 查看。除了 id 之外,也可以指定 “镜像名称[:TAG]” 进行删除,没有指定 TAG,则表示删除最新的(TAG 为 latest)。这里的 -f 表示强制删除,如果没有使用该镜像创建容器的话,那么加不加 -f 是没有区别的。但是一旦使用该镜像创建了容器并且启动的话,那么删除必须加上 -f,否则会删除失败。值得一提的是,即便删除了镜像,已经创建的容器也不会消失,并且仍然可以正常运行,因为这个容器已经被创建出来了。
为什么会删除这么多,之前也说过,镜像是分层的,镜像下面还有镜像,但是对外显示的只有一层。至于为什么设计成分层,上面也说了,这是 docker 镜像的设计原理,但是我们使用就当只有一层就行。
另外 docker rmi 可以同时删除多个镜像:
- docker rmi 镜像id1 镜像id2 …
- 或者按照镜像名称删除,docker rmi mysql mysql:5.7,如果名称后面没有 TAG,那么会删除最新的,因此这里的 mysql 等价于 mysql:latest

删除的时候可以指定镜像 id 或镜像名称,id 是唯一的,用它来删除最准确。如果使用镜像名称,那么要注意 TAG,不指定 TAG,那么相当于删除 TAG 为 latest 的镜像,所以最后 TAG 为 5.7 的 mysql 镜像没有被删除。
如果你想删除所有的镜像,docker 也是支持的:
- docker rmi -f $(docker images -qa)
- docker images -qa | xargs docker rmi -f
- 通过 docker images -qa 找到所有镜像的 id,然后删除它们。
最后如果你想删除未被容器使用的镜像,那么可以通过 docker image prune 来实现,会删除所有未使用的镜像,也包括中间层镜像。
查看某个镜像的详细信息
docker inspect 镜像id / 镜像名称[:TAG]

会返回有关指定镜像的详细信息,包括镜像的元数据、配置和网络设置等。
以上就是镜像相关的常用命令。
1.7 docker 容器
下面来看看容器,我们说镜像是用来创建容器的模板,而镜像显然是无法提供服务的,真正提供服务的是根据镜像创建的容器。注意:镜像都是只读的,而当基于镜像创建并启动一个容器时,一个新的可写层被加载到镜像的顶部,这一层通常被称作 “容器层”,“容器层” 之下的都叫 “镜像层”。
新建并启动容器
docker run [options] 镜像id / 镜像名称[:TAG]
创建容器时,可选参数是非常重要的,我们来看一下。
- –name 容器名字:为容器指定一个名称;
- -d:后台运行容器,并返回容器ID,也即启动守护式容器;
- -i:以交互模式运行容器,通常与 -t 同时使用;
- -t:为容器重新分配一个伪输入终端,通常与 -i 同时使用;
- -P:随机端口映射;
- -p:指定端口映射;
下面来通过交互式启动容器。

docker 启动 centos 之后会自动进入到容器中,这个 centos 只保留了最核心的部分,使用的资源都是宿主机的资源,我们通过 exit 可以退出容器。
docker run 是创建并启动容器,还可以用 docker create 创建容器但不启动。
列出当前所有正在运行的容器
docker ps [options]
依旧先来看一下可选参数,如果不指定可选参数,则列出当前正在运行的容器。
- -a:列出当前所有正在运行的容器+历史上运行过的
- -l:显示最近一次创建的容器
- -n count:显示最近 count 个创建的容器
- -q:静默模式,只显示容器id
- –no-trunc: 不截断输出

然后看一下输出的每一列所代表的含义:
- CONTAINER ID:容器的id
- IMAGE:容器是由哪个镜像创建的
- CREATED:创建时间
- STATUS:容器状态,是在运行啊,还是在多长时间之前退出
- NAMES:容器的名字,创建容器的时候通过 --name 指定,不指定的话会默认生成一个
退出容器
退出容器有两种方式:
- exit:容器停止、退出
- ctrl+p+q:容器不停止、退出

exit 会停止容器之后再退出,ctrl+p+q 相当于直接从容器内部跳到宿主机中,但容器没有停止。
启动容器
docker start 容器id / 容器名称

一开始没有正在运行的容器,但是这个容器确实被创建出来了,只不过退出了。我们通过最近创建的容器找到 id,然后 docker start 容器id 进行启动,启动成功会返回容器id。顺便一提这个 id 可能有点长,我们也可以只输入前几位,比如 6 位,只要能够准确定位到指定容器即可。
重启容器
docker restart 容器id / 容器名称
重新启动一个正在运行的容器,一般重新启动都是针对正在运行的容器来说,就像 Windows,重新启动只有电脑开机之后,才有重新启动这一说。但 docker restart 也可以对没有启动的容器使用,等于 start,同时 start 也可以对已经启动的容器来使用。
停止容器
docker stop 容器id / 容器名称
停止正在运行的容器,即便容器没有运行,也可以使用这个命令,会返回容器的 id。
[root@satori ~]# docker ps -q
c929e01e5c52
[root@satori ~]# docker stop c929e01e5c52
c929e01e5c52
[root@satori ~]# docker ps -q
[root@satori ~]#
强制停止容器
docker kill 容器id / 容器名称
和 docker stop 功能一样,但是更加粗暴。stop 类似于关机,kill 类似于拔电源。
删除容器
删除已停止的容器:docker rm 容器id,所以删除镜像是 rmi、删除容器是 rm。注意:docker rm 只能删除已停止的容器,如果想删除正在运行的容器,那么需要使用 docker rm -f。
并且该命令可以同时删除多个,也可以将容器一次性全部删除。
docker rm -f $(docker ps -qa)
docker ps -qa | xargs docker rm -f
通过以上命令可以将容器全部删除,和镜像类似,先找到容器的 id,然后基于 id 删除。
启动守护式容器
我们说启动容器的时候,指定 -i 参数是以交互式方式启动;再指定 -t 的话,会分配一个伪终端,这两个参数一般搭配使用。如果我们指定 -i 但是不指定 -t 的话,看看会有什么结果:

我们看到虽然也是交互式的,但是很明显终端没了。
而除了 -i 和 -t 之外,我们还可以指定为 -d,表示启动守护式容器。我们说一个容器就类似于一个精简的虚拟机,每个容器提供一种服务,而服务一般显然都是后台启动的。

我们在创建并启动容器之后,使用 docker ps 没有输出,而使用 docker ps -l 查看,发现容器已经退出了,这是怎么回事?很重要的一点:docker 容器后台运行的时候,内部必须有一个前台进程,否则会自动退出。
这个是 docker 机制的问题,我们以 nginx 为例,正常情况下,在宿主机中配置 nginx 一定是后台启动的,否则终端一关闭进程就停止了。但如果启动的是容器,还让内部的 nginx 服务后台运行,就会导致容器前台没有运行的应用,这样的容器后台启动后,会立即自杀,因为它觉得没事可做了。所以最佳的解决方案是,将你要运行的程序以前台进程的形式运行,因此像 nginx、redis 等镜像在启动之后,内部的进程都是以前台方式启动的。

比如我们基于 redis 镜像创建一个容器,该容器内部会运行一个 redis 服务端。注意:这个容器是后台启动的,那么它的内部必须要至少有一个前台进程,否则该容器会觉得自己无事可做,从而立即自杀。因此容器内部运行的 redis 服务端一定是前台启动的,我们通过 attach 进入到容器中会处于阻塞,然后通过 Ctrl + C 结束前台进程。
所以像 nginx、redis 等镜像在启动之后,内部的服务相对于容器来说是前台运行的,而整个容器相对于宿主机来说是后台运行的。
而对于我们刚才后台启动的 centos 来说,由于内部没有前台进程(比如 top、tail 等等),所以启动之后就退出了。
查看容器日志
docker logs 容器id / 容器名称
也可以指定一些可选参数:
- -t:加入当前时间
- -f:类似于 tail -f, 跟随最新的日志打印
- –tail 数字:显示最后多少条
具体的语法细节后面会说,但上面的容器是用 -d 后台启动的,不是说启动之后会被立刻杀死吗?很简单,如果启动之后立刻退出,说明后台启动的容器内部没有相应的前台进程。但这里不一样,我们启动容器之后内部是有前台进程的,会一直打印 hello world。
查看容器内部运行的进程
docker top 容器id / 容器名称

注意这里的 adoring_bartik 是容器的名称,名称和 id 一样都是唯一的,用哪个都一样。
查看容器内部运行的进程
docker inspect 容器id / 容器名称
返回的内容非常多,详细地描述了该容器。
进入正在运行的容器并与之交互
之前其实有一个问题没有说,当我们使用 ctrl+p+q 的时候,会在不停止容器的情况下退出,容器依旧在运行。但是如果我们想要再次进入之前的容器的话,该怎么办呢?
docker attach 容器id / 容器名称

docker attach 会直接进入命令行的终端,不会启动新的进程。
docker exec -it 容器id /bin/bash
[root@satori ~]# docker exec -it 94dcd /bin/bash
[root@94dcd7f29e84 /]# ls /root/
anaconda-ks.cfg anaconda-post.log original-ks.cfg
[root@94dcd7f29e84 /]#
这个命令是在容器中打开新的终端,比如说,我们在 Linux 上开了一个终端,attach 是在原来的终端上执行,exec 则是新打开了一个终端(这个终端是 /bin/bash,当然还有其它终端,比如 /bin/sh),并且启动一个新的进程。
此外我们也可以直接执行 shell 命令:
[root@satori ~]# docker exec -it 94dcd /bin/bash -c "ls /root"
anaconda-ks.cfg anaconda-post.log original-ks.cfg
[root@satori ~]#
也是开启一个新的终端,然后执行,只不过执行完之后自动回到宿主机。-c “” 可以同时写多个命令,中间使用分号隔开。
从容器内拷贝文件到主机上
比如某个容器不想要了,但里面有一个很重要的文件,这个文件我想把它拿到宿主机上,该怎么做呢?
docker cp 容器id:容器路径 目的主机路径

注意这里的容器 id,因为只有一个正在运行的容器,所以使用 id 的前一位即可定位到指定容器。
镜像打包
说到拷贝文件,我想起了镜像。在介绍镜像的时候忘记说了,如果没有网络,我们如何将镜像打包拷贝到另一个机器上呢。既然要拷贝到另一台机器上,肯定要先拷贝到本机上。
docker save 镜像id / 镜像名[:TAG] > xxx.tar

镜像加载
有了 tar 文件之后,将其拷贝到另一台机器上,然后再加载成镜像。
docker load < xxx.tar
将 tar 文件加载成镜像,保存镜像时一般以 tar 结尾。可能有人发现在加载镜像的时候没有指定镜像名,这是因为 tar 文件中包含了镜像的所有信息。

查看容器内部的变化
docker diff 容器id / 容器名称
查看一个镜像的形成历史
docker history 镜像id / 镜像名称[:TAG]

暂停一个容器
docker pause 容器id / 容器名称
恢复暂停的容器
docker unpause 容器id / 容器名称
阻塞、直到容器退出,然后打印退出时候的状态值
docker wait 容器id / 容器名称
镜像 commit:将一个容器变成一个镜像
docker commit -m “提交的容器信息” -a “作者” 容器id 要创建的镜像名[:TAG]
比如我们启动了一个容器,在这个容器里面我们做了相应的操作,我们想把当前这个已经做了操作的容器变成一个镜像。
[root@satori ~]# docker run -d -p 90:80 nginx
b5c4bf042a157f023a9ef033c3b8b76aabc35d18f85cad7230c3b10b8d61815c
注意一下这里的 -p 90:80,我们说一个容器就类似于一个小型的 CentOS,比如这里的 nginx 容器,它监听 80 端口,这个 80 端口指的是容器(小型 CentOS)内部的 nginx 服务监听的端口。而 -p 90:80 里面的 90 指的是和容器内部 80 端口绑定的宿主机的端口,因为外界不能直接访问容器,需要通过宿主机的 90 端口映射到容器的 80 端口,访问服务。
所以我们可以启动多个 nginx 容器,每个容器内部的 nginx 服务都监听 80 端口,而这个 80 端口是每个容器内部的 80 端口,它们是彼此隔离的,因为每个容器是彼此隔离的。但和宿主机绑定的端口则不能重复,比如第一个 nginx 容器和宿主机的 90 端口绑定,那么第二个容器就不能再和 90 端口绑定了。
而我们从外界访问的话,只能通过 90 端口访问,因为要先访问到宿主机才能访问到容器。

然后我们来对容器做一些修改:

我们进入容器,将里面的 index.html 给改掉(将里面的字符串 nginx 换成了 my_nginx),然后将其打包成镜像。下面启动我们新打包的镜像:
[root@satori ~]# docker run -d -p 100:80 my_nginx:3.3
25d3298083fc220c0273a2631c91301b5ecad5f72ba39b03821eedebd2da5146
90 端口被之前的 nginx 容器给占了,所以我们需要绑定其它的宿主机端口。另外基于镜像创建容器,如果镜像有 TAG(或者 TAG 不是 latest),那么启动的时候需要指定 TAG,因为默认启动的是 TAG 为 latest 的镜像。如果发现不存在此镜像,会自动从仓库中拉取。或者启动容器的时候指定镜像 id 也可以的,但一般都指定镜像名称,因为名称更好记忆。

我们将 “nginx” 换成了 “my_nginx”,启动容器之后,没有做任何的修改,但是显示的内容变了,因为此镜像是由配置改变的容器 commit 得到的。
因此我们可以看到,除了可以用镜像生成容器之外,还可以将容器 commit 成一个镜像。
将容器变成镜像还有一种方式:docker export 容器id / 容器名称 > xxx.tar。
1.8 docker 容器数据卷
先来看看 docker 的理念:
- 将应用与运行的环境打包形成容器运行,运行可以伴随着容器,但是我们对数据的要求则希望是持久化的
- 容器之间能共享数据
docker 容器产生的数据,如果不通过 docker commit 生成新的镜像,使得数据做为镜像的一部分保存下来,那么当容器删除后,数据自然也就没有了。我们之前介绍了一个 docker cp 命令,可以将容器内的数据拷贝到宿主机当中,但是有没有更简单的办法呢?可以不用我们显式地调用命令,而是实现自动关联,让容器中新建的文件或者修改的文件可以自动地同步到宿主机当中呢?答案是可以的,在 docker 中我们使用卷的方式。
卷就是目录或文件,存在于一个或多个容器中,由 docker 挂载到容器,但不属于联合文件系统,因此能够绕过 Union File System 提供一些用于持续存储或共享数据的特性。卷的设计目的就是数据的持久化,完全独立于容器的生存周期,因此 docker 不会在容器删除时删除其挂载的数据卷:
- 数据卷可在容器之间共享或重用数据
- 卷中的更改可以直接生效
- 数据卷中的更改不会包含在镜像的更新中
- 数据卷的生命周期一直持续到没有容器使用它为止
核心就是:容器的持久化,以及容器间的继承+共享数据。
1.8.1 直接命令添加
docker run -it -v 宿主机绝对路径:容器绝对路径 镜像名

一开始宿主机内没有 host 目录,然后我们启动容器,将宿主机的 /root/host 和容器的 /container 进行关联,显然这两个目录各自都不存在。但是当启动之后,它们就被自动创建了。然后此时宿主机的 /root/host 和容器的 /container 就实现了共享,在其中一个目录中做的任何修改都会影响到另一目录。
如果你在启动容器的时候发现失败了,提示没有权限,那么需要加上一个可选参数。
docker run -it --privileged=true -v 宿主机绝对路径:容器绝对路径 镜像名
然后我们测试一下数据是否真的会共享:
[root@satori ~]# touch host/1.txt
[root@satori ~]# docker start 699c
699c
[root@satori ~]# docker exec -it 699c /bin/bash
[root@699c19240a62 /]# ls container/
1.txt
[root@699c19240a62 /]# touch container/2.txt
[root@699c19240a62 /]# exit
exit
[root@satori ~]# ls host/
1.txt 2.txt
[root@satori ~]#
我们在宿主机的 host 的目录中创建 1.txt 文件,然后启动容器(注意:容器刚才是关闭的),查看 /container 目录,发现内部的 1.txt 被自动创建了。然后在容器的 /container 内部创建 2.txt,发现也被同步到宿主机中了。
同理,我们对里面的文件本身做修改,同样会实现共享。
我们进入容器,看到里面的文件都是没有内容的,然后向 1.txt 写入内容,回到宿主机中发现 host 目录下的 1.txt 已经有内容了。然后在 host 目录下的 2.txt 里面也写入内容,再进入容器,看到 /container 目录下的 2.txt 中也有内容了。
所以在目录中做任何的修改,都会同步到另一个目录中。
并且我们在操作的时候,是使用 exit 直接退出容器,并不是使用 ctrl+p+q。也就是说,我们在宿主机操作的时候,容器是处于关闭状态的。这种情况下依旧会同步,类似于持久化,当容器启动之后再将数据同步过去就可以了。
如果我们在同步之后,希望禁止容器内部修改文件,只能在宿主机中修改,该怎么做呢?
docker run -it --privileged=true -v 宿主机绝对路径:容器绝对路径:ro 镜像名
只需要在容器的目录后面加上一个 ro 即可,表示 read only,只读。

这个容器是我们新创建的,但是里面居然有文件,因为宿主机内部有文件,启动的时候自动同步。另外即使删除整个容器,宿主机内部的目录和目录里面的文件也不受影响。
然后我们在容器内的 /container 目录创建文件、修改文件都是不允许的,因为它是只读的,当然在其它目录创建是可以的。因此可以看到,如果是以只读方式创建容器,那么在宿主机里面是可以修改并创建文件的,但是在容器里面不行,至于数据本身,在宿主机里面进行的操作依旧会进行同步。
我们使用 docker inspect 查看一下容器的内部细节:
1.8.2 Dockerfile添加
dockerfile 会在下面详细介绍,但是现在可以提前了解一下。dockerfile 相当于是对镜像的描述,可以对 dockerfile 进行 build,得到镜像。如果我们想修改或者创建镜像的话,那么就可以修改或者创建 dockerfile 文件。dockerfile 相当于是源码文件,镜像相当于是编译之后的字节码。Python 运行的也是字节码文件,如果我们想修改字节码,那么就要修改源码,再重新编译为字节码。dockerfile 也是一样的。
新建一个文件,就叫 dockerfile,写入如下内容:
FROM centos
VOLUME ["/root/dataVolumeContainer1","/root/dataVolumeContainer2"]
CMD echo "finished,--------success1"
CMD /bin/bash
dockerfile 会在下一节介绍,先来简单地看一看。首先是第一行的 FROM centos,相当于继承,extend。之前说过镜像是分层的,这样可以共享。比如 tomcat,总共四百多兆,这显然太大了。但是如果看 tomcat 的 dockerfile 文件的话,会发现开头写着 from open-jdk1.8,说明 tomcat 是包含了 jdk 的,所以才会这么大。不然只有 tomcat 没有 jdk 是没法运行的,因此在删除 tomcat 的时候,会发现删除的不止一层。镜像就像花卷或者俄罗斯套娃一样,一层套着一层。
VOLUME 则是数据卷,里面可以有多个目录,这些目录会自动和宿主机内的目录进行关联。就像 -v 一样,当然我们使用命令添加数据卷的时候也可以关于多个目录,比如:
-v /root/host1:/container1 -v /root/host2:/container2
但我们说 VOLUME 里面的目录会自动和宿主机里面的目录进行关联,那宿主机目录在哪里指定呢?答案是不需要指定,因为出于可移植和分享的考虑,用 -v 主机目录:容器目录 这种方法不能够直接在 dockerfile 中实现。由于宿主机目录是依赖于特定宿主机的,并不能够保证在所有的宿主机上都存在这样的特定目录。所以我们只需要指定容器目录即可,宿主机目录 docker 会自动创建。
而最后两个 CMD 则不用管,后面说。然后生成镜像:
docker build -f dockerfile文件 -t 生成的镜像名称 生成在哪个目录(一般写 . 即可)
那么问题来了,容器目录关联的宿主机目录怎么找?使用 docker inspect 即可,容器的所有细节都能查到。

我们创建个文件试试:

但是很多时候,我们不希望关联一个目录,而是只需要关联一个文件即可。那么这个时候就不能使用 dockerfile 了,而是使用数据卷,以 -v /a:/b 为例。
- a 不存在, 则 a、b 均为目录
- a 是个目录, 则 a、b 均为目录
- a 是个文件, 则 a、b 均为文件
1.8.3 数据卷容器的继承
容器可以挂载数据卷,也可以挂载父容器,从而实现数据共享。挂载数据卷的容器,称之为数据卷容器。
直白一点就是,宿主机相当于电脑,容器相当于硬盘,电脑的数据放到硬盘里。但是如果我有很多的容器呢?因此数据卷容器,相当于硬盘挂载到硬盘上,这样硬盘之间的数据也可以共享。
我们之前使用 dockerfile build 了一个镜像,下面根据这个镜像来启动几个容器。
[root@satori ~]# docker run -it --name c1 my_centos
[root@7f1e1fe29325 /]# ls /root/dataVolumeContainer1
[root@7f1e1fe29325 /]# ls /root/dataVolumeContainer2
[root@7f1e1fe29325 /]#
返回的容器 id 不好记,所以这里我们给容器起一个名字,因为操作容器除了可以指定容器id、还可以指定容器的名字。
[root@satori ~]# docker run -it --name c2 --volumes-from c1 my_centos
[root@38b928631c50 /]# ls /root/dataVolumeContainer1
[root@38b928631c50 /]# ls /root/dataVolumeContainer2
[root@38b928631c50 /]# exit
exit
[root@satori ~]# docker run -it --name c3 --volumes-from c1 my_centos
[root@5001a0aaf2da /]# ls /root/dataVolumeContainer1
[root@5001a0aaf2da /]# ls /root/dataVolumeContainer2
[root@5001a0aaf2da /]#
然后创建容器 c2,要挂载到 c1 上,–volumes-from 容器 表示挂载到某个容器上。所以 c2 里面也有相应的目录,注意此时容器 c1 已经退出了,但是不影响。同理容器 c3 也是一样。
接下来进入容器 c1,在里面创建文件并写入内容。
[root@satori ~]# docker start c1
c1
[root@satori ~]# docker exec -it c1 /bin/bash
[root@7f1e1fe29325 /]# echo "hello cruel world" > /root/dataVolumeContainer1/1.txt
[root@7f1e1fe29325 /]# exit
exit
[root@satori ~]# docker start c2
c2
[root@satori ~]# docker exec -it c2 /bin/bash
[root@38b928631c50 /]# cat /root/dataVolumeContainer1/1.txt
hello cruel world
[root@38b928631c50 /]# exit
exit
[root@satori ~]# docker start c3
c3
[root@satori ~]# docker exec -it c3 /bin/bash
[root@5001a0aaf2da /]# cat /root/dataVolumeContainer1/1.txt
hello cruel world
[root@5001a0aaf2da /]#
在 c1 里面写文件,会同步到 c2 和 c3 中,那么问题来了,在 c2 和 c3 中写文件会不会同步到 c1 中呢?由于 c2 和 c3 是等价的,我们只需要在 c2 中写就可以了。
[root@satori ~]# docker start c2
c2
[root@satori ~]# docker exec -it c2 /bin/bash
[root@38b928631c50 /]# echo "Hello World" > /root/dataVolumeContainer2/2.txt
[root@38b928631c50 /]# exit
exit
[root@satori ~]# docker start c1
c1
[root@satori ~]# docker exec -it c1 /bin/bash
[root@7f1e1fe29325 /]# cat /root/dataVolumeContainer2/2.txt
Hello World
[root@7f1e1fe29325 /]# exit
exit
[root@satori ~]# docker start c3
c3
[root@satori ~]# docker exec -it c3 /bin/bash
[root@5001a0aaf2da /]# cat /root/dataVolumeContainer2/2.txt
Hello World
[root@5001a0aaf2da /]#
所以说容器之间是共享数据的,c2 和 c3 都继承自 c1,我们在 c1 里面创建的文件,会同步到 c2 和 c3 里面去,但是我们在 c2 和 c3 里面做的修改也会作用到 c1 里面。因此 docker 容器不仅仅是父到子,还是子到父。尽管 c2 和 c3 都继承自 c1,但三者是共享的。在 c1 创建文件会同步到 c2 和 c3 里面去,同理在 c2 创建文件也会同步到 c1 和 c3 里面去,在 c3 创建文件也会同步到 c1 和 c2 里面去,当然除了创建文件,删除文件、修改文件也是一样的。
那么问题来了,现在 c2 和 c3 都是继承自 c1,那如果我把 c1 删掉,然后在 c2 里面创建文件,那么会不会也作用到 c3 里面去呢。
想都不用想,肯定是会的。如果我们再创建容器 c4,继承自 c3,那么数据也会同步到 c4 里面去。同理再创建 c5 继承 c4、创建 c6 继承 c5、创建 c7 继承 c6,然后在 c2 里面创建文件,也会同步到 c3、c4、c5、c6、c7 里面(c1被删掉了)。这些数据之间都是共享的,里面的数据会保持一致。
容器之间配置信息的传递,数据卷的生命周期一直持续到没有容器使用它为止。通俗点的说,只要没死绝,那么都可以进行全量的备份。
1.9 dockerfile 解析
dockerfile 是用来构建 docker 镜像的文件,是由一系列命令和参数构成的脚本。那么这个文件长什么样子呢?我们以官方的 centos 镜像为例:

先来了解一下 dockerfile,然后里面的关键字慢慢解释。
1.9.1 dockerfile 基础知识
- 每条保留字指令都必须为大写字母且后面要跟随至少一个参数
- 指定按照从上到下,顺序执行
- 井号表示注释, 但是必须写在单独的一行
- 每条指令都会创建一个新的镜像层,并对镜像进行提交
1.9.2 docker 执行 dockerfile 的大致流程
- docker 执行基础镜像运行一个容器
- 执行每一条指令对容器做出修改
- 执行类似 docker commit 的操作提交一个新的镜像层
- docker 再基于刚提交的镜像运行一个新的容器
- 再执行 dockerfile 中的下一条指令,重复相同的操作,直到所有的指令都完成
- 最终形成一个新的镜像
1.9.3 dockerfile、docker 镜像、docker 容器
-
dockerfile 是软件的原材料
-
docker 镜像是软件的交付品
-
docker 容器则可以认为是软件的运行态
-
dockerfile 面向开发,docker 镜像成为交付标准,docker 容器则涉及部署和运维,三者缺一不可,合力充当 docker 体系的基石。
-
dockerfile 定义了进程需要的一切东西,dockerfile 涉及的内容包括执行代码或者是文件、环境变量、依赖包、运行时环境、动态链接库、操作系统的发行版、服务进程和内核进程(当应用进程需要和系统服务和内核进程打交道,这时需要考虑如何设计namespace的权限控制)等等;
-
docker镜像,在用 dockerfile 定义一个文件之后,docker build 时会产生一个 docker 镜像,当运行 - - docker 镜像时,会真正开始提供服务;
-
docker容器,容器是直接提供服务的
1.9.4 dockerfile 体系结构(保留字指令)
下面来讲解一下 dockerfile 的语法:
FROM
基础镜像,当前要创建的镜像是基于哪一个镜像的。比如 centos 基于 scratch,自己创建的镜像 FROM centos 的话,等于也基于 scratch。
MAINTAINER
镜像维护者的信息。
RUN
容器构建时需要运行的命令。
EXPOSE
容器运行时对外暴露出来的端口。
WORKDIR
指定在创建容器时,终端登录进来的默认的工作目录,一个落脚点。
ENV
用来在构建镜像过程中设置的环境变量,ENV MY_PATH /usr/mytest,比如:WORKDIR $MY_PATH。
ADD
将宿主机目录下的文件或目录拷贝到镜像,且 ADD 命令会自动处理 url 和解压 tar 包。
COPY
类似于 ADD,拷贝文件或目录到镜像中,copy src dst,或者 COPY [“src”, “dst”]。至于它和 ADD 的区别,一会说。
VOLUME
容器数据卷,用于数据保存和持久化工作。
CMD
提交一个容器启动时要运行的命令,dockerfile 中可以有多个 CMD 指令,但只有最后一个生效,并且 CMD 会被 docker run -it centos 之后的参数替换。
ENTRYPOINT
作用和 CMD 一样,只不过多个命令不会覆盖,而是会追加。
ONBUILD
当构建一个被继承的 dockerfile 时运行命令,如果父镜像被子镜像继承,那么在生成子镜像时,父镜像会触发 ONBUILD,类似于一个触发器。或者理解为是父镜像里面的一个回调函数,当子镜像运行时,会触发父镜像的回调函数。
1.9.5 自定义镜像 my_centos2
先来看看默认的 centos 镜像是什么样子:
[root@satori ~]# docker run -it centos
[root@531d7adc9189 /]# pwd
/
[root@531d7adc9189 /]# vim
bash: vim: command not found
[root@531d7adc9189 /]#
进入之后在根目录,不支持 vim。那么我们的任务就是,自定义一个 centos,具备的特征是:进入之后要默认在 /hello 目录,支持vim。
# 继承自 centos:7, 另外有一个 Base 镜像 scratch
# 百分之 99 的镜像都是在此基础之上构建得到的
# 注意这里继承的是 centos:7, 因为默认是 centos8, 而 centos8 直接安装 yum 会失败
FROM centos:7
# 维护者的信息
MAINTAINER [email protected]
# 将 /hello 设置为环境变量
ENV h /hello
# 执行命令, 创建目录
# 也可以直接 RUN mkdir /hello
RUN mkdir $h
# 指定工作区, 进入容器之后默认在这个目录
WORKDIR $h
# 执行命令安装相关应用
RUN yum install -y vim
# 暴露端口为80
EXPOSE 80
# 启动容器之后执行 /bin/bash
CMD /bin/bash
然后我们 build 完镜像之后,创建容器。

此时我们的任务就完成了,来查看一下镜像的形成历史。

可以看到,类似于栈一样,从底往上。
1.9.6 CMD/ENTRYPOINT 镜像案例
两者都是指定一个容器启动时要运行的命令,但是如果 dockerfile 中有多个 CMD 指令,那么只有最后一个生效,并且 CMD 会被 docker run 镜像 之后的参数替换。
怎么理解呢?我们看看 tomcat 的 dockerfile 的最后两句。
EXPOSE 8080
CMD ["catalina.sh", "run"]
表示暴露端口为 8080,然后执行 CMD [“catalina.sh”, “run”]。docker run -it tomcat 之所以可以启动服务,输入 localhost:8080 能看到那只猫,是因为最后一条命令。但如果我们自己指定参数,比如:docker -d run tomcat ls -l,那么你会发现服务根本不会启动,因为我们的 ls -l 把 tomcat 的 dockerfile 文件中的 CMD 命令给覆盖了,所以只是执行了 ls -l,没有启动 tomcat。

我们创建 nginx 容器,默认启动之后容器内部会执行 nginx 启动命令,但我们第一次启动的时候在后面指定了 ls -l。那么相当于容器内部只是查看了一下当前目录,并没有启动 nginx 进程。如果不太好理解,我们改成前台启动。

现在你应该明白 CMD 是做什么的了,它就是容器启动后要执行的命令。如果指定了多个 CMD,那么只有最后一个生效,如果你因为想安装一些包、创建目录等,而执行系统命令的话,那么应该使用 RUN。
所以在介绍容器的时候没有说,docker run 镜像 的后面是可以加命令的。
再来看看 ENTRYPOINT,docker run -it 镜像 之后的参数会传递给 ENTRYPOINT,之后形成新的命令组合。举个栗子:
# vim dockerfile1,输入如下内容
FROM centos
CMD ["ls", "-l"]
# vim dockerfile2,输入如下内容
FROM centos
ENTRYPOINT ["ls", "-l"]
# 然后 build
# docker build -f ./dockerfile1 -t centos1 .
# docker build -f ./dockerfile2 -t centos2 .
那么这两个镜像在启动之后,都会默认执行 ls -l 打印根目录的信息。但如果启动镜像时,在结尾加上一个命令:
docker run -it centos1 usr
docker run -it centos2 usr
那么结果会如何呢?
对于 centos1 来说,在加上 usr 之后,CMD [“ls”, “-l”] 就被覆盖了,相当于直接输入一个 usr,而它显然不是一个命令
对于 centos2 来说,在加上 usr 之后,ENTRYPOINT[“ls”, “-l”] 不会被覆盖,而是会追加,相当于 ls -l usr
因此两者的区别就在于此,都是运行容器时执行指令。CMD 是如果加了参数会选择覆盖,ENTRYPOINT 则是加上了参数则选择追加。
1.9.7 onbuild 镜像案例
创建镜像 father。
FROM centos
CMD ["bin","bash"]
ONBUILD RUN echo "triggerred -------------"
创建子镜像,继承父镜像。
FROM father
CMD ["bin", "bash"]

1.9.8 自定义 tomcat
我们创建一个镜像,用于启动 tomcat 服务。首先在当前目录下的 tomcat 目录,有两个 gz 包,分别用于安装 tomcat 和 jdk。然后构建 dockerfile 文件:
FROM centos
MAINTAINER zgg
#把 java 与 tomcat 添加到容器中
# ADD 命令会自动将压缩包进行解压, 如果是 COPY 则不会自动解压
# 当然也可以使用 COPY,然后再执行 RUN tar -zxvf ...
ADD ./tomcat/jdk-8u211-linux-x64.tar.gz /usr/local/
ADD ./tomcat/apache-tomcat-8.5.29.tar.gz /usr/local/
#设置工作访问的 WORKDIR 路径,登录落脚点
#登录后会自动进入 /usr/local
ENV MYPATH /usr/local
WORKDIR $MYPATH
#配置 java 与 tomcat 环境变量
ENV JAVA_HOME /usr/local/jdk1.8.0_211
ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ENV CATALINA_HOME /usr/local/apache-tomcat-8.5.29
ENV CATALINA_BASE /usr/local/apache-tomcat-8.5.29
ENV PATH $PATH:$JAVA_HOME/bin:$CATALINA_HOME/lib:$CATALINA_HOME/bin
#容器运行时监听的端口
EXPOSE 8080
#启动时运行tomcat
CMD /usr/local/apache-tomcat-8.5.29/bin/startup.sh && \
tail -F /usr/local/apache-tomcat-9.0.8/bin/logs/catalina.out
创建容器并启动。
# 多个主机目录对应多个容器目录
docker run -d -p 9080:8080 --name mytomcat9 \
-v /home/satori/tomcat:/usr/local/apache-tomcat-9.0.8/webapps/test \
-v /home/satori/tomcat/tomcat9logs/:/usr/local/apache-tomcat-9.0.8/logs \
--privileged=true tomcat9
可以自己测试一下,随便下载一个 JDK 和 tomcat 即可。
1.9.9 docker 安装 mysql
虽然讲究容器化部署,但对于数据库来说,还是很少使用容器的。

然后执行几条 SQL。

结果没有任何问题。
1.10 docker 网络
当你开始大规模使用 docker 时,那么网络问题就成为你不得不面对的事情了,虽然 docker 本身很优秀,但在网络方面其实还是不完善的,所以我们有必要了解一下 docker 的网络。尽管到目前为止,即使我们不了解网络,依旧可以使用 docker 正常开发,但这仅限于单个容器。如果多个容器互相通信,那么网络就是不得不考虑的一个问题了。
首先安装完 docker 时,它会自动创建三个网络:bridge(创建容器默认连接到此网络)、 none 、host。它们的特点如下:
bridge:此模式会为每一个容器分配、设置 IP 等,并将容器连接到一个名为 docker0 的虚拟网桥,通过 docker0 网桥以及 iptables nat 表配置与宿主机通信
host:容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口
none:该模式关闭了容器的网络功能

docker 内置这三个网络,运行容器时可以使用 --network 标志来指定容器应连接到哪些网络。不指定的话,docker 守护进程默认将容器连接到 bridge 网络。
docker run -it --network bridge centos
docker run -it --network host centos
docker run -it --network none centos
那么这几个网络有什么区别呢?我们来聊一聊。
1.10.1 host 模式
相当于 Vmware 中的桥接模式,与宿主机在同一个网络中,但没有独立的 IP 地址。
我们知道 docker 使用了 Linux 的 Namespaces 技术来进行资源隔离,如 PID Namespace 隔离进程,Mount Namespace 隔离文件系统,Network Namespace 隔离网络等。
一个 Network Namespace 提供了一份独立的网络环境,包括网卡、路由、Iptable 规则等都与其他的 Network Namespace 隔离。一个 docker 容器默认会分配一个独立的 Network Namespace,但如果启动容器的时候使用 host 模式,那么这个容器将不会获得独立的 Network Namespace,而是和宿主机共用一个 Network Namespace。容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。

1.10.2 container模式
其实还有一个 container 模式,在理解了 host 模式后,这个模式也就好理解了。这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其它的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
1.10.2 none 模式
该模式将容器放置在它自己的网络栈中,但是并不进行任何配置。实际上,该模式关闭了容器的网络功能,适用于容器不需要网络的场景(例如只需要写磁盘卷的批处理任务)。
docker 在 1.7 版本对代码进行了重构,单独把网络部分独立出来编写,所以在 docker1.8 还新加入了一个 overlay 网络模式。docker 对于网络访问的控制也是在逐渐完善的。
1.10.3 bridge 模式
相当于 Vmware 中的 Nat 模式,容器使用独立的 Network Namespace,并连接到 docker0 虚拟网卡(默认模式),通过 docker0 网桥以及 Iptables nat 表配置与宿主机通信。bridge 模式是 docker 默认的网络设置,此模式会为每一个容器分配 Network Namespace、设置 IP 等,并将它们都连接到一个虚拟网桥(docker0)上。下面着重介绍一下此模式。
当 docker server 启动时,会在主机上创建一个名为 docker0 的虚拟网桥,此主机上启动的容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。接下来就要为容器分配 IP 了,docker 会从 RFC1918 所定义的私有 IP 网段中,选择一个和宿主机不同的 IP 地址和子网分配给 docker0,连接到 docker0 的容器就从这个子网中选择一个未占用的 IP 使用。一般 docker 会使用 172.17.0.0/16 这个网段,并将 172.17.0.1/16 分配给 docker0 网桥(在主机上使用 ifconfig 命令是可以看到 docker0 的,可以认为它是网桥的管理接口,在宿主机上作为一块虚拟网卡使用)。
单机环境下的网络拓扑如下,主机地址为172.24.60.6/18。

docker 完成以上网络配置的过程大致是这样的:
- 在主机上创建一对虚拟网卡 veth pair 设备。veth 设备总是成对出现的,它们组成了一个数据的通道,数据从一个设备进入,就会从另一个设备出来。因此,veth 设备常用来连接两个网络设备。
- docker 将 veth pair 设备的一端放在新创建的容器中,并命名为 eth0。另一端放在主机中,以 veth65f9 这样类似的名字命名,并将这个网络设备加入到 docker0 网桥中。
- 从 docker0 子网中分配一个 IP 给容器使用,并设置 docker0 的 IP 地址为容器的默认网关。
1.10.4 相关命令
下面来看看 docker 中和网络相关的命令。
docker network inspect 网络:查看一个网络的具体信息
docker network create -d bridge 网络:创建一个网络

当然我们也可以使用 docker network rm 网络:来删除我们创建的网络,注意:docker自带的不可以删除。

还可以使用 docker network prune:删除所有未被使用的网络。
如果我们想将某个容器连接到指定的网络上的话,可以通过 “docker network connect 网络 容器” 的方式。还可以通过 “docker network disconnect 网络 容器” 将容器从连接的网络上取消。
问题来了,两个容器如何互相连接呢?在创建容器的指定 --link 即可。
- docker run -it --link 连接的容器:给连接的容器起的别名 -d 网络 镜像

此时新建的 co2 容器就和 co1 容器进行的连接,在 co2 里面可以直接和 co1 通信,注意:这里起的别名也叫 co1,如果连接的容器的名字比较长,那么可以起一个别名,用别名也是可以通信的。如果创建容器时,没有使用 --link 连接的话,那么容器之间是无法访问的。

1.11 小结
以上就是 docker 相关的内容,掌握以上这些,完全可以学习 k8s 了。总之未来云原生是主流,我们一定要掌握它。
2 云原生和分布式系统的存储基石etcd的介绍、架构和概念解析
2.1 引言
etcd负责 k8s 元数据的存储,k8s 的状态数据全部存储在 etcd 上面。随着 k8s 的火热,etcd 也越来越受到重视,截止到此刻,它在 GitHub 的 star 数已经达到了 43.5k,很多软件工程师都在使用 etcd 去解决业务场景中遇到的痛点。etcd 的使用场景非常广泛,从服务发现到分布式锁,从配置存储到分布式协调等等,可以这么说,etcd 已经成为了云原生和分布式系统的存储基石。
另外 etcd 作为最热门的云原生存储之一,也被大量公司应用在和 k8s 无关的业务上。因此哪怕后续你不从事 k8s 开发,我觉得 etcd 也是有必要掌握的。

那么问题来了,etcd 说到底就是个分布式键值对存储系统,负责存储各种元数据。而说到键值对存储系统,很多人首先会想到 zookeeper,它起源于 hadoop,历史比 etcd 更加悠久,具有成熟、健壮以及丰富的特性,那 k8s 为啥不选择 zookeeper 呢?原因有以下几点:
1)zookeeper 的部署和维护比较复杂,管理员需要掌握一系列的知识和技能。而 zookeeper 所使用的 Paxos 强一致性算法也是以复杂难懂而闻名于世;
2)java 编写,由于 java 偏向于重型应用,会引入大量的依赖。而运维人员则希望保持强一致、高可用的机器集群尽可能简单,维护起来也不容易出错;
3)发展缓慢,Apache基金会庞大的结构以及松散的管理导致项目发展缓慢;
而现在 etcd 是更好的选择,与 zookeeper 相比它更简单,安装、部署和使用更加容易,并且 etcd 的某些功能是 zookeeper 所没有的。因此 etcd 比 zookeeper 更受用户的青睐,具体表现在如下几个方面:
1)etcd 更加稳定可靠,它的唯一目标就是把分布式一致性键值对存储系统做到极致,所以它更注重稳定性和扩展性;
2)在服务发现的实现上,etcd 使用的是节点租约(Lease),并且支持 Group(多key);而 zookeeper 使用的是临时节点,临时节点存在不少的问题,这些问题后面会提到;
3)etcd 支持稳定的 watch(监视 key 的变更),而不是像 zookeeper 那样使用简单的单次触发式(one time trigger)watch。因为在未来微服务的环境下,通过调度系统调度,一个服务随时可能会下线,也可能为应对临时的访问压力而增加新的服务节点,而很多调度系统是需要得到完整的节点历史记录的。在这方面,etcd 表现的更优秀,可以存储数十万个历史变更;
4)etcd 支持 MVCC(多版本并发控制),因为有协同系统需要无锁操作;
5)etcd 支持更大的数据规模,支持存储百万到千万级别的 key;
6)etcd 的性能比 zookeeper 更好,在一个由 3 台 8 核节点组成的云服务器上,etcd v3 版本可以做到每秒数万次的写操作和数十万次的读操作;
etcd 这么优秀,还有什么理由不去学习它呢?下面就来开始 etcd 的学习。
2.2 初识 etcd
我们说 etcd 是一个分布式键值对存储系统,那么官方是怎么定义它的呢?
A highly-available key value store for shared configuration and service discovery
所以 etcd 是一个分布式、高可用的一致性键值对存储系统,用于提供可靠的分布式键值存储、配置共享和服务发现等功能。etcd 以一致和容错的方式存储数据和实现分布式调度,在现代化的集群运行中起到关键性的作用。常见的 etcd 使用场景包括:服务发现、分布式锁、分布式数据队列、分布式通知和协调、主备选举等等。
补充:对于一个分布式系统来说,分布式数据存储功能是必不可少的,如果不支持数据分布式存储,那么这个系统就不能叫分布式。因此当你想自己实现一个分布式系统时,那么不妨把分布式存储的功能交给 etcd 负责吧。
另外 etcd 采用的是强一致性模型,基于 Raft 协议,通过复制日志文件的方式来保证数据的强一致性。当客户端写入一个键值对时,首先会存储到 etcd 集群的 Leader 上,然后再通过 Raft 协议复制到 etcd 集群的所有成员中,以此维护各成员(节点)状态的一致性与 可靠性。虽然 etcd 是一个强一致性的系统,但也支持从非 Leader 节点读取数据以提高性能,但是写操作仍然需要 Leader,所以当发生网络分区时,写操作仍可能失败。
关于 Raft 协议,etcd 专门提供了 Go 语言版本的代码实现 ,并广泛应用于各种项目,除了 etcd 之外,还包括 docker swarm kit等。
然后作为一个分布式系统,etcd 的容错能力也是不错的。假设集群中共有 n 个节点,即便集群中 (n - 1) / 2 个节点发生了故障,只要剩下的 (n + 1) / 2 个节点达成一致,也能操作成功,因此它能够有效地应对网络分区和机器故障带来的数据丢失风险。
2.3 etcd 架构简介
etcd 在设计的时候重点考虑了如下的四个要素。
-
简单
- 支持 RESTful 风格的 HTTP+JSON API
- 从性能角度考虑,etcd 增加了对 gRPC 的支持,同时也提供 rest gateway 进行转化
- 使用 Go 语言编写,跨平台、部署和维护简单
- 使用 Raft 算法保证强一致性,Raft 算法可理解性好
-
安全
支持 TLS 客户端安全认证 -
性能
单实例支持每秒一千次以上的写操作(v2 版本),极限写性能可达 10K+ 的QPS(v3 版本),现在都用 v3 不用 v2 了 -
可靠
使用 Raft 算法充分保证了分布式系统数据的强一致性;etcd 集群是一个分布式系统,由多个节点相互通信构成整体对外服务,每个节点都存储了完整的数据,并且通过 Raft 协议保证了每个节点维护的数据都是一致的
简单地说,etcd 可以扮演两大角色,具体如下:
- 持久化的键值存储系统
- 提供分布式系统的数据一致性
在分布式系统中,如何管理节点间的状态一直是一个难题,etcd 像是专门为集群环境的服务发现和注册而设计的。它提供了数据 TTL 失效、数据改变监视、多值、目录、分布式锁原子操作等功能,可以方便地跟踪并管理集群节点的状态。
etcd 大体上可以分为如下几个部分:

按照分层模型,etcd 可以分为客户端、API 网络层、Raft 算法层、逻辑层和存储层,这些层的功能如下。
-
客户端:和 zookeeper 一样,etcd 也提供了一个客户端(etcdctl),可以直接输入命令让 etcd 服务端执行。当然客户端也可以是 Python、Go 等编程语言实现的客户端,并且 API 有 v2 和 v3 两个版本,现在用 v3 即可;
-
API 网络层:主要包括 client 访问 server、以及 server 之间通信(当通过 Raft 算法实现数据复制、以及 Leader 选举时)所使用的协议,v2 API 使用 HTTP/1.1 协议,v3 API 使用 gRPC 协议。同时 v3 API 通过 etcd grpc-gateway 组件也支持 HTTP/1.1,便于各种语言的服务调用;
-
Raft 算法层:实现了 Leader 选举、日志复制、ReadIndex 等核心算法特性,用于保障 etcd 多个节点间的数据一致性、提升服务可用性等,是 etcd 的基石和亮点;
-
功能逻辑层:etcd 核心特性实现层,如典型的 KVServer 模块、MVCC 模块、Auth 鉴权模块、Lease 租约模块、Compactor 压缩模块等,其中 MVCC 模块主要由 treeIndex 模块和 boltdb 模块组成;
-
存储层:存储层包含预写日志(WAL)模块、快照(Snapshot)模块、boltdb 模块,其中 WAL 可保障 etcd 宕掉后数据不丢失,因为所有的数据提交前都会先写入日志。Snapshot 是为了防止数据过多而进行的状态快照,boltdb 负责保存集群元数据和用户写入的数据(提交前先写入 WAL);
当一个请求到来时,API 层会先转发给逻辑层进行具体的事务处理,如果涉及到节点的修改,则交给 Raft 层进行仲裁和日志记录。而 etcd 是采用 Raft 协议的 Leader-Follower 架构,满足以下几个特点: -
多个副本节点中,有且只有一个副本会被指定为「领导者」,它是整个分布式系统中的霸道总裁,一切都要以它为准。当客户端要向系统中写入数据时,它必须将请求发给领导者,领导者会将其持久化到 WAL 中;
-
其它副本被称为「追随者」,每当领导者将数据持久化到 WAL 时,它也会将数据变更广播给追随者,这个过程就是「复制日志」。每个追随者从领导者拉取日志,并相应更新本地的副本,并且顺序和领导者写入的顺序保持一致;
-
当客户端想从系统读取数据时,它可以向领导者或追随者查询,但只有领导者才能接收写操作(从客户端的视角来看,追随者都是只读的);
然后重点来了,领导者将新请求的数据持久化到 WAL 的时候,还会广播给其它节点。如果有一半以上的节点成功完成 WAL 持久化,则该请求对应的日志条目就会被标记为已提交,然后异步拉取已提交的日志条目,并应用到状态机(boltdb)。
而为了保证数据的强一致性,etcd 集群中所有的数据流向都是一个方向,从 Leader(主节点)流向 Follower,也就是所有 Follower 的数据必须与 Leader 保持一致,如果不一致会被覆盖。
简单点说就是,客户端可以对 etcd 集群中的所有节点进行读写。首先读取非常简单,因为每个节点保存的数据是强一致的。对于写入来说,etcd 集群会选举出 Leader 节点,如果写入请求来自 Leader 节点,则可以直接写入,然后 Leader 节点会把写入分发给所有的 Follower;如果写入请求来自其它 Follower 节点,那么写入请求会给转发给 Leader 节点,由 Leader 节点写入之后再分发给集群上所有其它节点。
2.4 etcd 典型应用场景
正如上面介绍的那样,etcd 的定位是通用的一致性 key/value 存储,但也有服务发现和共享配置的功能。因此典型的 etcd 应用场景包括但不限于分布式数据库、服务注册与发现、分布式锁、分布式消息队列、分布式系统选主等 。etcd 的定位是通用的一致性 key/value 存储,同时也面向服务注册与发现的应用场景。下面将对 etcd 的一些典型应用场景进行简单概括。
2.4.1 服务注册与发现
服务发现(Service Discovery)要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。从本质上说,服务发现就是要了解集群中是否有进程在监听指定的 UDP 或 TCP 端口,并且通过名字就可以进行查找和链接。而要解决服务发现的问题,需要具备如下三个条件:
-
需要一个强一致性、高可用的服务存储目录,而基于 Raft 算法的 etcd 天生就完美符合这一点。
-
可以对服务进行注册,并且还能监控服务的健康状况;而用户可以在 etcd 中注册服务,并且对注册的
服务配置 key TTL,定义保持服务的心跳以达到监控健康状态的效果。 -
具备查找和连接服务的机制,在 etcd 指定的主题下注册的服务也能在该主题下被找到;为了确保连接,我们可以在各个服务机器上都部署一个代理模式的 etcd,这样就可以确保访问 etcd 集群的服务都可以互相连接。

图上有三个角色,分别是服务请求方、服务提供方、服务注册方。假设有三台机器:A、B、C,用于提供邮件发送服务,这个时候服务请求方如果想要使用邮件发送服务,那么就会去找服务提供方。但服务请求方并不是直接寻找服务提供方,因为它不知道提供请求的是谁,所以它会寻找服务注册方,然后服务注册方将服务提供方的信息返回给服务请求方,比如:返回 A、B、C 的 IP 和端口,表示这三台机器是用来提供服务的。
但是服务注册方如何才能准确返回服务提供方的信息呢?显然服务提供方是要先进行注册的,服务注册方保存了提供方的信息。并且提供方还要不断地向注册方发送心跳信息,表示自己还活着。假设 B 机器挂掉了,那么请求方向注册方寻找服务方的时候,注册方就不会再返回 B 机器的信息了。所以服务请求方首先找的是服务注册方,而我们的 etcd 充当的就是服务注册方这一角色,当然 zookeeper 也是类似。
2.4.2 消息发布和订阅
在分布式系统中,组件之间的通信机制最为适用的是消息的发布和订阅机制。具体而言就是,设置一个配置共享中心,消息提供者在这个配置中心发布消息,而消息使用者则订阅它们关心的主题,一旦所关心的主题有消息发布,就会实时通知订阅者。通过这种方式,我们可以实现分布式系统配置的集中式管理和实时动态更新,比如:
etcd 管理应用配置信息更新
这类场景的使用方式通常是,应用在启动的时候主动从 etcd 获取一次配置信息,同时在 etcd 节点上注册 Watcher 并等待。以后每当配置有更新的时候,etcd 都会实时通知订阅者,以此达到获取最新配置信息的目的。
分布式日志收集系统
这个系统的核心工作是收集分布在不同机器上的日志。
收集器通常按应用(或主题)来分配收集任务单元,因此可以在 etcd 上创建一个以应用(或主题)为名字的目录,并将这个应用(或主题)相关的所有机器 IP 以子目录的形式存储在目录下。然后设置一个递归的 etcd Watcher,递归式地监控应用(或主题)目录下所有信息的变动。这样就能够实现在节点 IP(消息)发生变动时,系统能够实时接受收集器调整的任务分配。
2.4.3 负载均衡
在分布式系统中,为了保证服务的高可用以及数据的一致性,通常都会把数据和服务部署为多份,以此达到对等服务,即使其中的某一个服务失效了,也不会影响使用。
这样的实现虽然会导致一定程度上数据写入性能的下降,但是却能够实现数据访问时的负载均衡 。因为每个对等服务节点上都存储有完整的数据,因此所有用户的访问流量都可以分流到不同的机器上。
分布式通知与协调
这里讨论的分布式通知与协调,和消息的发布订阅有点相似。两者都使用了 etcd 的 Watcher 机制,通过注册与异步通知机制, 实现分布式环境下不同系统之间的通知与协调,从而对数据变更进行实时处理。
实现方式是不同的系统都在 etcd 上对同一个目录进行注册,同时设置 Watcher 监控该目录的变化(如果子目录的变化也有需求,那么可以设置成递归模式)。若某个系统更新了 etcd 的目录,那么设置了 Watcher 的系统就会收到通知,并也做出相应的通知,然后进行相应的处理。
2.4.4 分布式锁
因为 etcd 使用 Raft 算法保证了数据的强一致性,操作之后存储到集群中的值就必然是全局一致的,所以 etcd 很容易实现分布式锁。
而锁服务包含两种使用方式:保持独占,以及控制时序。
保持独占
即所有试图获取锁的用户最终只有一个可以得到。etcd 为此提供了一套实现分布式锁原子操作 CAS(ComparaAndSwap)的 API,通过设置 prevExist 值,可以保证在多个节点上同时创建某个目录时,只有一个节点能够成功,而成功的那个即可获得分布式锁。
控制时序
试图获取锁的所有用户都会进入等待队列,获得锁的顺序是全局唯一的,同时还能决定队列的执行顺序。etcd 为此也提供了一套 API(自动创建有序键),它会将一个目录的键值指定为 POST 动作,这样 etcd 就会在目录下生成一个当前最大的值作为 key。
同时还可以使用 API 按顺序列出所有目录下的键值,此时这些 key 就是客户端的时序,而 value 则可以是代表客户端的编号。

2.4.5 分布式队列
分布式队列的常规用法与分布式锁的控制时序类似,即通过创建一个先进先出的队列来保证顺序。
另一种比较有意思的实现是在保证队列达到某个条件时再统一按顺序执行,要实现这种方法,可以创建一个 /queue 目录,然后在里面另外建立一个 /queue/condition 节点,如图所示:

condition 可以表示队列的大小,比如一个大的任务需要在很多小任务都就绪的情况下才能执行,那么每当有一个小任务就绪时,就将这个 condition 的数值加 1,直到到达大任务规定的数字,然后再开始执行队列里的一系列小任务,直至最终执行大任务。
condition 可以表示某个任务不在队列中,这个任务既可以是所有排序任务的首个执行程序,也可以是拓扑结构中没有依赖的点。通常必须在执行这些任务之后才能执行队列中的其他任务。
condition 还可以表示开始执行任务的通知,可以由控制程序来指定,当 condition 发生变化时,开始执行队列任务。
2.4.6 集群监控与 Leader 竞选
通过 etcd 来进行监控的功能实现起来非常简单并且实时性较强,主要会用到如下两点特性:
前面几个场景已经提到了 Watcher 机制,当某个节点消失或发生变动时,Watcher 会第一时间发现并告知用户;
节点可以设置 TTL key,比如每隔 30s 向 etcd 发送一次心跳信号,代表该节点依然存活着,否则就说明节点已经消失了;
这样就可以第一时间检测到各节点的健康状态,以完成集群的监控要求。
另外,使用分布式锁还可以完成 Leader 竞选,并且对于一些需要长时间进行 CPU 计算或使用 I/O 的操作,只需要由竞选出 Leader 计算或处理一次,再把结果复制给其他的 Follower 即可,从而避免重复劳动,节省计算资源。
Leader 应用的经典场景是在搜索系统中建立全量索引,如果各个机器都进行索引的建立,那么将很难保证索引的一致性。通过 etcd 的 CAS 机制竞选 Leader,再由 Leader 进行索引计算,最后将计算结果分发到其它节点即可。
2.5 etcd 与其它键值存储系统的对比
这里我们主要探讨 etcd 和 zookeeper 之间的区别。zookeeper 是一个用于维护配置信息 、命名、分布式同步以及分组服务的集中式服务框架,它使用 Java 语言编写,通过 Zab 协议来保证节点的一致性。因为 zookeeper 是一个 CP 型系统,所以在发生网络分区问题时,系统不能注册或查找服务。
zookeeper 和 etcd 可用于解决的问题:分布式系统的协同和元数据存储。然而,etcd 却有着 zookeeper 的设计和实现的后见之明,zookeeper 最大的问题就是太复杂了,etcd 吸取了 zookeeper 的教训后具备更好的工程和运维体验。相比 zookeeper,etcd 的改进之处在如下几个方面:
动态的集群节点关系重配置
高负载条件下的稳定读写
多版本并发控制的数据模型
持久、稳定的 watch,而不是简单的单次触发式 watch。zookeeper 的单次触发式 watch 是指监听到一次事件之后,需要客户端重新发起监听,这样 zookeeper 服务器在接收到客户端的监听请求之前的事件是获取不到的;而且在两次监昕请求的时间间隔内发生的事件,客户端也是没法感知的。etcd 的持久监听是每当有事件发生时,就会连续触发,不需要客户端重新发起监听;
租约(lease)原语实现了连接和会话的解耦
安全的分布式共享锁 API
另外 etcd 广泛支持各种各样的语言和框架,但 zookeeper 只有它自己的客户端协议:Jute RPC 协议。 Jute 是 zookeeper 独一无二的协议,且只在特定的语言库(Java 和 C)中绑定。etcd 的客户端协议 gRPC,它是一个流行的 RPC 框架,支持的语言非常多。gRPC 也能序列化成通过 HTTP 传输的 JSON,所以通用的命令行工具 curl 也能与它进行交互。这就为分布式系统的构建者提供了丰富的选择,他们能够用操作系统原生的工具来构建,而不是非得围绕 etcd 用指定的技术,也就是无需迎合 etcd,而是让 etcd 配合你。
至于其它的分布式键值存储系统就不对比了,总之 etcd 绝对是脱颖而出的。
2.7 etcd 相关概念
etcd 中存在许多概念,或者说术语,来看一下,先有一个印象。
- Raft:etcd 所采用的保证分布式系统强一致性的算法
- Node:一个 Raft 状态机实例,就是里面的 boltdb
- Member:一个 etcd 实例,它管理着一个 Node,并且可以为客户端请求提供服务
- Cluster:由多个 Member 构成的,遵循 Raft 一致性协议的 etcd 集群
- Peer:对同一个 etcd 集群中的其它 Member 的叫法
- Client:客户端,凡是连接 etcd 服务器请求服务的,比如获取 key-value、写数据等等,都统称为 - Client;所以 etcd 命令行连接工具、编写的连接 etcd 服务的代码对应的进程都是 Client
- Proposal:一个需要经过 Raft 一致性协议的请求,例如写请求或配置更新请求
- Quorum:Raft 协议需要的、能够修改集群状态的、活跃的 etcd 集群成员数量称为 Quorum(法定人数)。etcd 使用仲裁机制,若集群中存在 n 个节点,那么有 (n+ 1) / 2 个节点达成一致,则操作成功。所以建议的最优节点数 3、5、7、9,也就是奇数个。大多数用户场景中, 一个包含 7 个节点的集群是足够的,更多的节点(比如 9、11 等)可以最大限度地保证数据安全,但是写性能会受影响,因为需要向更多的节点写入数据
- WAL:预写式日志,etcd 用于持久化存储的日志格式
- Raft:etcd 集群在某一时间点的快照(备份),etcd 为防止 WAL 文件过多而设置的快照,用于存储 etcd 的数据状态
- Proxy:etcd 的一种模式,为 etcd 集群提供反向代理服务
- Leader:Raft 算法中通过竞选而产生的负责客户端写请求的节点,即领导者节点
- Follower:如果竞选失败没能成为 Leader,那么节点会自动成为 Raft 中的 Follower 节点,即追随者节点,负责为算法提供强一致性保证
- Candidate:Follower 超过一定的时间接收不到 Leader 的心跳时,它会认为 Leader 已经挂掉了,于是决定咸鱼翻身成为 Leader。但想成为 Leader 需要竞选,而竞选需要节点从 Follower 转变为 - Candidate,然后才能发起投票
- Term:某个节点从成为 Leader 到下一次竞选的时间,称为一个 Term
- IndexWAL 日志数据项编号,在 Raft 中通过 Term 和 Index 来定位数据
- Key:键
- Key space:键空间,etcd 集群内所有键的集合
- Revision:etcd 集群范围内 64 位的计数器,键空间的每次修改都会导致该计数器的增加
- Modification Revision:一个 key 最后一次修改的 revision
- Lease:一个短时的(会过期)、可续订的契约(租约),当它过期时,会删除与之关联的所有键
- Transition:事务,一个自动执行的操作集,要么一块成功,要么一块失败
- Watcher:观察者,etcd 最具特色的概念之一。客户端通过打开一个观察者来获取一个指定键范围的更新
- Key Range键范围,一个键的集合。这个集合既可以是一个 key、也可以是在一个字典区间,例如(a, b],或者是大于某个 key 的所有 key
- Endpoint:指向 etcd 服务或资源的 URL
- Compaction:etcd 的压缩(Compaction)操作,丢弃所有 etcd 的历史数据并且取代一个给定 - revision 之前的所有 key;压缩操作通常用于重新声明 etcd 后端数据库的存储空间,和 Raft 的日志压缩是一个原理
- Key version:键版本,即一个键从创建开始的写(修改)次数,从 1 开始;一个不存在或已删除的键版本是 0,注意 key version 和 revision 的概念不同
2.8 etcd 发展里程碑
etcd 已经进化到 3.x 版本了,发展到现在总共有 3 个可以成为里程碑的版本,分别是 0.4、2.0、3.0,我们分别介绍一下。
etcd 0.4
该版本是 etcd 对外发布的第一个稳定版本,很多特性均在这个版本成型。比如以下几个特性:
- 使用 Raft 算法做分布式协同
- HTTP + JSON 的 API
- 使用 SSL 客户端证书验证
- 基准测试在每个实例中每秒写入 1000 次等等
etcd 2.0
该版本是 etcd 第一个真正意义上的大版本,其引入了如下几个重要特性:
- 内部 etcd 协议的优化能够有效避免意外的错误配置
- etcdctl 增加了 backup 子命令, 便于从集群异常中恢复数据
- 运行时动态更新集群 member 配置, 通过 etcdctl 客户端的 member 子命令: etcd member - list/add/remove 可以动态查看集群信息和调整集群大小
- 通过 CRC校验 和append-only的行为提高了存盘数据的安全性
- 优化的 Raft 一致性算法实现, 该实现被其他项目, 例如 CockroachDB 引用
- etcd 的 TCP 2379/2380 端口正式成为 IANA(The Internet Assigned Numbers Authority, 互联网数字分配机构)官方分配的端口; 变得更有名了, 比如提到3306你会想到MySQL、提到6379你会想到Redis
etcd 3.0
该版本在 etcd 2.0 的基础上引入了多处优化,可以说是万众瞩目,千呼万唤始出来,并且一经发布即引起了巨大的轰动。优化内容具体如下:
- 提升了整体吞吐率、降低了延迟, 通过 gRPC API 降低了 Raft 协议调用的开销, 提高了 WAL 的磁盘利用率
- 全新的存储后端带来了每个 key 平均内存开销的减少
- 自动的 TLS 配置(可能需要用户提供 ca 证书)
- 扁平的二进制键空间, 摒弃了 v2 的 key-value 层级和目录
- 全新的 v3 API, 支持基于 key 为前缀和范围的 get/watch
- 多版本的键空间, 允许访问历史版本的 key
- 事务, 将对 etcd 服务的多个请求合并成一个操作
- 租约, 允许一组 key 共享一个 TTL
- 监控/告警, 通过存储配额保护 etcd 免受偶然发生的超额使用
以上就是 etcd 的几个著名的版本,如果想要更加详细地了解 etcd 的变迁,可以查看 etcd 发布的各个版本的 CHANGELOG。对于我们现在来说,使用 3.x 的版本就行。