XGBoost的参数
目录
1. 迭代过程
1.1 迭代次数/学习率/初始最大迭代值
1.1.1 参数num_boost_round & 参数eta
1.1.2 参数base_score
1.1.3 参数max_delta_step
1.2 xgboost的目标函数
1.2.1 gamma对模型的影响
1.2.2 lambda对模型的影响
2. XGBoost的弱评估器
2.1 三大评估器与DART树
2.1.1 参数booster
2.1.2 参数rate_drop、one_drop、skip_drop、sample_type、normalize_type
2.2 弱评估器的分枝
2.3 控制复杂度(一):弱评估器的剪枝
2.4 控制复杂度(二):弱评估器的训练数据
2.4.1 样本的抽样
2.4.2 特征的抽样
3. XGBoost的其他参数与方法
3.1 提前停止
3.2 模型监控与评估
3.3 样本不均衡
3.4 并行的线程
由于xgboost本身是一个复杂的算法系统,其超参数的数量十分惊人,现将可能用到的参数总结在了如下表格当中:
| 类型 | 参数 |
|---|---|
| 迭代过程/目标函数 | params: eta, base_score, objective, lambda, gamma, alpha, max_delta_step xgb.train(): num_boost_round |
| 弱评估器结构 | params: max_depth, booster, min_child_weight |
| dart树 | params: sample_type, normalized_type, rate_drop, one_drop, skip_drop |
| 弱评估器的训练数据 | params: subsample, sampling_method, colsamle_bytree, colsample_bylevel, colsample_bynode |
| 提前停止 | xgb.train(): early_stopping_rounds, evals, eval_metric |
| 其他 | params: seed, verbosity, scale_pos_weight, nthread |
1. 迭代过程
1.1 迭代次数/学习率/初始 最大迭代值
最大迭代值
1.1.1 参数num_boost_round & 参数eta
作为Boosting算法,XGBoost的迭代流程与GBDT高度相似,因此XGBoost自然也有设置具体迭代次数的参数num_boost_round、学习率参数eta以及设置初始迭代值的base_score。具体来说,对于样本![]() ,集成算法当中一共有棵树,则参数
,集成算法当中一共有棵树,则参数num_boost_round的取值为K。假设现在正在建立第个弱评估器,则第个弱评估器上![]() 的结果可以表示为
的结果可以表示为![]() (
(![]() )。假设整个Boosting算法对样本
)。假设整个Boosting算法对样本![]() 输出的结果为(
输出的结果为(![]() ),则该结果一般可以被表示为k=1~k=K过程当中,所有弱评估器结果的加权求和:
),则该结果一般可以被表示为k=1~k=K过程当中,所有弱评估器结果的加权求和:
![]()
其中,![]() 为第k棵树的权重。特别的,XGBoost算法不计算树权重,因此XGBoost的输出结果为:
为第k棵树的权重。特别的,XGBoost算法不计算树权重,因此XGBoost的输出结果为:
![]()
对于第次迭代来说,则有:
![]()
在这个一般过程中,每次将本轮建好的决策树加入之前的建树结果时,可以增加参数,表示为第k棵树加入整体集成算法时的学习率,对标参数eta。
![]()
该学习率参数控制Boosting集成过程中(![]() )的增长速度,是相当关键的参数。当学习率很大时,(
)的增长速度,是相当关键的参数。当学习率很大时,(![]() )增长得更快,所需的
)增长得更快,所需的num_boost_round更少,当学习率较小时,(![]() )增长较慢,所需的
)增长较慢,所需的num_boost_round就更多,因此boosting算法往往会需要在num_boost_round与eta中做出权衡。在XGBoost当中,num_boost_round的默认值为10,eta的默认值为0.3。
1.1.2 参数base_score
在上述过程中,我们建立第一个弱评估器时有:
![]()
由于没有第0棵树的存在,因此![]() ()的值在数学过程及算法具体实现过程中都需要进行单独的确定,而这个值就由
()的值在数学过程及算法具体实现过程中都需要进行单独的确定,而这个值就由base_score确定。在xgboost中,我们可以对base_score输入任何数值,但并不支持类似于GBDT当中输入评估器的操作。当不填写时,该参数的默认值为0.5,即对所有样本都设置0.5为起始值。当迭代次数足够多、数据量足够大时,调整算法的![]() ()意义不大,因此我们基本不会调整这个参数。
()意义不大,因此我们基本不会调整这个参数。
1.1.3 参数max_delta_step
在迭代过程当中,XGBoost有一个独特的参数max_delta_step。这个参数代表了每次迭代时被允许的最大![]() (
(![]() )。当参数
)。当参数max_delta_step被设置为0,则说明不对每次迭代的![]() (
(![]() )大小做限制,如果该参数被设置为正数C,则代表
)大小做限制,如果该参数被设置为正数C,则代表![]() (
(![]() )≤,当
)≤,当![]() (
(![]() )大于时算法执行:
)大于时算法执行:
![]()
通常来说这个参数是不需要的,但有时候这个参数会对极度不均衡的数据有效。如果样本极度不均衡,那可以尝试在这个参数中设置1~10左右的数。
总结:
| 参数含义 | 原生代码 | sklearn API |
|---|---|---|
| 迭代次数/树的数量 | num_boost_round (xgb.train) |
n_estimators |
| 学习率 | eta (params) |
learning_rate |
| 初始迭代值 | base_score (params) |
base_score |
| 一次迭代中所允许的最大迭代值 | max_delta_step (params) |
max_delta_step |
1.2 xgboost的目标函数
与GBDT不同的是,xgboost并不向着损失函数最小化的方向运行,而是向着令目标函数最小化的方向运行。需要注意的是,损失函数可以针对单个样本进行计算,也可以针对整个算法进行计算,但在XGBoost的定义中,目标函数是针对每一棵树的,而不是针对一个样本或整个算法。对任意树![]() 来说,目标函数有两个组成部分,一部分是任意可微的损失函数,它控制模型的经验风险。从数值上来说,它等于现在树上所有样本上损失函数之和,其中单一样本的损失为
来说,目标函数有两个组成部分,一部分是任意可微的损失函数,它控制模型的经验风险。从数值上来说,它等于现在树上所有样本上损失函数之和,其中单一样本的损失为![]() 。另一部分是控制模型复杂度的Ω(
。另一部分是控制模型复杂度的Ω(![]() ),它控制当前树的结构风险。
),它控制当前树的结构风险。
![]()
其中表示现在这棵树上一共使用了M个样本,表示单一样本的损失函数。当模型迭代完毕之后,最后一棵树上的目标函数就是整个XGBoost算法的目标函数。
-
经验风险:模型对数据学习越深入,损失越小(经验风险越小),模型对数据学习得越浅显,损失越大(经验风险越大)。
-
结构风险:树结构越复杂、模型复杂度越高,过拟合风险越大(结构风险越大)。树模型结构越简单、模型复杂度越低、过拟合风险越小(结构风险越小)。
通常来说,模型需要达到一定的复杂度,才能保证较小的损失,但如果只追求最小的经验风险,反而容易导致过拟合。相对的,如果只追求模型复杂度低、结构风险低,那模型又容易陷入欠拟合的困局、损失函数过高,因此平衡结构风险与经验风险十分关键。XGBoost向着目标函数最小化的方向运行,可以保证在迭代过程中,经验风险和结构风险都不会变得太大,因此模型的损失不会太大、同时又不会太容易过拟合。
在具体的公式当中,结构风险Ω(![]() )又由两部分组成,一部分是控制树结构的,另一部分则是正则项:
)又由两部分组成,一部分是控制树结构的,另一部分则是正则项:
![]()
其中,与都是可以自由设置的系数,而表示当前第棵树上的叶子总量,则代表当前树上第片叶子的叶子权重(leaf weights)。叶子权重是XGBoost数学体系中非常关键的一个因子,它实际上就是当前叶子的预测值,这一指标与数据的标签量纲有较大的关系,因此当标签的绝对值较大、值也会倾向于越大。因此正则项有两个:使用平方的L2正则项与使用绝对值的L1正则项,因此完整的目标函数表达式为:
![]()
不难发现,所有可以自由设置的系数都与结构风险有关,这三个系数也正对应着xgboost中的三个参数:gamma,alpha与lambda。
- 参数
gamma:乘在一棵树的叶子总量之前,依照叶子总量对目标函数施加惩罚的系数,默认值为0,可填写任何[0, ∞]之间的数字。当叶子总量固定时,gamma越大,结构风险项越大;同时,当gamma不变时,叶子总量越多、模型复杂度越大,结构风险项也会越大。在以上两种情况下,目标函数受到的惩罚都会越大,因此调大gamma可以控制过拟合。
- 参数
alpha与lambda:乘在正则项之前,依照叶子权重的大小对目标函数施加惩罚的系数,也就是正则项系数。lambda的默认值为1,alpha的默认值为0,因此xgboost默认使用L2正则化。通常来说,我们不会同时使用两个正则化,但也可以尝试这么做。 是当前树上所有叶子的输出值之和,因此当树上的叶子越多、模型复杂度越大时,自然的数值自然会更大,因此当正则项系数固定时,模型复杂度越高,对整体目标函数的惩罚就越重。当固定时,正则项系数越大,整体目标函数越大,因此调大
是当前树上所有叶子的输出值之和,因此当树上的叶子越多、模型复杂度越大时,自然的数值自然会更大,因此当正则项系数固定时,模型复杂度越高,对整体目标函数的惩罚就越重。当固定时,正则项系数越大,整体目标函数越大,因此调大alpha或lambda可以控制过拟合。
| 参数含义 | 原生代码 | sklearn API |
|---|---|---|
| 乘在叶子节点数量前的系数 | gamma (params) |
gamma |
| L2正则项系数 | lambda (params) |
reg_lambda |
| L1正则项系数 | alpha (params) |
reg_alpha |
然而,在实际控制过拟合的过程中,可能经常会出现这几个参数“无效”。比如:
1.2.1 gamma对模型的影响
import xgboost as xgb
from xgboost import XGBRegressor
from sklearn.model_selection import cross_validate, KFold
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
data = pd.read_csv(r"F:\\Jupyter Files\\机器学习进阶\\datasets\\House Price\\train_encode.csv",index_col=0)
#回归数据
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
data_xgb = xgb.DMatrix(X,y)
params_default = {"max_depth":5,"seed":1412}
result_default = xgb.cv(params_default,data_xgb,num_boost_round=100
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
#result_default.iloc[-1,:]
#定义一个函数,用来检测模型迭代完毕后的过拟合情况
def overfitcheck(result):
return (result.iloc[-1,2] - result.iloc[-1,0]).min()
overfitcheck(result_default) #26260.56033687031
train = []
test = []
gamma = np.arange(0,10,1)
overfit = []
for i in gamma:
params = {"max_depth":5,"seed":1412,"eta":0.1
,"gamma":float(i)
}
result = xgb.cv(params,data_xgb,num_boost_round=100
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
overfit.append(overfitcheck(result))
train.append(result.iloc[-1,0])
test.append(result.iloc[-1,2])
plt.plot(gamma,overfit)
plt.plot(gamma,train)
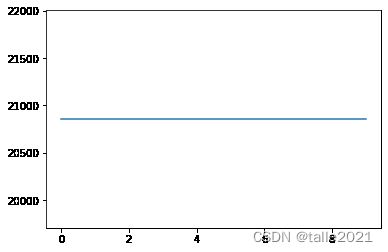

如上所示,训练集结果纹丝不动,过拟合程度也纹丝不动。这是不是gamma失效了呢?实际上,对于没有上限或下限的参数,我们要关注参数的敏感度。如果参数值稍稍移动,模型就变化很大,那参数敏感,如果参数值移动很多,模型才能有变化,那参数不敏感。当树的结构相对复杂时,gamma会比敏感,否则gamma可能非常迟钝。当原始标签数值很大、且叶子数量不多时,lambda和alpha就会敏感,如果原始标签数值很小,这两个参数就不敏感。因此在使用这些参数之前,最好先对参数的敏感程度有一个探索,这里很容易看到:当前树结构不复杂,gamma不敏感。
扩大gamma的范围:
train = []
test = []
gamma = np.arange(0,10000000,1000000)
overfit = []
for i in gamma:
params = {"max_depth":5,"seed":1412,"eta":0.1
,"gamma":float(i)
}
result = xgb.cv(params,data_xgb,num_boost_round=100
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
overfit.append(overfitcheck(result))
train.append(result.iloc[-1,0])
test.append(result.iloc[-1,2])
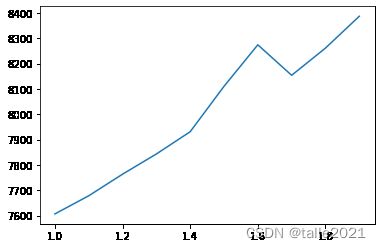
plt.plot(gamma,train)
plt.plot(gamma,test,color="red")
plt.plot(gamma,overfit,color="orange")

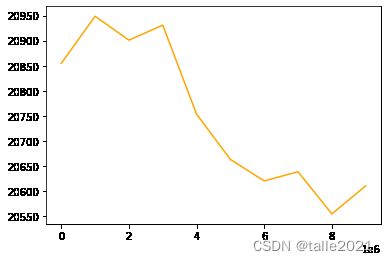
gamma控制过拟合的最好成绩:
min(overfit) #20554.40156281.2.2 lambda对模型的影响
当前数据标签值较大,因此预测标签的值也较大,lambda会更敏感。
train = []
test = []
lambda_ = np.arange(1,2,0.1)
overfit = []
for i in lambda_:
params = {"max_depth":5,"seed":1412,"eta":0.1
,"lambda":float(i)
}
result = xgb.cv(params,data_xgb,num_boost_round=100
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
overfit.append(overfitcheck(result))
train.append(result.iloc[-1,0])
test.append(result.iloc[-1,2])
plt.plot(lambda_,train)
plt.plot(lambda_,test,color="red")
plt.plot(lambda_,overfit,color="orange")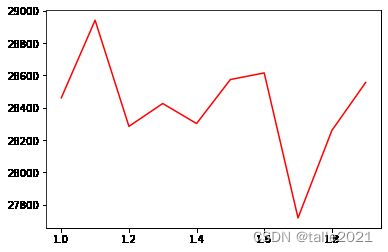
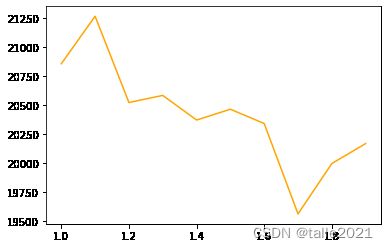
lambda控制过拟合的最好成绩:
min(overfit) #19564.888281400003可见,在当前数据集中,lambda比gamma有效。当然,在实际使用时,并不是在所有数据情况下都如此,需要根据具体情况具体分析。因此在使用和调节这些参数时,要先考虑适合的参数范围,否则再多的搜索也是无用。总结一下,在整个迭代过程中,涉及到了如下参数:
| 类型 | 参数 |
|---|---|
| 迭代过程/损失函数 | num_boost_round:集成算法中弱分类器数量,对Boosting算法而言为实际迭代次数 eta:Boosting算法中的学习率,影响弱分类器结果的加权求和过程 objective:选择需要优化的损失函数(默认为reg:squarederror) base_score:初始化预测结果 max_delta_step:一次迭代中所允许的最大迭代值 gamma:乘在叶子数量前的系数,放大可控制过拟合 lambda:L2正则项系数,放大可控制过拟合 alpha:L1正则项系数,放大可控制过拟合 |
2. XGBoost的弱评估器
2.1 三大评估器与DART树
梯度提升算法当中不只有梯度提升树,也可集成其他模型作为弱评估器,而作为梯度提升树进化版的XGBoost算法,自然也不是只有CART树一种弱评估器。在XGBoost当中,我们还可以选型线性模型,比如线性回归或逻辑回归来集成,同时还可以选择与CART树有区别的另一种树:DART树。在XGBoost当中,使用参数booster来控制所使用的具体弱评估器。
2.1.1 参数booster
参数booster:使用哪种弱评估器。可以输入"gbtree"、"gblinear"或者"dart"。
①输入"gbtree"表示使用遵循XGBoost规则的CART树,XGBoost在GBDT上做出的改善基本都是针对这一类型的树。这一类型的树又被称为“XGBoost独有树”,XGBoost Unique Tree。
②输入"dart"表示使用抛弃提升树,DART是Dropout Multiple Additive Regression Tree的简称。这种建树方式受深度学习中的Dropout技巧启发,在建树过程中会随机抛弃一些树的结果,可以更好地防止过拟合。在数据量巨大、过拟合容易产生时,DART树经常被使用,但由于会随机地抛弃到部分树,可能会伤害模型的学习能力,同时可能会需要更长的迭代时间。
③输入"gblinear"则表示使用线性模型,当弱评估器类型是"gblinear"而损失函数是MSE时,表示使用xgboost方法来集成线性回归。当弱评估器类型是"gblinear"而损失函数是交叉熵损失时,则代表使用xgboost来集成逻辑回归。
每一种弱评估器都有自己的params列表,例如只有树模型才会有学习率等参数,只有DART树才会有抛弃率等参数。评估器必须与params中的参数相匹配,否则一定会报错。其中,由于DART树是从gbtree的基础上衍生而来,因此gbtree的所有参数DART树都可以使用。
在上述三种树当中,DART树的参数需要单独进行说明。DART树的建树过程与普通提升树gbtree完全一致,但在集成树结果的过程中与传统gbtree有所区别。具体来说,提升树的模型输出结果往往等于所有树结果的加权求和:
![]()
在第次迭代中建立新的树时,迭代后的结果等于之前所有−1棵树的结果加新建立的树的结果:
![]()
DART树在每一次迭代前都会随机地抛弃部份树,即不让这些树参与![]() 的计算,这种随机放弃的方式被叫做“Dropout”(抛弃)。举例说明,假设现在一共有5棵树,结果分别如下:
的计算,这种随机放弃的方式被叫做“Dropout”(抛弃)。举例说明,假设现在一共有5棵树,结果分别如下:
| k=1 | k=2 | k=3 | k=4 | k=5 | |
|---|---|---|---|---|---|
| () | 1 | 0.8 | 0.6 | 0.5 | 0.3 |
当建立第6棵树时,普通提升树的![]() = 1+0.8+0.6+0.5+0.3 = 3.2。对于DART树来说,我们可以认为设置抛弃率
= 1+0.8+0.6+0.5+0.3 = 3.2。对于DART树来说,我们可以认为设置抛弃率rate_drop,假设抛弃率为0.2,则DART树会随机从5棵树中抽样一棵树进行抛弃。假设抛弃了第二棵树,则DART树的![]() = 1+0.6+0.5+0.3 = 2.4。通过影响
= 1+0.6+0.5+0.3 = 2.4。通过影响![]() ,DART树影响损失函数、影响整个算法的输出结果
,DART树影响损失函数、影响整个算法的输出结果![]() ,以此就可以在每一次迭代中极大程度地影响整个xgboost的方向。
,以此就可以在每一次迭代中极大程度地影响整个xgboost的方向。
在一般的抗过拟合方法当中,我们只能从单棵树的学习能力角度入手花式对树进行剪枝,但DART树的方法是对整体迭代过程进行控制。在任意以“迭代”为核心的算法当中,我们都面临同样的问题,即最开始的迭代极大程度地影响整个算法的走向,而后续的迭代只能在前面的基础上小修小补。这一点从直觉上来说很好理解,毕竟当我们在绘制损失函数的曲线时,会发现在刚开始迭代时,损失函数急剧下降,但随后就逐渐趋于平缓。在这个过程中,没有任何过拟合手段可以从流程上影响到那些先建立的、具有巨大影响力的树,但DART树就可以削弱这些前端树的影响力,大幅提升抗过拟合的能力。
2.1.2 参数rate_drop、one_drop、skip_drop、sample_type、normalize_type
在使用DART树中,会涉及到以下几个参数:
① 参数rate_drop:每一轮迭代时抛弃树的比例
设置为0.3,则表示有30%的树会被抛弃。只有当参数booster="dart"时能够使用,只能填写[0.0,1.0]之间的浮点数,默认值为0。
② 参数one_drop:每一轮迭代时至少有one_drop棵树会被抛弃
可以设置为任意正整数,例如one_drop = 10,则意味着每轮迭代中至少有10棵树会被抛弃。
当参数one_drop的值高于rate_drop中计算的结果时,则按照one_drop中的设置执行Dropout。例如,总共有30棵树,rate_drop设置为0.3,则需要抛弃9棵树。但one_drop中设置为10,则一定会抛弃10棵树。当one_drop的值低于rate_drop的计算结果时,则按rate_drop的计算结果执行Dropout。
③ 参数skip_drop:每一轮迭代时可以不执行dropout的概率
即便参数booster='dart',每轮迭代也有skip_drop的概率可以不执行Dropout,是所有设置的概率值中拥有最高权限的参数。该参数只能填写[0.0,1.0]之间的浮点数,默认值为0。当该参数为0时,则表示每一轮迭代都一定会抛弃树。如果该参数不为0,则有可能不执行Dropout,直接按照普通提升树的规则建立新的提升树。需要注意的是,skip_drop的权限高于one_drop。即便one_drop中有所设置,例如每次迭代必须抛弃至少10棵树,但只要skip_drop不为0,每轮迭代则必须经过skip_drop的概率筛选。如果skip_drop说本次迭代不执行Dropout,则忽略one_drop中的设置。
④ 参数sample_type:抛弃时所使用的抽样方法
填写字符串"uniform":表示均匀不放回抽样。填写字符串"weighted":表示按照每棵树的权重进行有权重的不放回抽样。注意,该不放回是指在一次迭代中不放回。每一次迭代中的抛弃是相互独立的,因此每一次抛弃都是从所有树中进行抛弃。上一轮迭代中被抛弃的树在下一轮迭代中可能被包括。
⑤ 参数normalize_type:增加新树时,赋予新树的权重
当随机抛弃已经建好的树时,可能会让模型结果大幅度偏移,因此往往需要给与后续的树更大的权重,让新增的、后续的树在整体算法中变得更加重要。所以DART树在建立新树时,会有意地给与后续的树更大的权重(树的权重指的是整棵树上所有叶子权重之和)。参数normalize_type有两种选择:填写字符串"tree",表示新生成的树的权重等于所有被抛弃的树的权重的均值。填写字符串"forest",表示新生成的树的权重等于所有被抛弃的树的权重之和。 算法默认为"tree",当我们的dropout比例较大,且我们相信希望给与后续树更大的权重时,会选择"forest"模式。
当模型容易过拟合时,我们可以尝试让模型使用DART树来减轻过拟合。不过DART树也会带来相应的问题,最明显的缺点就是:
- 用于微调模型的一些树可能被抛弃,微调可能失效
- 由于存在随机性,模型可能变得不稳定,因此提前停止等功能可能也会变得不稳定
- 由于要随机抛弃一些树的结果,在工程上来说就无法使用每一轮之前计算出的
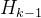 ,而必须重新对选中的树结果进行加权求和,可能导致模型迭代变得略微缓慢
,而必须重新对选中的树结果进行加权求和,可能导致模型迭代变得略微缓慢
data_xgb = xgb.DMatrix(X,y)
params_dart = {"max_depth":5 ,"seed":1412, "eta":0.1
,"booster":"dart","sample_type": "uniform"
,"normalize_type":"tree"
,"rate_drop": 0.2
,"skip_drop": 0.5}
result_dart = xgb.cv(params_dart,data_xgb,num_boost_round=100
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
overfitcheck(result_dart) #18356.036718800002
result_dart.iloc[-1,:]
-------------------------------------------------------
train-rmse-mean 9906.142188
train-rmse-std 317.321406
test-rmse-mean 28262.178906
test-rmse-std 8082.918652
Name: 99, dtype: float64可以看出,dart树抗过拟合效果比gamma、lambda等参数更强,不过在提升模型的测试集表现上,dart树还是略逊一筹,毕竟dart树会伤害模型的学习能力。
2.2 弱评估器的分枝
当参数booster的值被设置为gbtree时,XGBoost所使用的弱评估器是改进后的的CART树,其分枝过程与普通CART树高度一致:向着叶子质量提升/不纯度下降的方向分枝、并且每一层都是二叉树。在CART树的基础上,XGBoost创新了全新的分枝指标:结构分数(Structure Score)与结构分数增益(Gain of Structure Score)(也被叫做结构分数之差),更大程度地保证了CART树向减小目标函数的方向增长。需要注意的是,XGBoost不接受其他指标作为分枝指标,因此在众多的xgboost的参数中,并不存在criterion参数。幸运的是,XGBoost中没有任何参数与结构分数的公式本身相关,不过,结构分数是XGBoost整个运行流程中非常核心的概念,它即精又巧,串起了整个XGBoost几乎所有的数学流程。结构分数的相关公式:
假设现在目标函数使用L2正则化,控制叶子数量的参数gamma为0。现存在一个叶子节点,对该节点来说结构分数的公式为:
![]()
其中, 是样本在损失函数上对预测标签求的一阶导数,
是样本在损失函数上对预测标签求的一阶导数, 是样本在损失函数上对预测标签求的二阶导数,∈表示对叶子上的所有样本进行计算,就是L2正则化的正则化系数。所以不难发现,结构分数实际上就是:
是样本在损失函数上对预测标签求的二阶导数,∈表示对叶子上的所有样本进行计算,就是L2正则化的正则化系数。所以不难发现,结构分数实际上就是:

需要注意结构分数是针对节点计算的,不纯度衡量指标如基尼系数、信息熵等也是如此。在此基础上,我们依赖于结构分数增益进行分枝,结构分数增益表现为:

这即是说,结构分数增益实际上就是:
= 左节点的结构分数+右节点的结构分数−父节点的结构分数
我们选择增益最大的点进行分枝。而CART树中所使用的信息增益是:树中的信息增益=父节点的不纯度−(左节点的不纯度+右节点的不纯度)我们追求的是最大的信息增益,这意味着随着CART树的建立整体不纯度是在逐渐降低的。无论不纯度衡量指标是基尼系数还是信息熵,不纯度是越小越好。然而在XGBoost当中,增益的计算公式与CART树相反,但我们依然追求最大增益,所以这意味着随着XGBoost树的建立,整体结构分数是逐渐上升的。因此我们可以认为结构分数越大越好。
结构分数与信息熵的关键区别:与信息熵、基尼系数等可以评价单一节点的指标不同,结构分数只能够评估结构本身的优劣,不能评估节点的优劣。我们利用一棵树上所有叶子的结构分数之和来评估整棵树的结构的优劣,分数越高则说明树结构质量越高,结构分数也被称为质量分数(quality score)。
2.3 控制复杂度(一):弱评估器的剪枝
一般来说,控制树模型复杂度的方式有两种:一种是对树进行剪枝,一种是从训练数据上下功夫。与其他树模型中五花八门的剪枝参数不同,XGBoost只有三个剪枝参数和一个侧面影响树生长的参数,其中最为我们熟知的剪枝参数是max_depth,它的用法与其他树模型中一致,在XGBoost中默认值为6,因此在对抗过拟合方面影响力不是很大。需要重点来说明的是以下三个参数:
① 参数min_child_weight:可以被广义理解为任意节点上所允许的样本量(样本权重)
更严谨的说法是,min_child_weight是在任意节点上所允许的最小的![]() 值。如果一个节点上的
值。如果一个节点上的![]() 小于该参数中设置的值,该节点被剪枝。当损失函数为
小于该参数中设置的值,该节点被剪枝。当损失函数为 ,任意样本的=1,因此
,任意样本的=1,因此![]() 应该等于该叶子节点上的总样本量。因为这个原因,在XGBoost原始论文和官方说明中有时被称为“样本权重”(instance weight)。因此,当MSE为损失函数时,参数
应该等于该叶子节点上的总样本量。因为这个原因,在XGBoost原始论文和官方说明中有时被称为“样本权重”(instance weight)。因此,当MSE为损失函数时,参数min_child_weight很类似于sklearn中的min_sample_leaf,即一个节点上所允许的最小样本量。然而,如果我们使用的损失函数不是MSE,那也就不会等于1了。不过官方依然将称之为样本权重,当损失函数更换时,样本的权重也随之变化。当损失函数不为MSE时,参数min_child_weight时一个节点上所允许的最小样本权重量。很显然,参数min_child_weight越大,模型越不容易过拟合,同时学习能力也越弱。
② 参数gamma:目标函数中叶子数量前的系数,同时也是允许分枝的最低结构分数增益。当分枝时结构增益不足gamma中设置的值,该节点被剪枝。
在目标函数当中,gamma是叶子数量前的系数,放大gamma可以将目标函数的重点转移至结构风险,从而控制过拟合:![]()
当gamma不为0时,结构分数增益的公式如下:
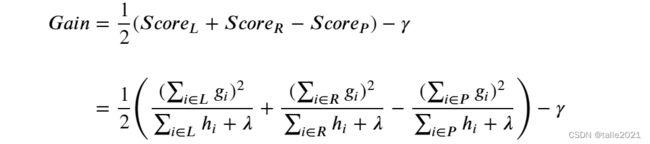
在XGBoost中,我们追求一棵树整体的结构分数最大,因此XGBoost规定任意结构的分数增益不能为负,任意增益为负的节点都会被剪枝,因此可以默认有:

当参数gamma为0时,任意增益为负的节点都会被剪枝。当gamma为任意正数时,任意增益小于gamma设定值的节点都会被剪枝。不难发现,gamma在剪枝中的作用就相当于sklearn中的min_impurity_decrease。很显然,gamma值越大,算法越不容易过拟合,同时学习能力也越弱。
③ 参数lambda和alpha:正则化系数,同时也位于结构分数中间接影响树的生长和分枝。
当使用L2正则化时,结构分数为:
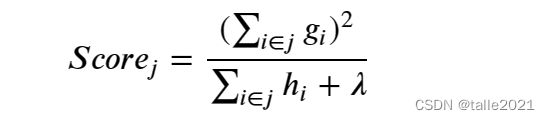
当使用L1正则化时,结构分数为:

当lambda越大,结构分数会越小,参数gamma的力量会被放大,模型整体的剪枝会变得更加严格,同时,由于lambda还可以通过目标函数将模型学习的重点拉向结构风险,因此lambda具有双重扛过拟合能力。
当alpha越大时,结构分数会越大,参数gamma的力量会被缩小,模型整体的剪枝会变得更宽松。然而,alpha还可以通过目标函数将模型学习的重点拉向结构风险,因此alpha会通过放大结构分数抵消一部分扛过拟合的能力。整体来看,alpha是比lambda更宽松的剪枝方式。
在XGBoost当中,我们可以同时使用两种正则化,则结构分数为:

此时,影响模型变化的因子会变得过多,我们难以再从中找到规律,调参会因此变得略有困难。但是当你感觉到L2正则化本身不足以抵抗过拟合的时候,可以使用L1+L2正则化的方式尝试调参。
2.4 控制复杂度(二):弱评估器的训练数据
2.4.1 样本的抽样
① 参数subsample
参数subsample:对样本进行抽样的比例,默认为1,可输入(0,1]之间的任何浮点数。例如,输入0.5,则表示随机抽样50%的样本进行建树。当该参数设置为1时,表示使用原始数据进行建模,不进行抽样。同时,XGBoost中的样本抽样是不放回抽样,因此不像GBDT或者随机森林那样存在袋外数据的问题,同时也无法抽样比原始数据更多的样本量。因此,抽样之后样本量只能维持不变或变少,如果样本量较少,建议保持subsample=1。
② 参数sampling_method
参数sampling_method:对样本进行抽样时所使用的抽样方法,默认均匀抽样。输入"uniform":表示使用均匀抽样,每个样本被抽到的概率一致。如果使用均匀抽样,建议subsample的比例最好在0.5或以上。需要注意的是,该参数还包含另一种可能的输入"gradient_based":表示使用有权重的抽样,并且每个样本的权重等于该样本的![]() 。
。
2.4.2 特征的抽样
参数colsample_bytree,colsample_bylevel,colsample_bynode,这几个参数共同控制对特征所进行的抽样。所有形似colsample_by*的参数都是抽样比例,可输入(0,1]之间的任何浮点数,默认值都为1。
对于GBDT、随机森林来说,特征抽样是发生在每一次建树之前。但对XGBoost来说,特征的抽样可以发生在建树之前(由colsample_bytree控制)、生长出新的一层树之前(由colsample_bylevel控制)、或者每个节点分枝之前(由colsample_bynode控制)。三个参数之间会互相影响,全特征集 >= 建树所用的特征子集 >= 建立每一层所用的特征子集 >= 每个节点分枝时所使用的特征子集。
举例说明:假设原本有64个特征,参数colsample_bytree等于0.5,则用于建树的特征就只有32个。此时,如果colsample_bylevel不为1,也为0.5,那新建层所用的特征只能由16个,并且这16个特征只能从当前树已经抽样出的32特征中选择。同样的,如果colsample_bynode也不为1,为0.5,那每次分枝之前所用的特征就只有8个,并且这8个特征只能从当前层已经抽样出的16个特征中选择。在实际使用时,我们可以让任意抽样参数的比例为1,可以在某一环节不进行抽样。一般如果特征量太少(例如,10个以下),不建议同时使用三个参数。
总结:
| 类型 | 参数 |
|---|---|
| 弱评估器 | booster:选择迭代过程中的弱评估器类型,包括gbtree,DART和线性模型 sample_type:DART树中随机抽样树的具体方法 rate_drop:DART树中所使用的抛弃率 one_drop:每轮迭代时至少需要抛弃的树的数量 skip_drop:在迭代中不进行抛弃的概率 normalized_type:根据被抛弃的树的权重控制新增树权重 max_depth:允许的弱评估器的最大深度 min_child_weight:(广义上)叶子节点上的最小样本权重/最小样本量 gamma:目标函数中叶子数量的系数,同时也是分枝时所需的最小结构分数增益值 lambda与alpha:正则项系数,同时也位于结构分数的公式中,间接影响模型的剪枝 sample_type:对样本进行抽样具体方式 subsample:对样本进行抽样的具体比例 colsample_bytree, colsample_bylevel, colsample_bynode:在建树过程中对特征进行抽样的比例 |
3. XGBoost的其他参数与方法
3.1 提前停止
参数early_stopping_rounds:位于xgb.train方法当中。如果规定的评估指标不能连续early_stopping_rounds次迭代提升,那就触发提前停止。
3.2 模型监控与评估
参数evals:位于xgb.train方法当中,用于规定训练当中所使用的评估指标,一般都与损失函数保持一致,也可选择与损失函数不同的指标。该指标也用于提前停止。
参数verbosity:用于打印训练流程和训练结果的参数。我们可以在verbosity中设置数字[0,1,2,3],参数默认值为1。0表示不打印任何内容;1表示如果有警告,请打印警告;2表示请打印建树的全部信息;3表示我正在debug,请帮我打印更多的信息。
3.3 样本不均衡
参数scale_pos_weight:调节样本不均衡问题,类似于sklearn中的class_weight,仅在算法执行分类任务时有效。参数scale_pos_weight的值是负样本比正样本的比例,默认为1,因此XGBoost是默认调节样本不均衡的。同时,如果你需要手动设置这个参数,可以输入(负样本总量)/(正样本总量)这样的值。
3.4 并行的线程
参数nthread:允许并行的最大线程数,类似于sklearn中的n_jobs,默认为最大,因此xgboost在默认运行时就会占用大量资源。如果数据量较大、模型体量较大,可以设置比最大线程略小的线程,为其他程序运行留出空间。