CHI中的System Debug, Trace, and Monitoring
========Data Source indication======
□ Read request的completer,可以在CompData, DataSepResp, SnpRespData, and SnpRespDataPtl response中的datasource域段中指定data的来源;即使响应中带有错误,该datasource也是有效的;
□ 该域段也可复用为传递SLC replacement policy;
□ DataSource的值必须按如下赋值:
□ 当数据来源于memory的话,是采用固定值来指示如下信息:
□ 0b110:PrefetchTgt memory的预取是有用的;
读数据以更低latency从Slave获得,是由于PrefetchTgt request已经读取或触发从memory读取数据;
□ 0b111:PrefetchTgt memory的预取是无用的;
Read request仍然经历整个memory访问过程,因此没有因为之前PrefetchTgt的作用而使得有latency的缩小;
具体为啥没有效果的精确原因是由具体实现决定的。
注意:有几个原因可能导致PrefetchTgt request无效。
1. prefet命令被Slave丢掉;
2. prefetch数据被buffer替换掉;
3. Read request比PrefetchTgt先到达Slave。
□ 对于不是来自memory的response,即来自cache,DataSource的值由具体实现决定的。
CHI协议推荐但不要求在以下情况使用设置DataSource的值。
component允许软件编程来重写DataSource的值:
1. 将分组更改为更合适的指定配置设置;
2. 将错误的值改变;
□ Responder允许返回的DataSource值无效,但是要遵从下面两条:
1. 除了访问memory SN-F,responder必须返回0b000值;
2. memory SN-F组件必须返回0b111作为默认值;
这种例外情况必须得到系统认定。
======Crossing a chip-to-chip interface=====
□ 如果存在across chip,需要将到来的Data packet的DataSource值映射成不同的值,用于标识响应是来自remote chip cache,这个功能应该是由chip interface module来完成的。
□ chip interface module可能采用的方法示例为:
□ 将remote cache打包成单一编码,如图1所示;
□ 实现一个最大8个入口的查找表,用于将到来Data packet的DataSource域段的实现值映射成新值。
一个实例如下:

□ 图1展示了multichip配置和对于系统中不同组件的DataSource映射建议值的例子:
□ 系统中每个chip的每个cluster有两个processors,并带有三级cache;
□ chip-to-chip接口module的cache和ICN内cache一致;
□ remote peer chip的所有cache分成一组;
□ non-memory组件不能编程去标识它自己,由于它可以返回的DataSource默认为0b000;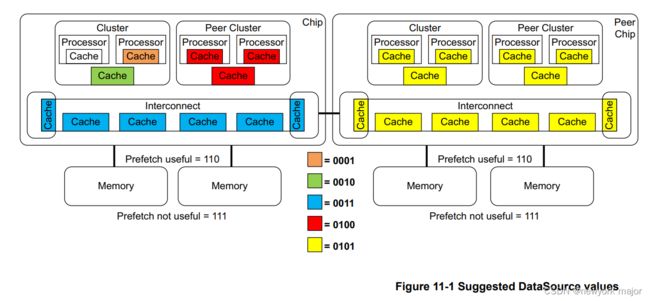
□ 为什么要知道datasource?
□ 用于确定PrefetchTgt触发memory controller prefetch上是否有用;
□ 通过监控SN-F memory返回数据的DataSource值,Requester可以确定PrefetchTgt的有效性,然后调整PrefetchTgt的发送速率;
□ 可以用于性能分析和调试软件用于优化数据共享模式 ;
=====SLC replacement hint=====
□ 引入这个操作的原因是,当一个cache line放到了RNF之后,这个cache line的使用状态,其实这个RNF最清楚,比如经常使用,或者很少使用;
□ 如果这个cache line经常使用,当SLC在进行cache line替换的时候,如果把这个cache line替换掉了,则会invalid掉RNF中的cache line,但是这个line又在RNF中经常使用,因此,这样操作显然是不合理的;
□ 为此,引入这个filed, 用来告诉SLC, 那些cacheline是我常用的,那些不是,这样SLC进行替换的时候,就可以采取更加高效的手段,从而避免这样的问题发生;
□ 此特性是在req channel增加7bit的域段,该域段又被分为两个sub域段; 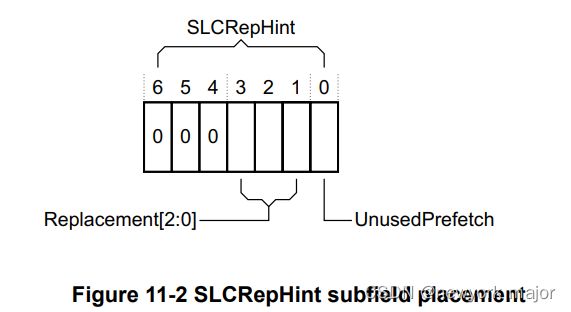

□ 该特性虽然是在copyback req中最有用(RN借助这些copyback操作,可以把当前对该cacheline的使用情况带下来),但是协议也没有限制其使用,可以在如下的命令之外的所有请求中使用:
• Atomics
• Stash transactions when StashNIDValid is 1
• PrefetchTgt
• PCrdReturn
• DVMOp
========MPAM========
□ 内存系统性能资源分区和监控(MPAM)是一种在用户之间有效利用内存资源并监控这些资源利用率的机制。
□ 内存资源,按照Partition ID (PartID) and Performance Monitoring Group (PerfMonGroup)进行分区;RN 发送的request包含该信息后,HN/SN根据此信息进行资源分配;
□ MPAM域段只在REQ/SNP 通道有效;
□ REQ channel, 当发送者不想使用MPAM时,填写默认值;
□ SNP channel, MPAM只在stash snoop中使用;其他snoop type, 填写默认值;
Stash snp, 其包含data pull请求时,MPAM值和原始请求中的MPAM要一致;
□ MPAM域段的分配;
— PartID = 9 bits
— PerfMonGroup = 1 bit
— MPAMNS = 1 bit
MPAMNS
□ 此域段表示是否是secure的分区,和请求中的ns不是一个概念;
□ MPAMNS/NS的四种组合都被允许;
MPAM value propagation
□ 接收者可以支持所有的partition和performance monitor group, 但是不强制;
□ 在系统配置阶段,可以先看下当前支持多少partition和performance monitor group,然后进行适配;
===========Completer Busy=============
□ 此标记,用来指示当前completer的繁忙程度;
□ 3bit, 在DAT/RSP channel使用;
□ 当分开返回data/rsp时,两个的busy可以单独置位;
□ 协议没有规定cbusy的取值含义,以及RN收到之后,如何结束各个值的含义,这是实现决定的;
简单的例子;
CBusy[2], 多个core正在发送请求;
CBusy[1:0],表示当前completer处,tracker的空满度;
• 00 = Less than 50% full.
• 01 = Greater than 50% full.
• 10 - Greater than 75% full.
• 11 = Greater than 90% full.
□ RN处的Prefetcher,也可以根据cbusy的值,调整预取器的工作模式;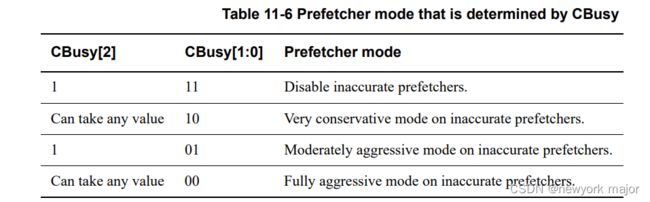
--11,此时负载非常大,不再发送预取操作;
--10,采用非常保守的预取方式;
--01,正常的预取方式;
--00,可以发送大量的预取;
========Trace Tag========
□ 协议规定,每个channel都有一个tracetag域段,用来增强debug能力;
TraceTag usage and rules
□ 何时设置TraceTag和怎样传输TraceTag域段的值按如下规则:
□ TraceTag bit是由transaction的发起者或ICN组件设置的;
□ 如果组件收到TraceTag置位的packet,必须将保留和反射该域值给任何响应的packet或衍生的packet;
□ 例如,compack 和多个compdata之间的对应;
□ Dvm和两个snp resp之间的对应;
□ 如果接收到的置位的TraceTag packets衍生了许多response,那么每个衍生的response的TraceTag域段都要求置位。例如:
□ 对于写操作,Separate comp和dbidresp;
□ 对于读操作,separate datasepresp/respsepdata;
□ 如果衍生的packet没有将TraceTag置位,那么该衍生packet和其它相关衍生packets是无关的;
□ 如果一个组件可以收到和一笔transaction的多个packets,此时这个RN将要发送的trans, 其trace tag是否置位,只和收到的相关packet有关,例如:
□ 如果Comp和DBIDResp是分开返回的,那么RN的write transaction流程可能有WriteData和CompAck两个响应。由于CompAck是作为接收到Comp的响应,它的值必须和Comp packet的 TraceTag的值有依赖关系,对于DBIDResp和WriteData的同样适用;
□ 如果Requester收到分离的DataSepResp和RespSepData响应,然后产生CompAck,那么CompAck的TraceTag只和DataSepResp有关。
□ 如果Comp或DBIDResp的任何一个将TraceTag置位,那么NCBWrDataCompAck响应必须将TraceTag置位。
□ 如果ICN收到一笔TraceTag置位的packet,那它必须要保留该值且不能将复位该值。
注意点:
□ 怎么来跟踪和使用trace tag,是实现决定的,协议不做描述;
□ 精确的机制来trigger和使用tracetag, 是实现决定的;
□ Tracetag bit任何时候,都会被限制在单一系统的维度进行使用,例如:
□ 通过tracing trans flow, 来进行debug;
□ 进行性能统计;
□ 测试latency;
注意,以下列出一些Request-Response对的例子:
□ Snoop request和snoop resp;
□ Snoop resp和snpdvmop;
□ Read requst和data resp;
等等;
=======Memory Tagging========
□ Memory Tagging Extension (MTE)是一种用来检查memory中数据使用方式是否正确的机制;
□ 当某个地址的数据,是专门用来做某种用途时,可以给他分配一个memory tag;
□ 这个tag是和数据一起存在memory中的,这个tag称之为分配标签(allocation tag);
□ 当这个地址后面再次进行访问时,RN除了要指定访问的地址外,还需要指明跟这个地址相匹配的tag的值;该tag称之为PA tag;
□ 只要是tag check enable的访问,PA tag就需要和allocation tag进行比较;命令处理都按照正常进行,只是tag check的结果,需要用来指示是否需要返回error;
□ 这个机制,保证了对memory的访问,是按照预期来处理的,而不是错误的,或者是恶意访问; 它可以在运行时用于识别许多常见的编程内存错误,例如缓冲区溢出和释放后使用;
□ 该tag, 每16B数据,对应4bit tag;
支持如下的一些行为:
□ 只有normal writeback memory才使用memory tagging;
□ Read trans,会有一个指示信号,用来表示是否要返回allocation tag;
□ Physical tag和allocation tag的比较,是在RN中进行的;
□ 如果data value是缓存在cache中的,但是allocation tag没有,那么read trans必须要返回数据和tag, 返回tag对应的data可以是无效的?
□ 想要获得tag的read, 不能使用forwarding snoop;
□ Stashonce的命令,allocation tag也会和data一样;被stash到对应的RN中;
□ 携带physical tag的Write trans,必须与allocation tag进行check; 该check的动作,在completer完成;如果不匹配,则需要发出failure的notifycation;
□ Write trans可以通过将数据的BE全部无效,来专门更新tag;
□ 对于pass a dirty or clean cacheline的写操作,不需要更新或者进行tag检查;
□ Snoop trans, 在返回data的时候,也需要同时返回data对应的allocation tag; 如果tag是dirty的,必须返回,否则,可以选择性返回;
□ CMO操作,必须同时对data和tag进行;
CHI协议中,为了实现MTE, 增加了如下的一些域段;
□ Tag:每16B数据,4bit tag, 只在data通道中有;
□ TU: tag update, 用来指示是否要更新allocation tag, 只在data通道有;
每1bit TU, 对应4bit tag, 也就是对应16B数据;
TU域段,只有在snoop resp,以及write trans中有效,其他trans都要设置成0;
□ Tagop: tag operation. 用来指示当前对tag要进行什么操作;在req/data/rsp channel中均存在,2bit;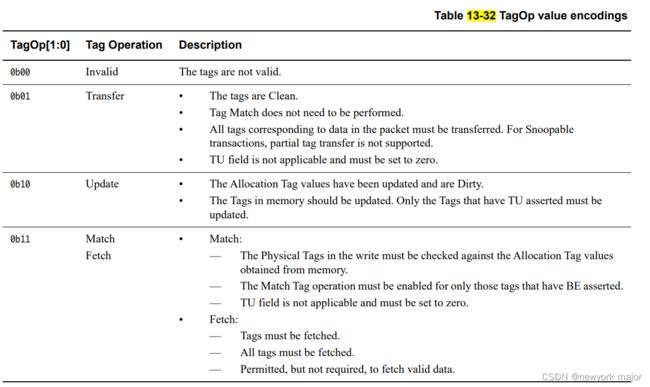
Transfer:
□ 当前的这个tag是clean的;
□ 不需要进行tag match检查;
□ 这个数据所有的tag都必须transfer, 对于snoopable trans,不允许只传输dirty的tag;
□ TU field无效,必须为0;
Update:
□ 当前这个tag是dirty的,allocation tag需要进行更新;
Match:
□ Write中的PT, 需要和memory中的allocation tag进行check;
□ TU无效,全部置零;
Fetch:
□ 需要预取tags, 对应的预取数据,可以有效,也可以无效;
□ Retry cmd中的tagop, 必须和原始的tagop相同;
Taggroupid:
□ 为了方便RN来处理不同的tagmatch resp, 将对应的request进行分组,并进行编号,这个编号就是TagGroupID;
□ TagGroupID到底包含什么内容,一般是看具体的实现,但是协议推荐包含exception level, TTBR, CPU ID;
□ 只有当tapOP为match的时候,taggroupID才有效;
□ 此域段在request flit中是和其他域段共用的bit位;

同样,在rsp flit中也是公用的;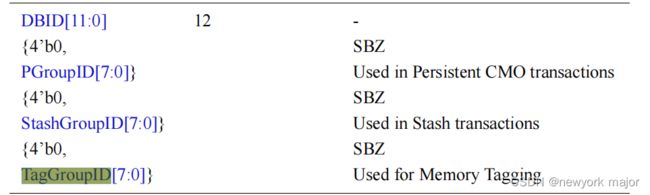
Tag一致性;
□ Allocation tag可以被cache, 同时支持硬件一致性;其一致性机理和data一致性一样;
□ Allocation tag状态有3种,Invalid, dirty, clean;
□ Data cache和tag cache之间的关系是:
□ Tags valid有效的条件是,data valid;
□ Data valid时,tag可以invalid;
□ 当cachelien state为Unique state, 标志着data和tag都是unique的;
□ 当cachelien state为Shared state, 标志着data和tag都是Shared的;
□ 当dirty tag的cachleine被逐出时,数据和tags都要看成dirty的,dirty的tag, 要么写回内存,要么将dirty pass给别人;
□ Clean tags被逐出时,可以给其他cache, 也可以直接丢弃;
□ Clean tags, dirty data的cacheline被逐出时,clean tag可以跟随dirty data一起,发送到POC;
各类命令的处理描述;
Error response
Tag Match
□ Write/atomic trans, tagop是match的,必须返回tag match的结果;
□ 该结果通过tagmatch message返回;
□ 无论标记匹配结果如何,事务都必须正常进行。即使WriteData被取消或未执行标记匹配,也必须发送TagMatch响应
使用单独的tagmatch meesage会增加复杂性和额外的消息,但是也有优势,可以提供更加准确的resp;
Tagmatch message有如下特性:
□ 由tag match check的那个人返回,可能是HN或者SN;
□ Tagid是从scrid获取的,如果是fwd的,则通过returnNID;
□ Resp必须携带request中的TagGroupID;
□ Trancetag无效;
□ Resp filed的值,指示tag match fail or pass;
□ 只要completer可以确定tag match的结果,就尽快返回tagmatch resp, 不用等data;
□ Resp在不同的场景下取值如下:
□ MTE不支持时,返回fail;
□ 支持MTE, 但是不进行match, 返回pass;
□ 如果需要match,则按照实际是否match进行返回;
Non-Tag Match errors
□ Resp的data err/non-data err,和memory tagging特性没有关系;
□ 当resperr取值为NDERR时;
□ Resp中的Tagop域段,无效;
□ Snoop resp返回的状态一定是invalid;