python反爬虫之fontTools库的使用破解字体加密
python反爬虫之FontTools库的使用
字体反爬虫也是我们常见的一种反爬手段,字体的加密使返回的网页代码内容中我们想要的信息部分看不到,即使看到了,也是其他格式的内容。但我们可以找到字体地址,把字体下载下来然后用FontTools就能解决问题。以起点中文网为例。
首先我们请求首页的url地址,可以发现重要的数据是用方块显示的,如下:

这就很难受了。字体加密当然会有请求字体文件的。所以就找字体文件。
在字体数据的下方竟然有字体文件的地址,这就又很轻松了。
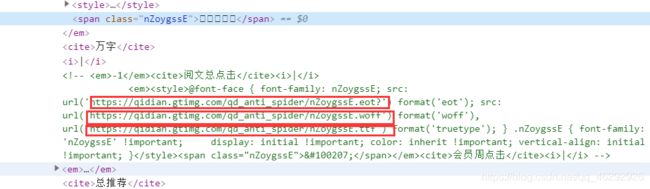
用正则表达式匹配出字体的地址即可。
font_url = re.findall(r"src: url\('(.*?)'\)", html)[1] # 提取woff字体文件
成功拿到字体地址。
![]()
接下来就是请求字体地址,保存字体文件。
# 请求字体文件地址
font_resp = requests.get(font_url)
# 保存字体文件
with open('字体文件.woff', 'wb') as f:
f.write(font_resp.content)
保存到本地的字体文件,我们是看不懂的,借助FontTools转换为xml形式的文件,我们就能找到其中的规律。
# TTFont打开字体文件
font = TTFont("字体文件.woff")
# 将字体文件保存为可读的xml文件
font.saveXML('font.xml')
# 找字体的映射关系,字体的映射关系在cmap中体现
font_map = font['cmap'].getBestCmap()
print(font_map)
在保存的xml文件中,我们可以找到其中的映射关系,如图:
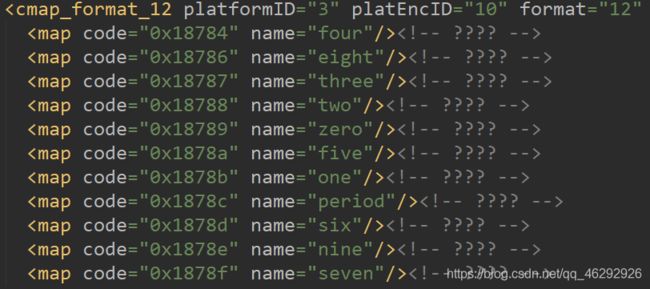
同时打印的映射关系为:
![]()
规律也很明显了,这时就到了转换字体的时候了。
我们将得到的映射关系手动修改一下,就能得到我们想要的字体数据了。
# 找到字体映射关系,并手动修改后的字体映射
d = {'three': 3, 'eight': 8, 'four': 4, 'two': 2, 'zero': 0, 'seven': 7, 'six': 6, 'five': 5, 'one': 1, 'period': '.',
'nine': 9}
替换完成后,需要重新对我们打印的字体映射关系替换。
# 将字体的映射关系重新修改
for key in font_map:
font_map[key] = d[font_map[key]]
print(font_map)
这一步的结果为:
![]()
映射关系简单明了了,接下就替换网页中的加密字体并保存即可:
# 将网页代码中的加密字体替换为数字
for key in font_map:
html_content = html_content.replace('&#' + str(key) + ';', str(font_map[key]))
# 保存修改后的网页代码
with open('after.html', 'w', encoding='utf-8') as f:
f.write(html_content)
结果如下:红圈中的加密字体直接请求的话返回的就是加密符号,这是替换后的html网页代码。

完整代码如下:
import re
import requests
import time
from fontTools.ttLib import TTFont
from fake_useragent import UserAgent
headers = {"UserAgent": UserAgent().random}
# 请求的目标网址
url = "https://book.qidian.com/info/1019275790"
# 延时等待一秒
time.sleep(1)
# 请求目标网页
html = requests.get(url, headers=headers).content.decode()
# 保存网页
with open('网页代码.html', 'w', encoding='utf-8') as f:
f.write(html)
# 传值
html_content = html
# 匹配网页中的字体文件路径
font_url = re.findall(r"src: url\('(.*?)'\)", html)[1]
print(font_url)
# 请求字体文件地址
font_resp = requests.get(font_url)
# 保存字体文件
with open('字体文件.woff', 'wb') as f:
f.write(font_resp.content)
# TTFont打开字体文件
font = TTFont("字体文件.woff")
# 将字体文件保存为可读的xml文件
font.saveXML('font.xml')
# 找字体的映射关系
font_map = font['cmap'].getBestCmap()
print(font_map)
# 找到字体映射关系,并手动修改后的字体映射
d = {'three': 3, 'eight': 8, 'four': 4, 'two': 2, 'zero': 0, 'seven': 7, 'six': 6, 'five': 5, 'one': 1, 'period': '.',
'nine': 9}
# 将字体的映射关系重新修改
for key in font_map:
font_map[key] = d[font_map[key]]
print(font_map)
# 将网页代码中的加密字体替换为数字
for key in font_map:
html_content = html_content.replace('&#' + str(key) + ';', str(font_map[key]))
# 保存修改后的网页代码
with open('after.html', 'w', encoding='utf-8') as f:
f.write(html_content)