AWQ模型量化实践
AWQ量化方法
https://github.com/mit-han-lab/llm-awq
https://arxiv.org/abs/2306.00978
AWQ量化与GPTQ量化对比
AWQ量化精度比GPTQ高一点,并且AWQ比GPTQ更容易实现,计算性能更高。个人认为是当前时段最优的量化方案之一。
AWQ的原理非常简单,就是计算一个scale系数tensor,shape为[k],k为矩阵乘的权重reduce的维度大小。对激活除以该tensor,并对矩阵乘的权重乘以该tensor,这降低了权重量化的难度,使得权重可以采用常规的group量化(直接根据最大最小值计算scale, zero point)。AWQ的核心技术一是这个对激活和权重应用scale的方法,另外就是如何计算这个scale tensor。因为激活是fp16不量化,对激活进行scale一般不会牺牲精度,因此可以对权重进行一些处理降低量化的难度。
虽然AWQ与GPTQ两者都采用group量化,对shape为[k, n]的矩阵乘权重都生成(k/group) * n套量化系数。但是GPTQ通常采用act_order=True选项,这个导致每一个group并非使用一组相同的scale和zero point系数,而是每个k位置对应的向量都对应不同的scale和zero point(不同k位置共享一组系数,但是这个位置是随机的),每读取一个元素都要读取scale和zero point,导致反量化效率很低。而act_order=False时,每一个向量group size元素都共享同一组scale和zero point系数,这样反量化只需要每隔group size个元素才需要重新读取一次scale和zero point,反量化效率很高。AWQ反量化跟GPTQ act_order=False是一样的,因此计算效率比较高。
另外AWQ虽然要对激活乘以一个scale tensor,但是这个tensor通常可以合并到前面的RMS NORM上面,使得这个操作不会引入额外计算。
AWQ量化实践
awq量化例子llama_example.sh给了4个步骤
MODEL=llama-7b
# run AWQ search (optional; we provided the pre-computed results)
python -m awq.entry --model_path /dataset/llama-hf/$MODEL \
--w_bit 4 --q_group_size 128 \
--run_awq --dump_awq awq_cache/$MODEL-w4-g128.pt
# evaluate the AWQ quantize model (simulated pseudo quantization)
python -m awq.entry --model_path /dataset/llama-hf/$MODEL \
--tasks wikitext \
--w_bit 4 --q_group_size 128 \
--load_awq awq_cache/$MODEL-w4-g128.pt \
--q_backend fake
# generate real quantized weights (w4)
python -m awq.entry --model_path /dataset/llama-hf/$MODEL \
--w_bit 4 --q_group_size 128 \
--load_awq awq_cache/$MODEL-w4-g128.pt \
--q_backend real --dump_quant quant_cache/$MODEL-w4-g128-awq.pt
# load and evaluate the real quantized model (smaller gpu memory usage)
python -m awq.entry --model_path /dataset/llama-hf/$MODEL \
--tasks wikitext \
--w_bit 4 --q_group_size 128 \
--load_quant quant_cache/$MODEL-w4-g128-awq.pt第一步生成scale和clip数据并保存文件。
第二步为加载第一步生成的量化系数,并评估量化性能。
第三步加载第一步生成的量化系数,对模型真实权重进行量化和保存量化模型权重。
第四步为评估真实量化模型。
当然这几个步骤是可以通过参数配置合并为一个的。
第一步会下载一个数据集,在utils/calib_data.py。默认的数据集可能无法下载,可以进行替换,或者手动下载下来用本地路径进行替换。
AWQ量化对每个权重生成一组scale和clip tensor,通过一个list存放到量化系数结果里面。
保存的结果scale和clip都是一个list,如下:


clip为权重每个量化分组clip的范围(对于矩阵乘权重为k*n,量化group size, clip shape大小为 (k/group) * n)。
scale为矩阵乘激活输入的scale系数tensor,shape为[k]。
它虽然为每个矩阵乘都生成一个scale,但是scale由激活值和后面并行连接的矩阵乘的权重共同计算而来,使得共享同一个输入的矩阵乘共享同一个scale。例如up_proj和gate_proj。并且这个scale tensor可以跟前面的rms norm的scale tensor或者矩阵乘的weight, bias融合,使得不需要任何额外计算。
如下图,up_proj和gate_proj共享同一个scale,并且可以合并到post_attention_layernorm的mul tensor上面。
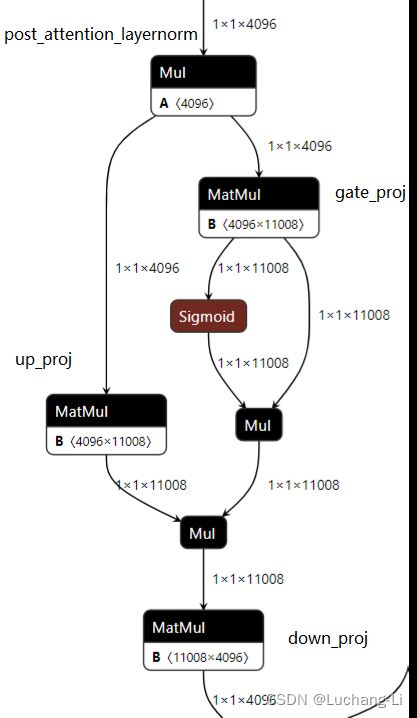
类似地,q_proj, k_proj, v_proj三个矩阵乘上面共同的输入是input_layernorm。
o_proj_scale的被添加到v_proj权重。
down_proj scale被添加到up_proj权重。
具体操作如:
def apply_awq(model, awq_results):
apply_scale(model, awq_results["scale"])
apply_clip(model, awq_results["clip"])def apply_scale(module, scales_list, input_feat_dict=None):
for prev_op_name, layer_names, scales in scales_list:
prev_op = get_op_by_name(module, prev_op_name)
layers = [get_op_by_name(module, name) for name in layer_names]
if isinstance(prev_op, nn.Linear):
assert len(layers) == 1
scale_fc_fc(prev_op, layers[0], scales)
elif isinstance(prev_op, (nn.LayerNorm, LlamaRMSNorm)):
scale_ln_fcs(prev_op, layers, scales)
else:
raise NotImplementedError(
f"prev_op {type(prev_op)} not supported yet!")
# apply the scaling to input feat if given; prepare it for clipping
if input_feat_dict is not None:
for layer_name in layer_names:
inp = input_feat_dict[layer_name]
inp.div_(scales.view(1, -1).to(inp.device))
@torch.no_grad()
def scale_fc_fc(fc1, fc2, scales):
assert isinstance(fc1, nn.Linear)
assert isinstance(fc2, nn.Linear)
assert fc1.out_features == fc2.in_features
scales = scales.to(fc1.weight.device)
fc1.weight.div_(scales.view(-1, 1))
if fc1.bias is not None:
fc1.bias.div_(scales.view(-1))
fc2.weight.mul_(scales.view(1, -1))
for p in fc1.parameters():
assert torch.isnan(p).sum() == 0
for p in fc2.parameters():
assert torch.isnan(p).sum() == 0
@torch.no_grad()
def scale_ln_fcs(ln, fcs, scales):
if not isinstance(fcs, list):
fcs = [fcs]
scales = scales.to(ln.weight.device)
ln.weight.div_(scales)
if hasattr(ln, 'bias') and ln.bias is not None:
ln.bias.div_(scales)
for fc in fcs:
fc.weight.mul_(scales.view(1, -1))
for p in ln.parameters():
assert torch.isnan(p).sum() == 0
for fc in fcs:
for p in fc.parameters():
assert torch.isnan(p).sum() == 0
可见,apply_scale把当前矩阵乘的scale tensor乘以到当前矩阵乘的权重上,然后把上一层的RMS norm或者矩阵乘的weight, bias除以该scale tensor。
感觉这里跟前面算子的合并定制性稍微有些强,从更加通用的角度可以在矩阵乘前面加上一个mul或者div算子,再利用图优化算法去合并。
@torch.no_grad()
def apply_clip(module, clip_list):
from ..utils.module import get_op_by_name
for name, max_val in clip_list:
layer = get_op_by_name(module, name)
max_val = max_val.to(layer.weight.device)
org_shape = layer.weight.shape
layer.weight.data = layer.weight.data.reshape(*max_val.shape[:2], -1)
layer.weight.data = torch.clamp(layer.weight.data, -max_val, max_val)
layer.weight.data = layer.weight.data.reshape(org_shape)再看clip部分,每个weight都包含一个clip tensor,shape为[n, k/g, 1]。
注意pytorch weight的shape为[n, k],先把weight reshape为[n, k/g, g]
再用torch.clamp(weight:[n, k/g, g], min/max:[n, k/g, 1])
也就是分组量化对每个分组内的weight范围clamp到[-max, max]。
apply_awq完成之后就开始对权重进行量化:
直接对每个分组计算min, max,然后计算量化的scale和zero point,然后把weight转换到定点:
参考pseudo_quantize_tensor函数
w = w.reshape(-1, q_group_size)
max_val = w.amax(dim=1, keepdim=True)
min_val = w.amin(dim=1, keepdim=True)
max_int = 2 ** n_bit - 1
min_int = 0
scales = (max_val - min_val).clamp(min=1e-5) / max_int
zeros = (-torch.round(min_val / scales)).clamp_(min_int, max_int)
w = (torch.clamp(torch.round(w / scales) + zeros, min_int, max_int) - zeros) * scales
最后在WQLinear.from_linear里面对weight和zero point 4bit打包为int32
AWQ与llama.onnx项目结合方法
llama.onnx通过把LLM转换为ONNX模型进行推理,使得LLM部署可以与传统推理引擎更好的结合:
https://github.com/tpoisonooo/llama.onnx/tree/main
根据上面的原理介绍,有几种可能的方案。
方案1:
先对Pytorch权重调用apply_awq修改权重,因为针对llama模型,awq直接把激活的scale tensor应用到前一层的矩阵乘或RMS norm的权重上,不会引入额外的计算。这使得可以直接用apply_awq更新模型权重,然后再导出ONNX模型。再在推理引擎层面使用一个图优化,实现naive的group量化即可。如果apply_awq需要增加专门的激活缩放计算,也可以在这一步进行修改pytorch模型图操作。该方案非常简单,易于实现。
方案2:
不修改模型权重,对于转好的onnx模型,在推理引擎层面使用一个图优化,读取量化系数,修改模型,进行group量化。该方法难点在于比较难以去匹配前面的层进行scale tensor合并,可以考虑先创建个div或者mul算子再进行额外图优化。
AWQ可能的改进点
k%group_size不整除的情况,不同layer支持不同group size。
w.shape[0] % oc_batch_size != 0处理
扩展到卷积等其他任意模型量化支持。
数据集替换
模型device选择,可以用CPU, GPU量化。
去除对A100 GPU依的赖,使得更低端的GPU也可以使用。
模型加载的精度选择
支持observe功能,不同layer选择最佳group size