《CUDA 编程入门》笔记
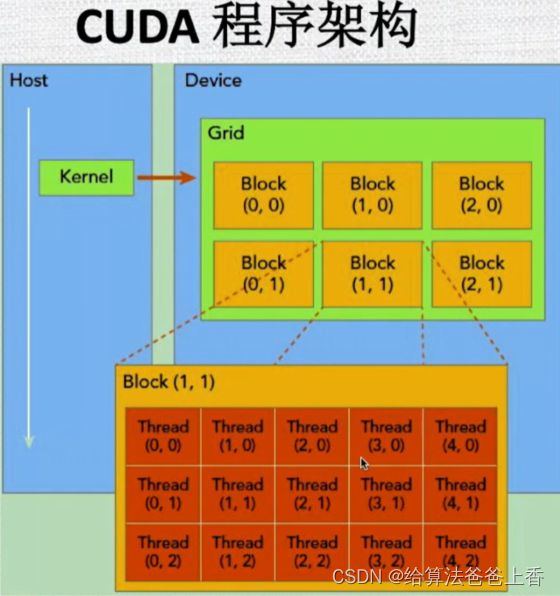
helloworld:vec-add
#include 内存管理
#include 规约算法






volatile关键字能防止编译器优化循环展开,造成结果错误。
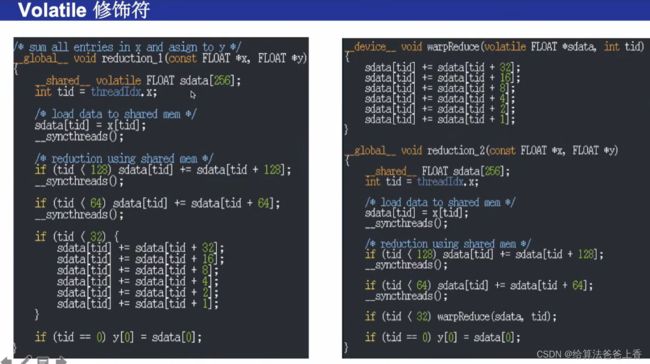
注意:下面的程序若去掉volatile关键字,则函数reduction_2和reduction_3的计算结果有误。
#include 完整的三阶段规约算法
1.块大小, 256:数组长度降低256倍 ——大规模数组依旧很长,例如256万降低到1万
2.对部分和继续使用上一步的算法
3.使用一个块,将最后结果规约
/* asum: sum of all entries of a vector */
#include "aux.h"
typedef double FLOAT;
__device__ void warpReduce(volatile FLOAT *sdata, int tid)
{
sdata[tid] += sdata[tid + 32];
sdata[tid] += sdata[tid + 16];
sdata[tid] += sdata[tid + 8];
sdata[tid] += sdata[tid + 4];
sdata[tid] += sdata[tid + 2];
sdata[tid] += sdata[tid + 1];
}
/* sum all entries in x and asign to y
* block dim must be 256 */
__global__ void asum_stg_1(const FLOAT *x, FLOAT *y, int N)
{
__shared__ FLOAT sdata[256];
int idx = get_tid();
int tid = threadIdx.x;
int bid = get_bid();
/* load data to shared mem */
if (idx < N) {
sdata[tid] = x[idx];
}
else {
sdata[tid] = 0;
}
__syncthreads();
/* reduction using shared mem */
if (tid < 128) sdata[tid] += sdata[tid + 128];
__syncthreads();
if (tid < 64) sdata[tid] += sdata[tid + 64];
__syncthreads();
if (tid < 32) warpReduce(sdata, tid);
if (tid == 0) y[bid] = sdata[0];
}
__global__ void asum_stg_3(FLOAT *x, int N)
{
__shared__ FLOAT sdata[128];
int tid = threadIdx.x;
int i;
sdata[tid] = 0;
/* load data to shared mem */
for (i = 0; i < N; i += 128) {
if (tid + i < N) sdata[tid] += x[i + tid];
}
__syncthreads();
/* reduction using shared mem */
if (tid < 64) sdata[tid] = sdata[tid] + sdata[tid + 64];
__syncthreads();
if (tid < 32) warpReduce(sdata, tid);
__syncthreads();
if (tid == 0) x[0] = sdata[0];
}
/* dy and dz serve as cache: result stores in dz[0] */
void asum(FLOAT *dx, FLOAT *dy, FLOAT *dz, int N)
{
/* 1D block */
int bs = 256;
/* 2D grid */
int s = ceil(sqrt((N + bs - 1.) / bs));
dim3 grid = dim3(s, s);
int gs = 0;
/* stage 1 */
asum_stg_1<<<grid, bs>>>(dx, dy, N);
/* stage 2 */
{
/* 1D grid */
int N2 = (N + bs - 1) / bs;
int s2 = ceil(sqrt((N2 + bs - 1.) / bs));
dim3 grid2 = dim3(s2, s2);
asum_stg_1<<<grid2, bs>>>(dy, dz, N2);
/* record gs */
gs = (N2 + bs - 1.) / bs;
}
/* stage 3 */
asum_stg_3<<<1, 128>>>(dz, gs);
}
FLOAT asum_host(FLOAT *x, int N);
FLOAT asum_host(FLOAT *x, int N)
{
int i;
FLOAT t = 0;
for (i = 0; i < N; i++) t += x[i];
return t;
}
int main(int argc, char **argv)
{
int N = 10000070;
int nbytes = N * sizeof(FLOAT);
FLOAT *dx = NULL, *hx = NULL;
FLOAT *dy = NULL, *dz;
int i, itr = 20;
FLOAT asd = 0, ash;
double td, th;
if (argc == 2) {
int an;
an = atoi(argv[1]);
if (an > 0) N = an;
}
/* allocate GPU mem */
cudaMalloc((void **)&dx, nbytes);
cudaMalloc((void **)&dy, sizeof(FLOAT) * ((N + 255) / 256));
cudaMalloc((void **)&dz, sizeof(FLOAT) * ((N + 255) / 256));
if (dx == NULL || dy == NULL || dz == NULL) {
printf("couldn't allocate GPU memory\n");
return -1;
}
printf("allocated %e MB on GPU\n", nbytes / (1024.f * 1024.f));
/* alllocate CPU mem */
hx = (FLOAT *) malloc(nbytes);
if (hx == NULL) {
printf("couldn't allocate CPU memory\n");
return -2;
}
printf("allocated %e MB on CPU\n", nbytes / (1024.f * 1024.f));
/* init */
for (i = 0; i < N; i++) {
hx[i] = 1;
}
/* copy data to GPU */
cudaMemcpy(dx, hx, nbytes, cudaMemcpyHostToDevice);
/* let dust fall */
cudaDeviceSynchronize();
td = get_time();
/* call GPU */
for (i = 0; i < itr; i++) asum(dx, dy, dz, N);
/* let GPU finish */
cudaDeviceSynchronize();
td = get_time() - td;
th = get_time();
for (i = 0; i < itr; i++) ash = asum_host(hx, N);
th = get_time() - th;
/* copy data from GPU */
cudaMemcpy(&asd, dz, sizeof(FLOAT), cudaMemcpyDeviceToHost);
printf("asum, answer: %d, calculated by GPU:%f, calculated by CPU:%f\n", N, asd, ash);
printf("GPU time: %e, CPU time: %e, speedup: %g\n", td, th, th / td);
cudaFree(dx);
cudaFree(dy);
cudaFree(dz);
free(hx);
return 0;
}
#include "_aux.h"
#include