MySql增删改查基础
目录
1.基本操作
1.1新增
1.2查询
1.2.1指定查询
1.2.2排序查询
1.2.3分页查询
1.3修改
1.4删除
2.进阶操作
2.1键值约束
2.1.1主键约束
2.1.2唯一键约束
2.1.3非空约束
2.1.4默认值
2.1.5自增属性
编辑 2.1.6外键约束
2.1.7check子句
3.表的设计
3.1ER关系图
3.2三大范式
3.2.1第一范式(1NF)
3.2.2第二范式(2NF)
3.2.3第三范式(3NF)
4.聚合函数
4.1COUNT
4.2SUM
4.3AVG
4.4MAX
4.5MIN
5.分组查询
1.基本操作
1.1新增
紧接上一篇博客的内容,我们向student表中添加内容。
首先是全列新增,即向表中的每一列都添加内容。
insert into student values(1,'张三',88.88,77.88,'2002-09-09 12:12:12', 1);多列新增便是将全列新增的结尾该为 ',' ,直到内容添加完全后使用 ';' 作为结尾。
然后是对指定列进行内容新增。
insert into student(sn, name, birthday, sex)values(2,'李四','2002-10-09 11:11:11', 1);我们只需表明对表中那几列的内容增加即可。
1.2查询
select * from student;其中select是关键字,*代表省略全部的表头信息,from也是关键字,后跟查询表的名称,具体查询之后的输出结果如下:

1.2.1指定查询
我们也可以指定查询指定列列信息,操作方法则是将上述语句当中的*代为具体的列名称即可,下面给出示例。
select sn, name, birthday, sex from student;对应输出结果为:

我们还可以加入表达式来进行内容查询,可以查询表中学生的总成绩 ,具体操作内容和结果如下:
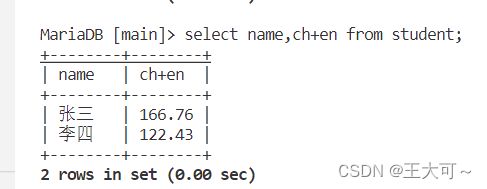
1.2.2排序查询
我们可以根据表中某一信息来对表内容进行排序查询,其中默认是asc(升序),还有desc(降序)。
select * from student order by ch desc;上述语句的意思是:对student表中的内容按照语文成绩降序查询,具体的输出结果如下:

1.2.3分页查询
limit …… offet ……其中,limit后跟一个数字,限制最多获取多少条数据;offset后面跟一个数字,描述从第几条数据开始获取。
我们引入实例,先加入新的班级成员王五,然后来获取班级当中语文成绩前二的同学。具体的实现过程为先对语文成绩进行降序排列,然后取出其中前两条数据。具体如下所示:

1.3修改
update stb set fields=val,…… where condition;其中,update是修改的关键字,stb是表名称,set也是关键字,fields是列信息,val修改后内容,where也是关键字,用于限定修改位置,condition是限定修改条件内容。
我们给出具体实例,修改表中李四的性别为0(女),效果如下:

值得注意的是,修改过程中,where关键字的限定很重要。因为不加以修改范围限定的话,我们所修改的内容范围将是整个表,即会对表中所有的内容进行对应的修改。
1.4删除
delete from stb where condition;其中,delete是删除关键字,后续说明同修改。
给出数据实例,将表中李四的信息删除,具体结果如下:
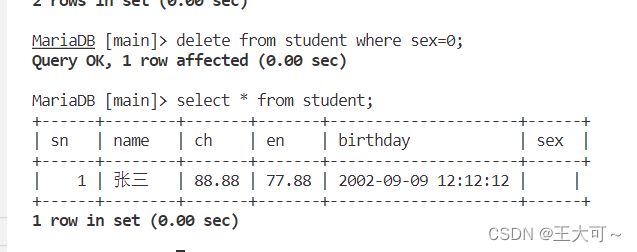
2.进阶操作
2.1键值约束
键值约束便是指给表中的字段内容设置一个约束,约束表中的数据必须符合某种规则。
2.1.1主键约束
主键约束的关键字为:primary key,约束表中某一字段的内容非空且唯一,并且一张表当中仅能存在一个主键内容。
当我们创建含有主键约束的表格之后,使用desc查看它的表结构,便可以有如下的发现:

上图中创建含有主键约束表的语句是一种方式,我们还存在一种创建含有主键约束表的方式。两种语句的内容如下:
create table stu1(sn int primary key, name varchar(32));
create table stu2(sn int, name varchar(32), primary key pk(sn));引入pk的设置之后,我们还可以设计一种主键约束,即组合主键约束,如下:
create table stu2(sn int, name varchar(32), primary key pk(sn, name));此时,sn和name都是主键,其中,只有当二者完全相同,或同时为空时便会触发主键约束,内容无法插入成功。
2.1.2唯一键约束
唯一键约束的关键字是:unique key,约束指定字段的内容必须唯一,并不对字段是否为NULL进行限制,因此唯一键约束当中可以存在多个NULL值。
同样的unique key约束存在两种书写方式,并且可以进行组合约束,其书写方式如下,并给出unique key在表结构中的内容效果。
create table stu4(sn int unique key, name varchar(32));
create table stu5(sn int, name varchar(32), unique key pk(sn));
create table stu5(sn int, name varchar(32), unique key pk(sn, name));其在表结构中的展示情况如下:
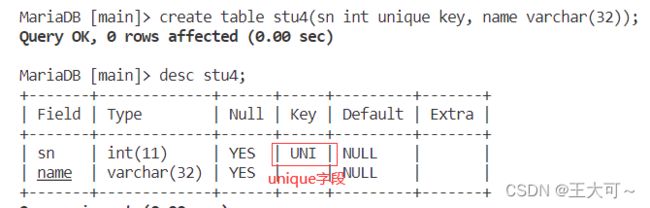
2.1.3非空约束
非空约束的关键字是:not null,这并不算是一种键值约束,可以理解为一种条件判断,具体实现字段如下:
create table stu6(sn int primary key, name varchar(32) not null);
2.1.4默认值
默认值不算在键值约束当中,但我们放在其中来讲述。默认值的关键字是:default val。当我们在指定列插入数据,且并没有设置被默认值修饰的字段时,则会使用默认值来进行内容填充。否则都是使用给定的值进行填充,包括null值。
具体的实现语句如下:
create table stu7(sn int, name varchar(32), sex varchar(1) default '男');得到表结构内容如下:
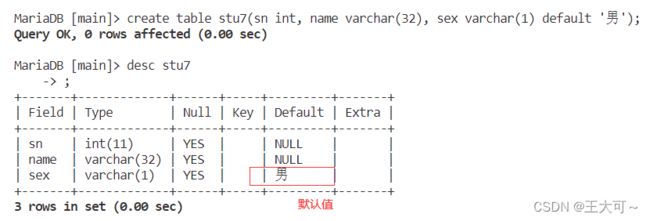
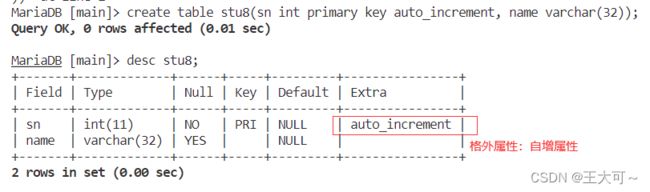
2.1.5自增属性
自增属性的关键字是:auto_increment,其只能针对整形字段进行设计,并且该字段只能是主键字段。当我们对带有自增属性列没有插入数据时,默认会从1开始每次+1来进行填充。
具体的实现语句如下:
create table stu8(sn int primary key auto_increment, name varchar(32));得到表结构内容如下:
 2.1.6外键约束
2.1.6外键约束
外键约束的语句是:
foregin key(fields) references other_table(fields)它的作用是:约束当前表中指定字段的值必须在另一张表当中存在(出现),才可与成功将数据内容插入。
2.1.7check子句
check子句:是用于插入内容被限定,具体语句如下:(我们规定性别选择)
create table stu9(sn int primary key, sex varchar(1) check (sex = '男' or sex = '女'));3.表的设计
3.1ER关系图
ER(Entity-Relationship)关系图是一种用于可视化数据库中数据模型的图形表示方法。它描述了数据库中实体(Entity)之间的关系,以及每个实体的属性(Attributes)。
在ER关系图中,有三个主要元素:
- 实体(Entity):表示数据库中的数据对象,通常对应于现实世界中的一个事物。每个实体在图中用矩形框表示,框中写有实体的名称;
- 属性(Attributes):实体具有的特征或属性。它们用椭圆形状的框表示,并连接到相应的实体;
- 关系(Relationships):表示实体之间的联系或关联。关系通常用菱形表示,并连接相关联的实体。
关系(Relationships):表示实体之间的联系或关联。关系通常用菱形表示,并连接相关联的实体。
3.2三大范式
在数据库设计当中,应存在一些规则,让表的设计更加合理美观,范式(Normalization)便是一种用于优化和规范化数据结构的方法。
3.2.1第一范式(1NF)
第一范式要求数据库表中的每个列都是原子的,不可再分的。它确保每个单元格中只包含一个值,而不是多个值的组合。要满足第一范式,需要将复杂的数据拆分为更小的原子值,并使用主键来唯一标识每条记录。(第一范式是其他范式的基础。)
3.2.2第二范式(2NF)
第二范式在满足第一范式的基础上,进一步消除非主键列对主键的部分依赖。换句话说,表中的非主键列必须完全依赖于主键,而不能依赖于主键的部分。
3.2.3第三范式(3NF)
第三范式在满足第二范式的基础上,消除非主键列之间的传递依赖。这意味着非主键列之间不应该有直接依赖关系,而是应该通过主键进行关联。
总而言之: 通过遵循三大范式,可以设计出规范化、减少冗余、易于维护和优化查询性能的数据库结构。然而,范式过度分解可能导致关联查询复杂,因此在实际设计中,有时可能需要根据具体情况进行权衡和优化。
4.聚合函数
MySQL中,聚合函数是用于处理多行数据并返回单个结果的函数。它们对数据进行统计、汇总或计算,并常用于SELECT语句的SELECT子句中。下面是MySQL中常用的聚合函数:
4.1COUNT
COUNT:用于计算指定列的行数或满足特定条件的行数。
SELECT COUNT(*) FROM Orders;
4.2SUM
SUM:用于计算指定列的数值总和。
SELECT SUM(amount) FROM Sales;
4.3AVG
AVG:用于计算指定列的数值平均值。
SELECT AVG(price) FROM Products;
4.4MAX
MAX:用于查找指定列的最大值。
SELECT MAX(age) FROM Students;
4.5MIN
MIN:用于查找指定列的最小值。
SELECT MIN(quantity) FROM Inventory;
5.分组查询
在MySQL中,分组查询是通过使用GROUP BY子句将数据按照指定的列进行分组,并在每个分组上执行聚合函数来进行数据统计和汇总。分组查询通常与聚合函数(如COUNT、SUM、AVG等)一起使用,以便在分组的基础上对数据进行汇总分析。
下面是MySQL中分组查询的基本语法:
SELECT column1, column2, aggregate_function(column3)
FROM table_name
GROUP BY column1, column2;
其中,column1和column2是用于分组的列,aggregate_function(column3)是对分组后的数据执行的聚合函数,table_name是要查询的数据表。